마이크로소프트, ACL 2022
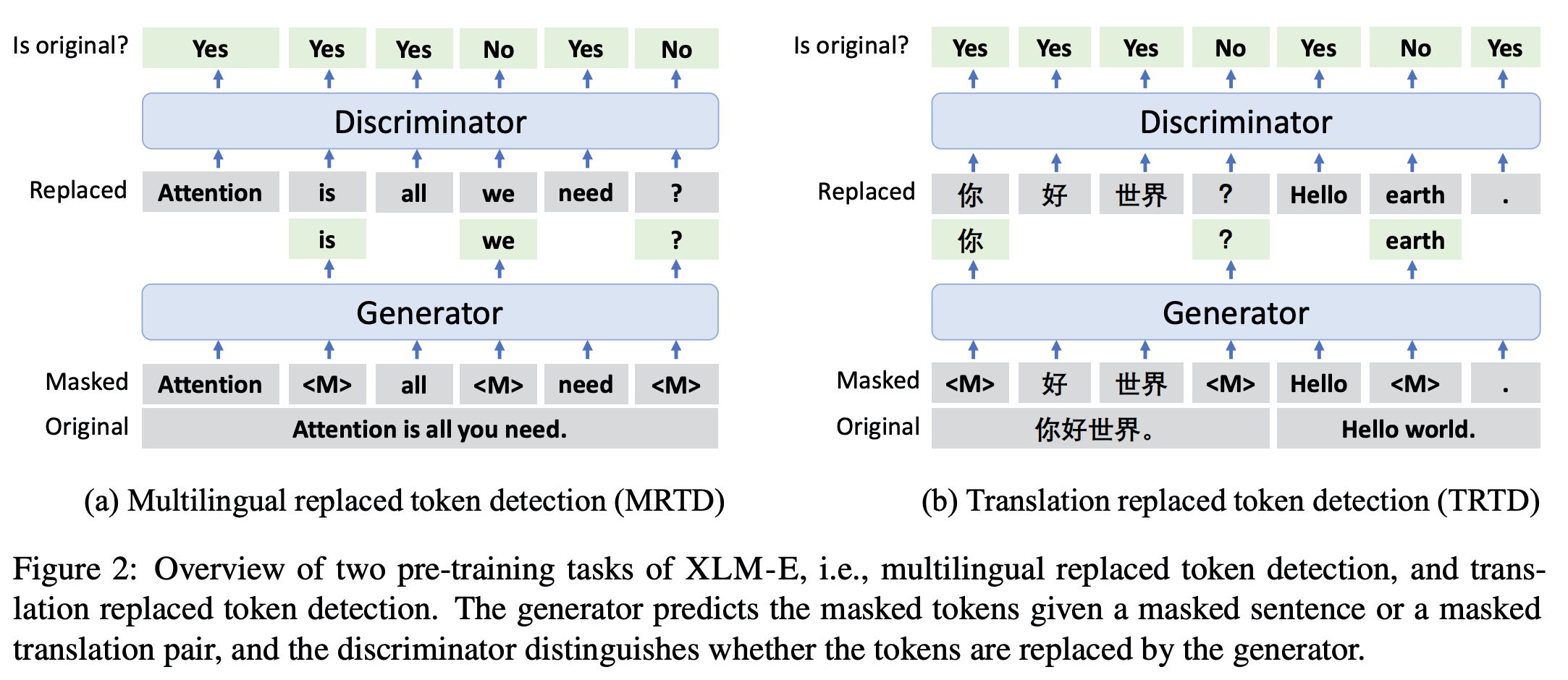
- MRTD(multi-lingual replaced token detection), TRTD(translation replaced token detection) 두 가지 loss 사용해서 ELECTRA multilingual 모델을 만들었다.
ELECTRA
- RTD(replaced token detection) task 제시한 논문
- Generator(MLM) - Discriminator(RTD) 구성되어있어서 mask 토큰을 generator 가 복구, discriminator가 replace 되었는지의 여부를 맞추도록 하였다.
- Generator를 보통 작은 BERT 모델을 가져와서 사용함.

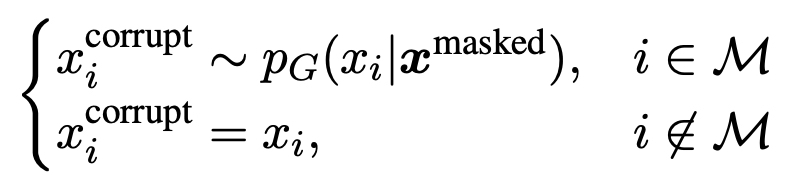
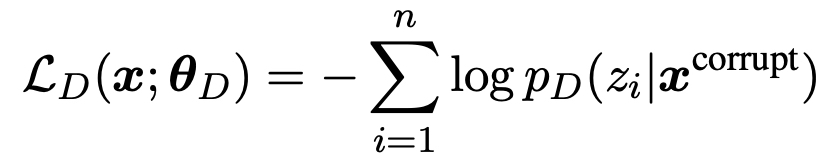
- : 가 변경된 토큰인지 원본 토큰인지에 대한 라벨
- 파인튜닝은 generator를 떼어내고 discriminator 만으로 진행한다.
XLM-E
- ELECTRA처럼 generator, discriminator로 구성된다.
- MLM, MRTD는 multilingual ELECTRA로 데이터로 다양한 언어를 사용한다.
- 마스킹은 uniform 마스킹을 진행했다.(span 마스킹의 경우 문제가 어려워져서 generator의 성능 저하가 있게 했고, 실제 사전훈련에서는 사용되지 않음)
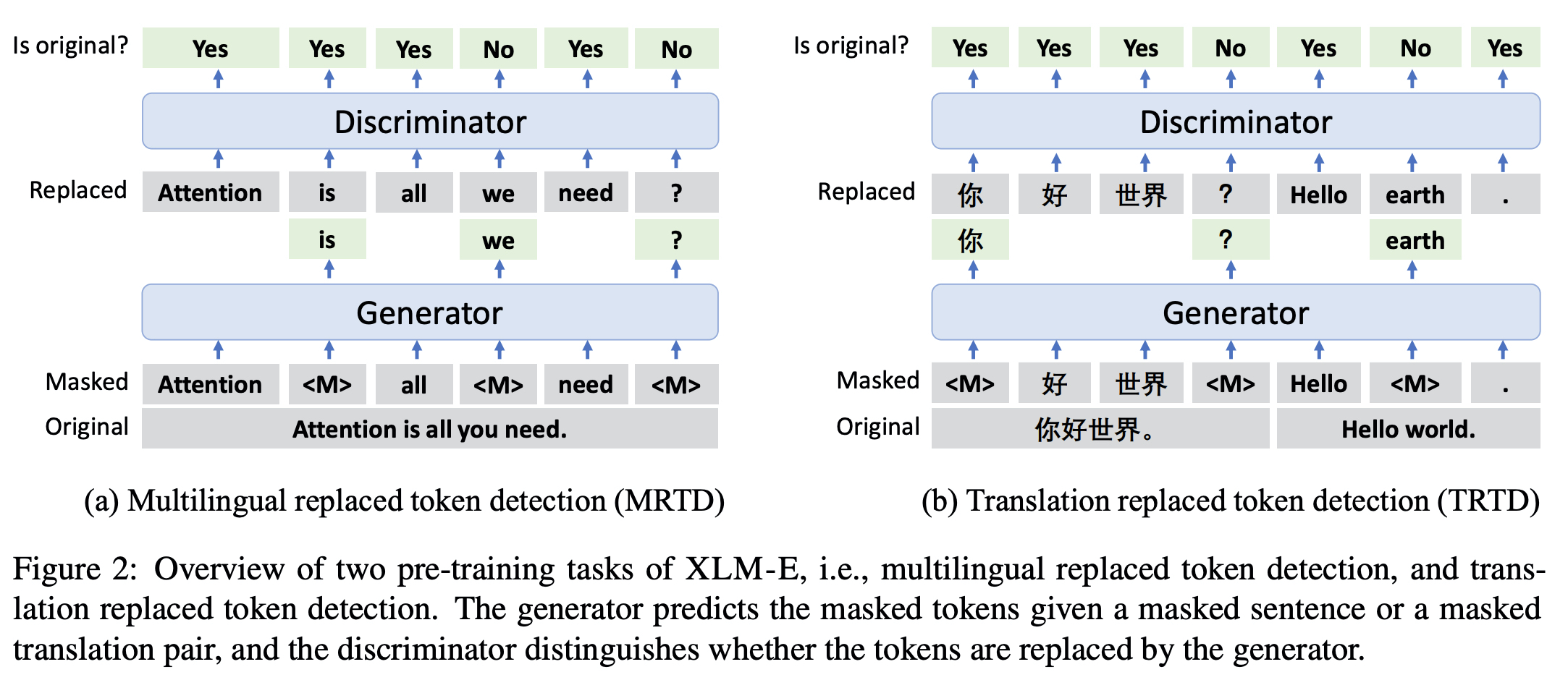
- TLM, TRTD의 경우는 번역된 데이터를 가지고 진행했다.
쌍으로 구성된 번역된 데이터로 input translation pair
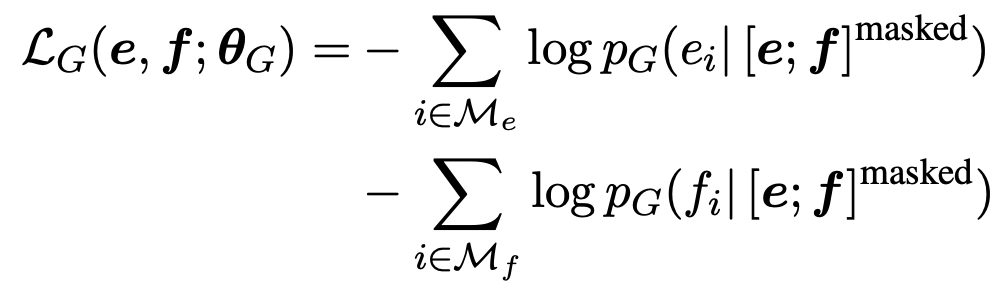
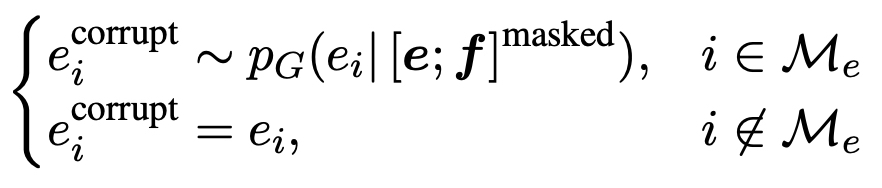
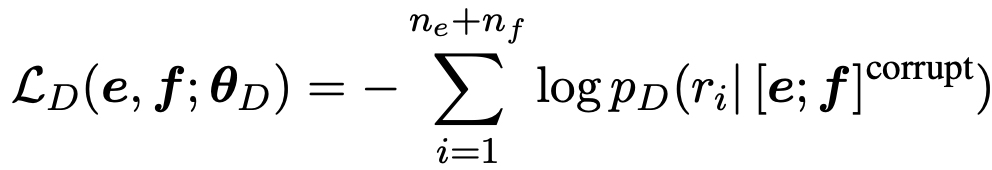
- Training objective
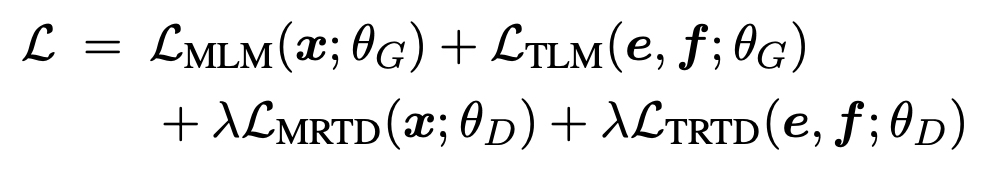
Gated Relative Position Bias
- Self-attention 내부에서 작용하는 relative position
- 포함되어서 어텐션 연산이 진행된다.
- update, reset 에 대한 정보를 통해서 받아옴으로써 내용으로부터 위치정보를 가져온다는 점이 다른 relative position 들과 비교해서 가장 다른 점이다.
- 언어마다 토큰 사이의 거리(위치)가 다르게 작용할 수 있다는 점을 녹여내고 싶었다.
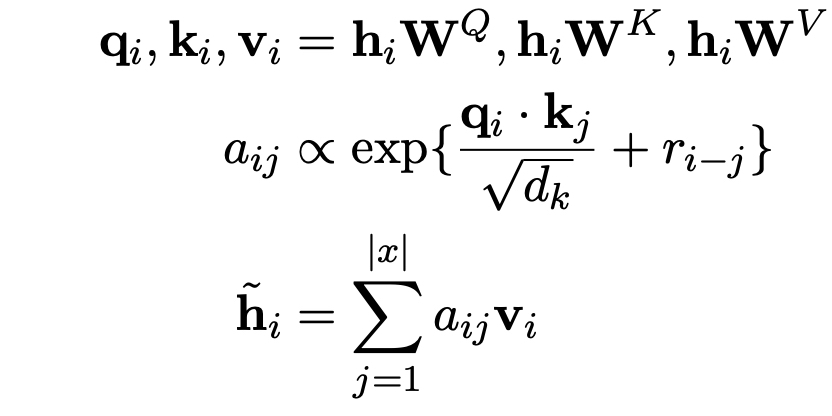
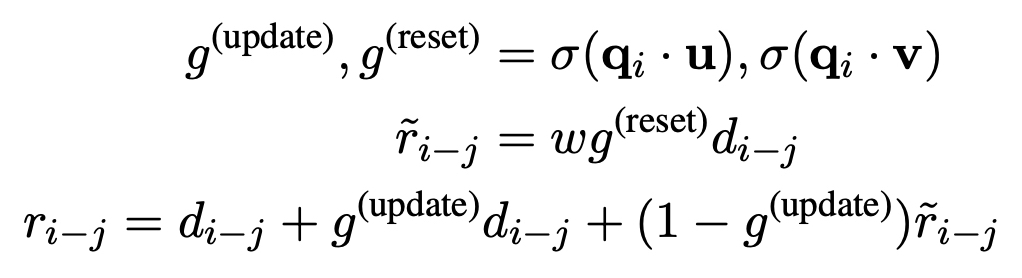
Initialization
large scale 훈련할 때에는 초기화가 중요
1. uniformly sampling (-0.02, 0.02)
2. 스케일링 : attention output, feed-forward output
Experiments
Data
- CC-100 multilingual corpus, Parallel corpora(MultiUN, IIT Bombay, OPUS, WikiMatrix, CCAligned)
- low resource 언어의 경우 데이터 수가 매우 작기 때문에 data sampling 진행하여 밸런스를 맞춰주고자 했다.
Model
- Transformer base-size 12 layer, hidden size 768, FFN hidden 3072
- generator 4-layer Transformer (hidden size 동일)
Training
- : 50
XTREME cross-lingual understanding tasks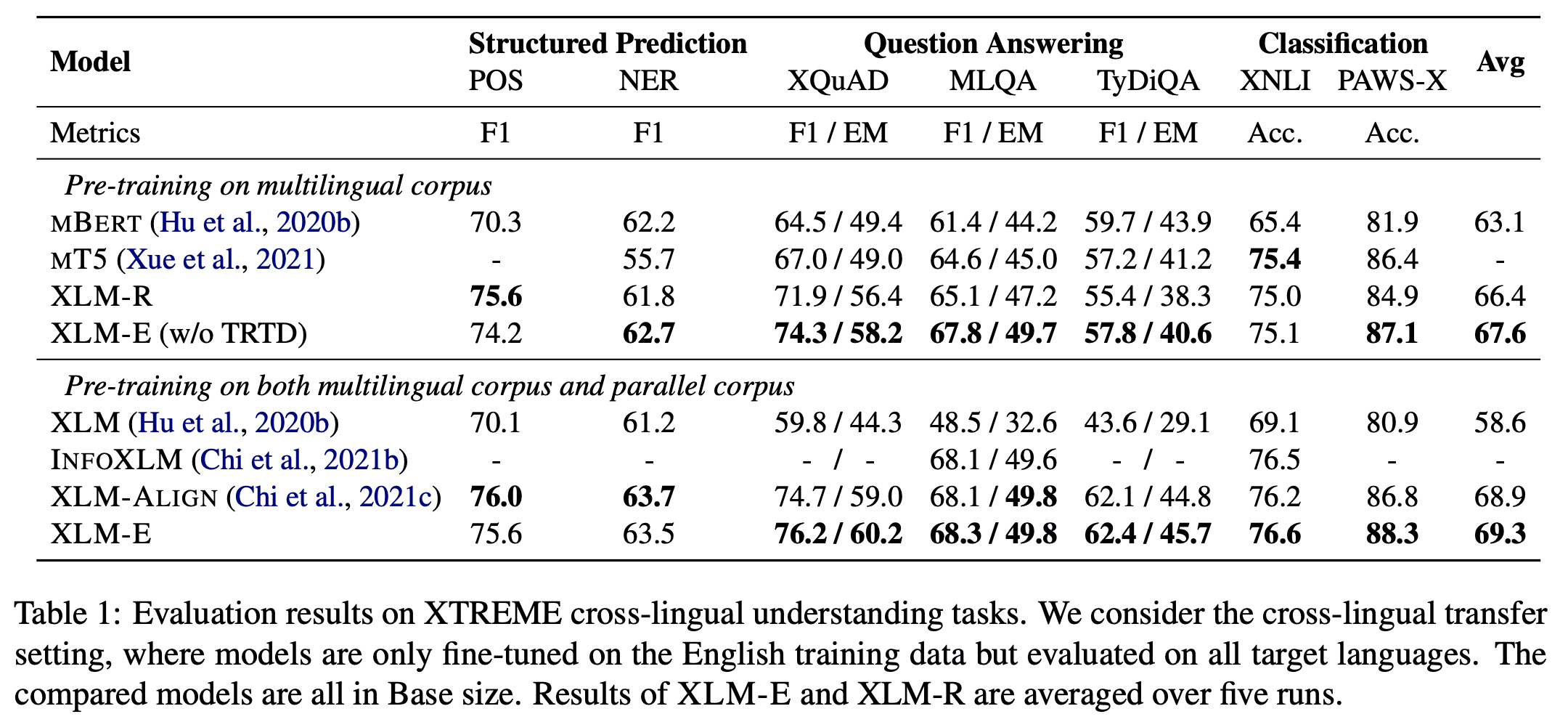
- Avg 기준에서 multilingual corpus에서 XLM-E가 XLM-R(XLM-RoBERTa) 비해 1.2 상승, multilingual corpus & parallel corpus 경우 XLM-ALIGN 비해 0.4 상승했다.
- XLM-R, XLM-ALIGN 비교했을 때에 computation cost 적게 들기도 했다.
Analysis
- Computation cost 보기 위해서 FLOPs 확인
- INFOXLM, XLM-ALIGN의 경우 post-training에 속하기 때문에 이전 사전학습 때에 사용된 FLOPs 포함된다.
- 연산량은 적은데 파라미터 수는 비슷하다.
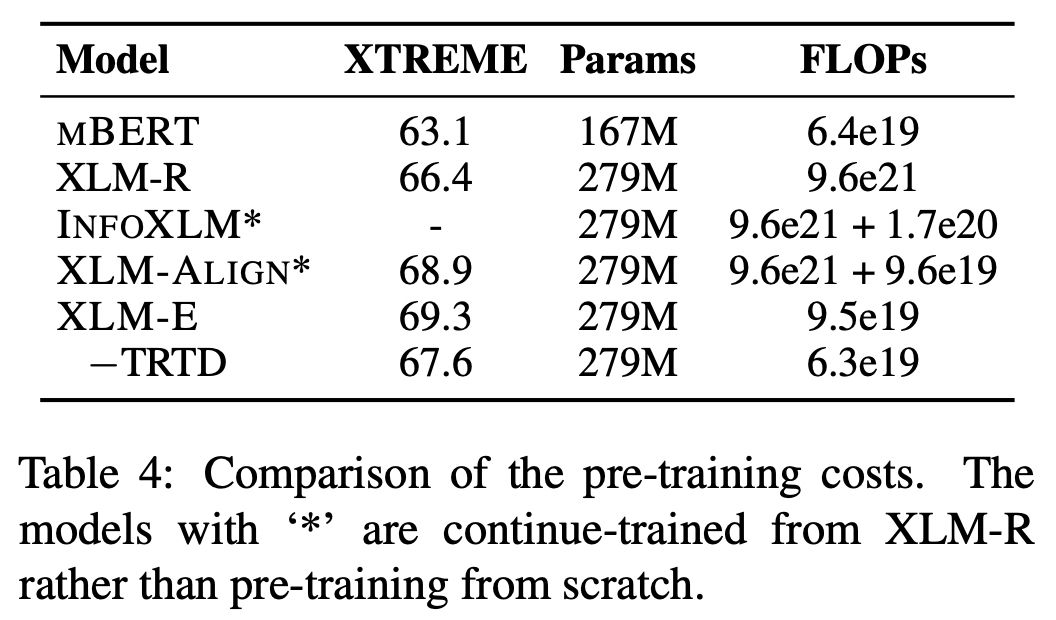
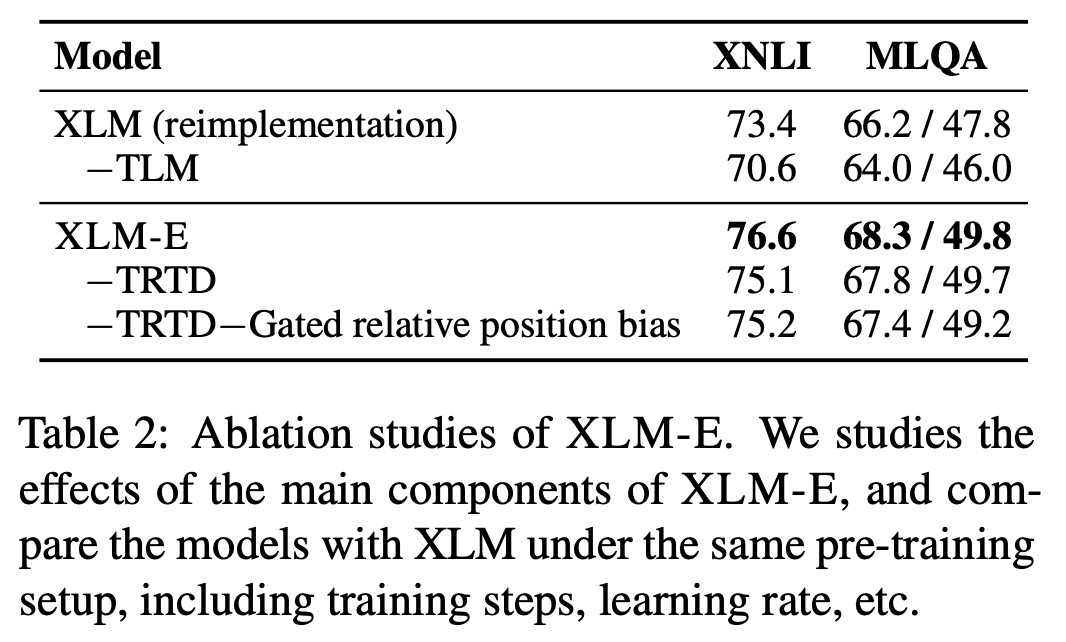
- TRTD를 뺐는데도 XLM-E가 더 좋고, MLQA에 대해서는 Gated relative position bias 쓰는게 도움이 됌
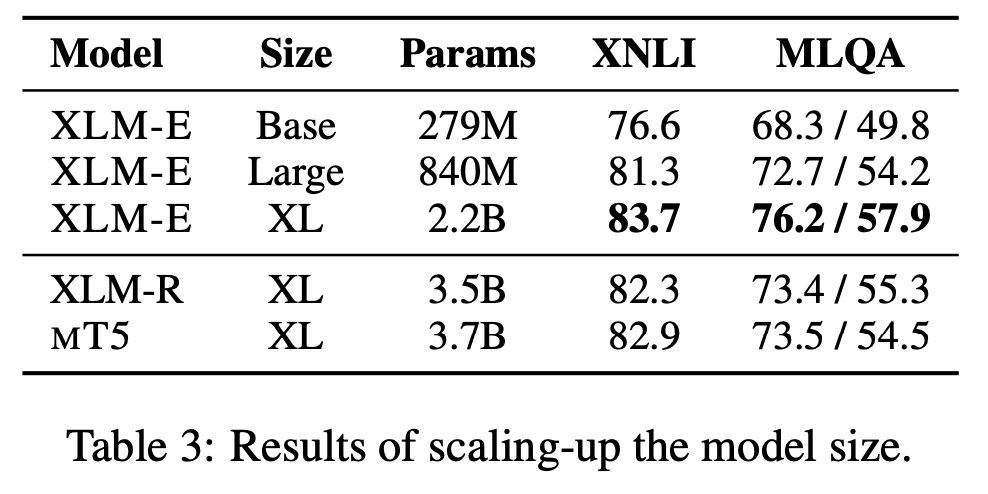
- 파라미터 적게 썼는데에도 점수는 우리가 더 좋아

산미 있는 커피를 좋아하는 자연어처리 엔지니어. 일상 속에서 요가와 따릉이
를 좋아합니다. 인간의 언어를 이해하고 생성하는 AI 기술 발전을 위해 노력하고 있습니다. 🧘♀️🚲☕️💻