- 단어 유사도를 이용해서 sparse transformer 만들어낸 논문
- Neural Clustering Method, Neural Clustering Attention Mechanism
- 비슷한 단어들을 그룹핑, 어텐션도 그룹 기준으로 최대한 진행되도록 하였다.
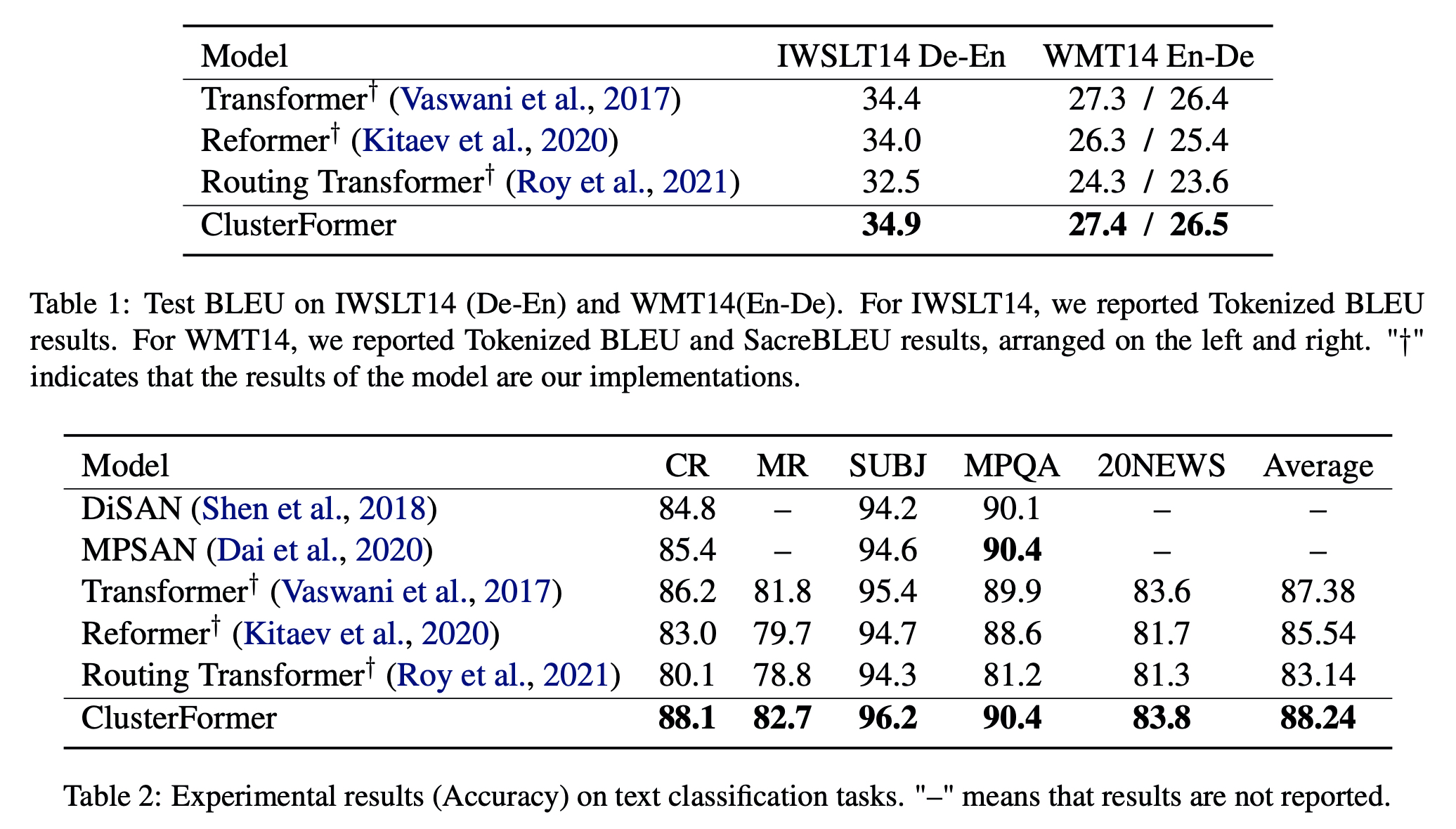
- 기계번역, 분류, NLI 같은 테스크에서 Reformer, Routing transformer 보다 좋은 성능을 내었다.
Computation 관련
Attention : Quadratic computation
Reformer, Routing transformer : O(N log N d), O(N√N d)
- 2000단어 넘을 때에 (ClusterFormer, Routing transformer, Reformer)
- Memory : 53.8%, 60.8%, 31.8%
- Training time : 51.4%, 41.8%, 14.4%
Neural Clustering Method
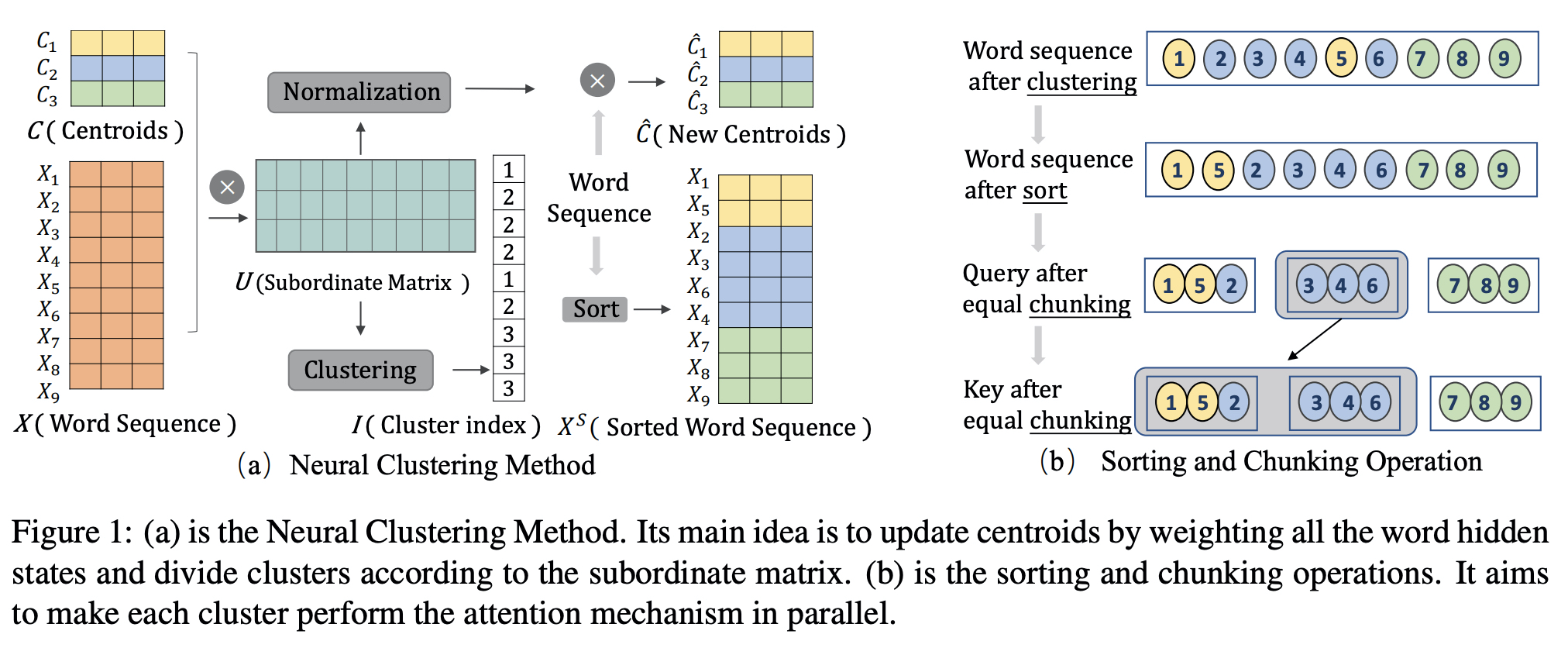
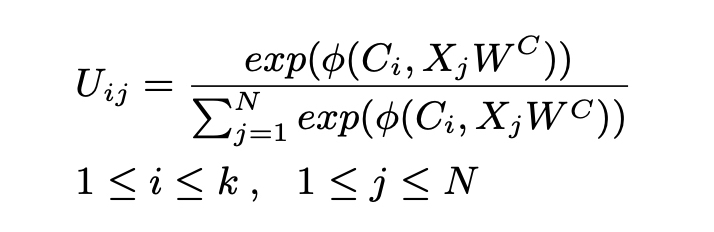
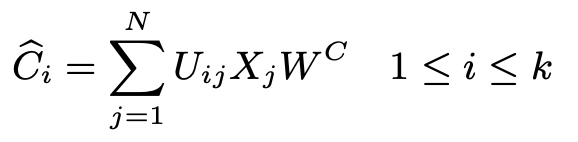
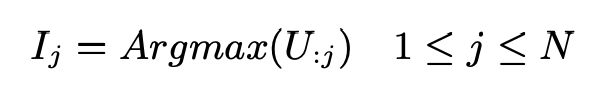
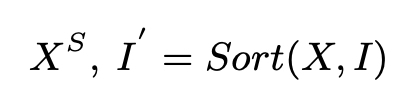
- X ∈ R(N×d), C ∈ R(k×d)
- C is initialized randomly in the first layer.
- subordinate (similarity) matrix U
- W(C) ∈ R(dmodel×dmodel)
- a similarity measure function
- i and j represent the index value of the centroid and word.
- I ∈ R(N) represents the cluster index of all the word hidden states
- X(S) ∈ R(N×dmodel)
Clustering Loss
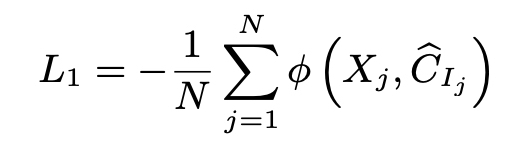
- the mean of the negative similarity scores of word hidden states and their belonging centroids.(optimal clustering scheme)
Neural Clustering Attention Mechanism
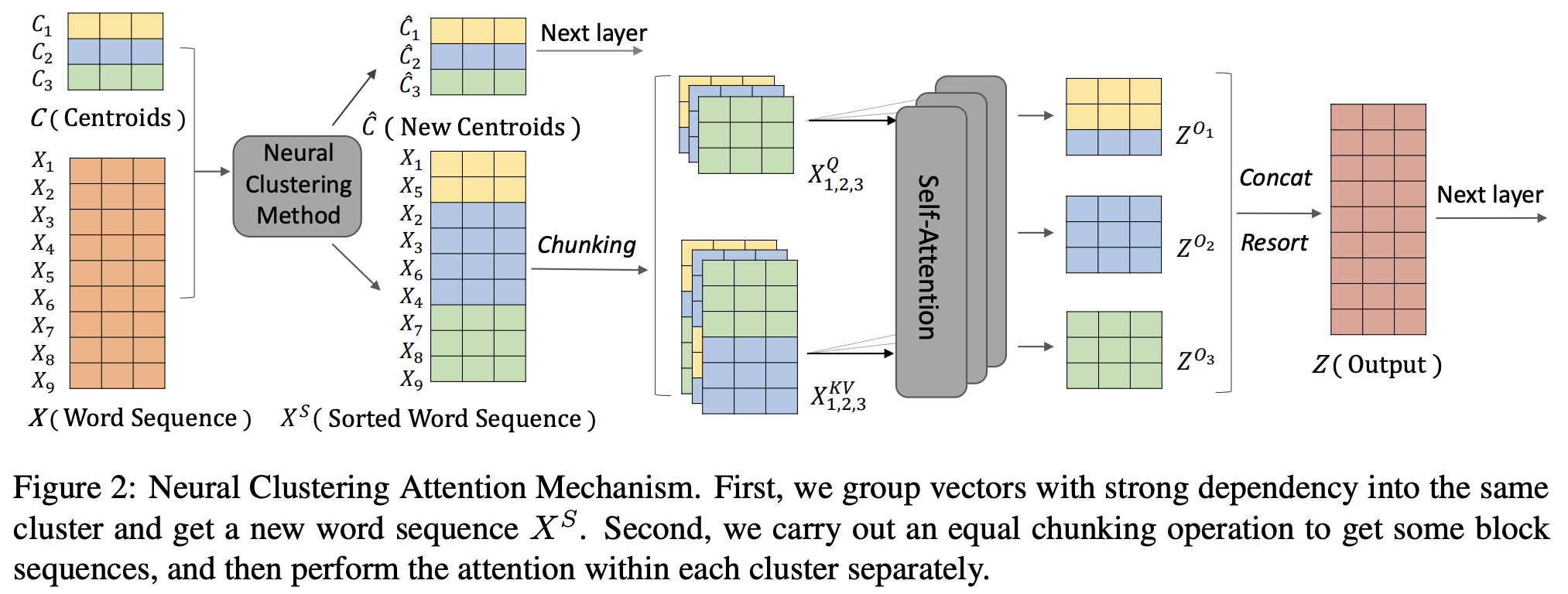
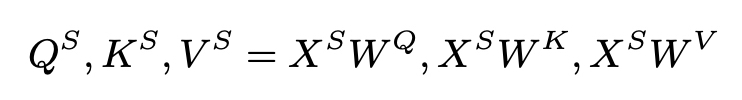
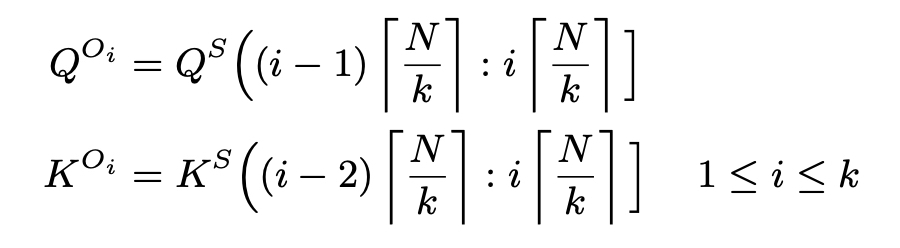
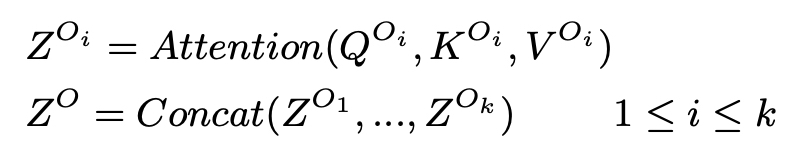
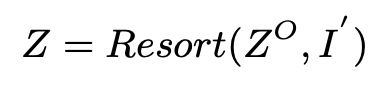
- Q(Oi) ∈ R(w×d), K(Oi) ∈ R(2w×d)
- w = N/k
- Z(Oi) ∈ R(w×d), Z(O) ∈ R(N×d)
- the query can cover the words in the same cluster as much as possible.
Centroid Sorting Loss
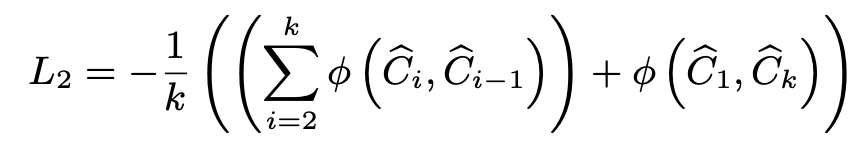
- the mean of the negative similarity scores of the adjacent centroid pairs.
Experiment
Reformer, Routing Transformer 뛰어넘고, Transformer 비슷한 결과

산미 있는 커피를 좋아하는 자연어처리 엔지니어. 일상 속에서 요가와 따릉이
를 좋아합니다. 인간의 언어를 이해하고 생성하는 AI 기술 발전을 위해 노력하고 있습니다. 🧘♀️🚲☕️💻