분석 순서
- 문서를 3D 형태 (n,m,c)로 표현 (하나의 이미지와 같은 형태로 표현)
- N : 문서 표현 시 사용하는 최대 단어 수 (각 문서별 동일한 길이로 세팅)
- M : 단어를 표현하는 임베딩 벡터의 차원
- C : 이미지 데이터에서의 채널 수 (텍스트 분석에서는 1)
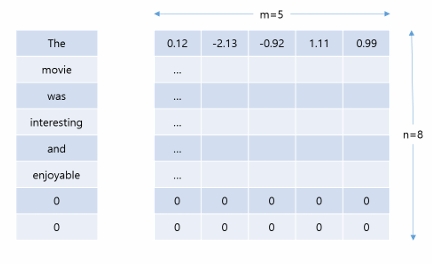
텍스트 분석1 - 문서 구조
- 문서 : The movie was interesting and enjoyable
- N = 8, M = 5, C = 1
텍스트 분석2 - 합성곱 필터
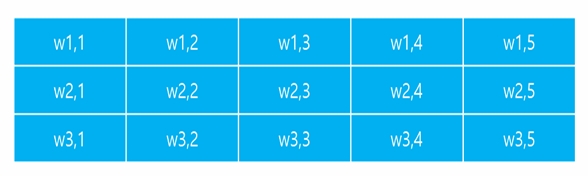
- (텍스트의 경우) NxMxC의 문서에 대해서 KxMxC 형태의 필터를 적용
- M,C는 입력 데이터 포맷에 따라 결정 (설계x)
- K < M
- ex) Kx5x1로 세팅
- K = 3
텍스트 분석3 - 필터 적용
- stride = 1 (문서의 경우 보통 1)
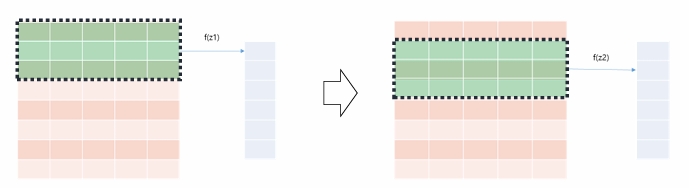
→ (N - K + 1) 크기의 1D array
- 여러 개의 필터 적용 가능
ex) (크기가 같은)필터 2개 적용
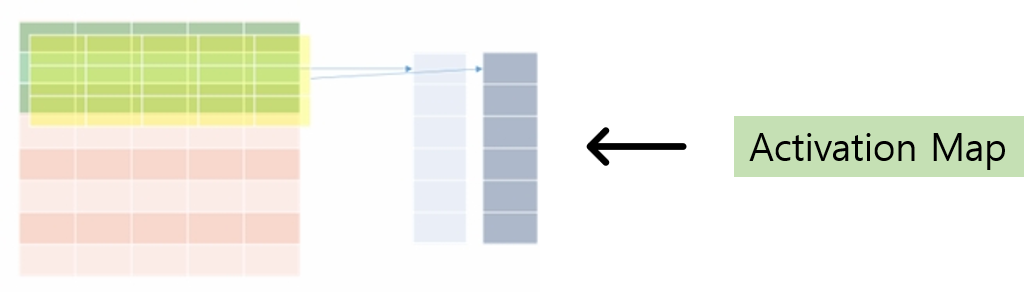
NxM 형태의 문서에 KxM 형태의 필터를 h개 적용
→ 결과물은 (N - K + 1)x h
텍스트 분석4 - Pooling 및 출력
- Pooling layer 추가 (이미지에서 처리와 유사)
- Flattening
- Fully connected layer
- 출력층 (with Softmax)

ML/DL Study,기록📝