RNN (Recurrent Neural Network, 순환 신경망)
-시계열 데이터 및 시퀀스 데이터나 자연어 처리와 같이 데이터가 순서에 의미가 있는 경우에 유용한 인공 신경망의 한 유형
-이전의 정보를 다음 상태의 입력으로 사용하는 순환 구조
-
Sequence Data를 다루기에 적합
Sequence Data : 순서를 가지고 연속적으로 나열되어 있는 데이터- Text : 단어들의 Sequence
- Video : 이미지들의 Sequence
-
Text Data 분석에 적합
- 단어들의 문맥적 의미 추출에 용이
- 단어들 간 관계 정보 추출에 용이
- 어떤 단어들이 어떤 순서로 언제 사용되었는지에 대한 정보 추출 용이
→ 텍스트가 가지고 있는 정보를 추출하기에 적합
RNN을 사용한 텍스트 분석
-
언어 모형 (Language Model), 분류, 기계 번역 등
-여러 개의 단어들이 동시에 출현할 확률이나 특정 단어들이 주어질 때 그 다음 나올 단어가 무엇인지 예측하는데 사용되는 모형
-일련의 단어들의 확률 분포
-특정 문장에서의 단어 시퀀스의 확률 분포 모델링 (단어들의 시퀀스에서 그 다음에 올 단어를 예측하는 확률 모델)- ex) "I like the movie. The movie is _"
-is 다음에 나오는 단어를 정확하게 예측하기 위해서는 이전에 어떠한 단어들이 어떠한 순서를 가지고 사용되었는지에 대한 정보를 사용하는 것이 필요
-"The movie is"만을 사용하는 것보다 그 앞 문장인 "I like the movie" 문장 정보와 함께 사용하는 것이 더 효과적
- ex) "I like the movie. The movie is _"
-
감성 분석
문서 (혹은 문장)의 감성을 분석할 시 단순히 단어들의 출현 빈도만을 고려하는 것보다 단어들 간의 관계 정보, 다른 단어들과 어떠한 관계를 갖고 출현하였는지에 대한 정보를 사용하는 것이 필요
→ 정답을 맞히는데 필요한 문서가 가지고 있는 정보를 더 잘 추출- ex) "The movie was not fun."
fun과 not이라는 단어들의 빈도 혹은 출현 여부 및 fun과 not의 시퀀스 정보 (fun과 not이 어떤 순서로 등장하는가)가 중요
→ 보다 정확한 문장의 감성 파악 가능
- ex) "The movie was not fun."
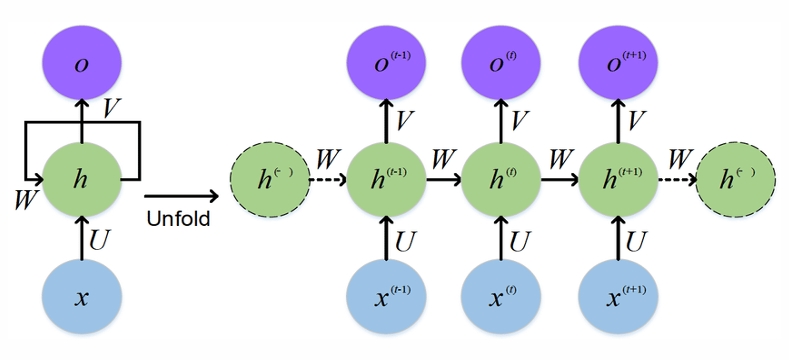
RNN 동작 원리
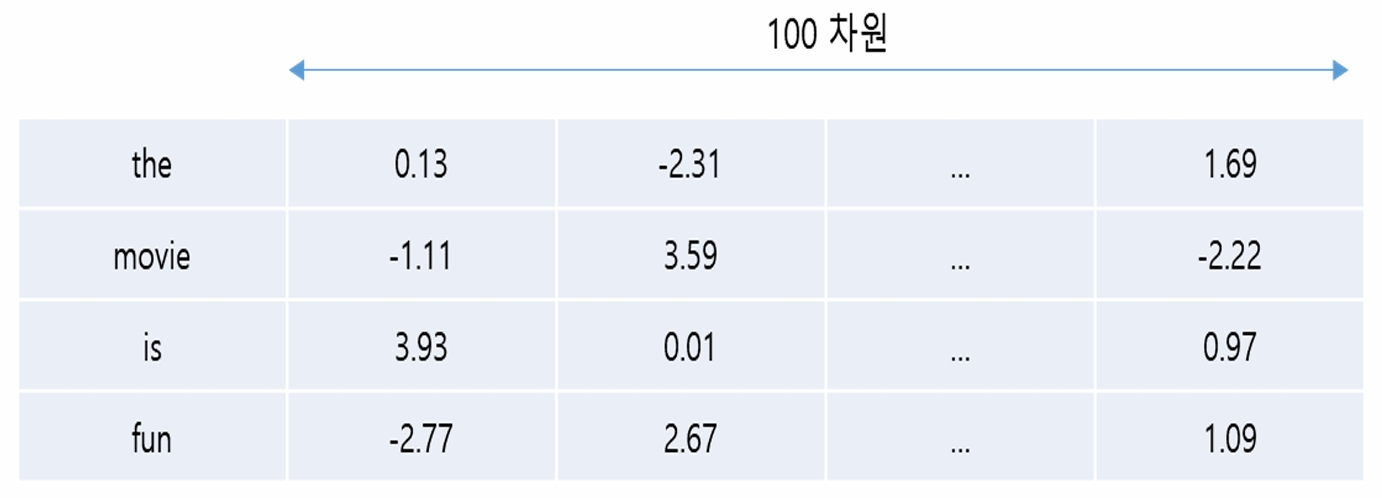
-RNN에 텍스트 데이터를 입력하기 위해서는 각 단어를 저차원의 벡터로 표현하는 것이 필요
-저차원 벡터 = Embedding Vector
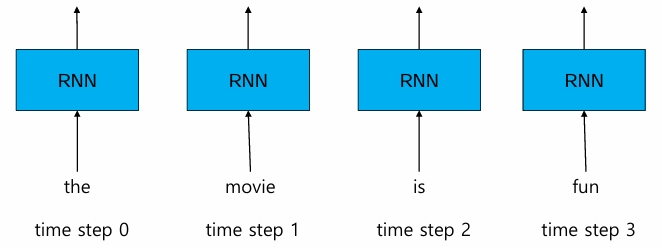
예제 텍스트 "the movie is fun"
-RNN에 각 단어의 벡터 정보가 순차적으로 입력
-첫 번째 the, 두 번째 movie, 세 번째 is, 네 번째 fun에 대한 벡터 정보 입력
-각 원소의 값도 학습을 통해서 값이 결정되는 파라미터
-초기에는 랜덤하게 설정, 학습을 통해 업데이트
-동일한 RNN층(은닉층)이 여러번 순차적으로 반복 사용
-time step : 입력되는 순서를 나타내기 위한 정보
-
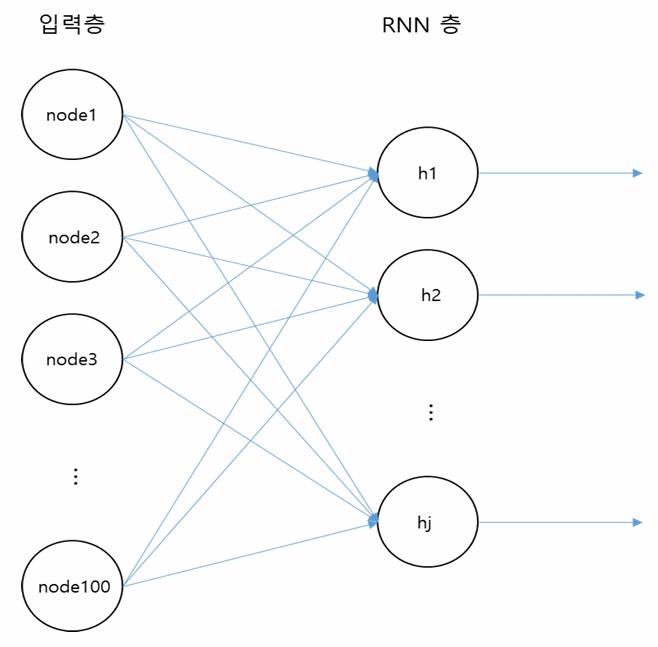
입력층을 통해 각 단어의 정보 입력
- 입력노드의 수 = 임베딩 벡터의 원소 수
(N = 100으로 가정) - 각 노드가 각 원소의 값을 입력 받음
- 입력노드의 수 = 임베딩 벡터의 원소 수
-
RNN층 = 은닉층
- 여러 개의 노드로 구성
- 은닉층의 노드 수는 분석가가 결정
- hidden state : RNN층이 출력값
- 활성화 함수는 주로 tanh 사용
-
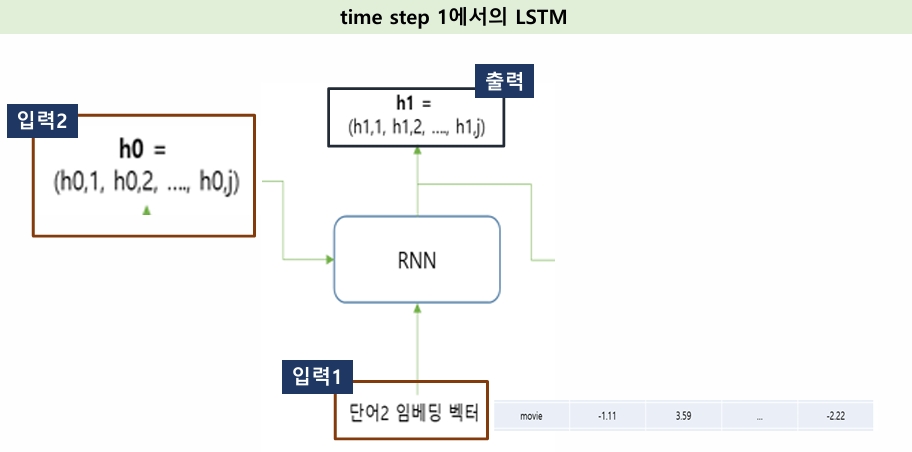
첫 번째 단어 정보 입력 Time Step 0
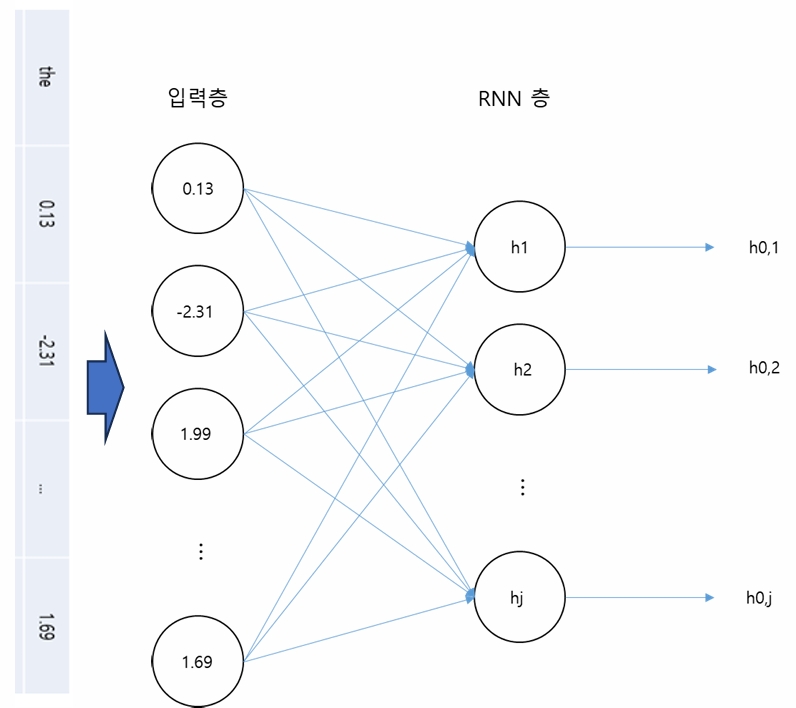
- hidden state(vector) : RNN층의 출력 값 → h0=(h0,1, h0,2, ...., h0,j)
-
두 번째 단어 정보 입력 Time Step 1
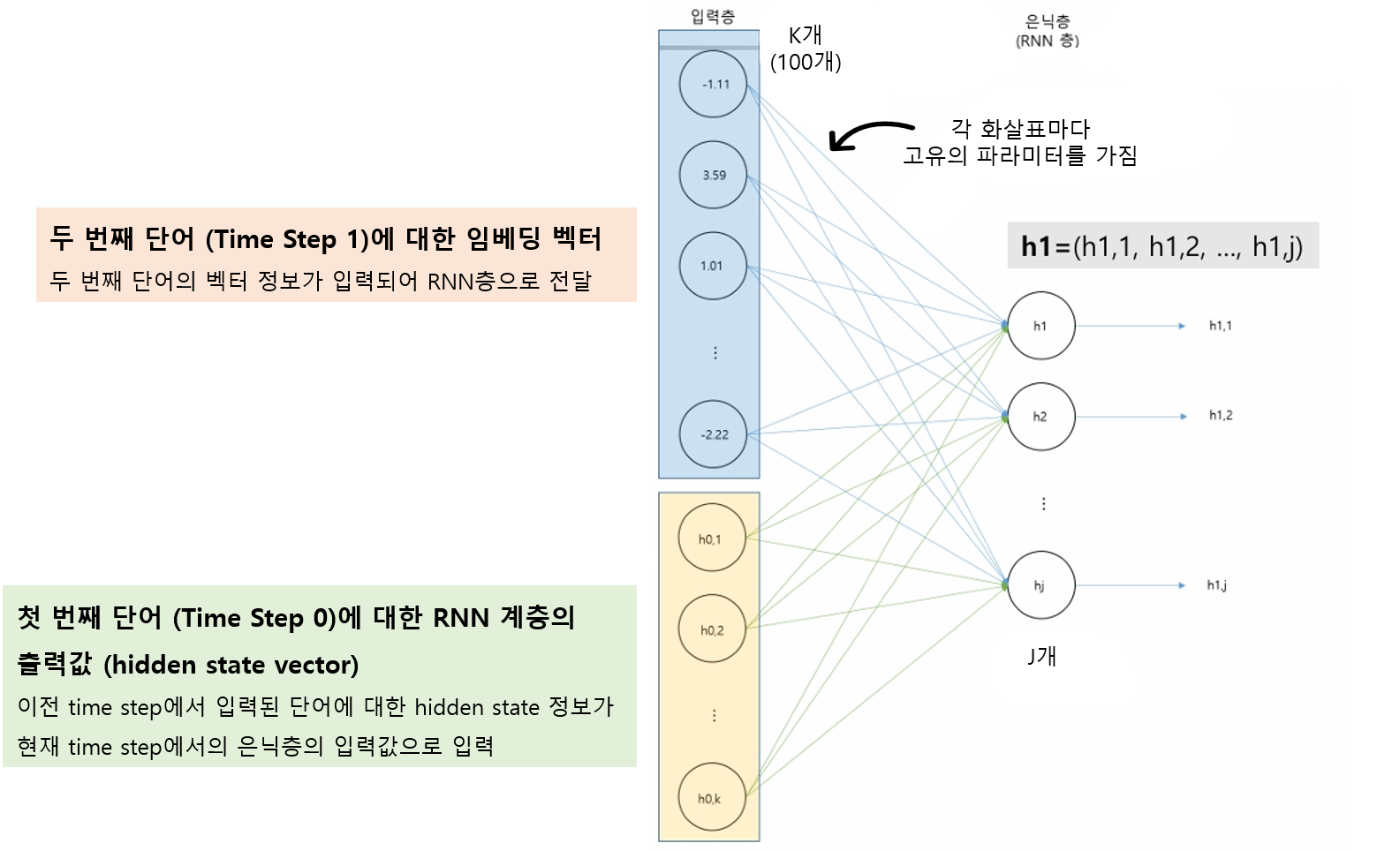
RNN 구조
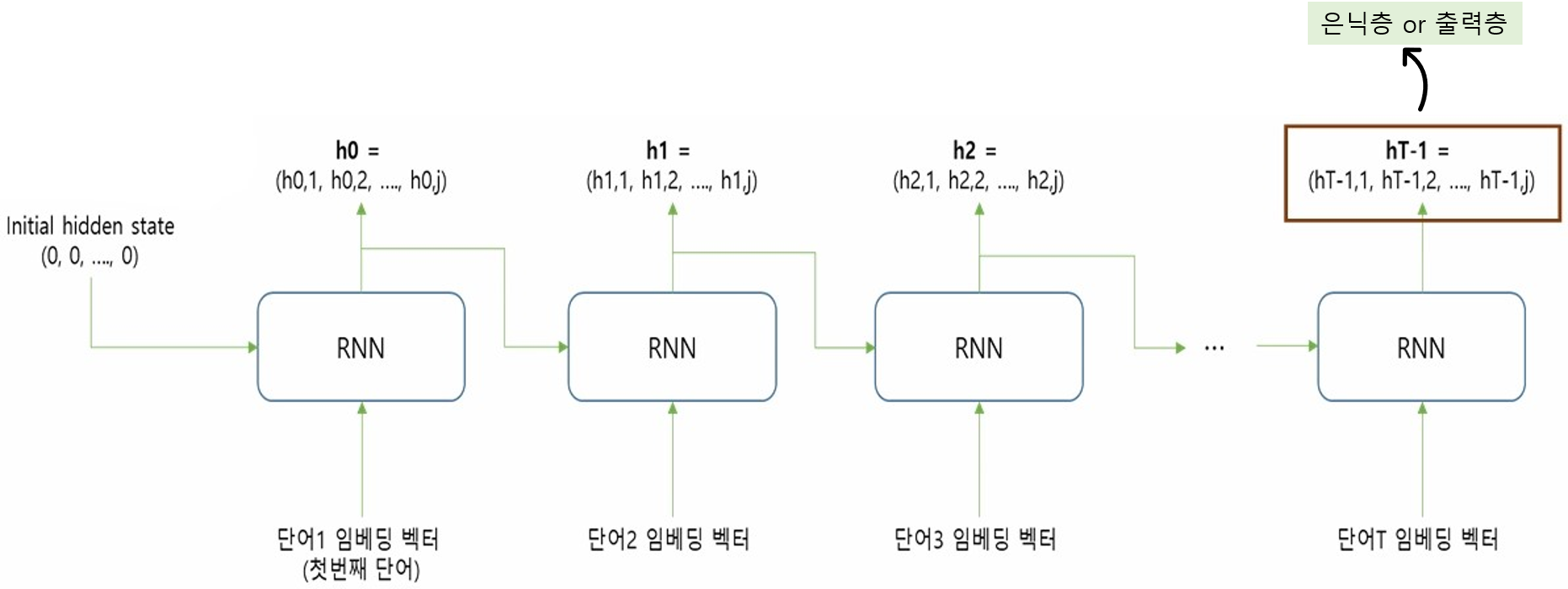
- 초기 hidden state 값은 보통 0으로 초기화
- hT-1
RNN층이 출력하는 (입력된)텍스트 데이터에 대한 최종값
→ 이 값이 다음 계층으로 전달 (이전에 입력된 단어들의 정보 포함)