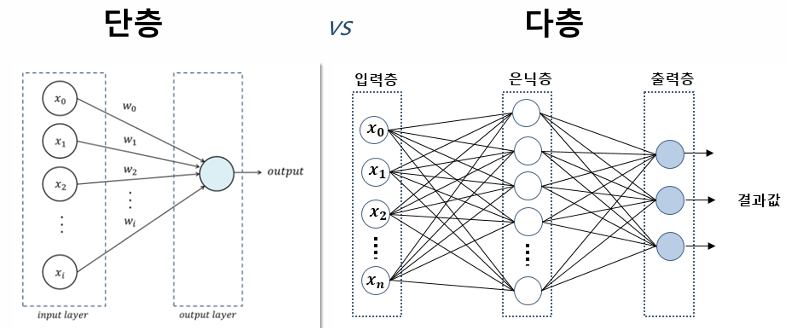
MLP(Multi-Layer Perception, 다층 신경망)
-인공 신경망의 한 종류로 하나 이상의 은닉층을 포함하는 Feedforward 신경망
-복잡한 데이터 패턴을 인식하고 분류, 회귀, 패턴 인식 등의 다양한 작업에 사용
MLP 주요 특징
-
비선형성
비선형성 활성화 함수를 사용하여 선형적으로 구분되지 않는 데이터 처리 -
Feedforward 구조
-MLP는 입력층에서 출력층으로 정보가 순차적으로 전달되는 전향적 구조
-데이터가 여러 은닉층을 거치며 변환 -
역전파 알고리즘
-학습 과정에서는 역전파 알고리즘 (Backpropagation Algorithm)을 사용
-가중치(Weights)와 편향(Biases) 조정 → 주어진 입력에 대한 예측 오류를 최소화하도록 학습 -
범용 근사자
매우 복잡한 함수나 패턴 학습 가능
신경망 발전 과정
-
McCulloch와 Pitts가 신경세포를 모방한 최초의 연산 모형 발표 (1943년)
-
Rosenblatt이 퍼셉트론 발표 (1958년)
-
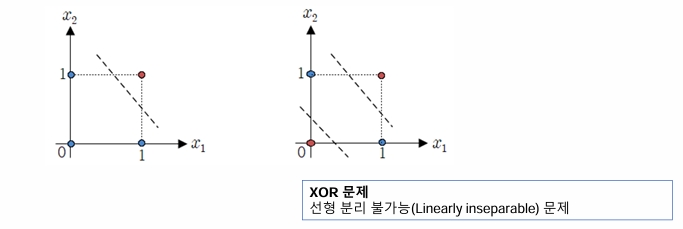
Minsky가 단층 신경망은 선형 분리가 불가능한 문제를 풀 수 없다고 지적 (1969년)
- 단층 신경망의 한계
- 선형 분리성의 제한
XOR 문제와 같은 선형으로 분리 불가능한 문제들에 적용 불가능 - 복잡한 문제 해결 능력 부족
입력과 출력 사이의 복잡한 관계를 모델링하는 데 한계
실세계의 많은 문제들은 복잡하고 비선형적인 관계를 포함하고 있음
→ 단층 신경망보다 더 복잡한 구조 필요 - 특성 추출 능력 부족
고차원 데이터에서 유의미한 특성을 자동으로 추출하고 학습하는 능력이 매우 제한적
-
Rumelhart의 연구진이 역전파 알고리즘(Backpropagation)을 제안하며 다층 퍼셉트론(Multi-layer Perceptron, MLP)의 학습이 가능해짐 (1986년)
인공 신경망 학습 프로세스
- 초기화 (Initialization)
학습 과정을 시작하기 위한 준비 단계, (보통)무작위 값으로 초기화 - 순전파 (Forward Propagation)
-입력 데이터가 신경망의 입력층으로 주어짐, 각 층의 뉴런을 통과하면서 활성화 함수에 의해 처리
-신경망의 출력층까지 과정 수행 - 오차 계산 (Error Calculation)
-신경망의 출력과 실제 타깃 값 사이의 차이 계산 (손실 함수 : MSE or 교차 엔트로피 사용)
-신경망의 예측이 얼마나 정확한지 수치적으로 표현 - 오류 역전파 (Error Backpropagation)
-계산된 오차는 출력층에서부터 입력층 방향으로 역전파되어 각 가중치가 오차에 얼마나 기여하는지 계산
-각 가중치가 오차에 미치는 영향 계산 → 가중치 조정 (경사하강법) - 가중치 업데이트 (Weight Update)
-경사하강법을 사용하여 각 가중치 업데이트
-오차를 최소화하는 방향으로 가중치를 조정하여 신경망의 성능 개선 - 과적합 (Overfitting)및 정규화 (Regularization)
-학습 과정 중 과적합 발생 가능 (학습 데이터에 대해 너무 잘 맞추어져 새로운 데이터에 대한 일반화 성능이 떨어지는 현상)
-방지를 위해 정규화 기법 (L1, L2 규제, 드롭아웃 등)을 사용, 모델의 복잡도를 제어하고 과적합을 줄임 - 반복 학습 (Iterative Learning)
-위 과정 반복, 최적화 진행
-반복을 통해 입력 데이터에 내재된 복잡한 패턴과 구조를 학습 → 다양한 문제에 대한 예측(계산) 수행
경사 하강법
-함수의 기울기(Gradient)를 사용하여 함수의 최소값을 찾는 최적화 방법
-손실 함수의 최소값을 찾아감
- 함수의 기울기
-주어진 점에서 함수의 증가율을 나타내는 벡터
-증가의 방향과 증가율의 크기를 알려줌
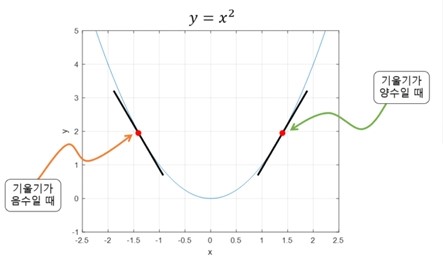
- 기울기가 양수인 경우 : x값이 증가할수록 함수값 증가
기울기가 음수인 경우 : x값이 증가할수록 함수값 감소
- 기울기 계산
함수의 미분을 통해 기울기 계산
→ 각 파리미터에 대해 함수의 출력값이 어떻게 변하는지 파악 - 이동 방향 결정
기울기가 양수라면 파라미터 감소, 음수라면 파라미터 증가 - 파라미터 업데이트
현재 파라미터에서 기울기의 반대 방향으로 일정 단계(학습률, Learning Rate)만큼 이동
→ 함수의 최소값(손실 함수의 최소값)을 향해 이동 - 반복
-위 과정을 반복하면서 (손실)함수의 값을 점차적으로 감소
-충분한 반복 후 함수의 값이 더이상 감소하지 않거나 특정 기준 아래로 떨어지면 과정 종료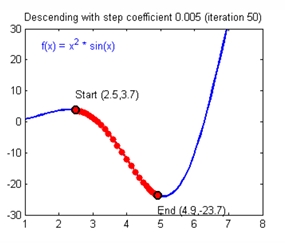
역전파 알고리즘 문제점
-
Gradient Vanishing (기울기 소실)
역전파 과정에서 출력층에서 멀어질수록 기울기 값이 매우 작아지는 현상- 기울기 소실 원인
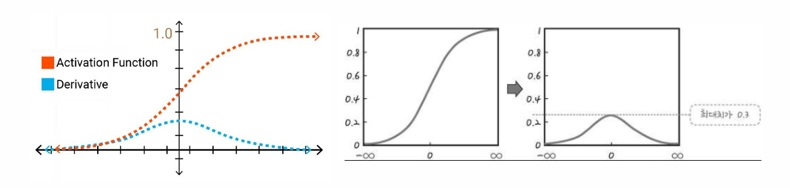
- 활성화 함수
Sigmoid, tahn 함수와 같은 활성화 함수 사용 시 미분값이 매우 작아지는 경우 발생
→ 가중치가 거의 업데이트 되지 않음
- 깊은 네트워크 구조
네트워크가 깊어질수록 역전파 과정에서 여러 층을 거치면서 미분값이 연속적으로 사용, 이 값들이 1보다 작을 경우 기울기 소실
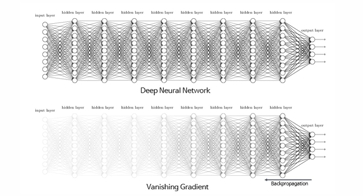
→ 신경망의 깊은 층에서 기울기 소실 문제 발생
연속적으로 기울기를 곱해 나가면서 그 기울기가 점점 작아짐
- 기울기 소실 해결책
ReLU 함수 사용 : 양수 입력에 대해선ㅇ Gradient가 1 → Gradient가 사라지는 문제 완화
-
Overfitting (과적합)
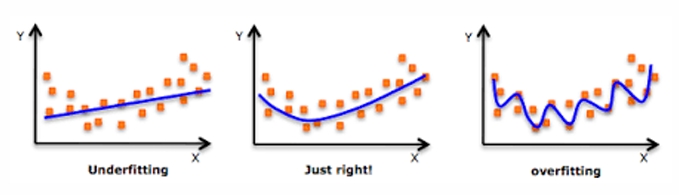
- 과적합 해결책
정규화 (Regularization)- L1 규제 (Lasso Regularization)
-가중치의 절대값에 비례하는 비용을 추가
→ 가중치를 정확히 0으로 만들어 해당 특성의 영향을 제거 → 모델 단순화
-모델의 희소성을 증가시키는 효과 - L2 규제 (Ridge Regularization)
-가중치의 제곱에 비례하는 비용을 추가
→ 가중치의 값을 줄여 모델의 복잡도를 낮춤
-가중치가 너무 크게 되어 과적합을 일으키는 것 방지 - 드롭아웃 (Dropout)
-학습 과정에서 무작위로 일부 노드를 비활성, 학습에 기여하는 것을 일시적으로 중단
-신경망이 특정 노드나 노드의 그룹에 과도하게 의존하는 것을 방지하여 과적합 감소
(test 시에는 모든 노드 사용) - 조기 종료 (Early Stopping)
-검증 세트의 성능이 더이상 개선되지 않을 때 학습을 조기 종료하는 방법
-학습 과정에서 모델의 일반화 성능이 최적점에 도달하면 그 시점에서 학습 중단
- L1 규제 (Lasso Regularization)
- 과적합 해결책


ML/DL Study,기록📝