시계열 데이터
-시간의 흐름에 따라 순차적으로 수집된 데이터로, 일정한 시간 간격으로 관측되며 각 시간 지점에서의 값으로 구성된다.
-계열 데이터는 시간의 변화에 따른 패턴을 분석하고 미래를 예측하는 데 사용된다.
시계열 예측
시간 순서대로 수집하거나 정렬한 순차적인 데이터를 활용하여 미래 시점의 상태를 예측
- 시계열 예측의 특징
-변동 가능성이 있고 완벽하지 않음
-다변량인 경우가 많음
-데이터셋의 구성을 적절히 변경하기 어려움
-시계열 데이터 예측을 위해서는 데이터 성질을 고려해야 함
-데이터가 정상성을 띨 때 시계열 예측 정확도가 높음
-정상성을 갖추지 못 했다면 정상성을 갖도록 변환 (차분, 로그 변환 등)
시계열 패턴
-
추세 (Trend)
장기적으로 증가하거나 감소하는 패턴
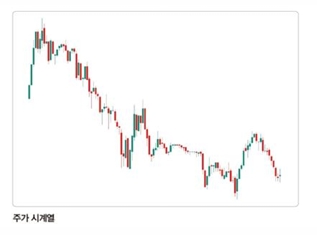
-
계절성 (Seasonality)
-주기적으로 반복되는 변화
-특정한 시기나 요일, 주, 월 등에 반복되는 계절성 요인에 영향을 받는 패턴
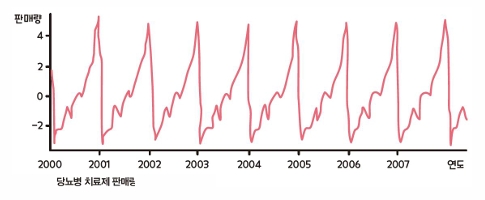
-
주기성 (Cycle)
-정해진 양이나 빈도 없이 값의 증가나 감소가 반복되는 패턴
-비계졀적인, 규칙적이지 않은 변동
-보통 불규칙한 기간을 가지며 계절성과는 다르게 사이클의 길이가 고정되어 있지 않음
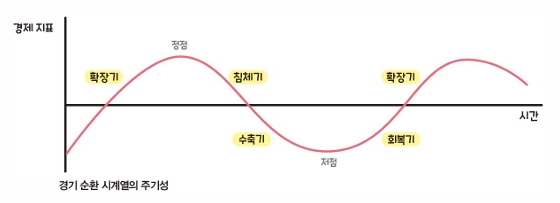
-
정상성 (Stationarity)
-정상성이란 '일정하여 늘 한결같은 성질'
-시계열의 확률적인 성질들이 시간의 흐름에 따라 불변
-평균, 분산, 공분산 등이 시간의 경과와 무관하게 일정
-특정한 트렌드(추세)가 존재하지 않는 성질
-비정상성 데이터는 정상성을 갖도록 변환 후 분석
→ 통계 기반 시계열 예측의 예측 정확도 향상
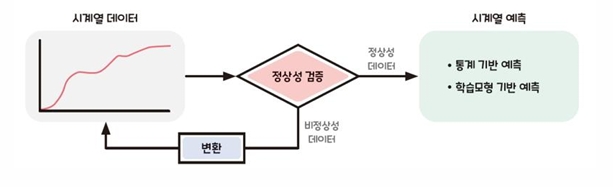
-
정상성 데이터의 3가지 조건
- 그래프에 지속적인 상승 또는 하락 추세가 없다.
- 과거의 변동폭과 현재의 변동폭이 같다.
- 계절성이 없다.
- 정상성 판단
| 시각적 판단 | 통계적 판단 |
|---|---|
| 그래프에 지속적인 상승 또는 하락 추세가 없음 | 평균이 일정 |
| 과거의 변동폭과 현재의 변동폭이 같음 | 분산이 시점에 독립적 |
| 계절성이 없음 | 공분산이 시차에 의존적이나 시점에 독립적 |

ML/DL Study,기록📝