Confusion Matrix
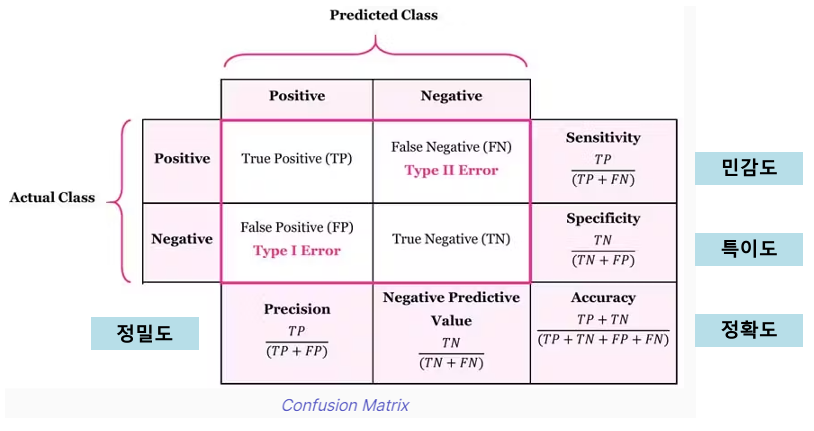
- 정확도 (Accuracy)
전체 예측한 것 중 올바른 예측의 비율 - 정밀도 (Precision)
긍정(positive)으로 예측한 것 중 실제로 맞힌 비율 - 민감도 (Sensitivity, Recall 재현율)
실제 positive를 얼마나 잘 예측했는지를 나타내는 지표 - 특이도 (Specificity)
실제 negative를 얼마나 잘 예측했는지를 나타내는 지표
F1 Score
-불균형 데이터의 분류 문제에서의 평가척도로 사용
-정밀도와 민감도의 조화 평균. 낮은 값에 더 많은 가중치 부여
-데이터가 불균형한 상태에서 Accuracy로 성능을 평가하기엔 데이터 편향성이 나타나 성능 척도로 사용하기에는 부적합
-거짓양성과 거짓음성의 중요성 사이의 균형을 유지해야 하는 경우 사용
클래스 비대칭 데이터 처리
클래스 간 비대칭
-데이터 세트 내에서 한 클래스의 샘플 수가 다른 클래스에 비해 현저히 많거나 적은 경우
-이러한 비대칭 데이터는 모델이 다수 클래스에 치우쳐 학습하는 경향을 가지게 만들어 소수 클래스의 예측 성능이 저하될 수 있음
- 데이터 레벨에서의 접근 방법
- 오버샘플링
소수 클래스의 샘플을 증가시켜 데이터 세트의 균형을 맞추는 방법
SMOTE(Synthetic Minority Over-sampling Technique) 같은 기법을 사용하여 소수 클래스의 샘플을 합성적으로 생성 - 언더샘플링
다수 클래스의 샘플을 줄여 데이터 세트의 균형을 맞추는 방법
데이터 손실을 초래하 수 있으므로 주의
- 오버샘플링
- 알고리즘 레벨에서의 접근 방법
- 가중치 부여(Weighting)
소수 클래스의 샘플에 더 높은 가중치를 부여하여 모델 학습 과정에서 소수 클래스의 더 큰 영향력을 갖도록 하는 방법
- 가중치 부여(Weighting)
- 평가 지표의 선택
- 정밀도, 재현율 및 F1점수 사용
비대칭 데이터에서는 정확도만으로 모델 성능 평가가 적합하지 않음
정밀도와 재현율의 조화 평균인 F1 점수를 포함하여 전체적인 모델 성능 평가 필요
- 정밀도, 재현율 및 F1점수 사용
- 기타
- 코스트-센서티브 학습 (Cost-sensitive Learning)
소수 클래스의 오류에 더 높은 비용을 부여
모델이 소수 클래스의 샘플을 더 주의 깊게 처리하도록 함 - 특징 선택 (Feature Selection)
소수 클래스를 더 잘 구별할 수 있는 가장 유의미한 특징 선택
- 코스트-센서티브 학습 (Cost-sensitive Learning)

ML/DL Study,기록📝