Pandas
- 파이썬 데이터 분석 라이브러리 중 하나로 데이터 조작, 정제, 분석, 시각화 등을 위한 다양한 기능 제공
- Series와 DataFrame이라는 자료형을 이용하여 데이터를 처리
- Series :인덱스와 값으로 이루어진 1차원 데이터를 다루기 위한 객체
- DataFrame : 행과 열로 이루어진 2차원 데이터를 다루기 위한 객체
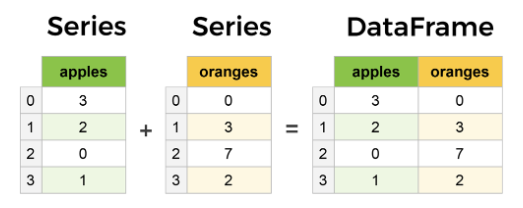
Pandas 기본 사용법
-
데이터 불러오기
판다스에서는 CSV, Excel, SQL 등 다양한 형태의 데이터를 불러올 수 있다.import pandas as pd # CSV 파일 불러오기 df = pd.read_csv('data.csv') # Excel 파일 불러오기 df = pd.read_excel('data.xlsx') -
데이터 살펴보기
-
info() : 데이터 프레임의 정보 출력, 데이터 프레임의 크기, 데이터 타입, 결측치 등의 정보 확인 가능
-
head() : 데이터 프레임의 첫 5줄을 출력
-
describe() : 데이터 프레임의 요약 통계량을 출력
# 데이터 프레임 정보 확인하기 df.info() # 데이터 프레임 일부 데이터 보기 df.head() # 데이터 프레임 요약 통계량 보기 df.describe()
-
-
데이터 선택
-특정 열을 선택할 때는 데이터 프레임의 열 이름을 사용
-특정 행을 선택할 때는 loc[] 함수를 사용, loc[] 함수는 행의 이름 또는 인덱스를 사용# 열 선택 df['열 이름'] # 여러 개의 열 선택 df[['열 이름 1', '열 이름 2', ...]] # 행 선택하기 df.loc[행 이름 또는 인덱스] # 여러 개의 행 선택하기 df.loc[[행 이름 또는 인덱스 1, 행 이름 또는 인덱스 2, ...]] -
데이터 필터링
-
조건 필터링 : [] 연산자와 조건식을 이용
-
isin() : 특정한 값이 포함된 데이터만 선택
# 조건 필터링 df[조건식] # isin() 함수 이용 df[df['열 이름'].isin([값1, 값2, ...])]
-
-
데이터 그룹화
- groupby() 함수 : 특정 열을 기준으로 데이터를 그룹화
# groupby() 함수 이용 df.groupby('열 이름') - 집계 함수 : 그룹화된 데이터에 집계 함수를 이용하여 다양한 처리 수행
# 집계 함수 이용하기 그룹화된 데이터.count() 그룹화된 데이터.sum() 그룹화된 데이터.mean() 그룹화된 데이터.median() 그룹화된 데이터.min() 그룹화된 데이터.max() 그룹화된 데이터.std() 그룹화된 데이터.var()
- groupby() 함수 : 특정 열을 기준으로 데이터를 그룹화

ML/DL Study,기록📝