
Orchestrator로 MySQL의 고가용성 및 장애 조치에 대해 살펴봅니다.
Topology recovery
테스트 방법은 아래 2가지 입니다. Automated recovery를 살펴보겠습니다.
- Manual recovery
- Automated recovery
실습 환경은 "Orchestrator로 MySQL High-Availability 구축하기" 를 참고 부탁드립니다.
Automated recovery
MySQL 환경은 아래와 같습니다.
- Master with Slaves (Single Replication)
- Binary Format : Row-based Type
- Asynchronous replication
.png)
A. orchestrator.conf.json
Automated recovery를 위해 Orchestrator의 설정 파일을 수정합니다.
- RecoverMasterClusterFilters : *
- PromotionIgnoreHostnameFilters : mysql-03
PromotionIgnoreHostnameFilters 항목은 master 승격시 대상에서 제외할 Hostname를 적습니다.
# AS-IS
"RecoverMasterClusterFilters": [
"_master_pattern_"
],
"PromotionIgnoreHostnameFilters": [],
# TO-BE
"RecoverMasterClusterFilters": [
"*"
],
"PromotionIgnoreHostnameFilters": ["mysql-03"],orchestrator를 재시작 합니다.
docker-compose restart orchestratorB. Graceful master promotion
mysql-01(master) 서버를 정지합니다.
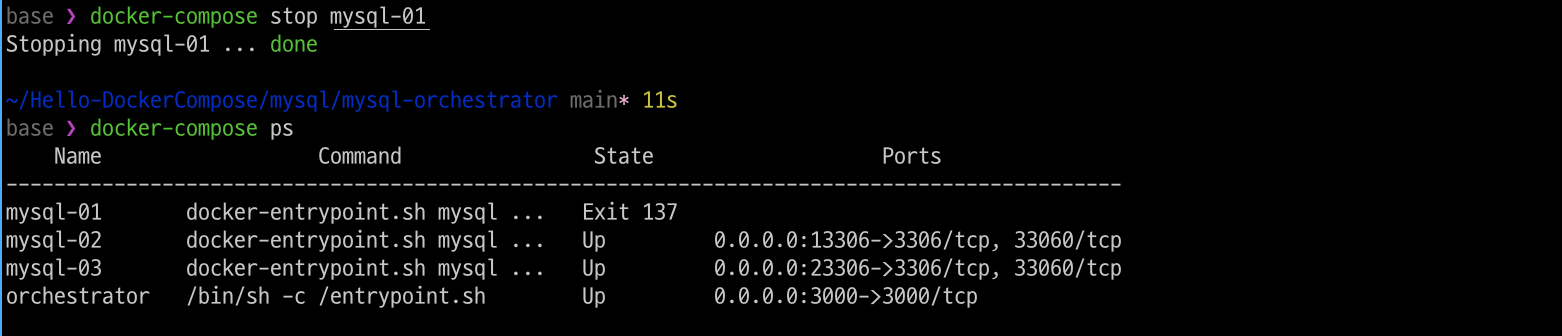
mysql-01서버가 Dead Master 상태인것을 확인할수 있습니다.
"Automated recovery" 모드의 경우 하트 이모티콘에 색이 채워져서 보입니다.
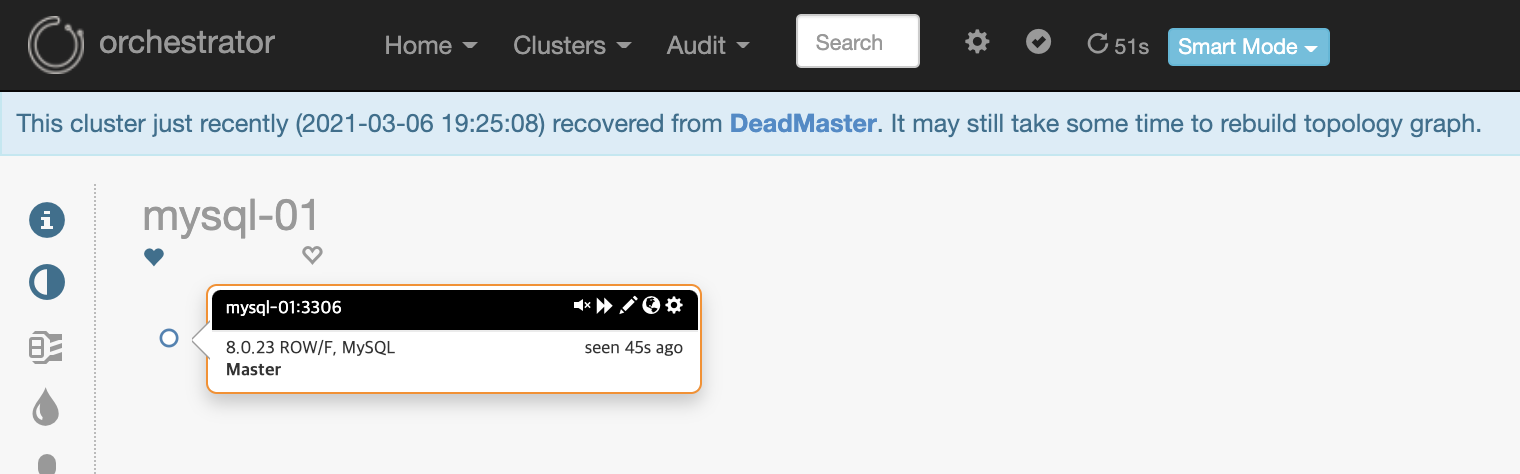
PromotionIgnoreHostnameFilters 환경설정 중 mysql-03을 예외처리 했기에 mysql-02서버가 master로 승격되었습니다. 그리고 mysql-03이 master로 승격된 mysql-02을 바라보고 있습니다.
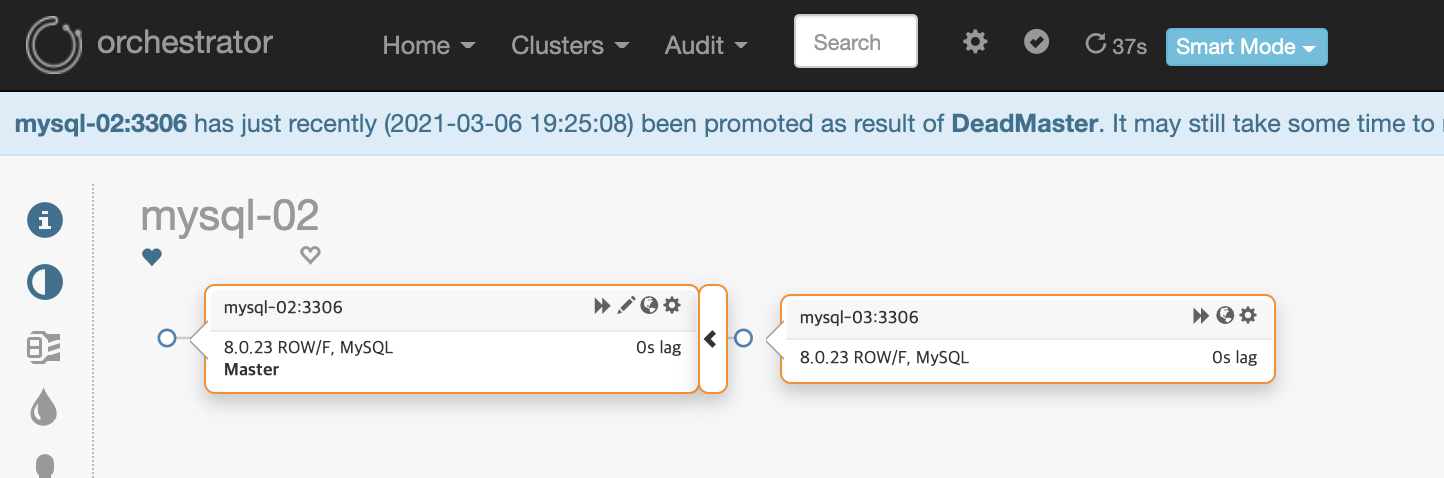
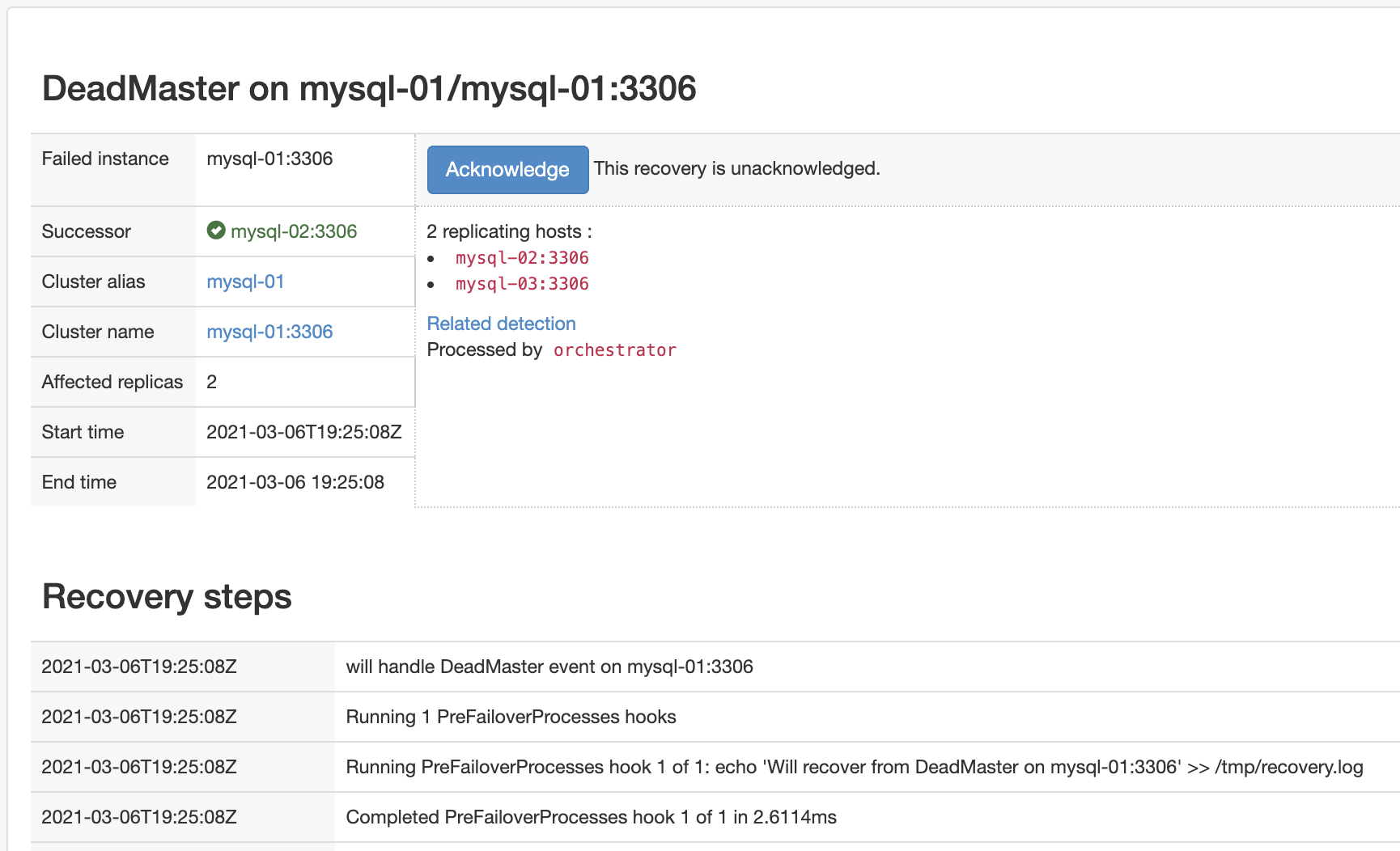
"Audit > Recovery" 메뉴를 선택합니다. 장애 조치를 마무리 했다면 Acknowledged를 선택하여 운영 모드로 전환 합니다.
C. mysql-01서버 replication 재구성
MySQL Replication 재구성을 진행합니다. 재구성은 이전 게시글의 내용과 동일하니 참고 부탁드립니다.
코드는 Github에서 확인 가능 합니다.

Data Engineer