Orchestrator로 MySQL의 고가용성 및 장애 조치에 대해 살펴봅니다.
Topology recovery
테스트 방법은 아래 2가지 입니다. Manual recovery를 살펴보겠습니다.
- Manual recovery
- Automated recovery
실습 환경은 "Orchestrator로 MySQL High-Availability 구축하기" 를 참고 부탁드립니다.
Manual recovery
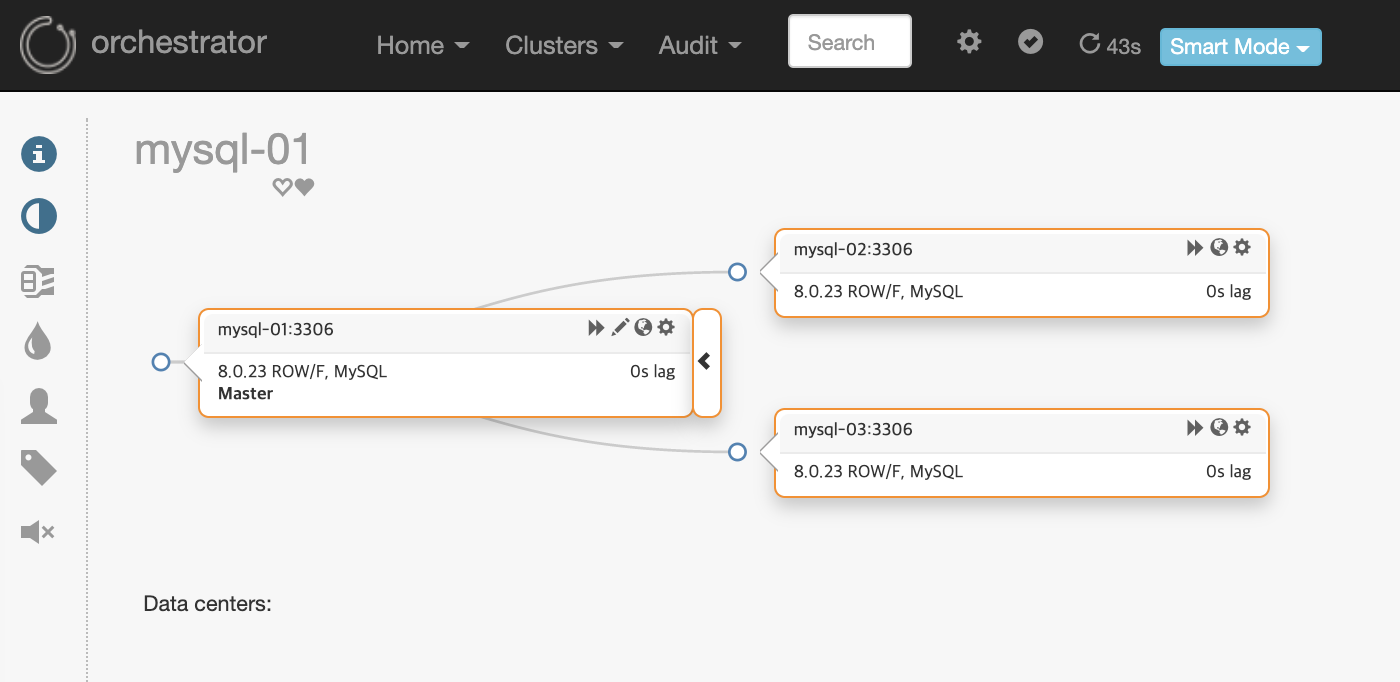
MySQL 환경은 아래와 같습니다.
- Master with Slaves (Single Replication)
- Binary Format : Row-based Type
- Asynchronous replication
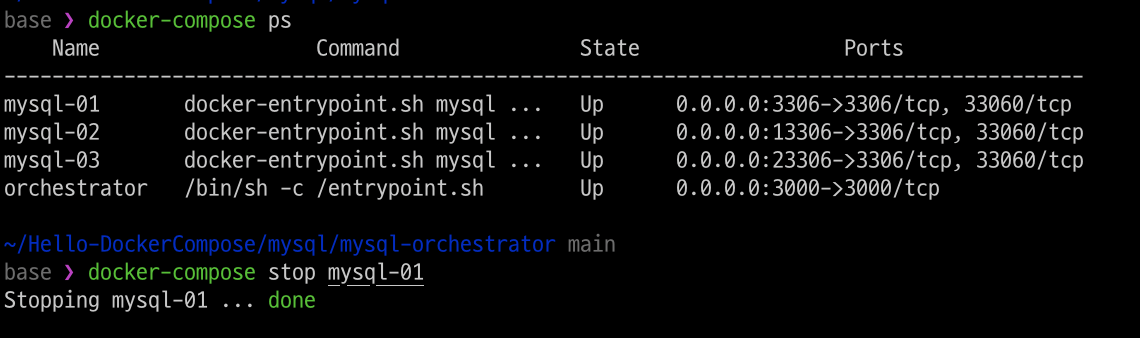
A. mysql-01, 장애 발생
MySQL Master 서버인 mysql-01을 종료합니다.
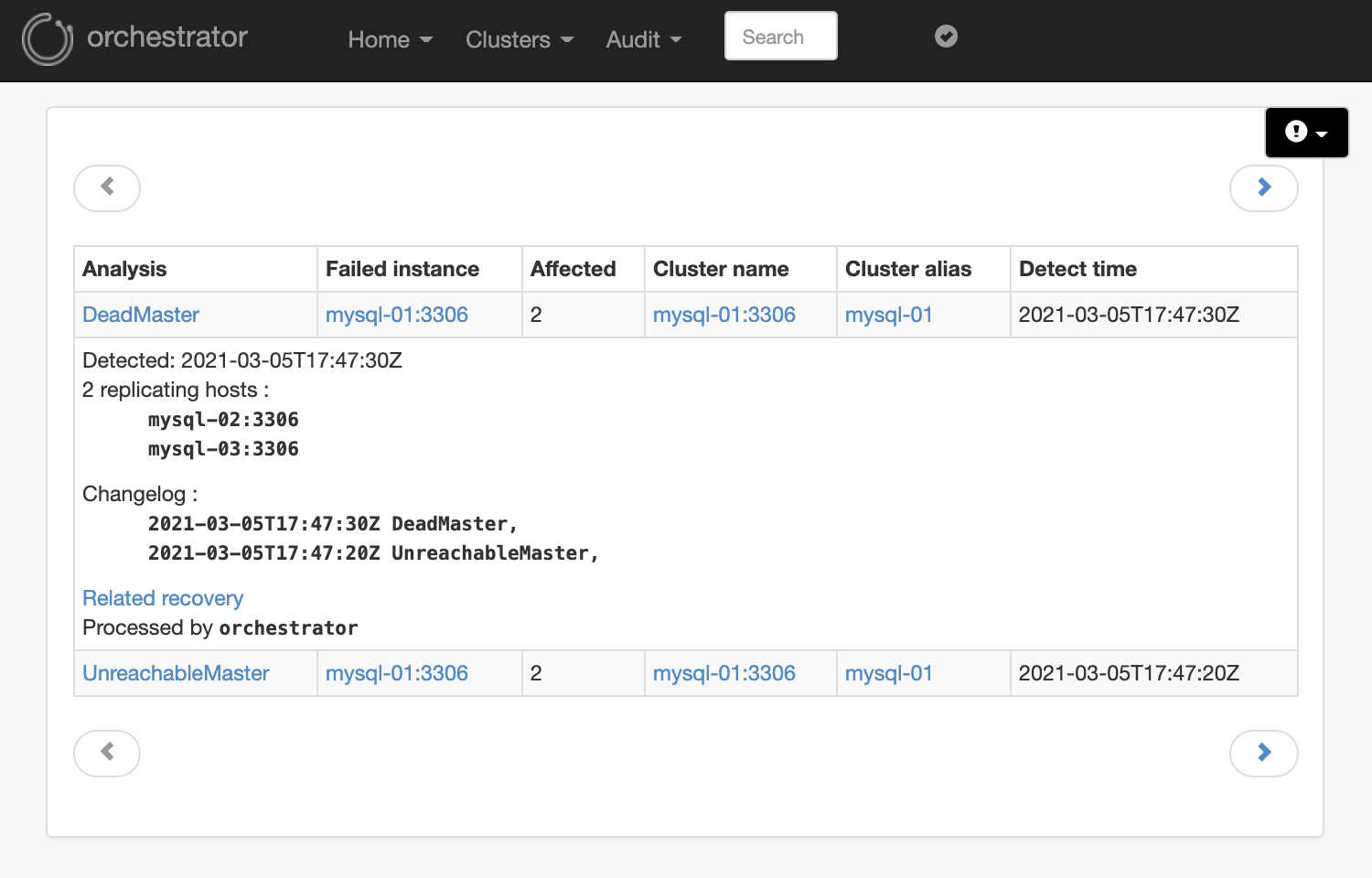
Topology 에서 mysql-01번가 DeadMaster 상태 인것을 확인할수 있습니다.
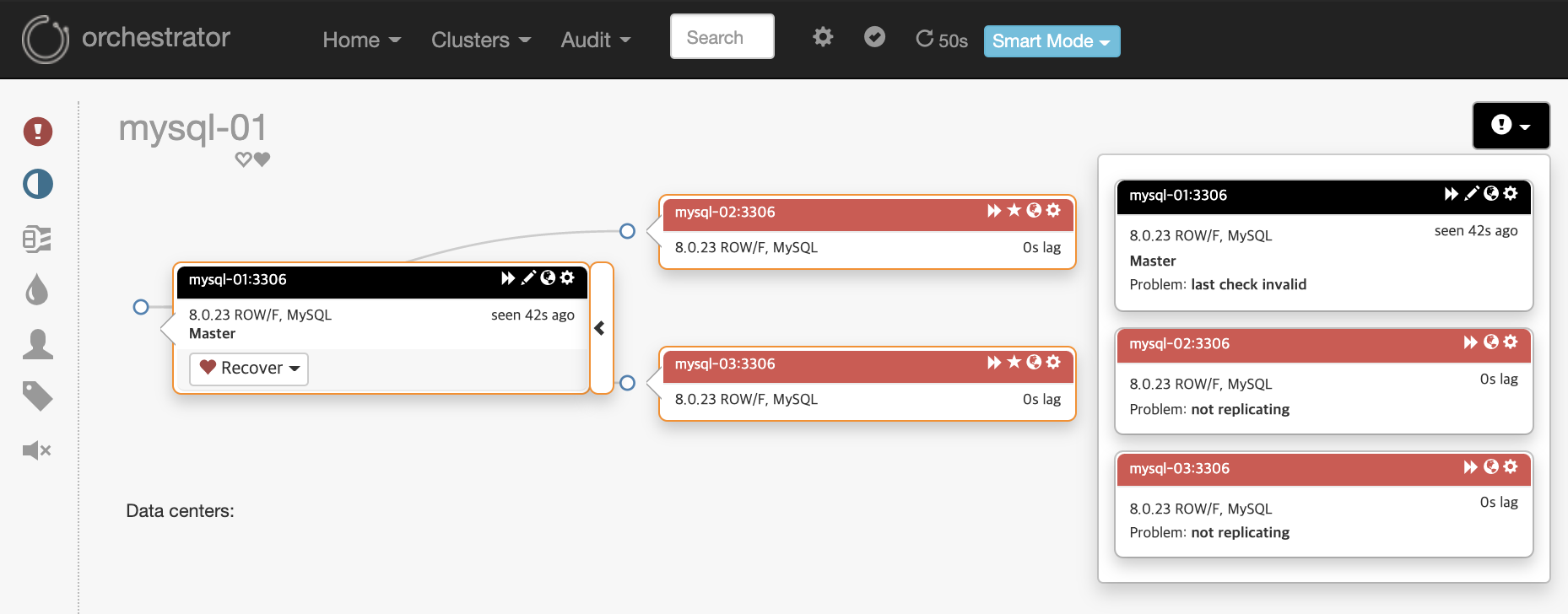
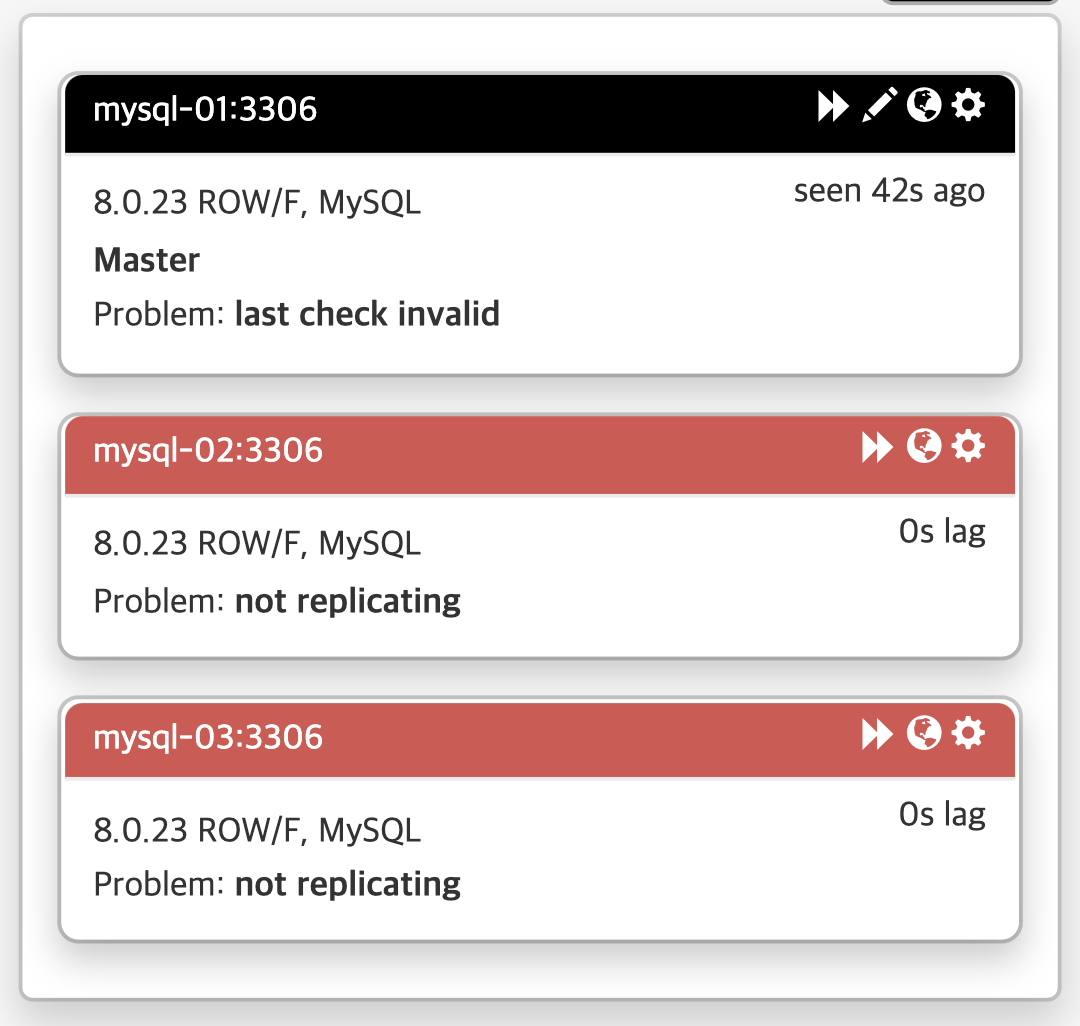
오른쪽에 각 노드(=서버)의 문제 상황에 대해 살펴볼수 있습니다.
- mysql-01 : last check invlid
- mysql-02, 03 : not replicating
"Audit > Failure Detection" 메뉴에서 장애 감시에관련 자세한 이력을 추적할수 있습니다.
- 2021-03-05 17:47:20 : Unreachable Master
- 2021-03-05 17:47:30 : Dead Master
B. mysql-01, Manual recovery
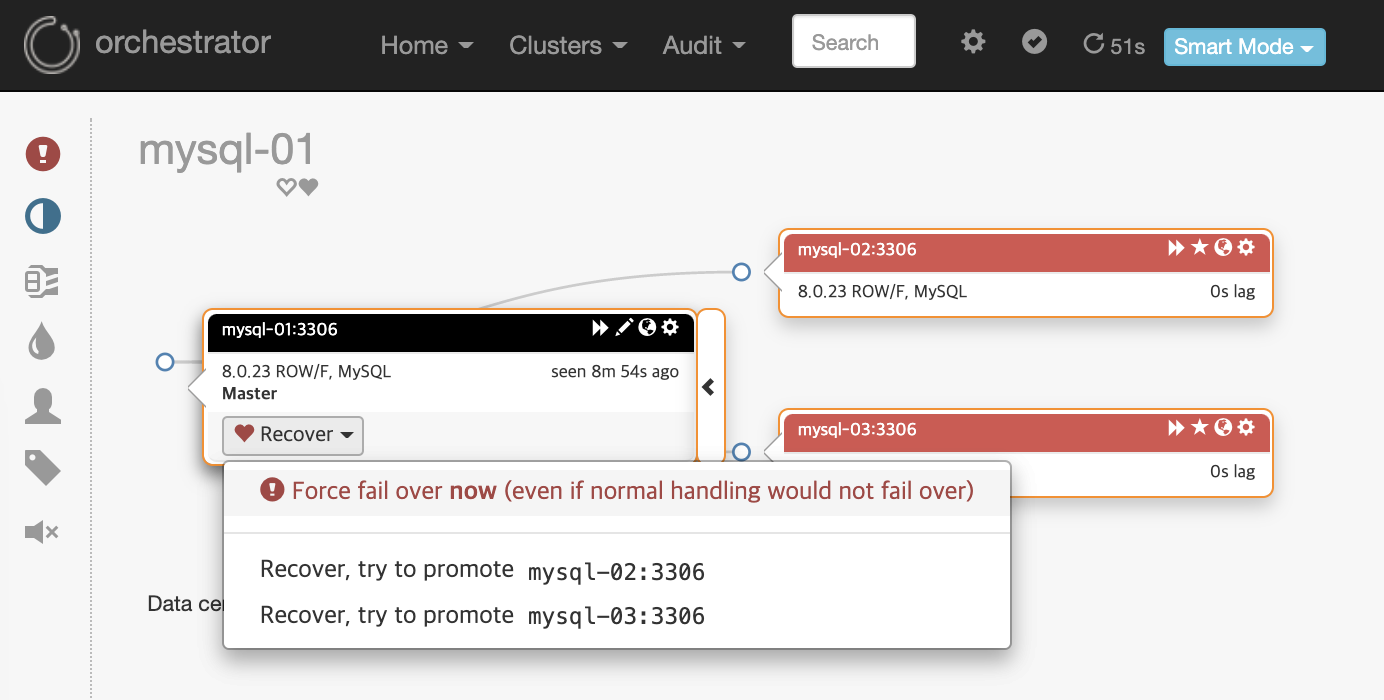
Dead Master 상태인 mysql-01 노드에서 Recover를 선택합니다. mysql-02 or 03 중 Master로 승격시킬 노드(=서버)를 선택합니다. mysql-03를 선택합니다.
- Recover, try to promote mysql-03:3306
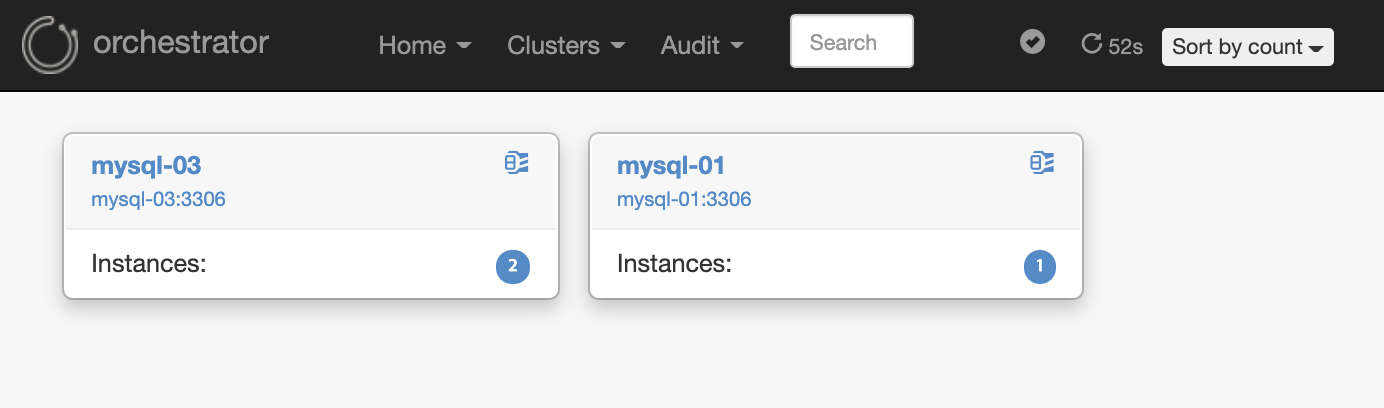
mysql-03과 mysql-01(=Dead Master)가 분리되어 보입니다. 오른쪽 하단에 인스턴스 수가 표시되네요. mysql-03을 선택합니다.
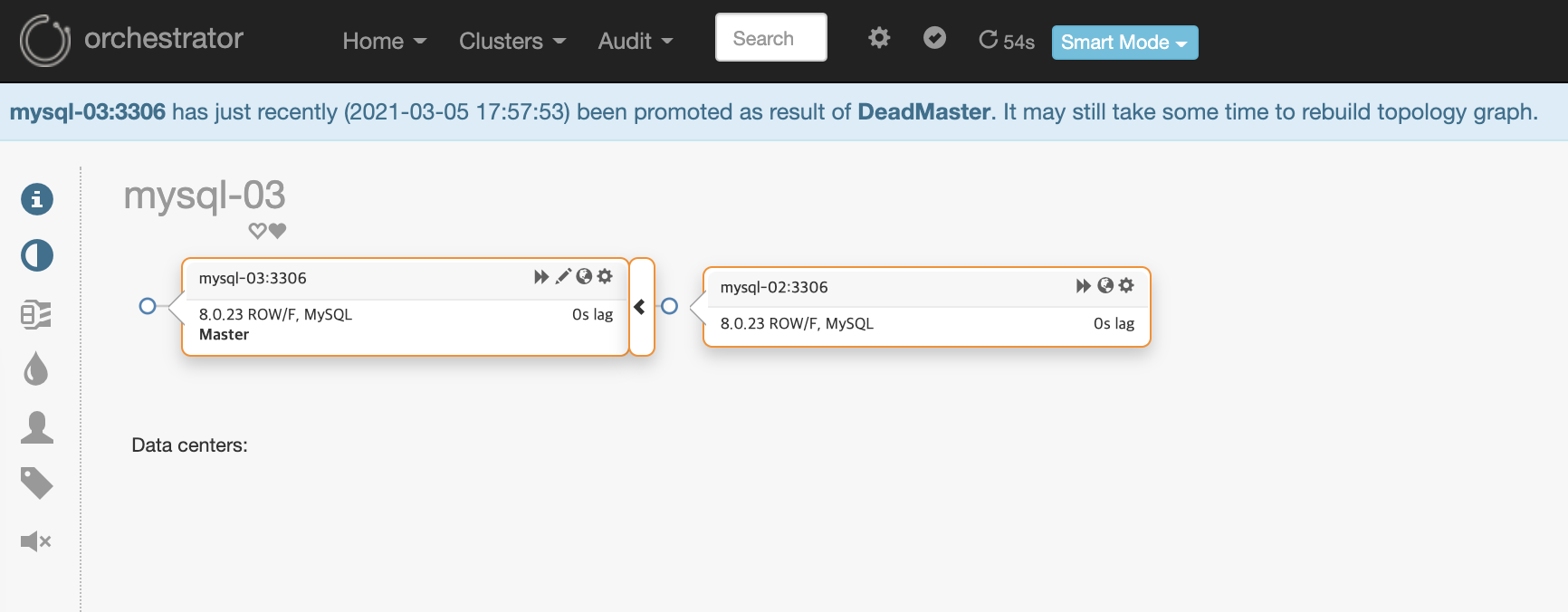
mysql-03을 master로 승격시킨 후 mysql-02 노드는 mysql-01이 아닌 mysql-03을 바라보도록 변경되었습니다.
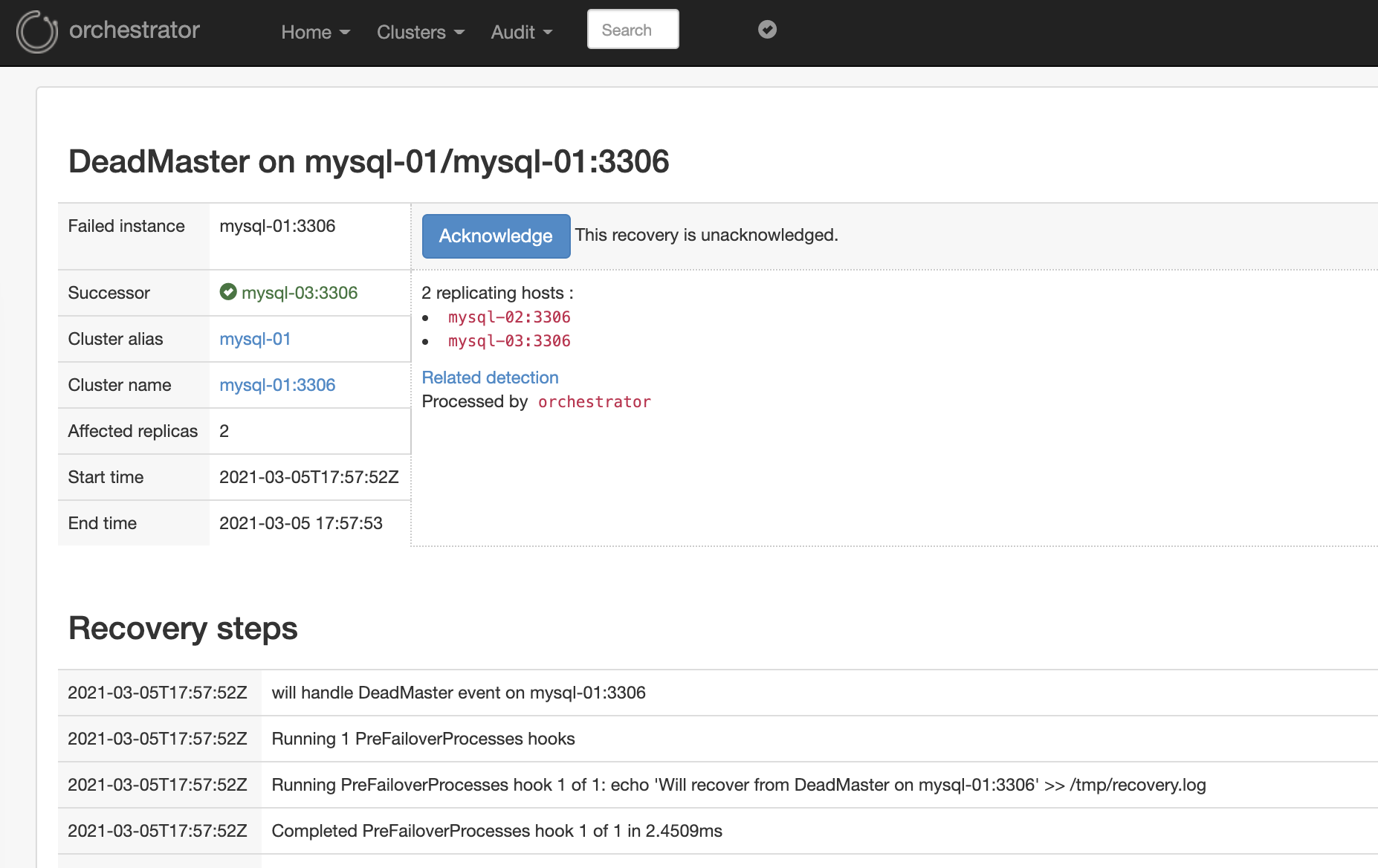
"Audit > Recovery" 메뉴를 선택합니다. Recovery steps에서 상세 로그에 대해 확인할수 있습니다.
장애 감지 및 복구 후 acknowledge를 선택해야 이후 장애 감지 또는 복구가 가능한 상태가 됩니다. acknowledge를 선택합니다.
C. mysql-01, replication 재구성
mysql-01(=Dead Master) 서버를 정상화 하고 MySQL Replication를 재구성 합니다.
mysql-01(=Dead Master) 서버를 재기동 합니다.
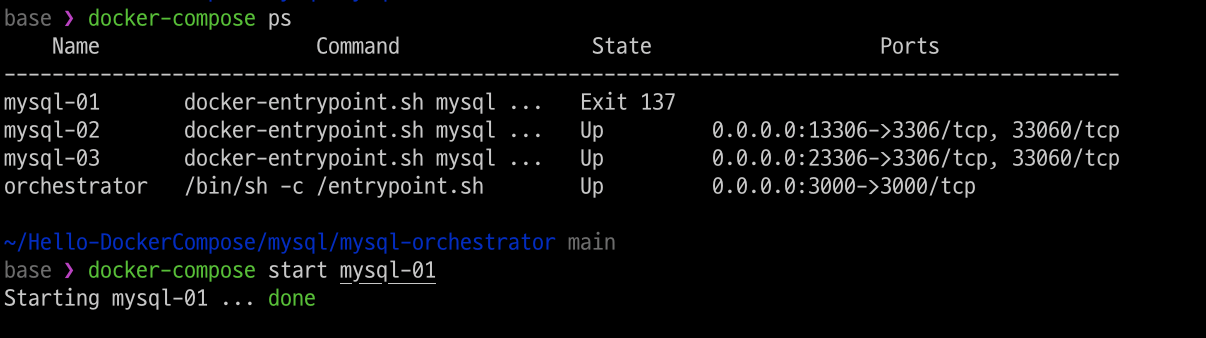
mysql-01(=Dead Master)가 mysql-02를 바라보도록 replication을 재구성 합니다.
docker exec -it -uroot mysql-01 /bin/bash
mysql -uroot -p
set global read_only=1;
select @@read_only;
change master to master_host='mysql-03', \
master_user='repl', master_password='repl', \
master_auto_position=1;
start slave;
show slave status\Gmysql-01 서버에서 replication 상태를 확인 합니다.
- Master_Host: mysql-03
- Slave_IO_Running: Yes
- Slave_SQL_Running: Yes
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: mysql-03
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000001
Read_Master_Log_Pos: 3120048
Relay_Log_File: mysql-01-relay-bin.000002
Relay_Log_Pos: 418
Relay_Master_Log_File: mysql-bin.000001
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 3120048
Relay_Log_Space: 630
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 300
Master_UUID: c1f00ced-7dae-11eb-b3dd-0242ac130005
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set: c1a6e078-7dae-11eb-939f-0242ac130003:1-10
Auto_Position: 1
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
Master_public_key_path:
Get_master_public_key: 0
Network_Namespace:
1 row in set, 1 warning (0.01 sec)Topology에서도 Replication이 정상화 된 부분을 확인할수 있습니다.
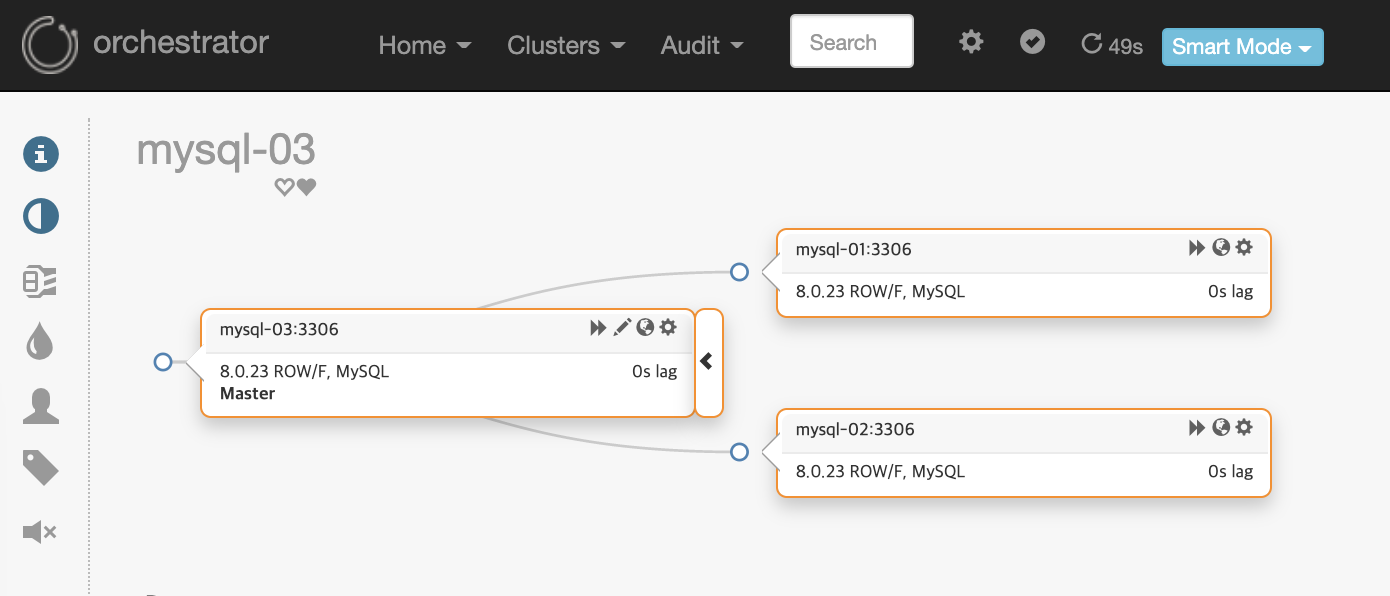
다음 글에서는 Orchestrator를 이용한 Automated recovery 실습을 해보도록 하겠습니다.
코드는 Github에서 확인 가능 합니다.
