 Orchestrator의 주요기능인 장애 감지 및 복구에 대해서 살펴봅니다.
Orchestrator의 주요기능인 장애 감지 및 복구에 대해서 살펴봅니다.
- Failure detection & recovery
- Topology refactored, Using the web interface
Failure detection & recovery
Failure detection
Orchestrator는 master 서버에 연결하거나 쿼리할 수 없을 때 master 를 탐색하고 경고를 보냅니다.
Orchestrator는 복제 토폴로지를 활용합니다. 서버 자체뿐만 아니라 복제본도 관찰합니다. 예를 들어, 비활성 master 장애 감지를 진단하려면 Orchestrator가 다음 두 가지를 모두 수행 해야합니다.
- Fail to contact said master
- Be able to contact master's replicas, and confirm they, too, cannot see the master.
오케스트레이터는 오류를 시간별로 검색하지 않고 복제 토폴로지 서버 자체를 여러 관찰자에 의해 검색합니다. 실제로 모든 마스터 복제본이 마스터에 연결할 수 없다는 데 동의하면 복제 토폴로지는 사실상 중단되고 페일오버는 정당화됩니다.
장애 감지 시나리오는 아래와 같습니다.
- DeadMaster
1.1 Master MySQL access failure
1.2 All of master's replicas are failing replication - DeadMasterAndReplicas
2.1 ... - DeadMasterAndSomeReplicas
- DeadMasterWithoutReplicas
- UnreachableMasterWithLaggingReplicas
- UnreachableMaster
- LockedSemiSyncMaster
- AllMasterReplicasNotReplicating
- AllMasterReplicasNotReplicatingOrDead
- DeadCoMaster
- DeadCoMasterAndSomeReplicas
- DeadIntermediateMaster
- DeadIntermediateMasterWithSingleReplicaFailingToConnect
- DeadIntermediateMasterWithSingleReplica
- DeadIntermediateMasterAndSomeReplicas
- DeadIntermediateMasterAndReplicas
- AllIntermediateMasterReplicasFailingToConnectOrDead
- AllIntermediateMasterReplicasNotReplicating
- UnreachableIntermediateMasterWithLaggingReplicas
- UnreachableIntermediateMaster
- BinlogServerFailingToConnectToMaster
상세 시나리오 내용은 공식 문서를 참고 합니다.
Topology refactored, Using the Web interface
Web UI를 통해 Topology를 살펴보고 리팩토링 하는 방법에 대해 알아보겠습니다.
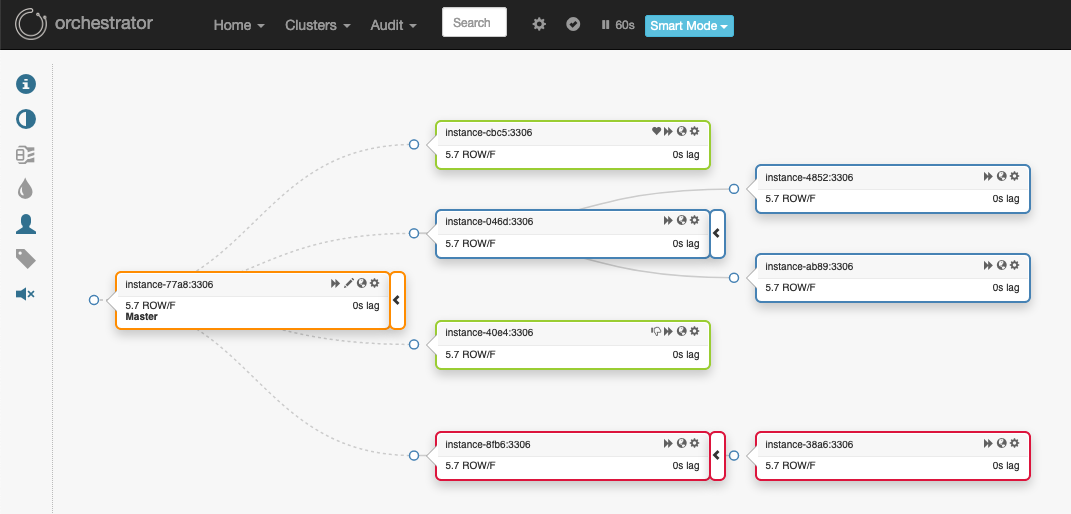
MySQL의 이중화 구성된 토폴리지를 한눈에 볼수 있습니다. 각 노드에 HostName, Port, 이진로그형식, 복제 지연 등 정보가 표시됩니다.
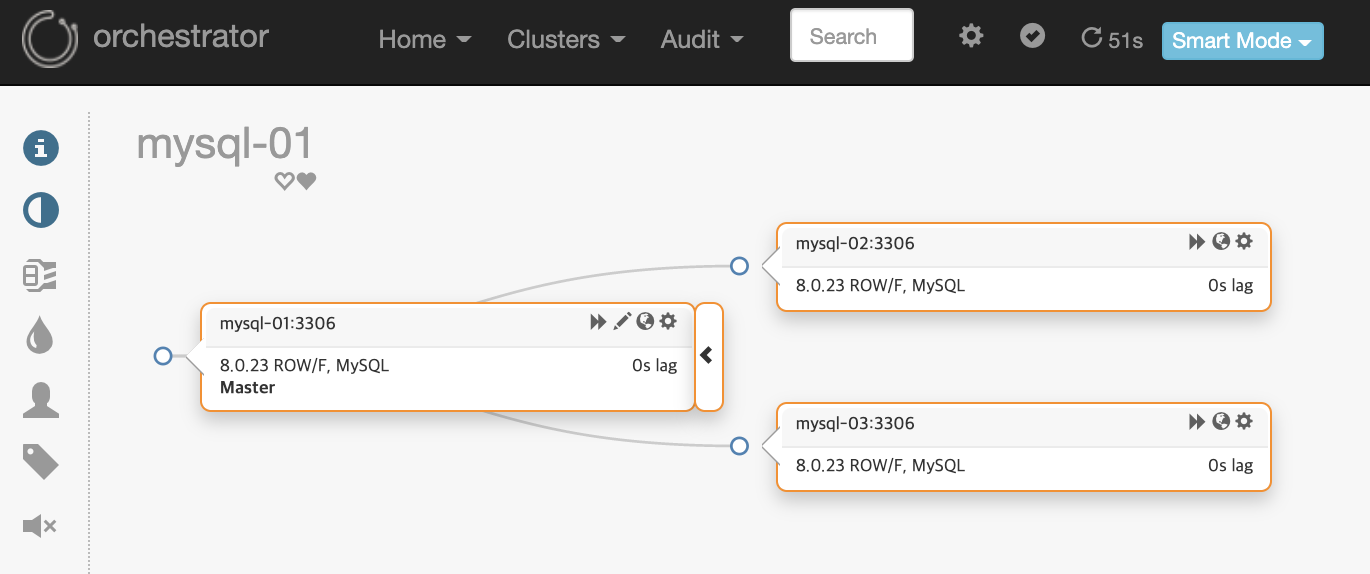
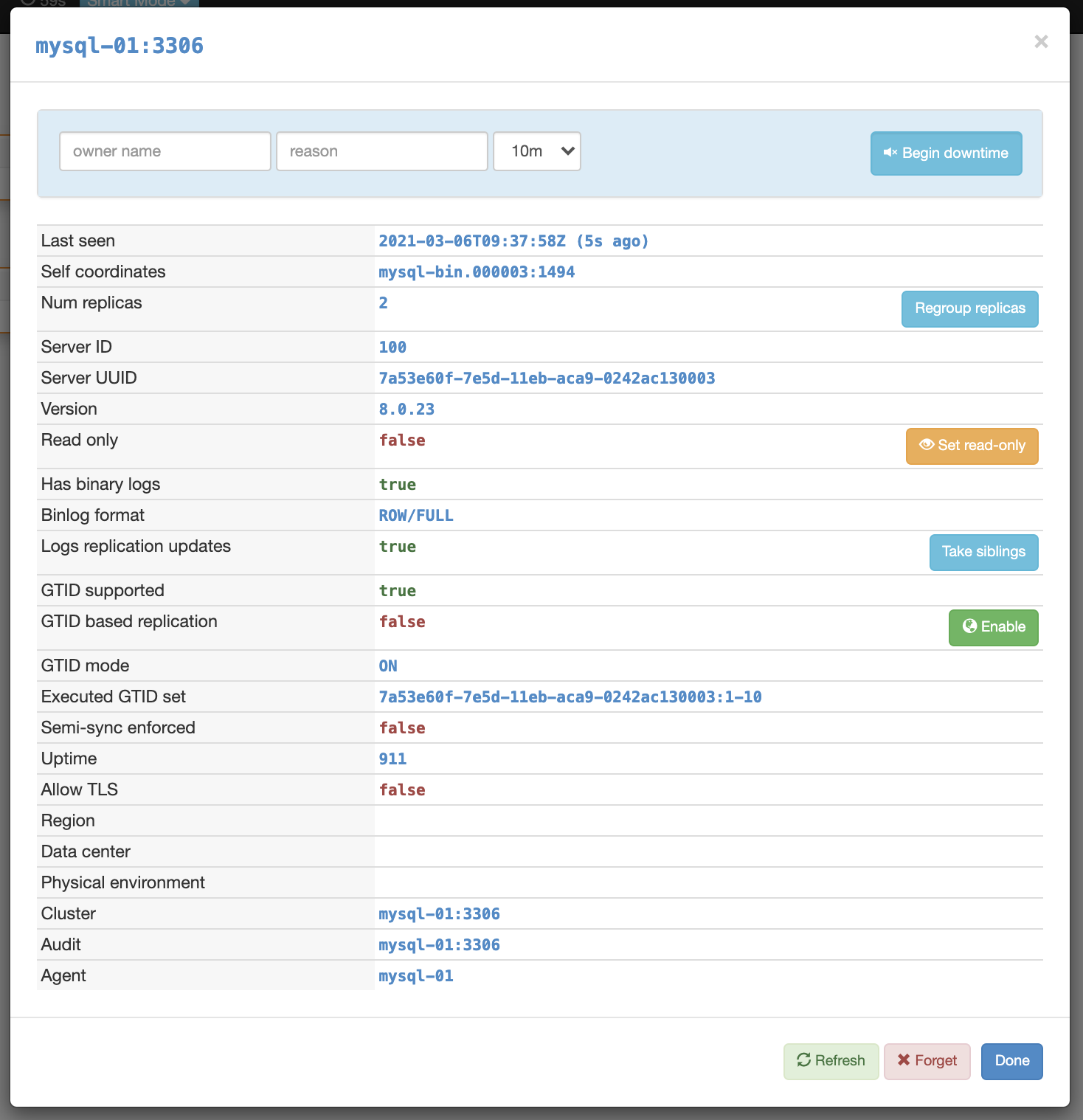
노드(=서버)의 오른쪽 설정 아이콘을 클릭하면 상세 정보 및 수행 가능한 작업 목록이 보입니다. 작업 목록은 인스턴스 시작/종료, 읽기 모드 설정/해제, Regroup replicas, 복제 중지/시작 등의 작업을 할수 있습니다.
A. Topology refactored:
Topology를 리팩토링합니다.
mysql-03 slave서버가 mysql-02서버를 바라보도록 노드를 선택 후 끌어 mysql-02 위에 놓습니다.
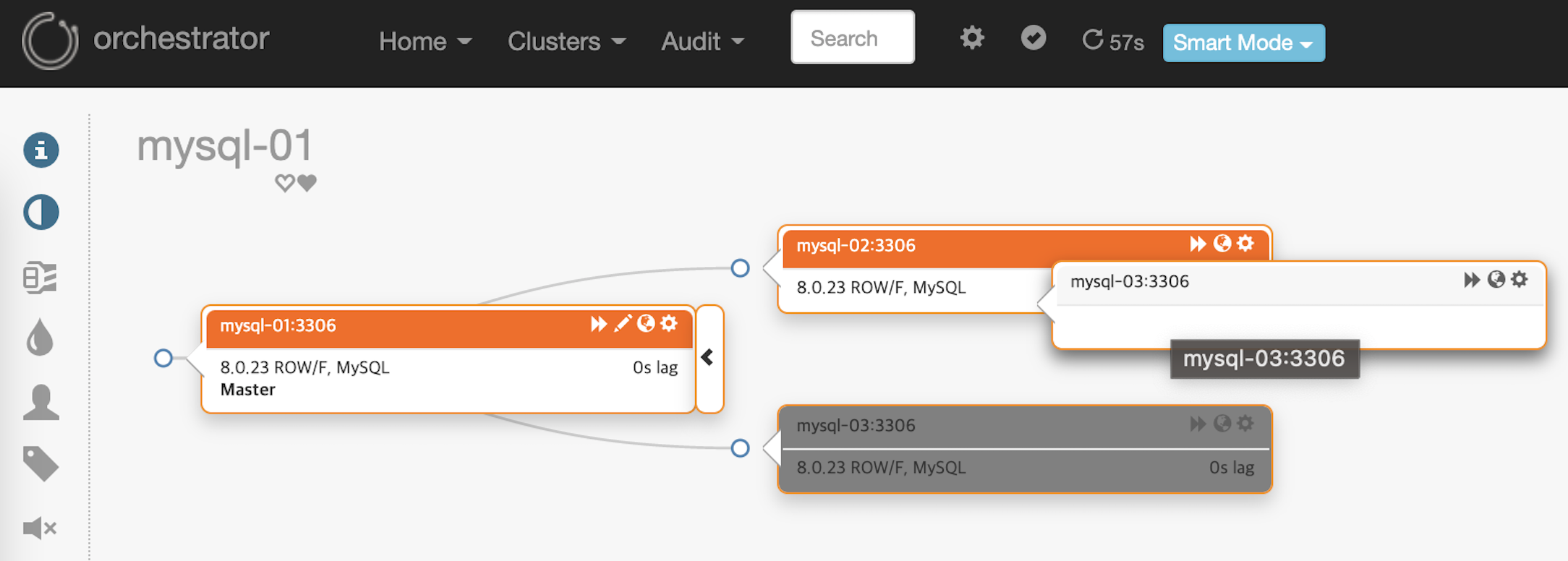
Topology가 아래와 같이 리펙토링 되었습니다.
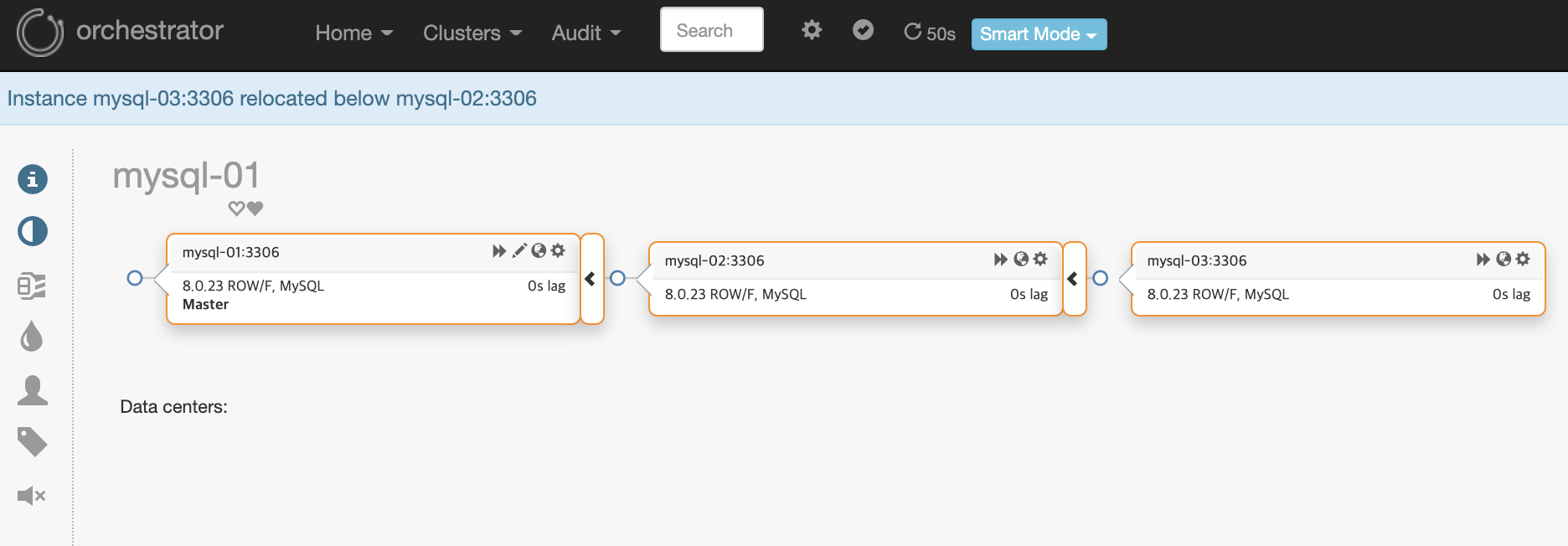
B. Dragging a master over its replica makes for a co-masters (master-master) topology:
master-master topology는 master를 복제본 중 하나로 끌어 두 개의 co-masters로 만들 수 있습니다.
mysql-01노드를 mysql-02노드 위에 끌어다 놓습니다.
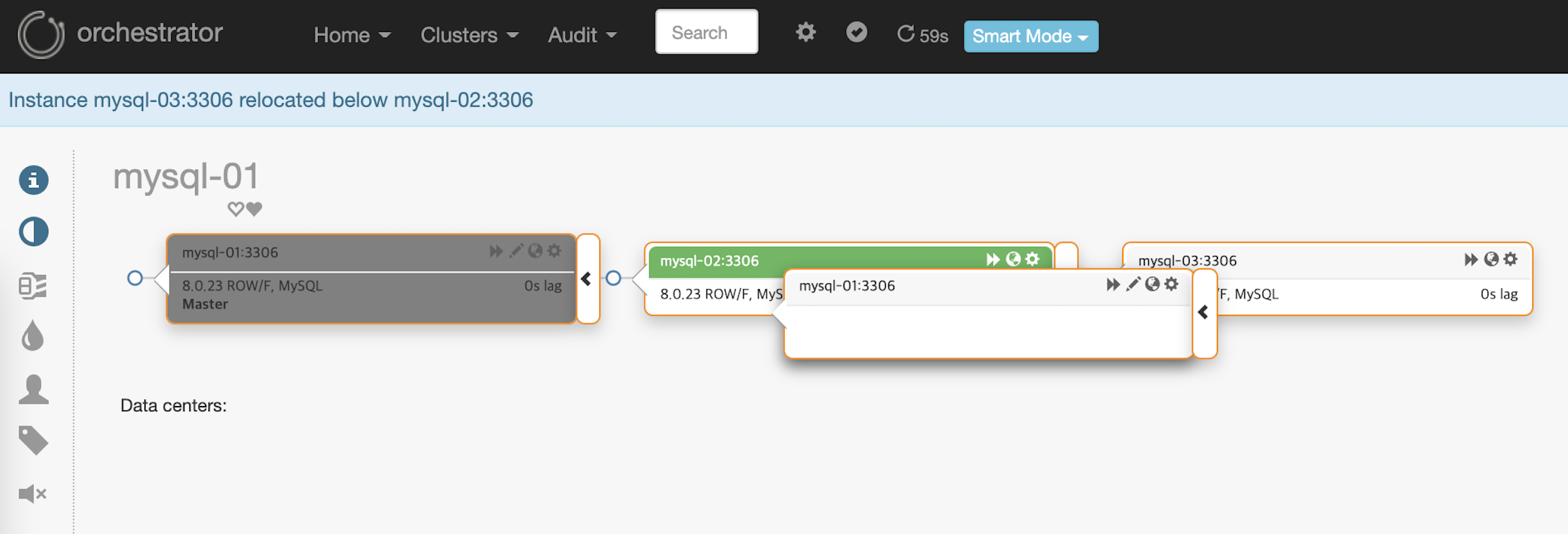
co-masters (master-master) topology가 구성되었습니다.
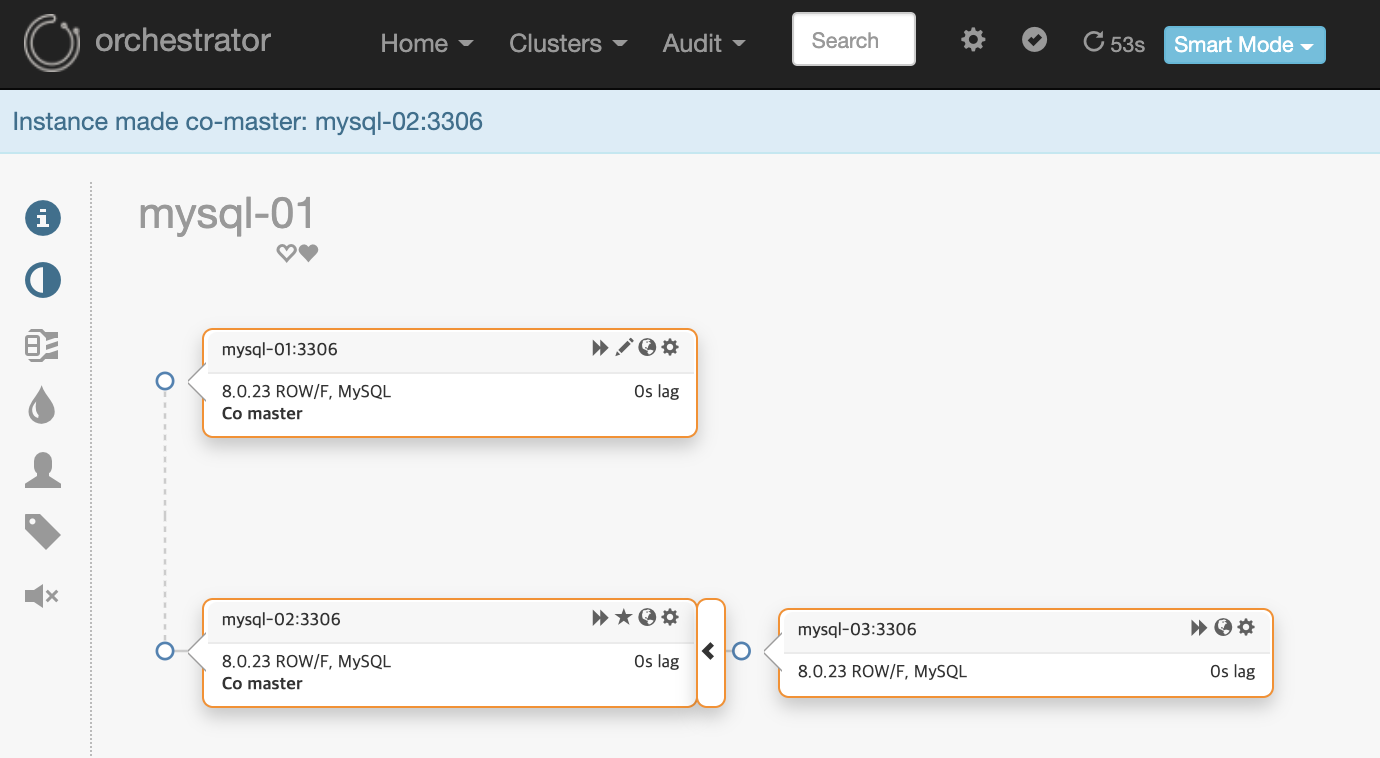
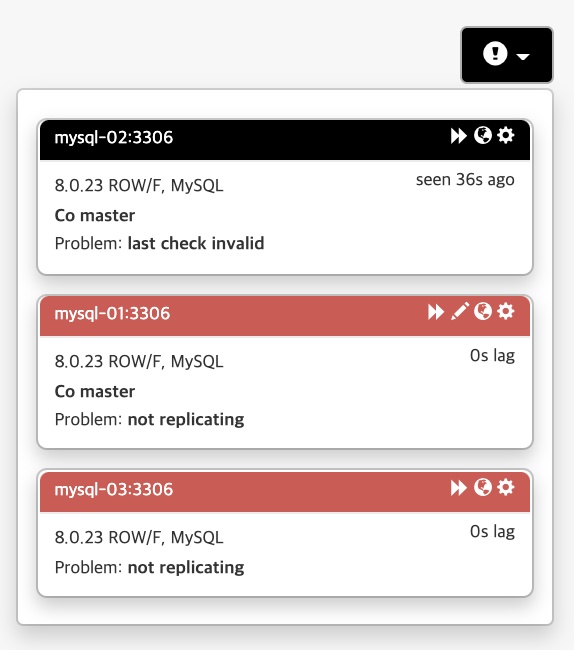
C. Orchestrator visually indicates replication & accessibility related problems:
Orchestrator는 복제 및 접근성 관련 문제를 시각적으로 나타냅니다
- 복제 지연
- 복제가 작동하지 않음
- 오랜 시간 동안 액세스하지 않은 인스턴스
- 인스턴스 액세스 실패
- 유지 보수 중 인스턴스
mysql-02 master 서버 하나를 중지합니다.

장애 감지 및 토폴리지의 상태를 시각화 됩니다.
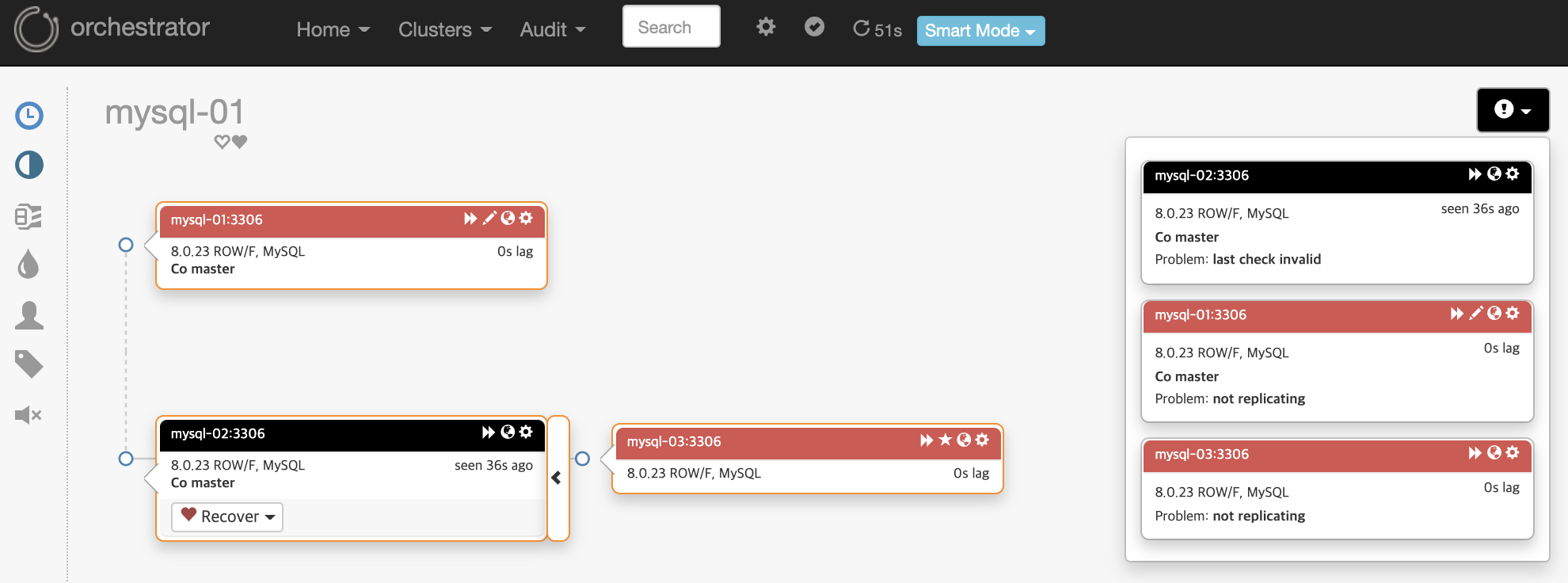
오른쪽을 보면 각 노드(=서버)의 문제 원인에 대해서 표현합니다.
다음 글에서는 Orchestrator를 이용한 Manual recovery 실습을 해보도록 하겠습니다.
코드는 Github에서 확인 가능 합니다.
