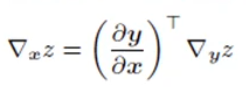[Deep Learning] 신경망 기초 - 다층 퍼셉트론
0. 신경망 기초
신경망 종류
- 전방 신경망과 순환 신경망
- 얕은 신경망과 깊은 신경망
- 결정론 신경망과 확률론적 신경망
- 결정론 : 모델의 매개 변수와 조건에 의해 출력이 완전히 결정되는 신경망
- 확률론적 : 고유의 임의성을 가지고 매개변수와 조건이 같더라도 다른 출력을 가지는 신경망
- 다양한 신경망 구조
1. 퍼셉트론
- node, weight, layer와 같은 새로운 개념의 구조 도입
- 학습 알고리즘 제안
- 깊은 인공신경망을 포함한 현대 인공신경망의 토대
- 퍼셉트론은 선형 분류만 가능하다 (선형으로 완벽하게 분리된다는 가정하에 진행)
구조
- 입력
- i번째 노드는 특징 벡터 x의 요소 xi를 담당
- 항상 1이 입력되는 편향 노드 포함 (threshold를 0으로 맞춰주기 위해)
- 연산
- 입력과 출력 사이에 연산하는 구조
- i번째 입력 노드와 출력 노드를 연결하는 edge는 가중치 wi를 가진다
- 퍼셉트론은 단일 층 구조라고 간주
- 출력
- 한개의 노드에 의한 수치(-1 또는 +1) 출력
동작
- 선형 연산 -> 비선형 연산
- 선형 : 입력값과 가중치를 곱하고 모두 더해 s를 구한다
- 비선형 : 활성함수 τ(s)를 적용
- 활성함수로 step function 사용(출력 +1 또는 -1)
- 결정 직선, 결정 평면, 결정 초평면은 특정 공간을 두 부분으로 분할하는 분류기
행렬 표기
- s=wTx+w0
- 여기서 x=(x1,x2,...,xd)T, w=(w1,w2,...,wd)T
- 편향 항을 벡터에 추가하면
- s=wTx
- 여기서 x=(1,x1,x2,...,xd)T, w=(w0,w1,w2,...,wd)T
- 퍼셉트론 동작을 아래와 같이 표현할 수 있다
- y=τ(wTx)
학습
- 일반적인 분류기의 학습 과정
- 과업 정의와 분류 과정의 수학적 정의 (가설 설정)
- 목적함수 J(θ) 정의
- 목적함수J(θ) 를 최소화하는 θ를 찾기 위한 최적화 방법 수행
목적함수 정의 (단계 1+2)
- 퍼셉트론의 매개변수를 w=(w0,w1,w2,...,wd)T라 표기하면 매개변수 집합은 θ=w
- 목적합수를 J(θ) 또는 J(w)로 표기
- 퍼셉트론 목적 함수의 상세 조건
- J(w)≥0
- w가 최적이면 J(w)=0
- 틀리는 샘플이 많은 w일수록 J(w)는 큰 값을 가진다
경사하강법
- 최소 목적함수의 기울기를 이용하여 반복 탐색하여 극값을 찾는다
- 미분값 활용
- 경사도 계산
- 일반화된 가중치 갱신 규칙 θ=θ−ρg를 적용하려면 경사도 g가 필요
- 편미분을 통해 구한다
- 델타 규칙 : wi=wi+ρxk∈Y∑ykxki
- 학습률
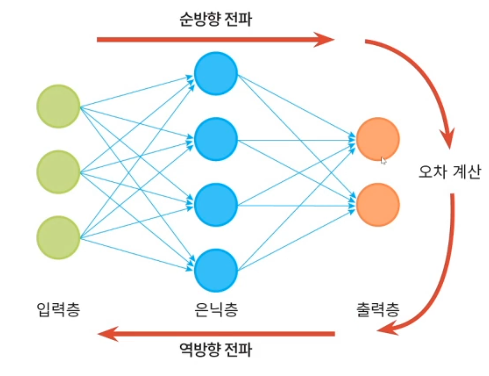
2. 다층 퍼셉트론
- 퍼셉트론 : 선형 분류기의 한계
- 다층 퍼셉트론의 핵심 아이디어
- 은닉층 : 유리한 새로운 특징 공간으로 변환
- 시그모이드 활성함수 : 출력이 연속값
- 오류 역전파 알고리즘 : 한층씩 gradient를 계산하고 가중치를 갱신
특징 공간 변환
- XOR 문제
- 퍼셉트론 2개를 병렬 결합하면 원래 공간을 새로운 특징 공간으로 변환
- 새로운 특징 공간에서 선형 분리 가능
- 다층 퍼셉트론의 용량
- p개의 퍼셉트론을 결합하면 p차원 공간으로 변환
활성 함수
- 계단 함수 : 영역을 점으로 변환
- 그외 활성함수 : 영역을 영역으로 변환
- 로지스틱 시그모이드 (0 ~ 1)
- 하이퍼볼릭 탄젠트 시그모이드 (-1 ~ 1)
- softmax와 ReLU (0 이후에 0~무한)
- 대표적인 비선형 함수인 s자 모양의 sigmoid를 활성함수로 사용
- 활성 함수에 따른 다층 퍼셉트론의 공간 분할 능력 변화
- 일반적으로 은닉층에서 logistic sigmoid를 활성함수로 많이 사용
- s자 모양의 넓은 포화곡선은 경사도 기반의 학습(오류 역전파)를 어렵게 한다(gradient vanishing 문제) -> 따라서 깊은 신경망에서는 ReLU 활용
구조
- d+1 개의 입력 노드, c개의 출력 노드
- p개의 은닉 노드 : p는 hyper-parameter
- p가 너무 크면 과잉적합, 너무 작으면 과소 적합 -> hyper-parameter 최적화
- 다층 퍼셉트론의 매개변수 (가중치)
- 범용적 근사 이론
- 하나의 은닉층은 함수의 근사를 표현
- 다층 퍼셉트론도 공간을 변환하는 근사 함수
- 얕은 은닉층의 구조
- 지수적으로 더 넓은 폭이 필요할 수 있다
- 일반적으로 깊은 은닉층의 구조가 좋은 성능을 가진다
동작
- 특징 벡터 x를 출력 벡터 o로 mapping하는 함수로 간주할 수 있다
- 깊은 신경망은 layer가 4개 이상일때
- o=τ(U2τh(U1x))
- 은닉층은 특징 추출기
- 은닉층은 특징 벡터를 분류에 더 유리한 새로운 특징 공간으로 변환
- 현대 기계학습에서는 특징 학습이라고 부른다
3. 오류 역전파 알고리즘
목적 함수 정의
- 훈련 집합
- 모든 샘플을 옳게 분류하는 함수 f를 찾는 일
- 목적함수 : 평균 제곱 오차
- 연쇄 법칙의 구현
- 반복되는 부분식들을 저장하거나 재연산을 최소화
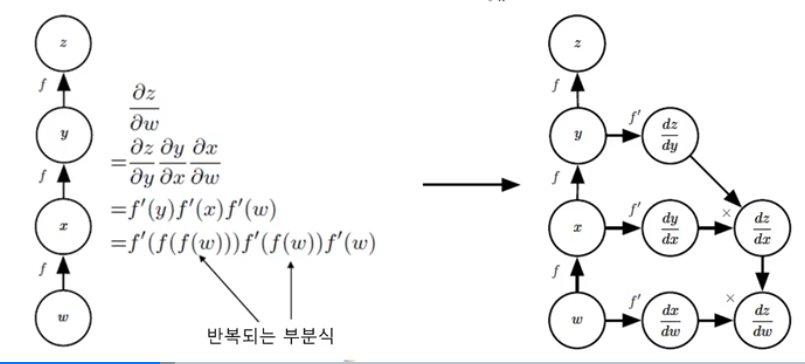
- 연쇄법칙 의미
- 출력값이 바뀌면 에러가 얼마나 바뀔까?
- 활성함수를 변경했을 때 출력값이 어떻게 바뀔까?
- 가중치를 변경했을 때 활성함수값은 어떻게 바뀔까?
- 목적함수 J(θ)=J(U1,U2)의 최저점을 찾아주는 경사하강법
- U1=U1−ρ∂U1∂J
- U2=U2−ρ∂U2∂J
- 출력의 오류를 역방향으로 전파하며 경사도를 계산하는 알고리즘
- 단일 노드의 역전파
- out = f(in)
- ∂in∂E=∂out∂E⋅∂in∂out=∂out∂E⋅f′(in)
- 곱셈의 역전파
- out=in1⋅in2
- ∂in1∂E=∂out∂E⋅∂in1∂out=∂out∂E⋅in2
- ∂in2∂E=∂out∂E⋅∂in2∂out=∂out∂E⋅in1
- 덧셈의 역전파
- out=i∑ini
- ∂ini∂E=∂out∂E⋅∂ini∂out=∂out∂E⋅1
- s자 모양의 활성 함수의 역전파
- out=σ(in)
- ∂in∂E=∂out∂E⋅∂in∂out=∂out∂E⋅σ′(in)=∂out∂E⋅[σ(in)(1−σ(in))]
- 최대화의 역전파(ReLU 형태)
- $out = max{in_i}
- ∂ini∂E=∂out∂E⋅∂in(0또는1)∂out=∂out∂E또는0
- ini가 max일 때만 전달된다
- 전개 fanout의 역전파
- 실제 역전파의 예
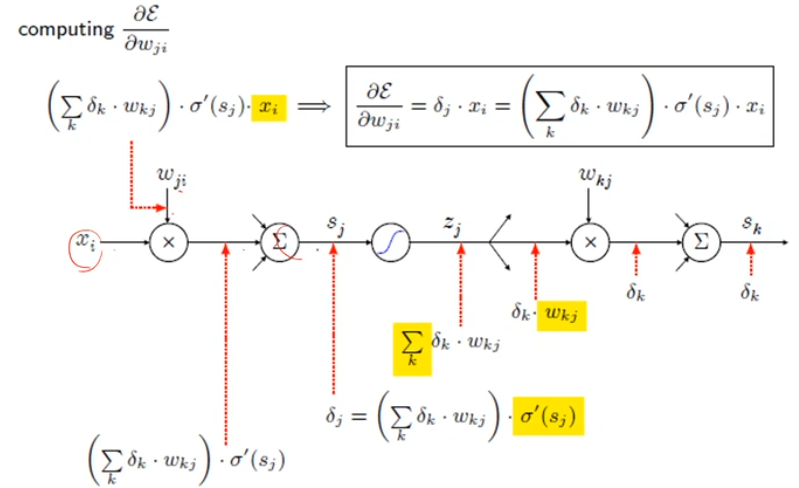
- 오류 역전파 미분의 연쇄 법칙을 이용
- 벡터이기 때문에 야코비안 행렬과 경사도를 곱한 연쇄 법칙을 얻어서 구한다
- 벡터끼리의 미분은 야코비안으로 표현 (벡터와 스칼라의 미분을 gradient)