[Deep Learning] 신경망 기초 - 인공지능과 기계학습
0. 인공지능이란?
- 인간의 학습능력과 추론 능력, 지각 능력, 자연언어의 이해능력 등을 컴퓨터 프로그램으로 실현한 기술
- 음성인식, 추천시스템, 자율주행, 실시간 객체 인식, 로봇, 번역 등의 기술
history
- 1940 ~ 1960년
- 인공지능의 시작 : 사람인지 기계인지 인식하지 못할 정도로
- 1980 ~
- 2000 ~
1. 기계 학습의 정의
- 학습이란?
- 경험의 결과로 나타나는 비교적 지속적인 행동의 변화나 그 잠재력의 변화 또는 지식을 습득하는 과정
- 기계 학습이란?
- 어떤 컴퓨터 프로그램이 T라는 작업을 수행한다.
- 이 프로그램의 성능을 P라는 척도로 평가했을 때
- 경험 E를 통해 성능이 개선된다면
- 이 프로그램은 학습을 한다고 말할 수 있다
- 지식 기반 -> 기계 학습 -> 심층 학습 (표현 학습)
- 데이터 중심
- 문제와 예측
- 예측 : 회귀(목표치가 실수), 분류(종류의 값)
- 데이터
- 훈련 data
- test data
- y=wx+b
- 훈련
- 최적의 매개변수를 찾는 작업
- 처음은 임의의 매개변수 값에서 시작하지만 개선하여 정량적인 최적 성능에 도달
- 추론
- 훈련을 마치면 추론 수행
- 새로운 특징에 대응되는 목표치의 예측에 사용
- 기계학습의 궁극적인 목표
- 훈련집합에 없는 새로운 데이터에 대한 오류 최소화
- 테스트 집합에 대한 높은 성능을 일반화 능력이라고 한다
- 기계학습의 필수 요소
- 데이터
- 데이터 규칙 존재
- 수학적으로 설명 불가능
2. 특징 공간에 대한 이해
1차원과 2차원 특징 공간
- 모든 데이터는 정량적으로 표현되며, 특징 공간 상에 존재
- 1차원 특징 공간
- 2차원 특징 공간 : 특징 벡터 표기
- 다차원 특징 공간 : 특징의 개수가 여러개
다차원 특징 공간
- d차원 데이터 : 특징 벡터 표기
- x=(x1,x2,...,xd)T
- 직선 모델을 사용하는 경우 매개변수 수 : d+1
- 2차 곡선 모델을 사용하는 경우 : d2+d+1
- 거리 측정 : 유클리드 거리 등
특징 공간 변환과 표현 학습
- 차원의 저주
- 차원이 높아짐에 따라 발생하는 현실적인 문제들
- 차원이 높아질수록 유의미한 표현을 찾기 위해 지수적으로 많은 데이터가 필요
- 선형 분리 불가능한 원래 특징 공간
- 직선모델을 적용하면 정확도 한계
- 새로운 특징 공간으로 변화하여 사용
- 표현 문제
- 표현 학습
- 심층 학습
- 표현학습의 하나로 다수의 은닉층을 가진 신경망을 이용하여 최적의 계층적인 특징을 학습
- 저급 특징(선, corner)에서 추상화된 특징(얼굴, 바퀴) 추출
3. 데이터에 대한 이해
- 기계학습
- 기계학습은 복잡한 문제를 다룬다
- 단순한 수학 공식으로는 표현 불가능하다
- 데이터를 설명할 수 있는 학습 모델을 찾아내는 과정
- raw data 수집 -> data 전처리 -> 모델 수립 -> 예측
데이터 생성 과정
- 실제 기계 학습 문제는 데이터 생성 과정을 알 수 없다
- 주어진 훈련 집합 X, Y로 가설 모델을 통해 근사 추정만 가능
데이터의 중요성
- 데이터의 양과 질
- 주어진 문제에 적합한 다양한 데이터를 충분한 양만큼 수집 -> 문제 성능 향상
- 주어진 문제와 관련된 데이터 확보는 아주 중요
- 파라미터가 많을 수록 모델 용량이 크고, 더 많은 특징을 파악할 수 있다
- 공개 데이터
- 기계학습의 대표적인 3가지 데이터 : Iris, MNIST, ImageNet
- UCI 저장소
데이터베이스 크기와 기계학습 성능
- 데이터의 적은 양 -> 차원의 저주와 관련
- 근데 어떻게 적은 양의 데이터베이스로 높은 성능 달성?
- 방대한 공간에서 실제 데이터가 발생하는 곳은 매우 작은 부분 공간이다
- 데이터 희소 특정 가정
- manifold 가정
- 고차원의 데이터는 저차원의 매니폴드에 가깝게 집중되어 있다
데이터 가시화
- 4차원 이상의 초공간을 한꺼번에 가시화 불가능
- 여러 가지 가시화 기법
간단한 기계학습의 예
- 선형회귀 문제
- 직접 모델을 사용하므로 두개의 매개 변수
- y=wx+b
- 목적 함수(비용 함수)
- 성능을 판단하는 기준
- 선형 회귀 목적 함수 : 평균제곱 오차
- 처음에는 최적 매개 변수 값을 알 수 없으므로 임의의 난수로 w, b 설정
- 최적화
- 최적의 매개변수를 찾는 과정
- 주어진 손실함수 값을 최소화
- 실제 세계는 선형이 아니며 잡음이 섞여있다 -> 비선형 모델이 필요
3. 모델 선택
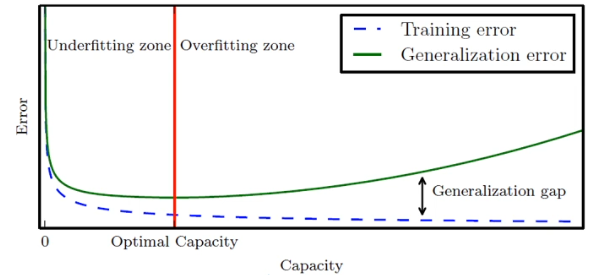
과소 적합과 과잉 적합
- 과소 적합
- 모델의 용량(자유도, 파라미터 수)이 작아 오차가 클 수 밖에 없는 현상
- 대안 : 비선형 모델을 사용
- 과잉 적합
- 새로운 데이터를 예측한다면 큰 문제 발생
- 모델의 용량이 크기 때문에 학습과정에서 잡음까지 수용 -> 과잉 적합 현상
- 적절한 용량의 모델을 선택하는 모델 선택 작업이 필요
- 모델의 일반화 능력과 용량의 관계
편향과 분산(변동)
- 훈련 집합을 여러 번 수집하여 1~12차에 반복 적용하는 실험
- 용량이 적은 모델을 편향이 크고 분산이 작다
- 용량이 복잡한 모델은 평향이 작고 분산이 크다
- 편향과 분산은 trade-off 관계
- 낮은 편향과 낮은 분산을 가진 예측 모델을 만드는 것이 목표
- 하지만 모델의 편향과 분산을 trade-off 관계
- 따라서 편향을 최소로 유지하며 분산도 최대로 낮추는 전략 필요
- 일반화 오차 성능 : 편향 + 분산은 U형의 곡선을 가진다
검증 집합과 교차 검증을 이용한 모델 선택 알고리즘
- 훈련 집합과 테스트 집합과 다른 별도의 validation set을 가진 상황 (데이터의 양이 많다)
- 향상된 일반화 성능을 확인할 수 있다
- validation set을 사용하여 중간중간 성능을 확인한다
- 교차 검증
- 비용 문제로 별도의 검증 집합이 없는 상황에 유용한 모델 선택 기법 (데이터 양 적음)
- n개로 group을 나눈 후, validation을 번갈아가며 사용한다 -> 평균
- bootstrap
- 임의의 복원 추출 샘플링 반복
- 데이터 분포가 불균형일때 적용
- 훈련 데이터를 추출하고 나머지는 test, val로 활용
모델 선택의 한계와 현실적인 해결책
- 용량이 충분히 큰 모델을 선택한 후 선택한 모델이 정상을 벗어나지 않도록 여러 규제 기법을 적용
4. 규제
데이터 확대
- 데이터를 더 많이 수집하면 일반화 능력이 향상
- 훈련집합의 크기가 클수록 오차가 줄어든다
- 데이터 수집은 많은 비용이 든다
- 인위적으로 데이터 확대 (data augmentation0
- 훈련집합에 있는 샘플을 변형(transform)
- 약간 회전, 왜곡을 통해
가중치 감쇠
- 가중치를 작게 조절하는 기법
- 개선된 목적함수를 이용하여 가중치를 작게 조절하는 규제 기법
- 용량을 낮추는 역할을 한다
- 목적함수 + 규제항
- w 즉, 매개변수가 다 발현되지 못하게 규제
5. 기계학습의 유형
지도 방식에 따른 유형
- 지도 학습
- X, Y가 모두 주어진 상황
- 회귀, 분류 문제로 구분
- 비지도 학습
- 특징 벡터 X는 주어지는데 목표치 Y가 주어지지 않는 상황
- 군집화
- 밀도 추정, 특징 공간 변환
- 강화 학습
- 상대적인 목표치가 주어지는 데 지도 학습과 다른 형태 (=보상)
- 준지도 학습
- 일부는 X, Y를 모두 가지지만 나머지는 X만 가진 상황
- 최근 대부분의 데이터가 X의 수집은 쉽지만 Y는 수작업이 필요하여 최근 중용성 부각
다양한 기준에 따른 유형
- 오프라인, 온라인 학습
- 결정론적 학습, 확률적 학습
- 결정론적 : 같은 데이터를 가지고 다시 학습하면 같은 예측 모델이 만들어진다
- 확률적 : 학습 과정에서 확률 분포를 사용하므로 같은 데이터로 다시 학습하면 다른 예측 모델이 만들어진다
- 분별 모델, 생성 모델
- 분별 : 분류 예측에만 관심이 있다
- 생성 : 새로운 샘플을 추정
