0. 구현 내용
- pytorch 사용
구현할 것
- data loader
- 학습을 할 때 data를 불러오는 부분
- local의 data 이미지를 불러와서 전처리하기
- annotation 파일을 불러와서 파일 형식을 torch에 맞게 parsing
- model
- YOLO v3
- cgf 파일을 사용하여 모델 구현
- train / eval logic
- loss
- prediction과 GT를 비교하는 기준
1. dataset 구조 설정
📦KITTI
┣ 📂eval
┃ ┣ 📂Annotations
┃ ┣ 📂ImageSets
┃ ┃ ┗ 📜eval.txt
┃ ┗ 📂JPEGImages
┣ 📂testing
┃ ┣ 📂ImageSets
┃ ┃ ┗ 📜test.txt
┃ ┗ 📂JPEGImages
┗ 📂training
┃ ┣ 📂Annotations
┃ ┣ 📂ImageSets
┃ ┃ ┗ 📜train.txt
┃ ┗ 📂JPEGImages
- eval은 train 데이터에서 9:1정도 약 600개의 데이터를 가져와서 만들어준다
JPEGImages
- JPEGImages에는 저번에 다운받은 KITTI image 데이터가 들어 있다
Annotations
- YOLO 형식에 맞는 annotation들이 들어 있다
ImageSets
- 데이터의 파일이름이 들어있는 txt 파일이 있다
- train.txt & eval.txt 파일
- Annotation 폴더에 있는 파일들의 이름을 txt 파일로 저장한 것이다. 이때 파일의 확장자와 경로를 제외한 파일 이름만 txt 파일로 저장했다
- 각각의 Annotation 폴더 안에서 아래의 명령어를 수행하여 ImageSets 폴더 안에 위치하도록 한다
- train.txt
$ ls | sed 's/\.[^.]*$//' > ../ImageSets/train.txt - eval.txt
$ ls | sed 's/\.[^.]*$//' > ../ImageSets/evla.txt
- test.txt 파일
- JPEGImages의 파일 이름들로 만들어 준다
- JPEGImages 폴더 안에서 아래의 명령어를 실행한다
$ ls | sed 's/\.[^.]*$//' > ../ImageSets/test.txt
2. parser 설정
- main.py의 parse_args()
- 파일을 실행할 때 argument를 주고 parsing 해주는 부분
3. config 파일에서 모델 정보 가져오기
yolo v3 모델 구조 (yolov3.cfg 파일)
[]
- layer들을 구분하기 위한 부분
net
- network의 하이퍼 파라미터를 세팅하는 부분
- layer가 아니다
shortcut
- feature map이 add되는 부분 / residual blcok 같은 부분
- 어떤 module을 담고 있는 layer가 아니다 (그냥 합쳐주는 부분이니까?)
- 그러면 modules에 넣어주지 않아도 되는 거 아닌가?
- module_list와 layer_info의 idx가 맞지 않으면 나중에 복잡할 수 있기 때문에 넣어준다
route
- feature map의 concatnation 하는 부분 (채널이 깊어진다)
- 전제조건은 두개의 feature map size가 같아야한다(width, height 동일, channel은 달라도 된다)
- route 내용의 개수에 따른 기능 차이
- layer = -4
- 4번째 전의 conv를 다음 layer와 연결시켜준다 (다음 layer의 input으로 들어간다)
- layer = -1, 61
- 이전 feature map과 61번쨰 feature map이 concat 되는 것
- layer = -4
yolo
- bbox point를 가지고 sigmoid와 같은 걸 수행하여 bbox를 뽑을 수 있게 만들어주는 역할을 하는 layer
- mask : 해당 yolo layer에서 9개의 anchor 중에 어떤 index의 anchor를 사용할지 정해준다
- stride : 한 grid가 차지하는 픽셀의 값
- yolo layer의 input channel은 39 = (8개의 classes + 4개의 bbox 좌표 + 1개의 objectness) * 3개의 anchor box
- 그래서 yolo layer 전의 conv의 filter는 39이다
3-1. config 파일 데이터 불러오기
- utils/tools.py
parse_hyperparm_config()
- yolov3.cfg에서 [net] 부분의 정보를 가져온다
parse_model_config()
- yolov3.cfg에서 [net] 부분을 제외한 나머지 부분의 정보를 가져온다
3-2. 원하는 파라미터만 가져오기
- utils/tools.py의 get_hyperparam()
- network 설정들에서 필요한 정보들만 가지고 온다
4. Data loader
- dataloader/yolodata.py
- transform : data augmentaion 여부, 데이터의 사이즈, 회전 등을 조절하여 데이터를 조금 변화시켜 전체 데이터의 수를 늘리는 방법
4-1. data loader class 생성
- 멤버변수 설정
4-2. __init__ 함수
- dataset을 불러오는 경로를 설정하고 후에 데이터를 불러올 때 경로에 해당하는 데이터를 불러올 수 있도록 하는 함수
4-3. __getitem__ 함수
- 매 iterator 마다 데이터가 불러질 때 사용되는 함수
- init에서 설정한 경로에서 실제 이미지와 annotataion 데이터를 불러와서 모델의 input으로 넣기 위해 전처리 하는 과정
- annotation path안에 있는 class와 bbox(center_x, center_y, width, height) 정보을 읽어온다
- 이때 class 값도 float로 가져오는데 그 이유는 하나의 array로 만들고 싶기 때문
- class, bbox 정보와 해당 object가 몇번째 batch에 index를 갖는지에 대한 정보를 return
- return : img, target, anno
- img shape : [batch, channel, height, width]
- target shape : [batch, object, 6(batch_idx, class, box coordinate 4)]
파일 읽어올 때 옵션 중 하나인 'b'
- 'rb'에서 b는 파일을 이진모드로 여는 것을 의미한다
- 이진 모드에서 파일을 열면 텍스트, 이미지, 오디오, 비디오 등의 이진 데이터 파일도 읽을 수 있다
- 이진 모드로 파일을 열면 파일의 데이터를 그대로 읽어온다. 텍스트 모드에서는 엔터 문자(\n)등이 자동으로 변환되지만 이진 모드에서는 이러한 변환이 없다
5. Data Transformation & Augmentation
- data_transforms.py 파일
- imgaug tool 사용 (https://github.com/aleju/imgaug)
- classification의 경우는 bbox는 하지 않고 class에 대한 정보만 사용하기 때문에 augmentation을 어떻게 해도 상관이 없다
- 하지만 object detection의 경우 bbox GT 값이 존재하기 때문에 object의 위치, 사이즈가 변하게 되면 GT 값도 이에 맞게 변해야한다
- 이 툴은 이것까지 가능하게 해준다
설치
pip install imgaug5-1. get_transformations 함수
- dataloader에서 파일을 불러올 때 Yolodata의 transform을 가져올 때 사용?????
- is_train을 하는 이유 : train할 때에만 augmentation을 하고 eval, test할 때는 사용하지 않기 때문에
tf.Compose()- 여러개의 augmentation을 하나의 function으로 사용할 수 있게 묶어준다
5-2. AbsoluteLabels 클래스
object 상속 클래스
- 모든 클래스는 내장 클래스인 object를 상속받는다
- object를 상속받는 것은 클래스가 파이썬의 기본 객체 모델을 따르고, 내장된 객체의 메소드와 속성들을 사용할 수 있도록 한다
- 이를 통해 클래스가 파이썬의 표준 객체 모델을 준수하게 되며, 예를 들어 __str__, __repr__, __hash__ 등의 메소드를 기본적으로 사용할 수 있게 된다
- 대부분의 경우 Python 3에서는 object를 명시적으로 상속받지 않아도 되지만, Python 2와의 호환성을 고려하여 클래스를 정의할 때 object를 상속받는 것을 권장
- normalize된 bbox 좌표를 절대 좌표로 변환
5-3. RelativeLabels 클래스
- 절대 좌표를 normalized 좌표로 변환
5-4. ImgAug 클래스
- image augmentation을 할 때 사용될 템플릿
- 나중에는 이 템플릿을 상속받아서 augmentation을 수행한다
- 템플릿을 만드는 이유는 augmentaion을 할 때 공통적으로 사용되는 부분들이 있기 때문이다
- bbox가 augmentation에 따라 값이 변해야하는 부분
- 순서
- xywh 형식의 bbox를 xyxy 형식으로 변환
- bbox를 augmentation 형식으로 변환
- data augmentation 수행 -> img, bbox 모두 변환된다
- 다시 output 형식으로 변환 -> xywh 형식의 bbox
...은 해당 축(axis)을 기준으로 모든 요소를 선택하는 역할
- y[...,0] : 맨 마지막 요소의 0번째를 의미
5-5. DefaultAug 클래스 (ImgAug 클래스 상속)
Sequential()- 여러개의 augmentation을 한번에 적용할 수 있도록 해주는 함수
- Compose와 비슷
- sharpening과 affine 수행
5-6. ResizeImage 클래스
- 모델의 input image size에 맞게 image 데이터의 사이즈를 resize 해주는 클래스
5-7. ToTensor 클래스
- transform 결과 array인 데이터를 tensor로 변환해주는 클래스
- 0~255 사이의 값으로 이루어진 image를 0~1 사이의 값으로 normalization 해준다
- channel, height, width 순으로 데이터 구조 변환
6. model 구현
- yolov3.py 파일
- config 파일을 통해 읽어온 모델 정보로yolo v3 모델을 구현한다.
nn.ModuleList()와 nn.Sequentail()
nn.ModuleList()
- 모듈을 list로 관리할 수 있도록 해준다
- forward할 때 여기서 하나씩 불러와서 사용한다
nn.Sequential()
- conv 후에 activation이 오는 구조는 딥러닝에서 가장 많이 사용하는 블록이다
- conv과 activation이 하나의 모듈로 반복
- 반복되는 것을 하나로 묶어주는 것을 Sequentail
- 이 둘의 차이?
- ModuleList은 module을 담고 있는 list
- Sequentail은 여러 module들을 묶어서 하나의 module로 만들어 주는 느낌
- 추가로 nn.Identity()는 자기 자신을 output으로 주는 것
6-1. Darknet53() 클래스
- 메인 모델
set_layer() 함수
- config 파일에서 불러온 모델 정보로 layer 설정
initialize_weights()
- 맨 처음에 모델의 weight와 bias를 초기화 해주는 부분
- 해당 layer가 conv이라면 nn.init.kaiminguniform 방법으로 초기화
- 초기화 방법은 다양하게 있다. nn.init에서 보면 알 수 있다
- 만약 pre trained weight를 사용할 때
- 기존의 weight 사용
forward()
- 모델의 forward를 진행하는 부분
- 결과
- output length : 3 -> 3가지 크기의 feature map
- output feature map의 shape : [batch, anchor수, grid, grid, box attribute(class수 + bbox 좌표 + objectness)]
- output[0].shape : torch.Size([1, 3, 19, 19, 13])
- output[1].shape : torch.Size([1, 3, 38, 38, 13])
- output[2].shape : torch.Size([1, 3, 76, 76, 13])
- 이때 모델의 input image size는 (608,608)이다. 이 값이 달라지면 feature map size 즉,output의 크기가 달라진다(19, 19가 달라진다)
tensor끼리 연산할 때 두 tensor는 동일한 device에 올라가 있어야한다
- self.anchor.to(x.device)
6-2. Yololayer() 클래스
- config에서 [yolo]인 layer는 따로 클래스로 만들어준다
- 4차원의 이미지 데이터를 5차원의 이미지 데이터로 변환해준다
- kttti data의 경우 channel은 (8 + 5) * 3 = 39개이다
- 8 : class 수
- 5 : box 정보 -> center_x, center_y, width, height, objectness
- 3 : anchor 수
- [batch, box_정보 * anchor, lh, lw] -> [batch, anchor, lh, lw, box_정보]
7. loss 계산
- train/loss.py
- 3가지 loss
- bbox에 대한 loss
- class와 관련된 loss
- objectness에 대한 loss
- 전체 예측한 22743개의 box와 GT값을 비교하여 유효한 것들만 뽑아낸다
- positive pred : GT와 box가 겹치고 잘 예측한 거
- negative pred : 그냥 배경을 친 것
- 둘의 비율은 0.01 : 0.99정도
- negative가 너무 많으면 수렴이 잘 되지 않을 수 있다
- positive에서만 class, box loss를 뽑을 수 있다
- negative에서는 obj_loss만 구할 수 있다
- 그래서 positive pred이 영향력있게 만들어주어야한다
7-1. compute_loss() 함수
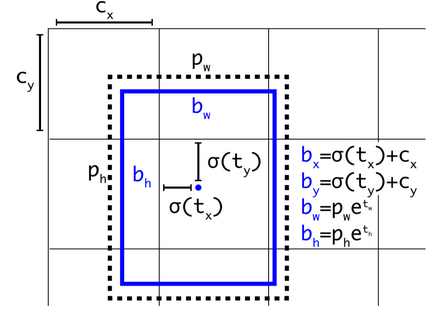
- 위의 식처럼 x,y 의 값에는 sigmoid를 적용하고 w, h값에는 exponential을 적용한다
- 예측한 box와 target box 간의 iou를 계산한다 -> utils/tools.py의 bbox_iou 함수
- box loss 계산
- mse loss를 사용하면 loss의 값이 너무 커지는 경우가 발생한다
- 따라서 iou 값 활용
- 식을 활용하여 0~1 사이의 값으로 만든다
- objectness loss 계산
- BCEWithLogitsLoss 사용
- 예측한 objectness 값과 iou 값의 차이로 loss 계산
- 원래는 객체가 있는 경우 target은 1, 없는 경우는 0으로 하여 계산하는데 iou 값을 활용하였다
- class loss 계산
- BCEWithLogitsLoss 사용
- total loss = box loss + objectness loss + class loss
7-2. get_targets() 함수
- target의 shape 변형
- target 값의 shape을 pred과 같게 만들어서 loss 계산하기 편하도록 해주는 함수
- indices, anch : 해당 index의 정보, anchor의 인덱스 정보
- 하나의 yolo layer에서 하나의 gt object에 3개의 box를 예측한다(anchor가 3개이기 때문에) -> 그래서 gt 값을 3개로 늘려줘서 각각 비교하여 어떤 box가 가장 잘 예측했는지 loss을 계산하기 쉽게 만들어 준다
-
anchor 값 변환
- cgf의 anchors는 전체 이미지에서의 absolute 좌표이다
- 따라서 이 값을 feature map의 grid에 맞게 변환해주어야 한다
- anchor 값 / grid
-
target의 bbox 값을 grid에 맞게 변환
- target의 cx, cy, w, h는 normalize 되어 있다
- 이 값을 grid에 맞게 변환
- target의 cx, cy, w, h * grid
-
예측한 box와 anchor의 비율이 4 이하인 target box만 남긴다
- bbox의 w, h를 anchor w, h로 나눈다
- ,
- , : 예측한 bbox의 w, h의 absolute 값
- , : anchor의 w, h
- , : 예측한 w, h의 지수값
-
원하는 target들의 class값, anchor값, box값들을 반환한다
- indices : batch_id, anchor_id, target data grid index y, index x 값
- tboxes : box의 grid안에서의 상대 x, y 좌표값과 w, h값
- anch : anchor값 (w, h)
- tcls : class 값
8. Trainer
- train/trainer.py
- 실제로 모델, dataloader를 받아와서 train하는 부분
- iter를 돌리면서 학습하는 부분
8-1. __init__ 함수
- max_batch
- 학습이 종료되는 구간
- scheduler_
- lr scheduler를 어떻게 할지 (optim.lr_scheduler)
- 이거에 따라 lr가 감소하는 기준, 그래프가 달라진다
- MultiStepLR : 학습을 진행할수록 lr가 떨어져야 정교하게 update할 수 있다
- milestones : 몇개의 epoch에서 lr을 감소시킬건지
- gamma : lr을 얼마의 비율로 감소시킬건지
8-2. run_iter 함수
- iteration 부분으로 batch에 따라 모델을 학습한다
- 모델의 결과와 GT 값을 비교하여 loss을 계산한다
- loss의 gradient를 구한다
- weight를 갱신한 후 gradient를 초기화한다
- learning rate를 조정한다
- loss 값들을 tensorboard에서 시각화로 확인하기 위해 로그를 작성한다
8-3. run 함수
- epoch 마다 모델을 학습한다
- checkpoint를 저장한다
- epoch, iteration, model state, optimizer statem loss를 저장한다
- model.state_dict()를 통해 모델에서 학습 가능한 파라미터들을 불러올 수 있다
9. main_train
- main.py의 train 함수
9-1. train data load
- Yolodata : data의 경로, annotation 파일, 이미지를 읽어온다
- DataLoader : 읽어온 데이터를 실제로 다루는 부분
DataLoader
num_workers- 모델을 학습할 때는 gpu에서 하기 때문에 데이터를 gpu로 올려줘야한다.
- 이때
num_workers가 cpu와 gpu 간의 데이터 교류를 담당하는 역할을 한다. - 0이면 single process, 1, 2, 3이 되면 multi thread 방식으로 사용된다
- cpu의 개수, 상황, 컴퓨터 환경에 따라 설정하는데 기본적으로 0을 넣으면 죽지 않는다
pin_memory- 데이터 array를 gpu로 올릴 때 메모리의 위치를 고정할지 말지
drop_last- batch size 만큼 이미지를 읽어오는데 이때 남은 데이터를 버릴지 말지
- true : 사용하지 않는다. 즉 버린다
- false : 다음 epoch 때 사용한다
shuffle- 이미지를 랜덤으로 읽어들일지 말지
collate_fn- getitem을 통해 데이터 하나를 읽어오는데 이를 batch로 구성해주어야한다
- batch가 4이면 4개를 하나의 데이터로 합쳐야하는데 이 방식을 collate function이라고 한다
- 따로 collate_fn()을 만들어준다 -> 3차원의 img를 4차원으로 만들어준다(batch가 포함된)
- 결과
- image 데이터, GT 값, annotation path가 출력된다
9-2. model 설정
- Darknet53을 모델로 설정한다
- model.train() 수행
- pytorch에서 모델을 학습모드로 설정하는 함수
- 모델 내부의 일부 레이어들이 학습 모드로 전환된다
- dropout, batch normalization과 같은 레이어들은 학습모드와 평가 모드에서 다르게 작동하는데 이를 제어하기 위해 사용하는 함수
- dropout layer의 경우 학습 시에만 활성화 되어야하고, batch noral의 경우 학습 시에는 미니 매치의 평균, 분산을 계산하여 정규화 수행
추가 : model.eval()
- 모델을 평가 모드로 설정하는 함수
- drouout를 비활성화, batch normal layer애서는 학습할 때 계산한 평균, 분산을 사용
- model의 weight를 초기화한다
- model train을 수행한다
