YOLO v1
0. Abstract
- 새로운 방식의 object detection
- 이전의 방식은 classifier를 사용하였지만 YOLO는 regression 방식으로 bounding box와 class probablities에 접근한다
- 한번의 forward로 bbox와 class를 예측한다
- single network
- 빠르다
1. Introduction
YOLO detection system
- resize input image (448x448)
- CNN 수행
- Non max suppression
YOLO의 특징
- 매우 빠르다
- 1초에 45fps
- 다른 real-time system과 다르게 2배의 mAP 성능
- sliding window나 region proposal-based 방법과 다르게 YOLO는 전체 이미지를 본다
2. Unified Detection
- 전체 이미지에서 각각의 object의 정보를 뽑는다
- input image를 SxS grid로 나눈다
- 각각의 grid cell에서 B bounding box와 confidence score를 찾는다
- confidence score
- confidence score =
- cell안에 object가 없으면 confidence score = 0
- bounding box
- 5개의 prediction : x, y, w, h, confidence
- grid = 7, bounding box = 2, class = 20 -> 7x7x(20+5x2) tensor
2.1 Network Design
- backbone으로 GoogLeNet 사용
- 24개의 convolution layer + 2 fc layer
2.2 training
- activation function으로 leaky relu 사용
- x > 0 : x
- otherwise : 0.1x
- sum squared error를 loss function으로 사용
loss function
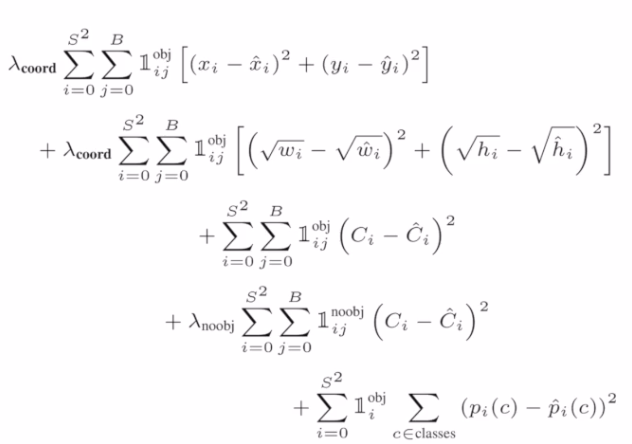
- width, height의 경우 값이 크기 때문에 루트를 씌워서 다른 값들과 비슷하게 적용할 수 있도록 한다
6. Conclusion
- 단순하면서 전체 이미지를 학습하는 방법의 모델이다
- classifier 접근 방식과는 다르게 loss function을 바로 학습한다
- localize error가 있고 low recall이라는 단정이 있다
YOLO v2(9000)
0. Abstract
- YOLO9000 : 9000개의 class
- YOLO v2 : fps 증가, mAP 증가
1. Intro
- 학습하려면 dataset이 중요한데 bbox를 설정하고 labeling하는 것이 힘든 일이기 때문에 labeling이 되지 않은 data도 사용했다
2. Better
- YOLO가 localize error와 low recall 단점이 있어서 이를 해결하고자 하였다
batch normalization
- conv layer 다음에 BN 추가
- mAP 2% 증가
- model regularize에 도움이 된다
- 기존에 사용하던 dropout은 제거
high resolution classifier
- 448x448을 사용
- 해상도가 높기 때문에 특징들을 좀 더 잘 학습할 수 있었다
- mAP 4% 증가
convolutional with anchor box
- fc layer 삭제
- 그 이유는 fc는 공간정보를 사라지게 하는 단점이 있는데 이를 해결하기 위해서이다
- output feature를 13x13 grid로 나누어서 사용
- recall 성능향상
- Grid Cell 당 Anchor Box 수 : 5
dimension cluster
Direct location prediction
-
anchor box를 사용할 때 box의 (x, y)를 예측하는 부분에서 모델의 불안정성이 있었다
-
GT 값과 초반에 예측한 (x,y)값이 크면 loss가 커지게 되고 loss가 크면 학습이 잘 되지 않는 문제가 있다
-
아래의 두 식을 적용하여 해당 문제를 해결하였다
- t : networt 예측 값
- (x, y) : grid의 center 좌표
- 따라서 gird center에 맞게 값을 normalization 해주는 과정
-
각각의 cell에서 5개의 bbox를 예측
-
bbox는 5개의 coordinate를 가지고 있다
- (object 확률값)
-
최종 예측값
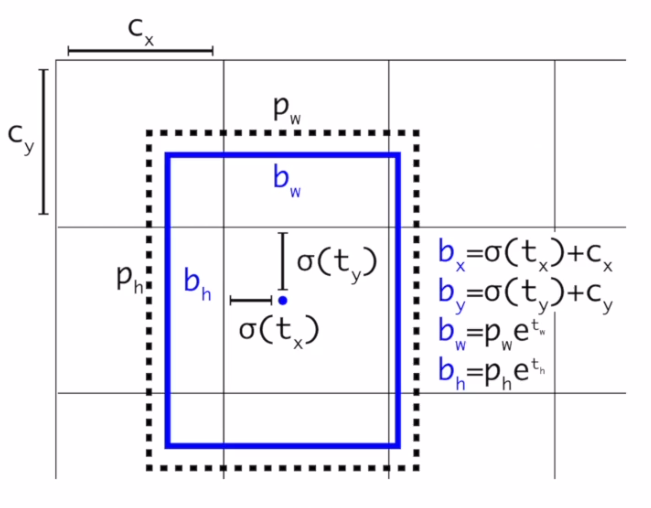
- 여기서 는 anchor의 w, h
-
5%의 성능 향상
Fine-Grained Feature
- 13x13 feature map을 사용
multi-scale training
- 이미지 크기를 다양하게
- 이미지 크기가 작을수록 FPS가 증가하고 이미지 크기가 클수록 mAP가 증가한다
3. Faster
Darknet-19
- v2부터 darknet 사용
- 3x3 filter만 사용
- 19개의 conv layer + 5개의 max pooling layer
5. Conclusion
- v2
- 빠르다
- 다양한 이미지 크기에서 사용할 수 있다
- 이미지 크기가 작으면 속도는 더 빠르다
YOLO v3
- bbox를 prediction 하는 부분이 달라졌다
0. Abstract
- 빠르다
- mAP 성능 증가
2.1 Bounding Box Prediction
- 각각의 bbox마다 4개의 coordinate 예측
- 하나의 cell에서 3개의 bounding box 사용
2.4 Feature Extractor
- darknet 53 사용
- 3개의 서로 다른 scale output feature map을 사용한다 (13x13, 26x26, 52x52)
- 13x13 grid에서는 큰 object를 예측하기 쉽고, 52x52의 경우 작은 object를 찾기 쉽다
5. What This All Means
- 좋고, 빠르고, 정확하다
