혼공머신 2주차
- Chapter 3) 회귀 알고리즘과 모델 규제
3-1 k-최근접 이웃 회귀
지도 학습 알고리즘은 크게 분류와 회귀로 나뉜다.
- 분류 : 샘플을 몇 개의 클래스 중 하나로 분류하는 것
- 회귀 : 정해진 클래스가 없고, 임의의 수치를 예측하는 것
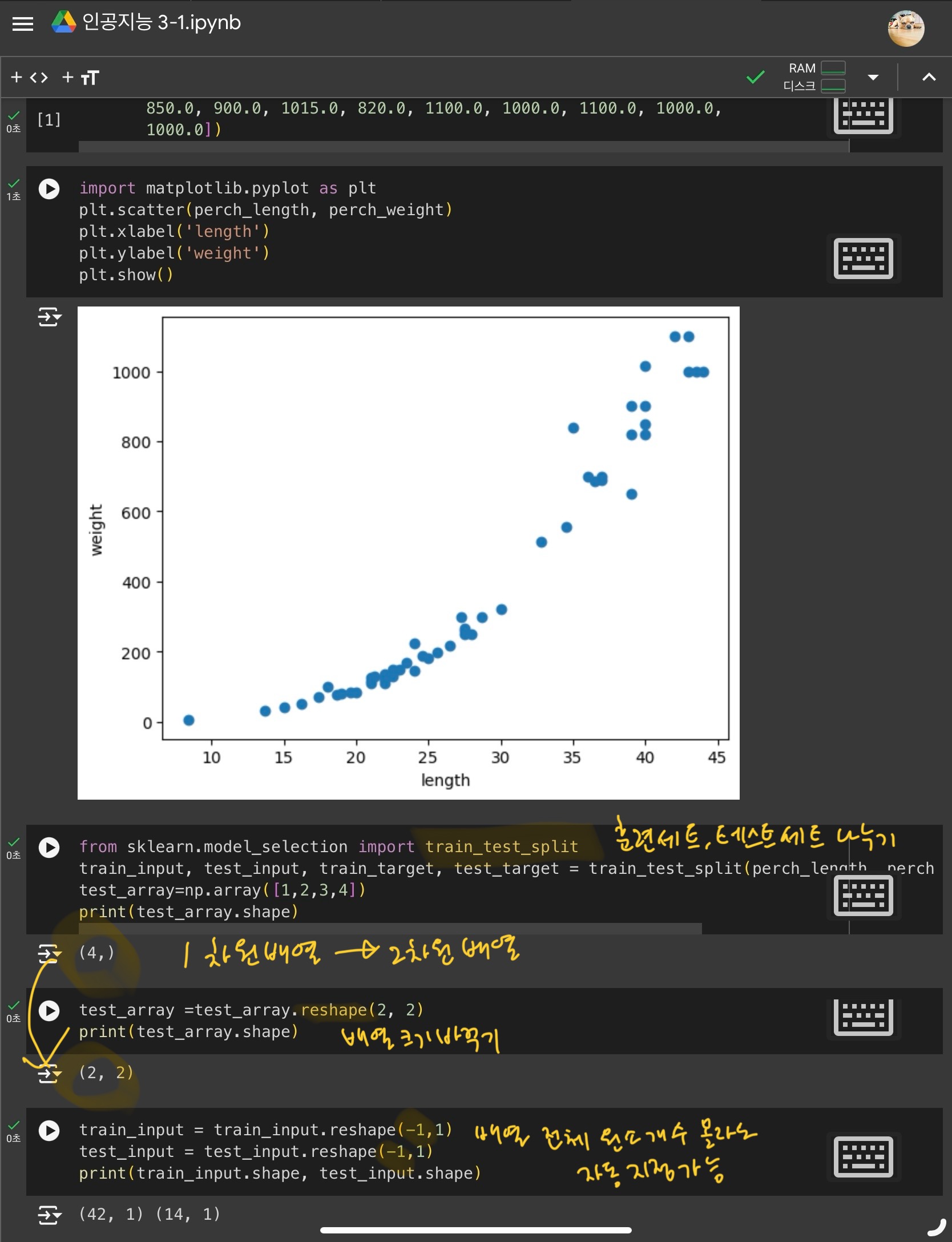
- 데이터 준비하기
훈련 세트와 테스트 세트 나누기
1개의 특성(길이)를 사용하므로 2차원 배열로 바꿔주기
- 회귀 알고리즘 구현하기
회귀는 결정계수(R^2)로 성능을 평가한다.
(결정계수 값이 1에 가까울수록 성능이 좋은 모델)
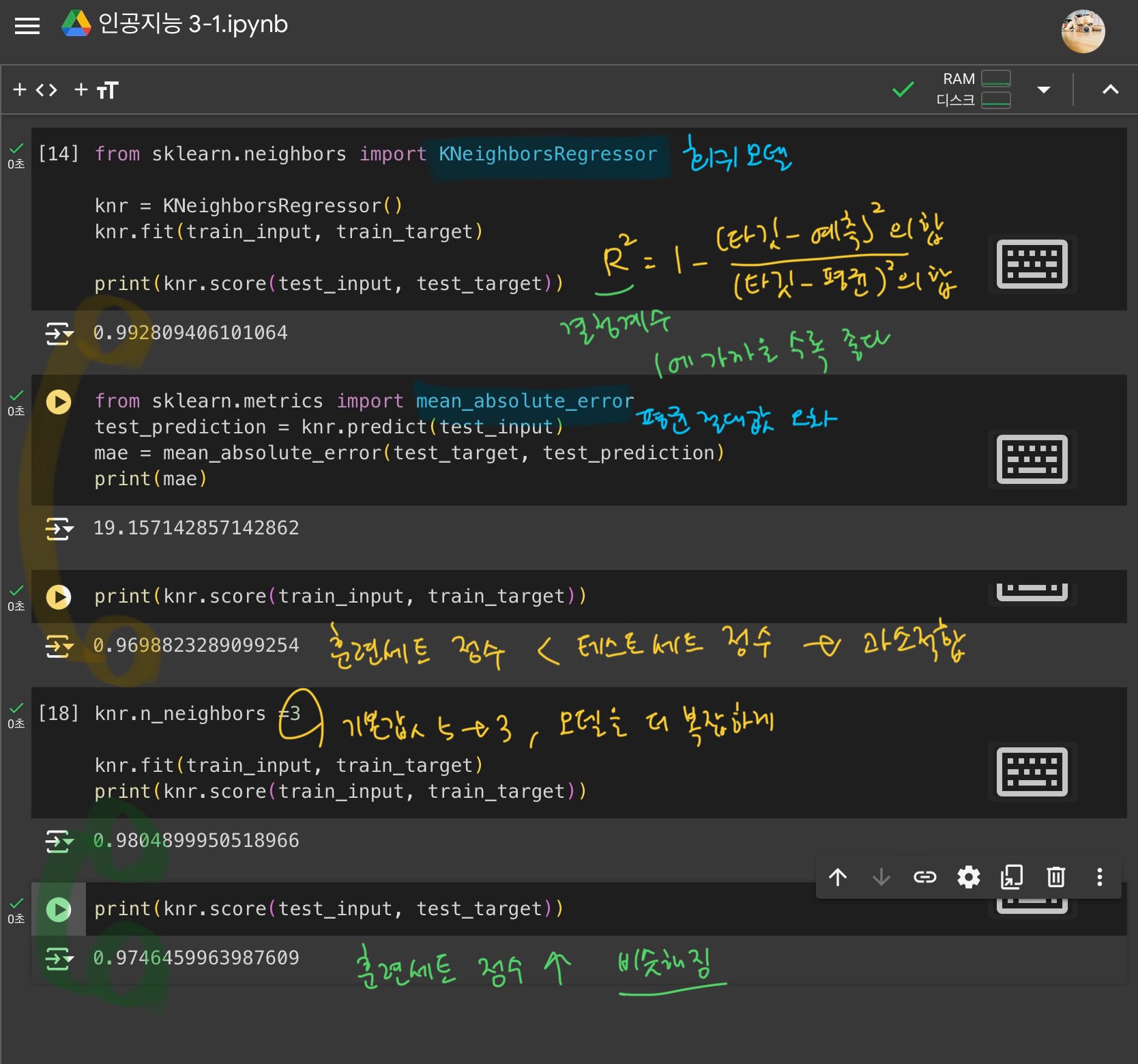
과소적합(훈련세트 점수 < 테스트세트 점수) 발생!!
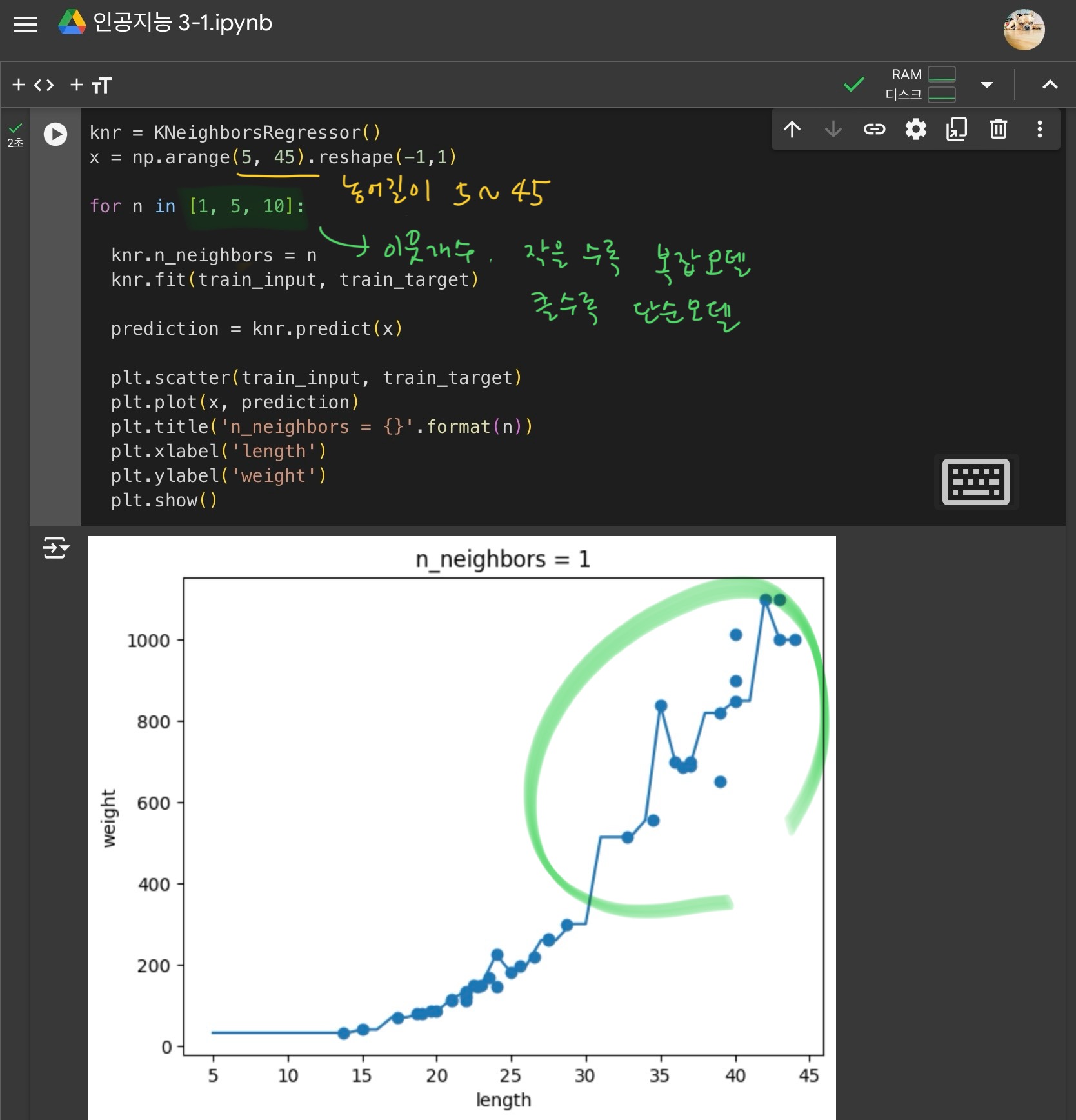
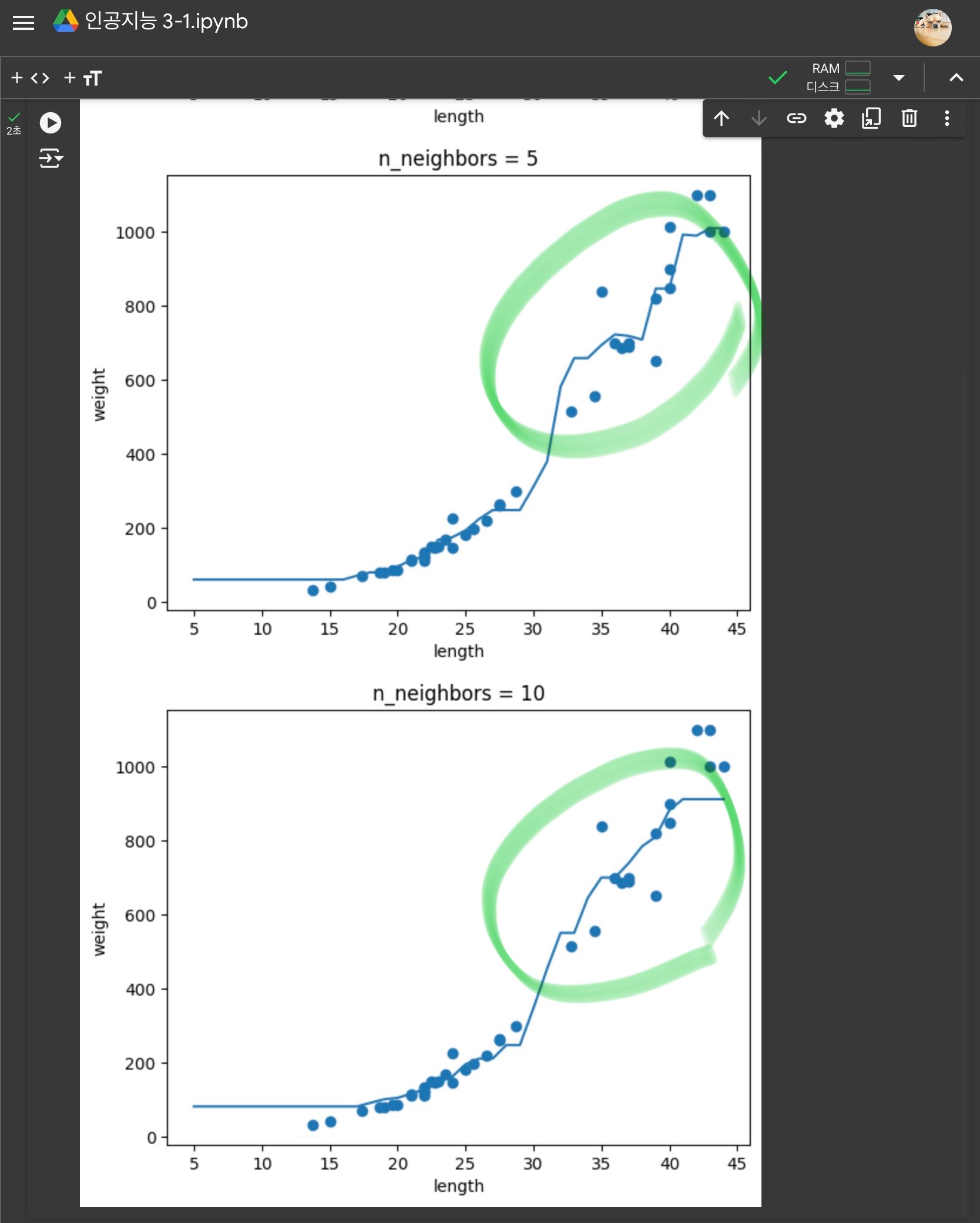
-> 이웃의 개수 k를 줄여서 모델을 더 복잡하게 만들기
이웃의 개수를 줄이면 훈련 세트에 있는 국지적인 패턴에 민감해짐
3-2 선형회귀
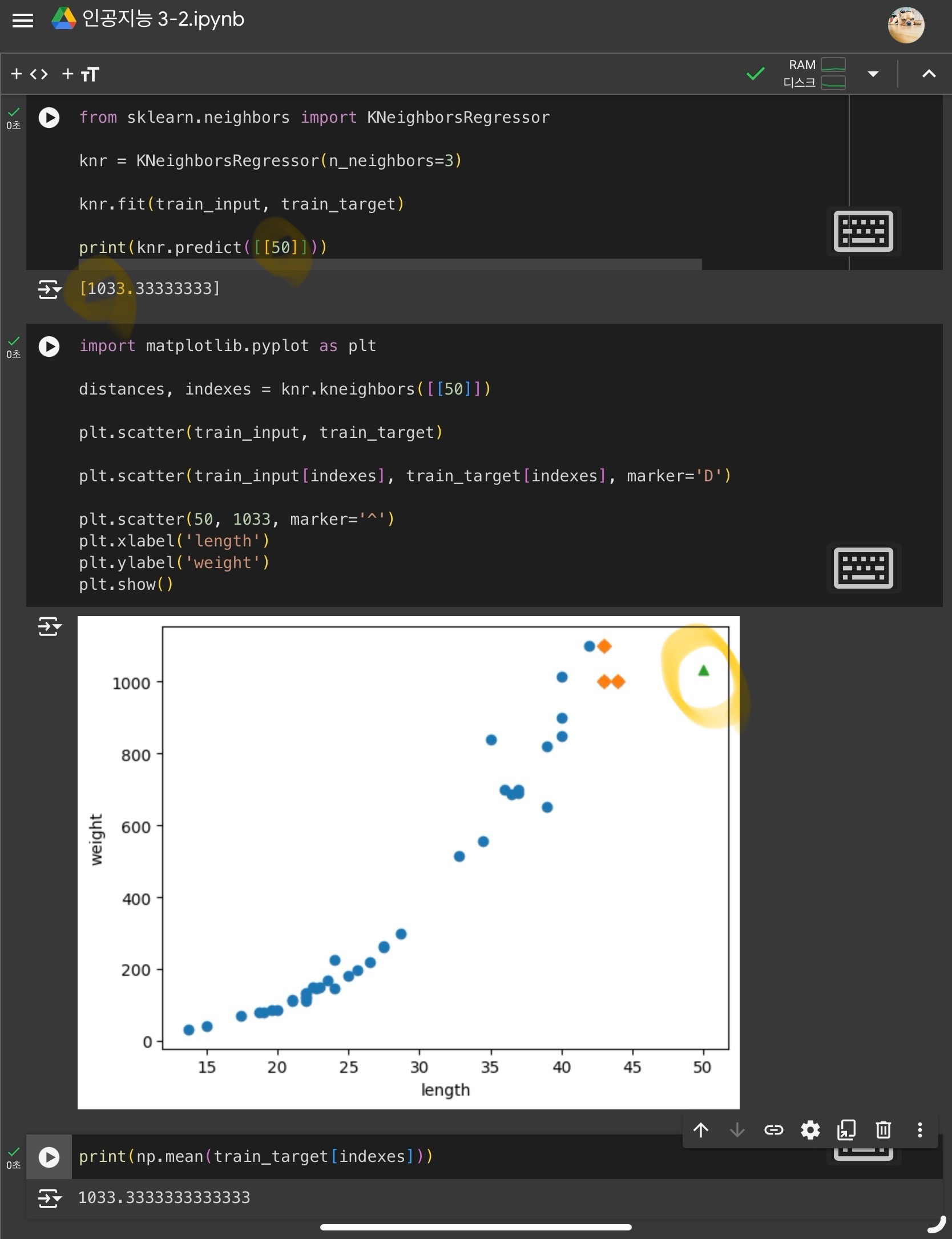
k-최근접 이웃 회귀의 문제점 발생!!
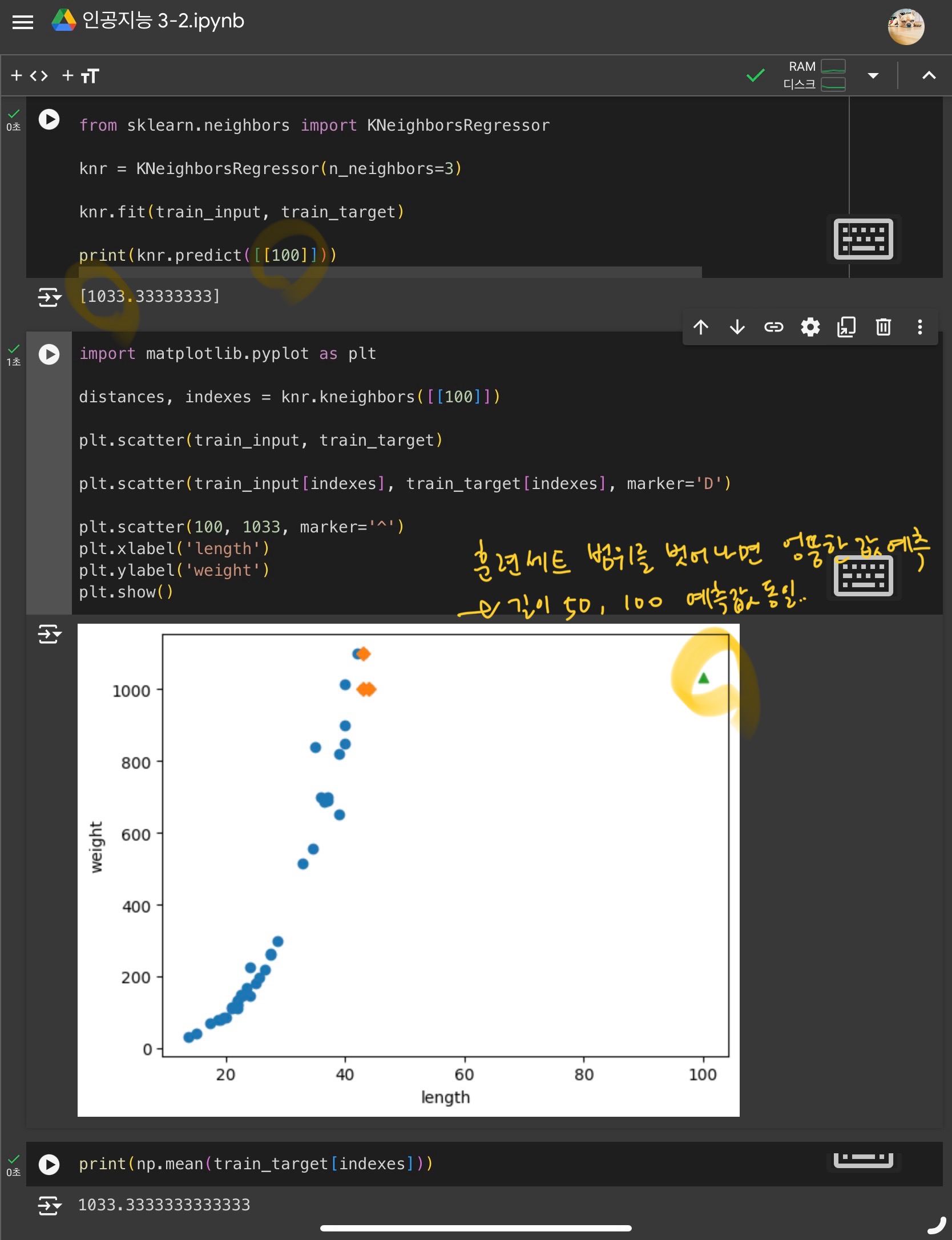
샘플이 훈련 세트의 범위를 벗어날 경우, 샘플을 예측할 수 없다.
범위 밖인 50cm 농어와 100cm 농어의 무게 예측값이 동일해짐
선형회귀란?
훈련 세트에 잘 맞는 직선 방정식을 찾는 알고리즘으로, 샘플이 훈련세트의 범위를 벗어날 경우 샘플을 예측할 수 없는 k-최근접 이웃 회귀의 문제를 해결할 수 있다.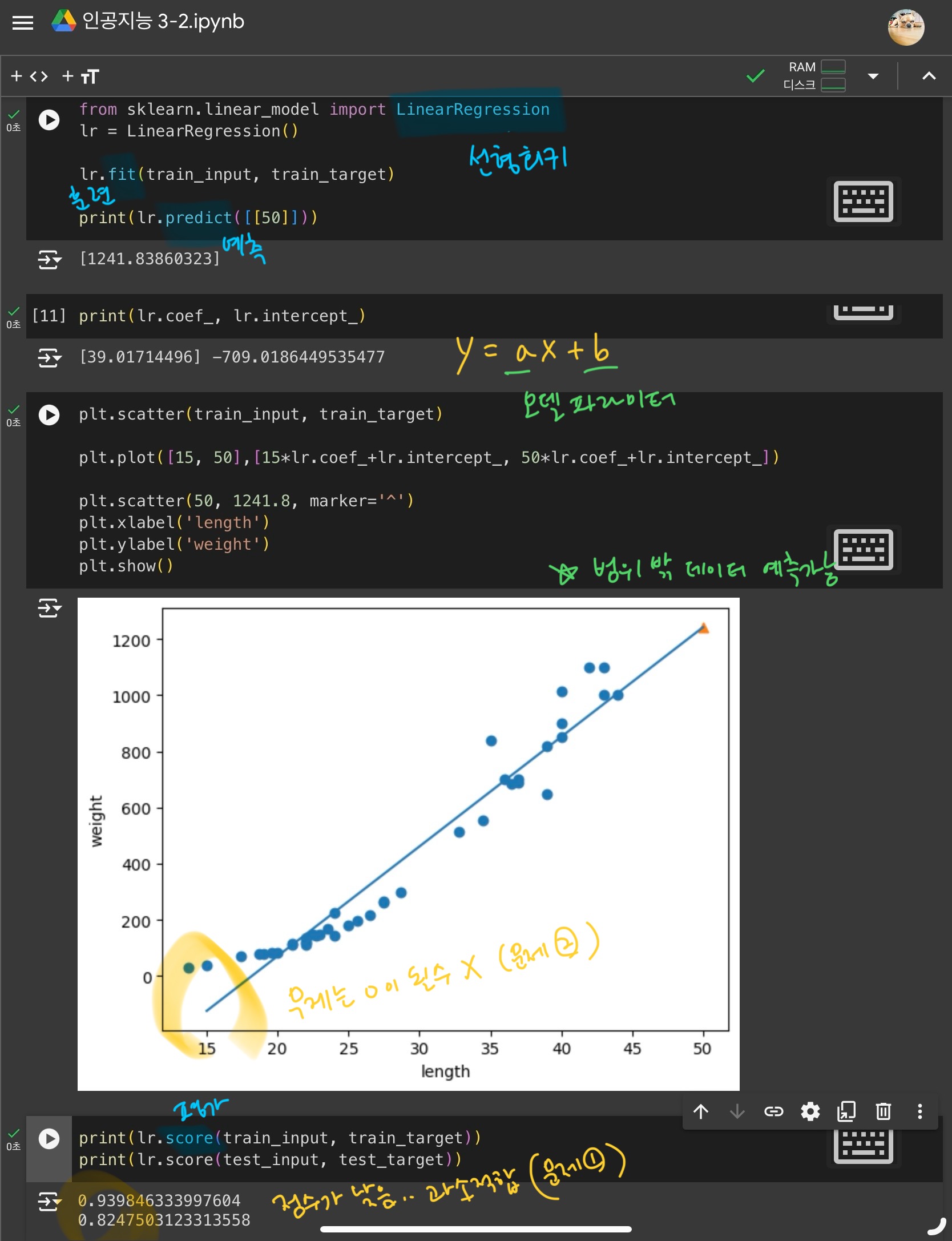
- 문제점 1) 훈련 세트 점수와 테스트 세트 점수가 낮다
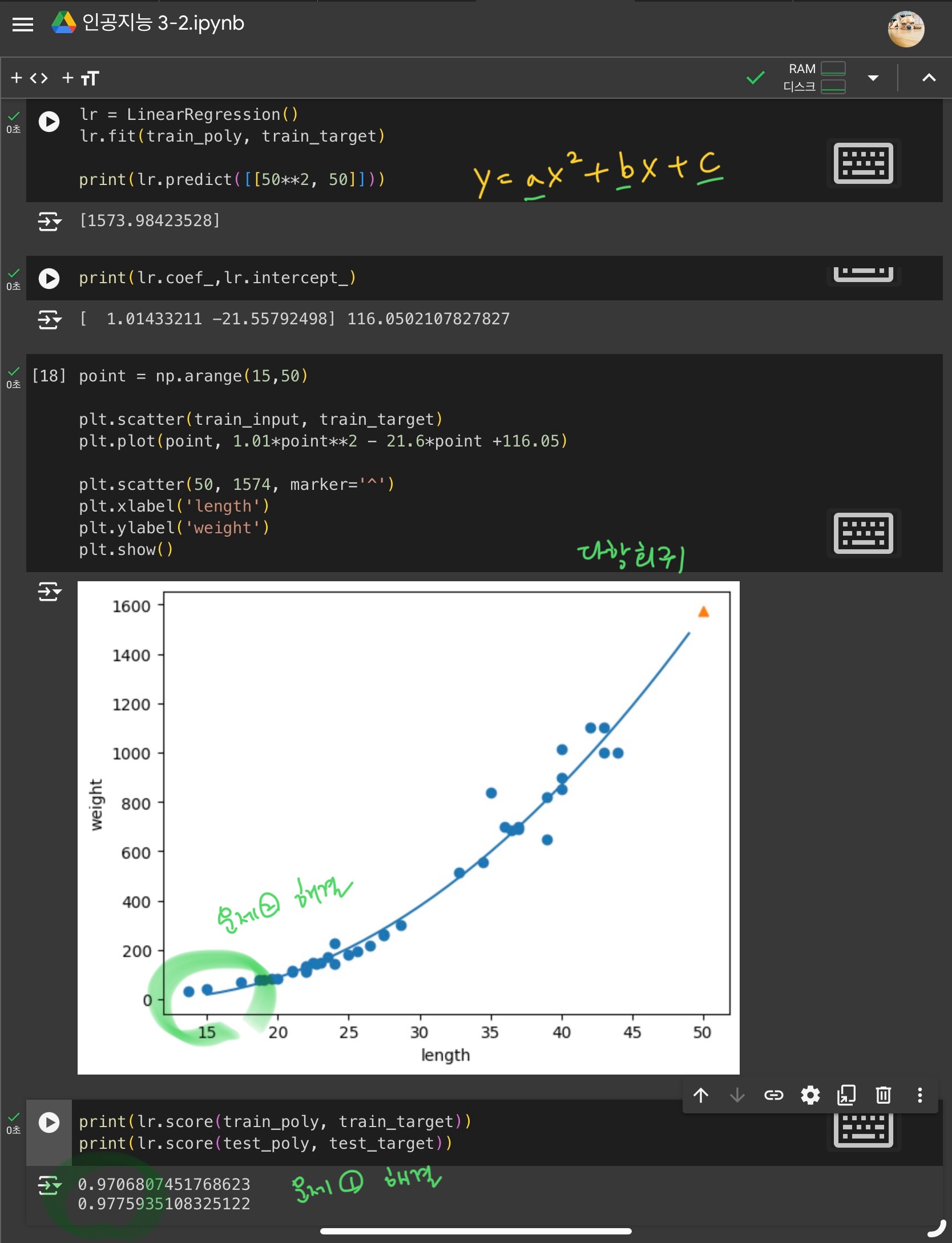
- 문제점 2) 길이와 무게는 0이 될 수 없다.
다항 회귀를 사용하여 2차 방정식 그래프(곡선) 형태로 학습
3-3 특성 공학과 규제
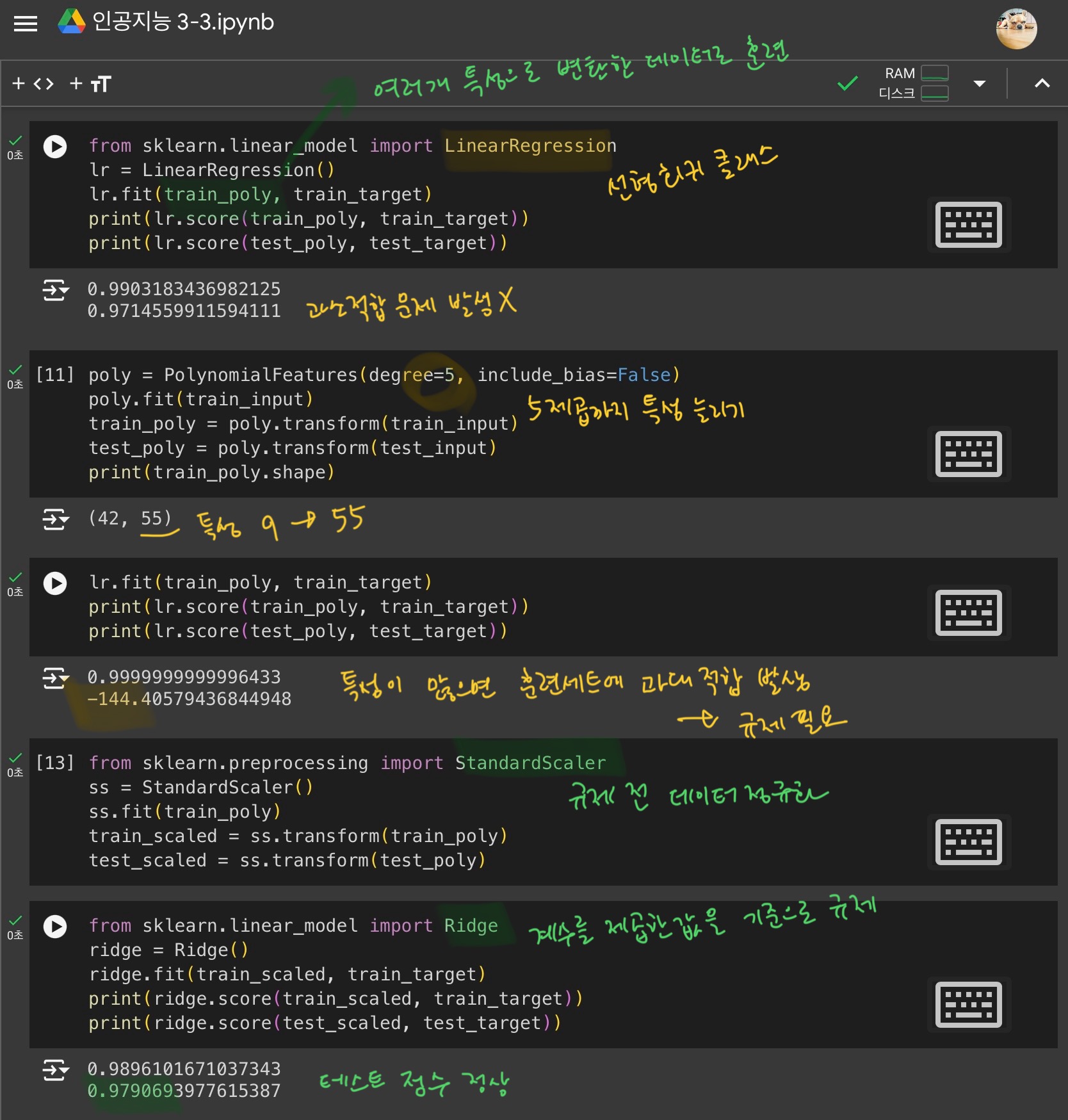
훈련 세트보다 테스트 세트의 점수가 높은, 과소적합 해결하기
여러 개의 특성을 사용한 선형 회귀, 다중회귀 -> 모델 성능 강화
- 특성 공학 - 기존 주어진 특성을 사용하여 새로운 특성을 뽑아내는 작업
- 변환기 - 특성을 만들거나 전처리하는 클래스

특성 개수가 너무 많으면, 훈련 세트에 과대적합한 모델됨
-> 테스트 세트의 점수가 낮아진다.
- 규제 : 머신러닝 모델이 훈련 세트를 너무 과도하게 학습하지 못하도록 훼방하는 것
선형 회귀 모델에 규제를 적용할 때, 정규화 필요!!- 규제 모델
릿지 : 계수를 제곱한 값을 기준으로 규제 적용
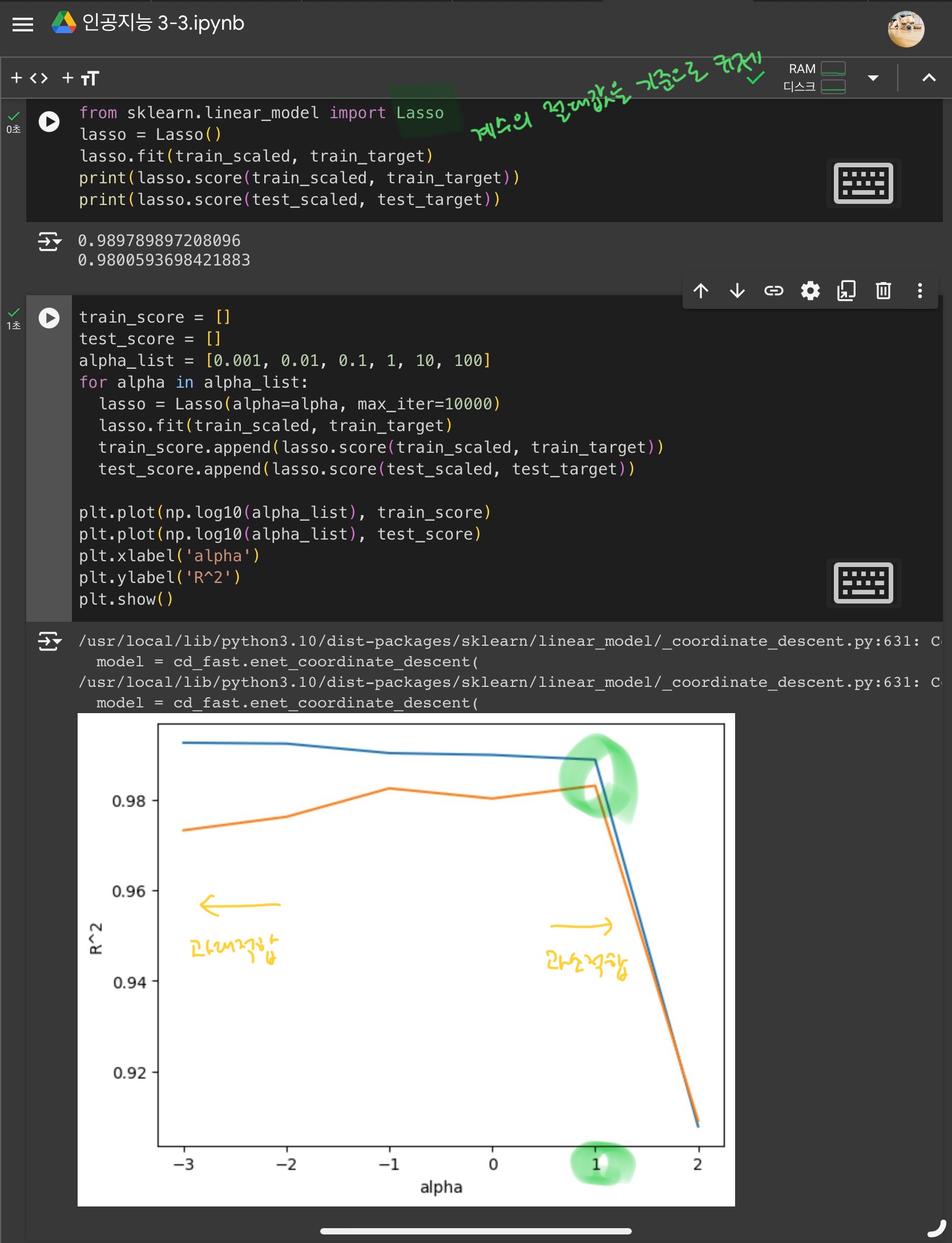
라쏘 : 계수의 절댓값을 기준으로 규제 적용
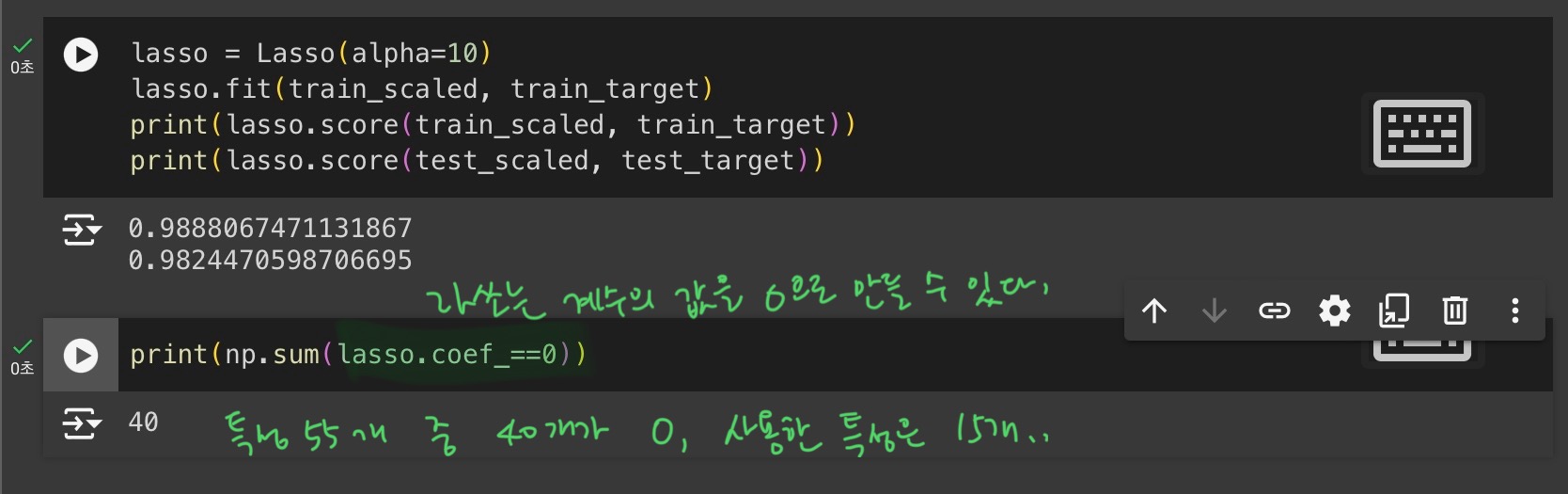
(릿지와 달리 계수값을 아예 0으로 만들 수 있음)
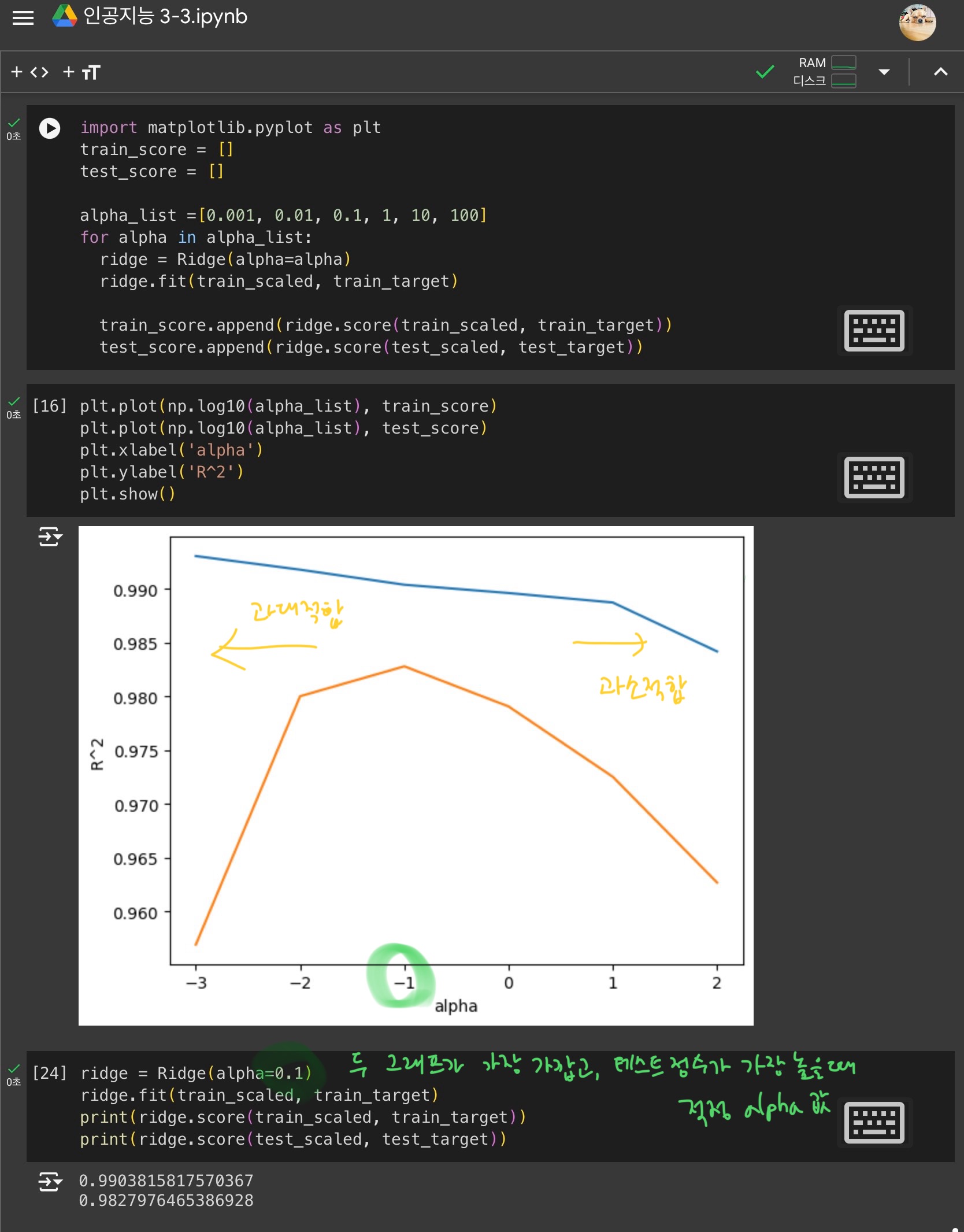
 적절할 alpha값 찾기 - R^2 값 그래프 그리기
적절할 alpha값 찾기 - R^2 값 그래프 그리기
- alpha값이 클수록 규제가 강해짐
-> 계수 값을 더 줄이고 조금 더 과소적합되도록 유도 - alpha값이 작을수록 규제가 약해짐
-> 계수를 줄이는 역할이 줄어들고, 과대적합될 가능성이 커짐
2주차 학습 일기
실습을 하면서 공부를 하니까 집중도와 이해도가 올라가는 것 같다.
중간중간 오류가 나오면 당황스럽지만!!
찬찬히 작성한 코드와 오류메시지를 보면서 해결해 나가는 재미가 있다.
사실 정말 왜 그런지 눈에 안들어올땐 답답하긴 하지만,
그만큼 해결했을 때 쾌감이 있다!! > <
어쨌든, 2주차도 성공!!
꾸준히 성공하길 바라며...

공부기록