본 포스팅은 "혼자 공부하는 머신러닝+딥러닝" 책을 바탕으로 제작되었습니다.
Deep Neural Network
어느 분야에서 사용될까?
chatGPT의 말에 따르면 ...
- 이미지 인식: DNN은 이미지 분류, 객체 감지, 얼굴 인식 등의 문제에서 높은 정확도를 보입니다. 컴퓨터 비전 분야에서 DNN은 현재 가장 인기 있는 기술 중 하나입니다.
- 자연어 처리: DNN은 자연어 처리에서도 많이 사용됩니다. DNN 기반의 언어 모델은 문장 생성, 기계 번역, 질의 응답 등에서 매우 뛰어난 성능을 보입니다.
- 음성 인식: DNN은 음성 인식 분야에서도 많이 사용됩니다. DNN은 음성 데이터를 분석하고 이를 텍스트로 변환하는 데 사용됩니다.
- 게임 AI: DNN은 게임 인공지능에서도 많이 사용됩니다. 예를 들어, 알파고와 같은 바둑 AI는 DNN을 사용하여 학습됩니다.
특징
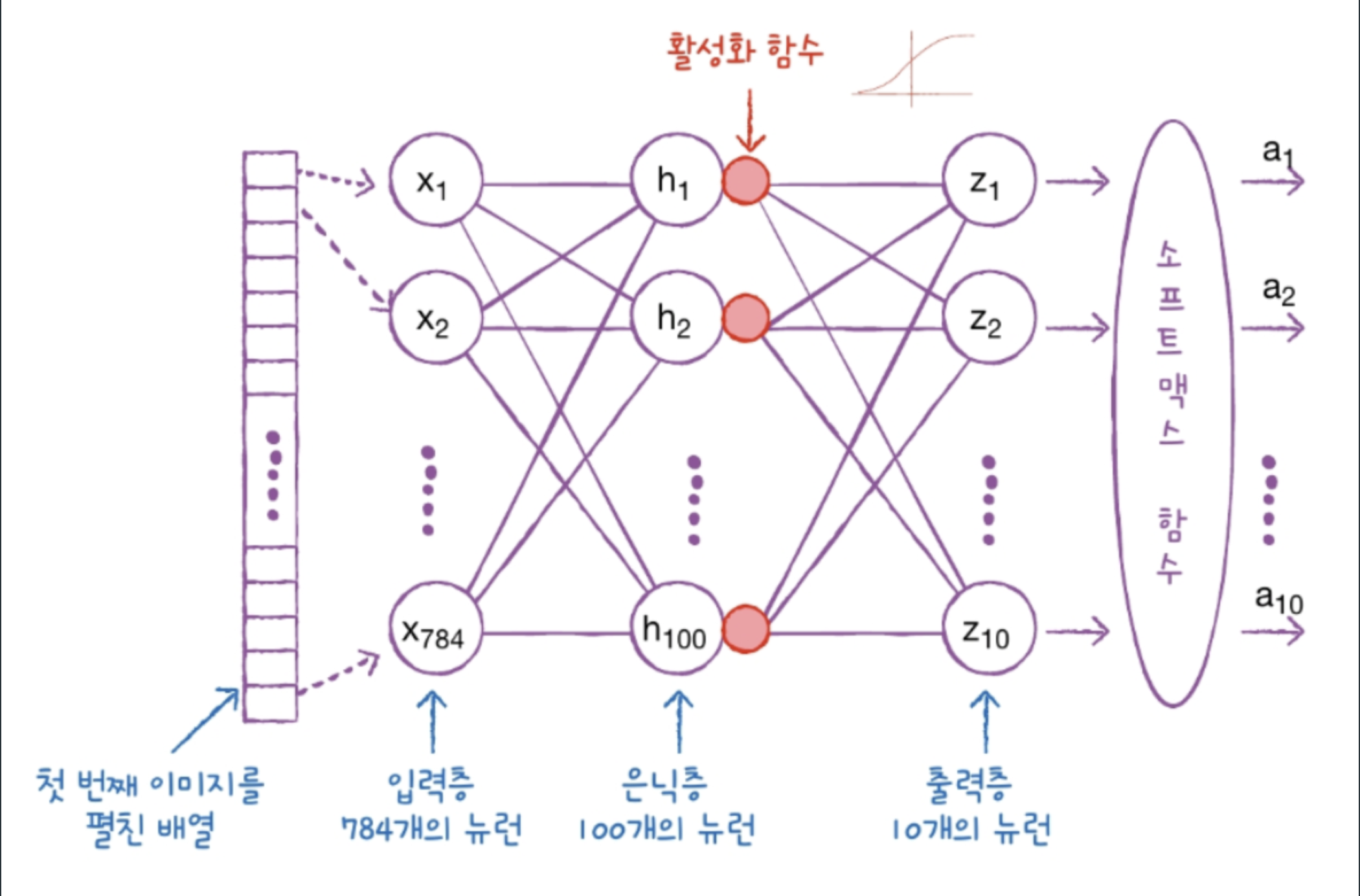
DNN은 입력층과 출력층 사이에 은닉층이 존재한다는 특징을 가지고 있다.
그리고 각 은닉층에는 활성화 함수가 존재한다.
활성화 함수를 왜 적용하는가?
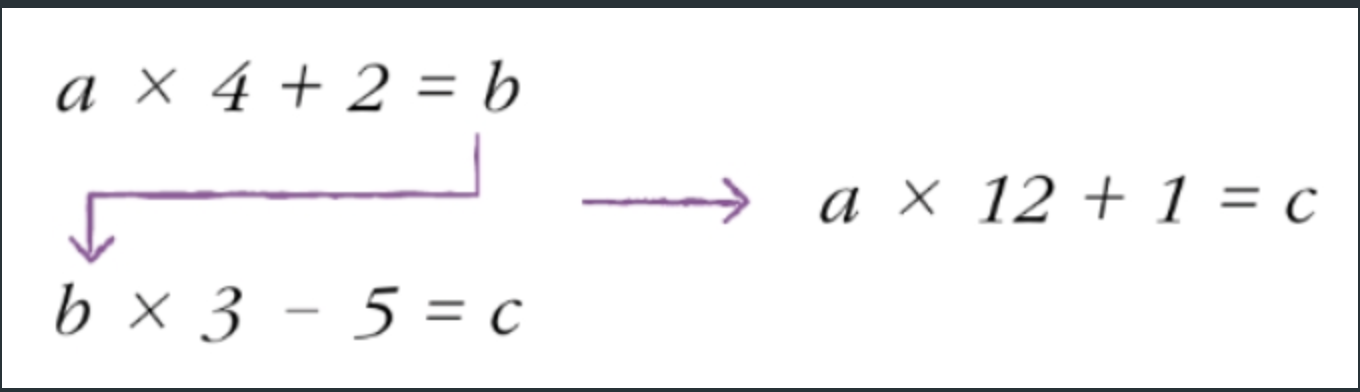
a = 입력층, b = 은닉층, c = 출력층이라고 가정하자.
만약 은닉층에 활성화 함수가 없으면(선형 수식이면) a와 c를 선형 모델로 치환할 수 있다.
그렇게 되면 왜 문제인가?
실제 데이터는 선형보다 비선형 구조를 가진 경우가 더욱 많다.
따라서, 선형 모델로만 학습시키는 경우는 빠뜨리는 특성도 많고 보다 정확하지 않은 예측 결과를 발생시킨다.
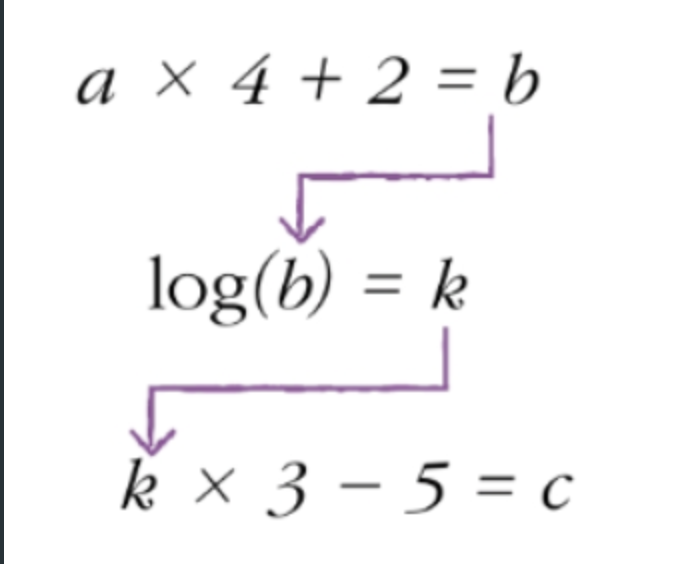
따라서 위의 수식과 같이 은닉층에 활성화 함수를 걸어 일부러 비선형 모델로 꼬아 만든다.
그러면 보다 복잡한 모델을 형성할 수 있고 이는 더욱 높은 학습율을 기록할 수 있게 만든다.
설계
사용 데이터 : 패션 MNIST

input: 28*28 image
output: 0~9 label
Layer 추가
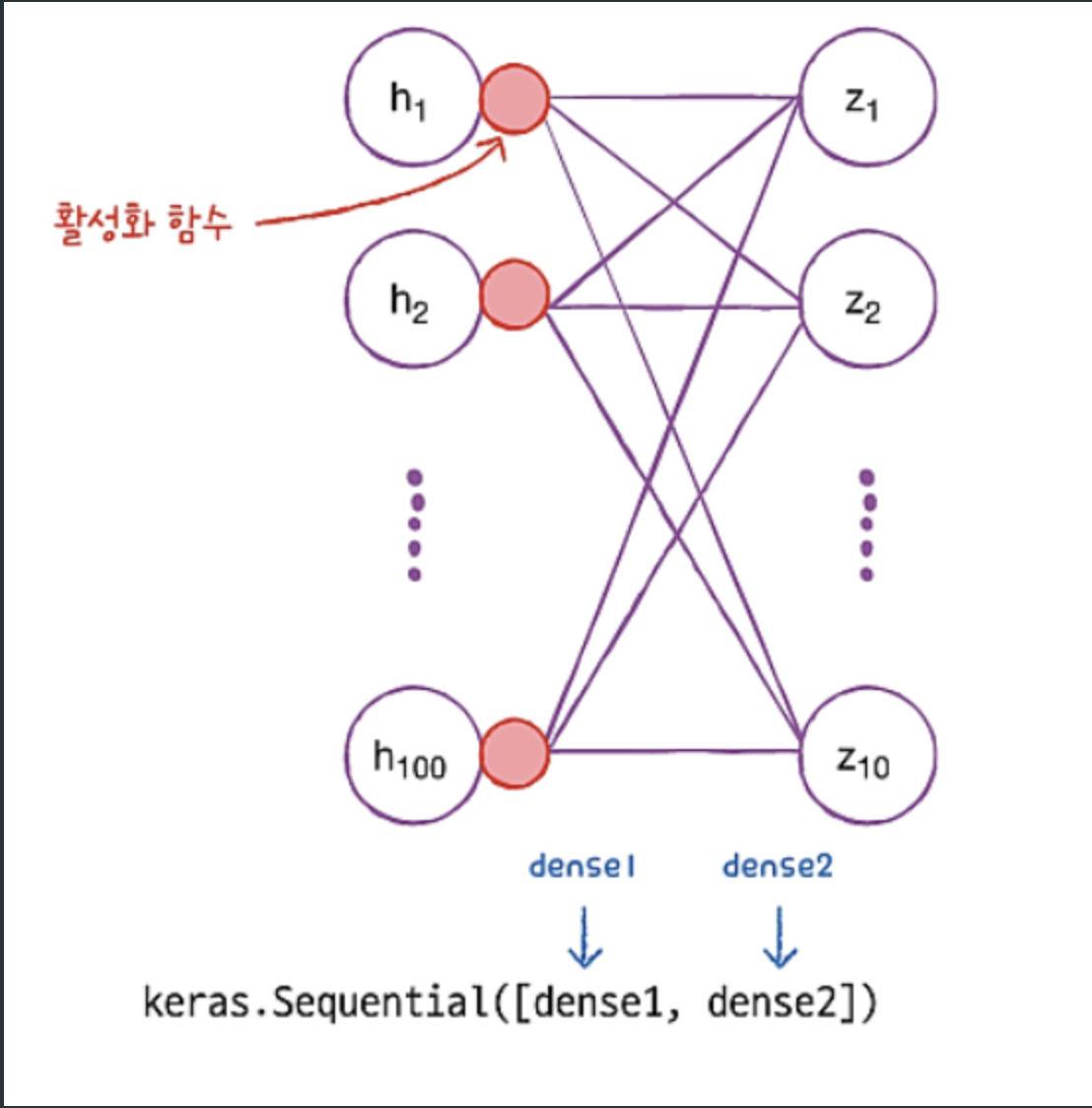
dense1 = keras.layers.Dense(100, activation='sigmoid', input_shape=(784,))
dense2 = keras.layers.Dense(10, activation='softmax')
model = keras.Sequential([dense1, dense2])
model.summary()dense1은 은닉층, dense2는 출력층을 의미한다.
은닉층 뉴런의 개수를 100개, 활성화 함수를 시그모이드로 설정했다.
인풋이 784개인 이유는 28*28 이미지를 1차원으로 펼치면 784개이기 때문이다.
실제 데이터를 예측하기 위해서는 보다 복잡한 모델이 필요하므로 은닉층을 여러 개 더 추가해보자.
model = keras.Sequential([
keras.layers.Dense(100, activation='sigmoid', input_shape=(784,), name='hidden1'),
keras.layers.Dense(100, activation='sigmoid', name='hidden2'),
keras.layers.Dense(100, activation='relu', name='hidden3'),
keras.layers.Dense(10, activation='softmax', name='output')
])
model.summary()2개의 sigmoid와 1개의 relu 은닉층을 추가했다.
나는 패션 MNIST 데이터로 연습을 하고 있으므로 10개의 출력층으로 softmax 함수를 이용했다.
compile / fit
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)우리는 다중 분류를 수행할 것이기 때문에 categorical_crossentropy를 사용.
평가 지표는 정확도를 채택.
evaluate
model.evaluate(val_scaled, val_target)loss: 0.3632 - accuracy: 0.8794
Optimizer
모델을 학습시킬 때, 다양한 경사 하강법 알고리즘을 적용할 수 있다.
이 때, 사용자는 어떤 경사 하강법 알고리즘을 쓸지 선택해야 하는데 이들을 optimizer라고 부른다.
방법 1
# optimizer를 선택하는 방법 1
model.compile(optimizer='sgd', loss='sparse_categorical_crossentropy', metrics='accuracy')방법 2
# optimizer를 선택하는 방법 2
sgd = keras.optimizers.SGD(learning_rate=0.01)
model.compile(optimizer=sgd, loss='sparse_categorical_crossentropy', metrics='accuracy')DropOut
🌟드롭아웃은 Overfitting 방지🌟
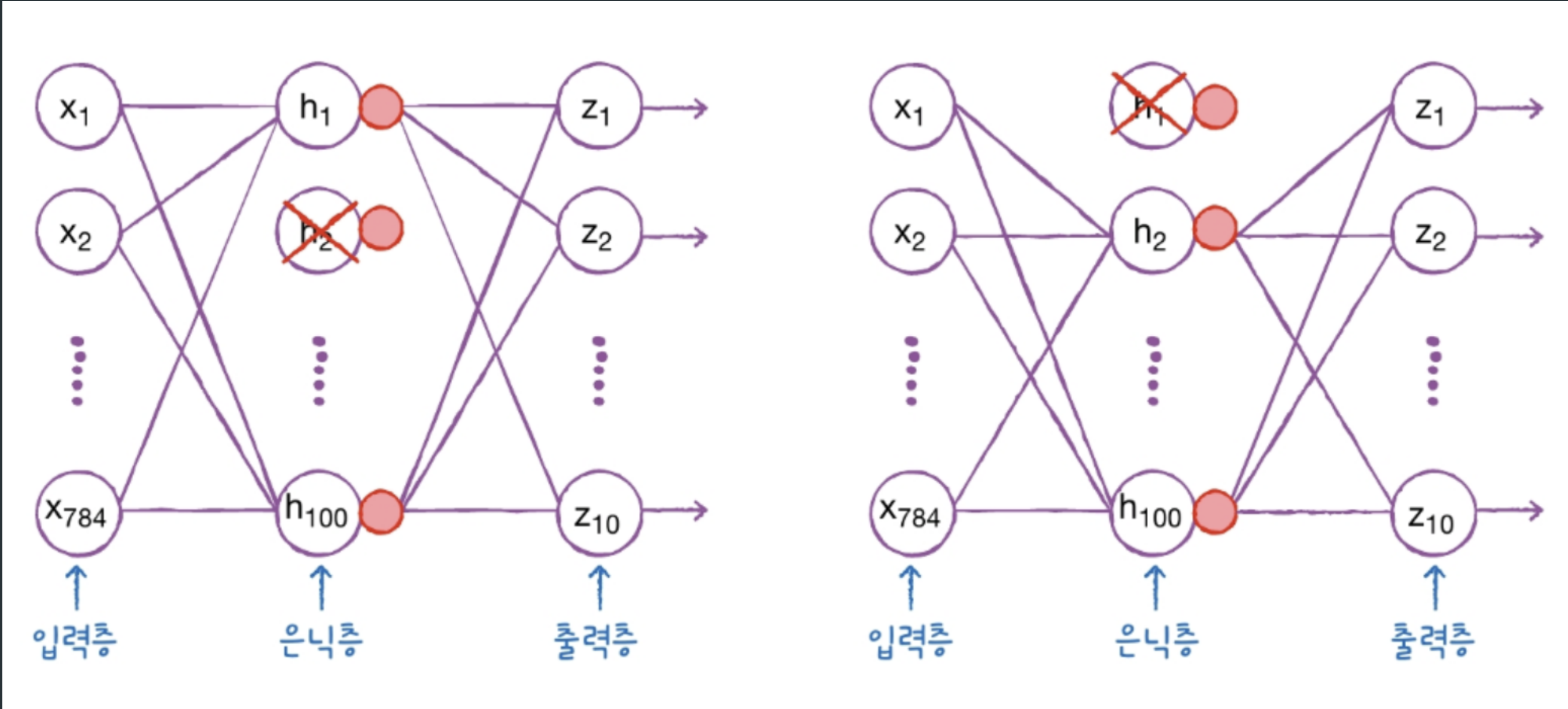
드롭아웃 기법에 대하여 플레이 데이터 강사님이 좋은 비유를 해주셨다.
군대에서 제설 작전을 한다고 하자
보통 말년 병장들은 설렁설렁 대충하고 일이병들이 열심히 뛰어다닌다.
각각의 병사를 뉴런에 빗댄다면 제설 작전 모델은 "일병"과 "이병" 뉴런에 의존도가 높다고 볼 수 있다.
그런데, 일이병이 훈련을 나가는 바람에 부대에 고참들 밖에 남지 않았다고 해보자.
그렇다면 결국 누군가는 눈을 치워야 하기 때문에 하기 싫은 병장들도 나서서 제설을 하게 될 것이다.
이게 바로 드롭아웃이다. 특정 뉴런에 너무 의존도가 높아버리면 overfitting이 발생할 여지가 있기 때문에 랜덤하게 뉴런들을 꺼버림으로써(출력을 0으로 만듦으로써) 더욱 안정적인 예측을 할 수 있도록 만든다.
사용 방법
keras.layers.Dropout(0.3)아까 전에 은닉층을 추가하듯이 추가하면 된다.
모델 저장과 복원
model.save_weights('model-weights.h5')save_weights 메서드를 이용하여 h5 확장자로 weight 값을 저장할 수 있다.
# 저장된 모델 로드하기
model = model_fn(keras.layers.Dropout(0.3))
model.summary()
model.load_weights('model-weights.h5')마찬가지로, load_weights 메서드를 이용해서 저장된 weight 값을 불러온다.
콜백
콜백 함수는 모델을 학습시키다가 최상의 weights값을 발견했을 때 저장하는 용도로 사용한다.
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-model.h5')훈련은 끝까지 시키지만 중간에 최적의 weights 값을 저장할 때 사용
early_stopping_cb = keras.callbacks.EarlyStopping(patience=2,
restore_best_weights=True)모델 성능이 더 나아질 기미가 보이지 않으면 멈춤
patience는 몇 번까지 참을 것인가
restore_best_weights는 최적의 weights를 저장할 것인가
