본 포스팅은 "혼자 공부하는 머신러닝+딥러닝"을 참고하여 제작하였습니다.
Convolution Neural Network
CNN은 이미지와 같은 2D 데이터를 처리하기에 적합한 알고리즘
그렇다면 Convolution이란 무엇일까?
여러개의 데이터를 하나로 만든다고 이해하면 편할 것이다.

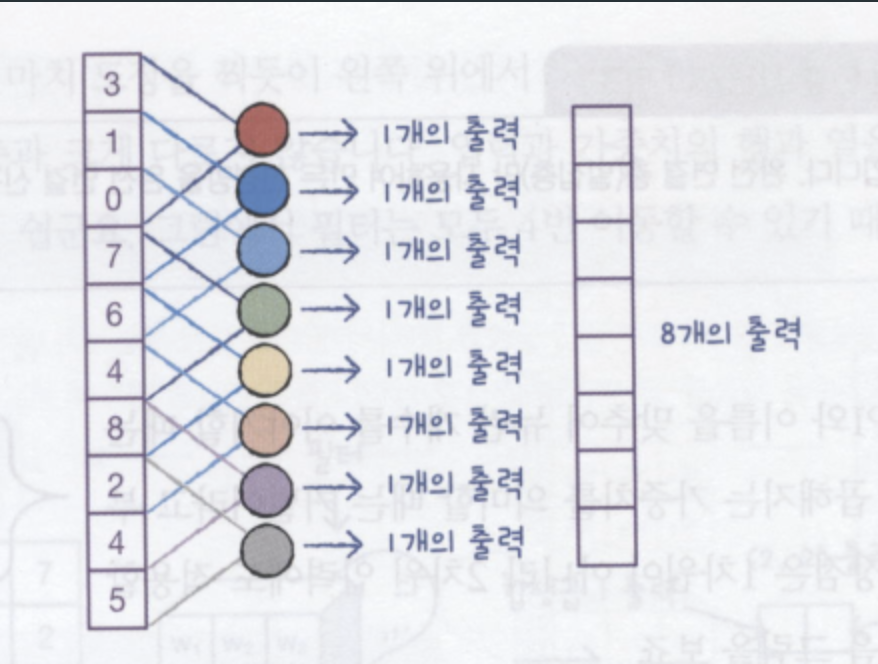
이를 2차원으로 확장하면 아래와 같다.
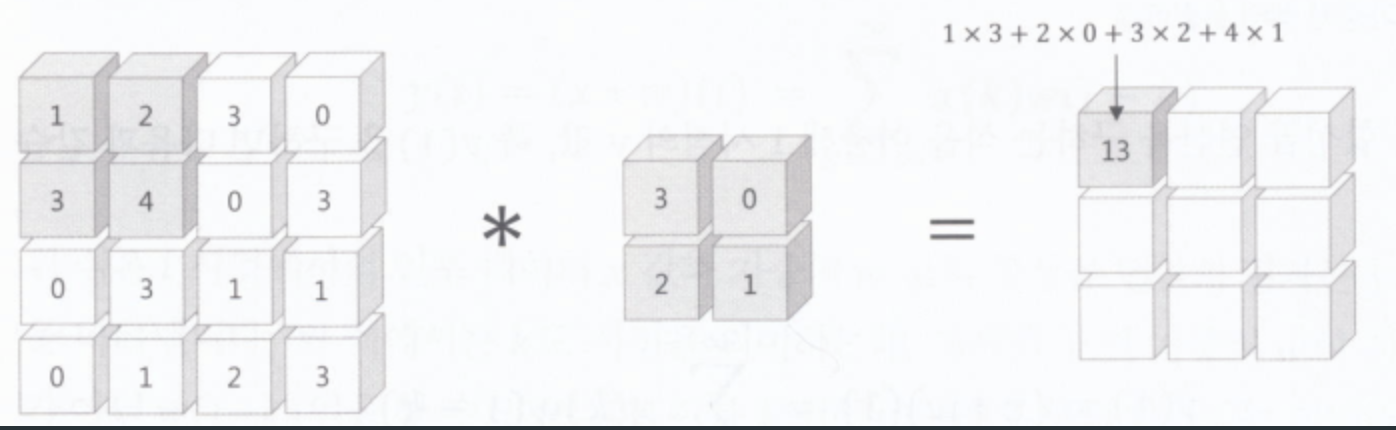
위 그림의 [[3,0],[2,1]]과 같은 것을 "필터" 혹은 "커널"이라고 칭한다.
그리고 이러한 convolution으로 얻은 출력을 "feature map"이라고 부른다.
패딩
패딩은 컨볼루션을 수행할 때 모든 feature가 feature map에 골고루 반영될 수 있도록 해준다.
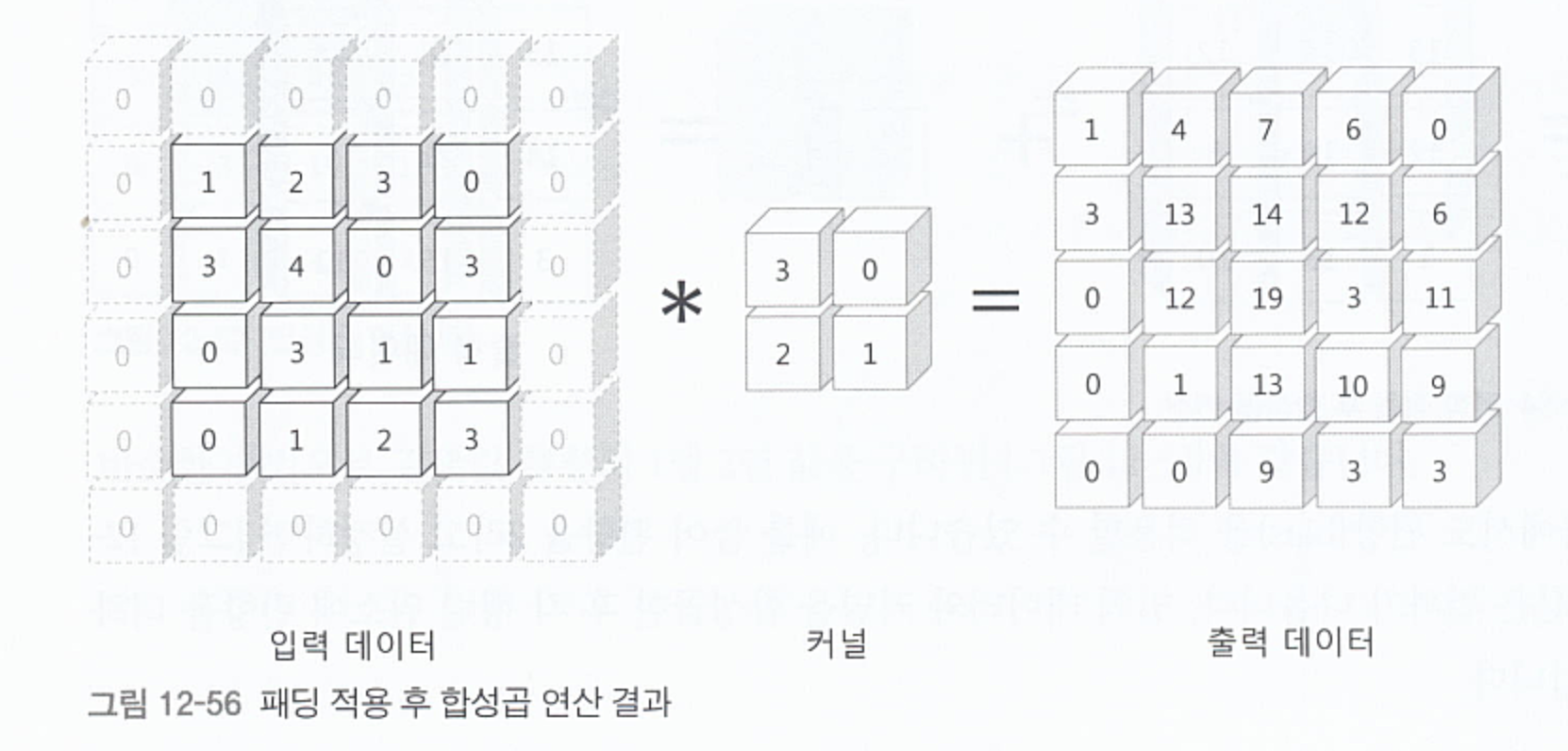
아래의 그림과 같이 컨볼루션을 하다보면 모서리에 있는 feature 보다 중앙에 있는 feature가 더욱 특성 맵에 영향을 많이 준다. 따라서, 기존 데이터를 최대한 중앙 쪽에 배치시켜 모든 feature가 골고루 반영될 수 있도록 한다.
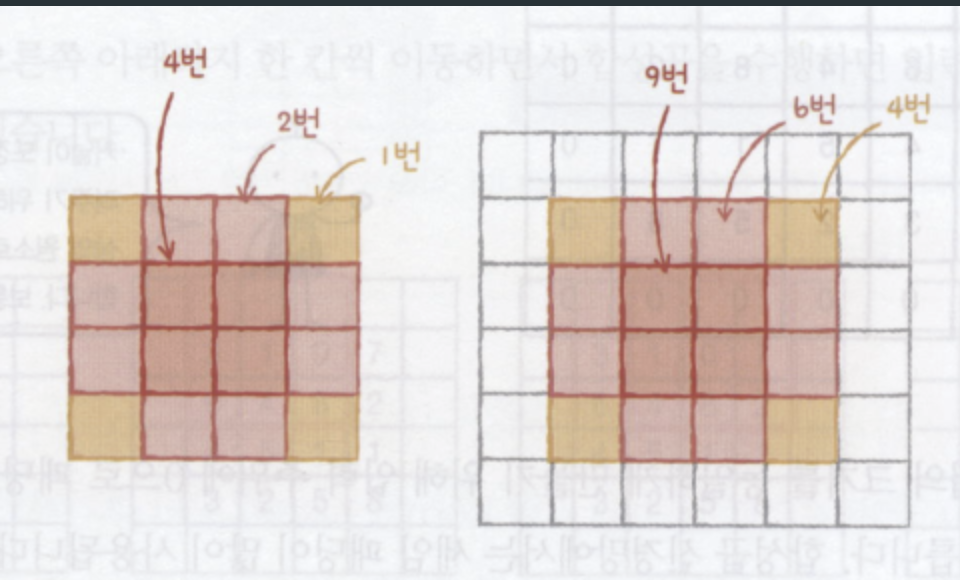
스트라이드 & 풀링
스트라이드와 풀링은 기존 컨볼루션보다 출력 데이터의 크기를 줄일 때 가져다 쓴다.
스트라이드
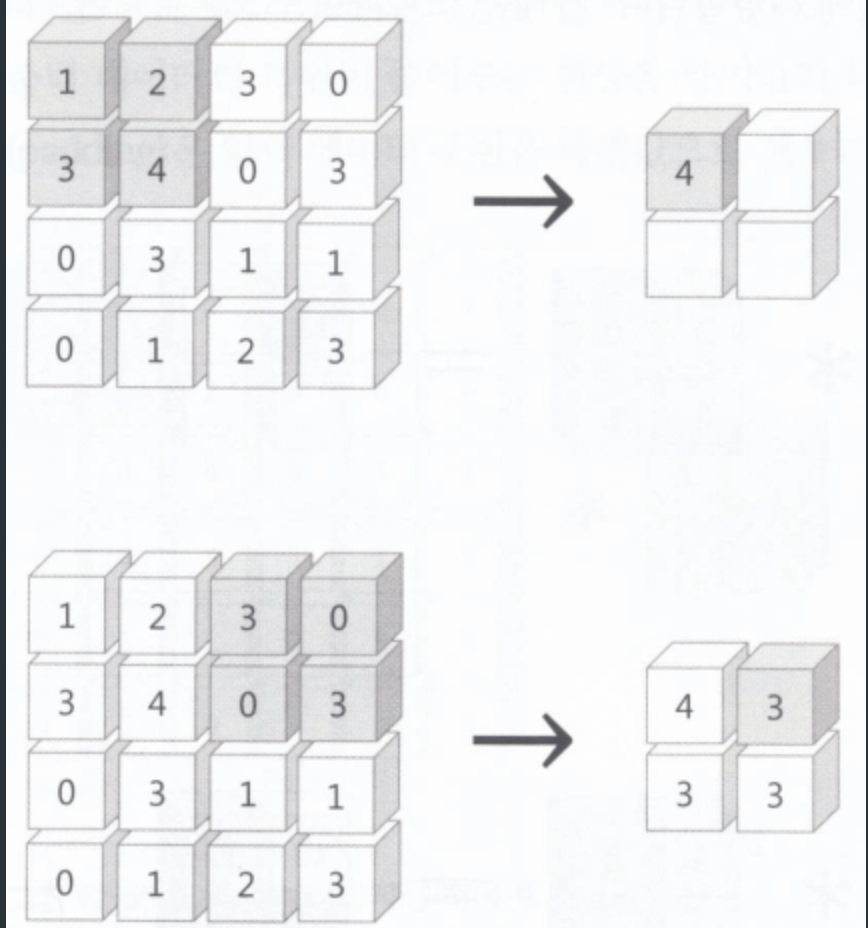
위 그림은 스트라이드를 2로 설정한 결과이다.
풀링
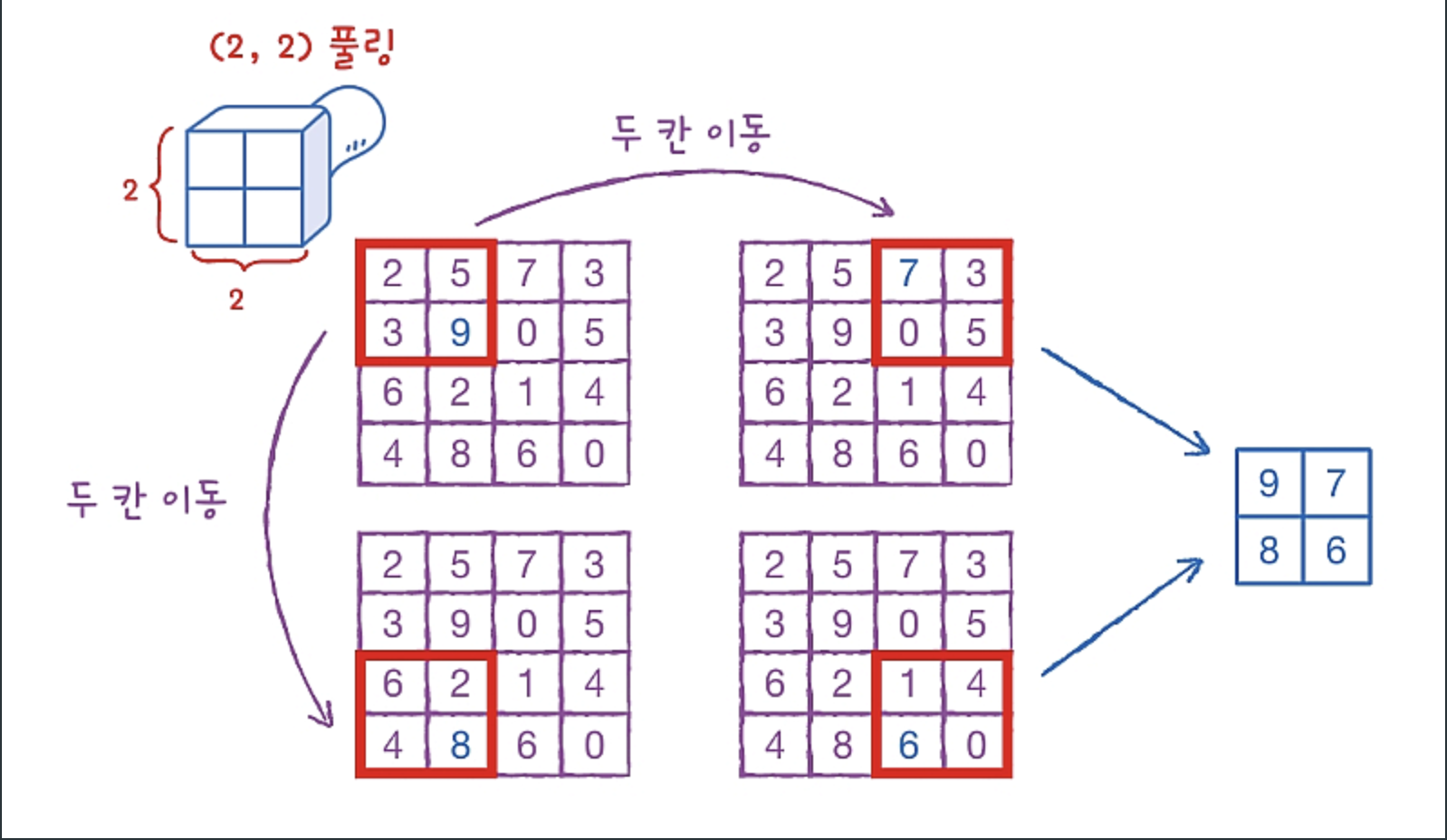
위 그림은 맥스 풀링을 적용한 예시이다.
맥스 풀링은 커널 영역에서 제일 큰 값을 선택한다.
컨볼루션 과정 설계도
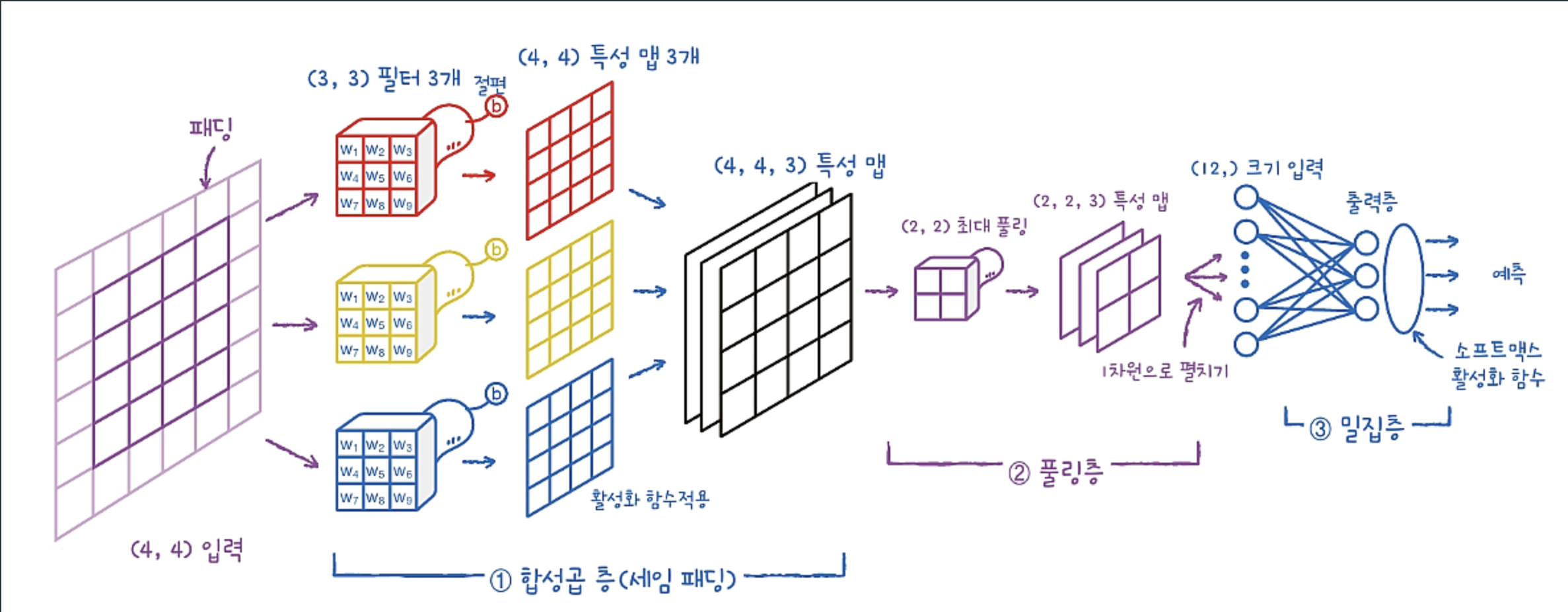
Keras에서 구현하기
입력 데이터 생성
from tensorflow import keras
from sklearn.model_selection import train_test_split
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()CNN 생성
model = keras.Sequential()
model.add(keras.layers.Conv2D(32, kernel_size=3, activation='relu', padding='same',input_shape=(28,28,1)))- 커널의 개수 = 32
- 커널 사이즈 = (3,3)
- same padding = 빈 공간을 전부 0으로 채우는 패딩
- input = 28*28 , 1 channel
model.add(keras.layers.MaxPooling2D(2))2*2 풀링 ➡️ 가로 세로 크기를 절반으로 줄인다.
model.add(keras.layers.Conv2D(64, kernel_size=(3,3), activation='relu', padding='same'))
model.add(keras.layers.MaxPooling2D(2))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dropout(0.4))
model.add(keras.layers.Dense(10, activation='softmax'))
model.summary()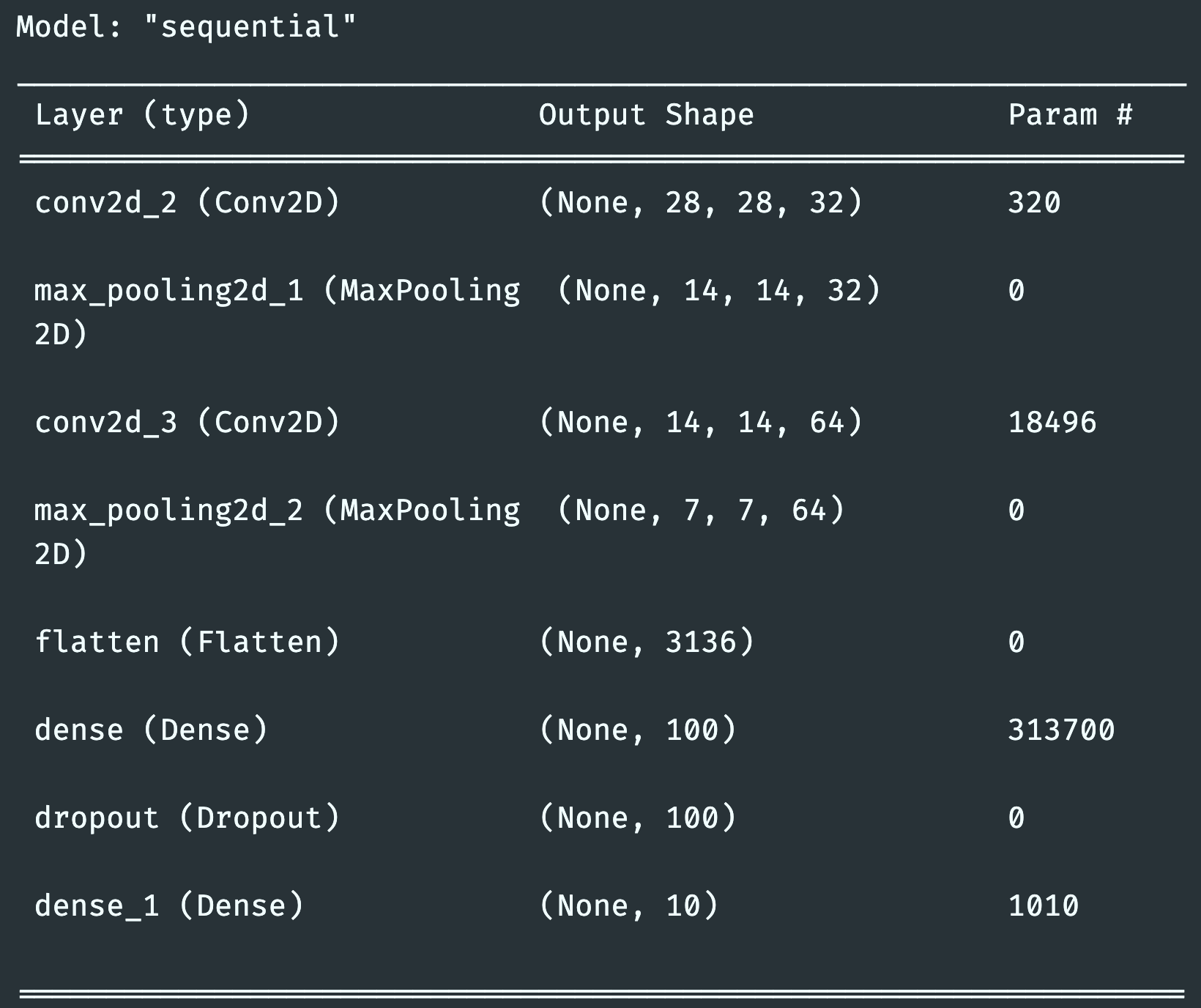
모델 컴파일과 훈련
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-cnn-model.h5')
early_stopping_cb = keras.callbacks.EarlyStopping(patience=2,
restore_best_weights=True)
history = model.fit(train_scaled, train_target, epochs=20,
validation_data=(val_scaled, val_target),
callbacks=[checkpoint_cb, early_stopping_cb])- adam optimizer
- categorical 손실 함수
- EarlyStopping 설정
model.evaluate(val_scaled, val_target)loss: 0.2188 - accuracy: 0.9207
확실히 DNN으로 했을 때보다 성능이 더 좋다.

0x68656C6C6F21