특징
- 지도학습은 데이터와 라벨링이 있다, X 그리고 y
- 비지도학습은 데이터만 있다, Only X
클러스터링
서로 유사한 데이터들은 같은 그룹으로, 서로 유사하지 않은 데이터는 다른 그룹으로 분리하는 것
목표
- 몇개의 그룹으로 묶을 것인가
- 데이터의 “유사도”를 어떻게 정의할 것인가 (유사한 데이터란 무엇인가)
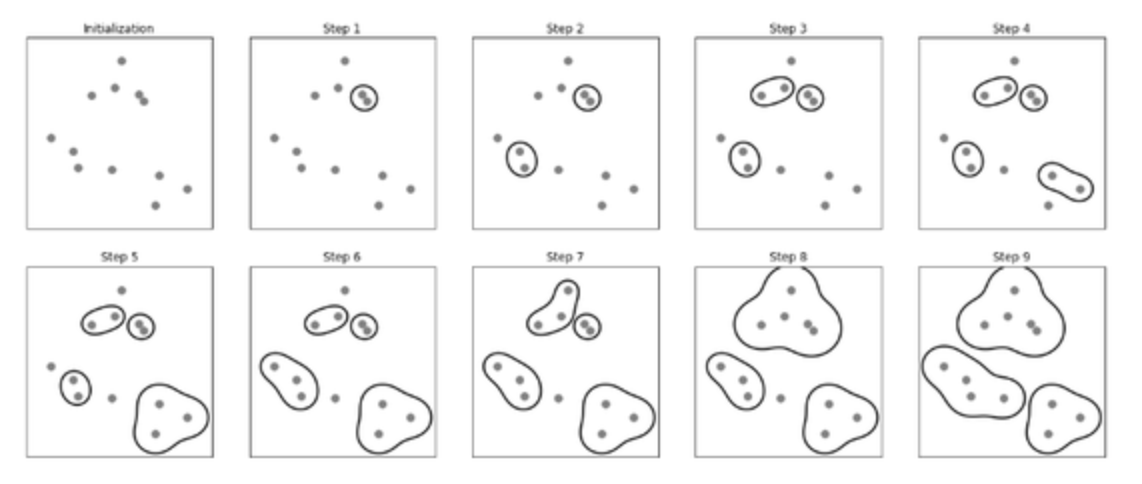
병합 군집
agglomerative clustering
- 특정 지점을 클러스터로 지정
- 종료 지점 도달까지 2개의 클러스터 병합
덴드로그램
- 병합 군집에서 군집 간의 구조적 관계를 살펴보는 도표

코드
from scipy.cluster.hierarchy import dendrogram, linkage
plt.figure(figsize=(10,5))
link_dist = linkage(df2,metric='euclidean',method='centroid')
dendrogram(link_dist,labels=list(df2.index))
plt.show()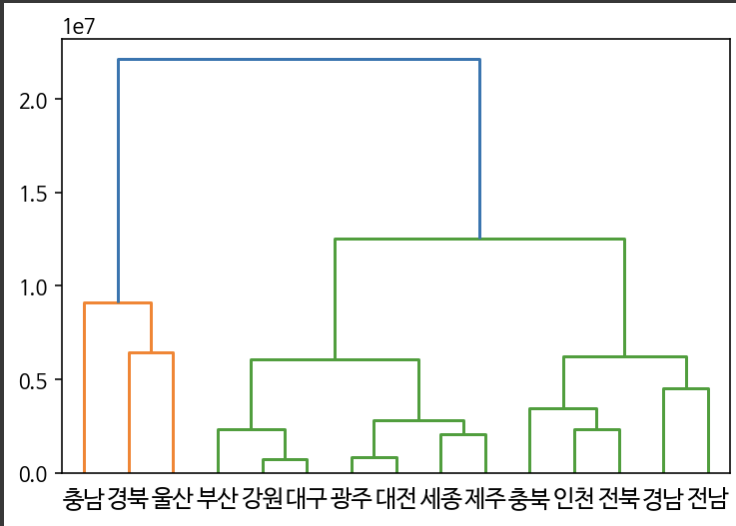
K-Means
- K: 클러스터 개수
- Means: 클러스터 중심까지 평균 거리
- means 축소가 목표
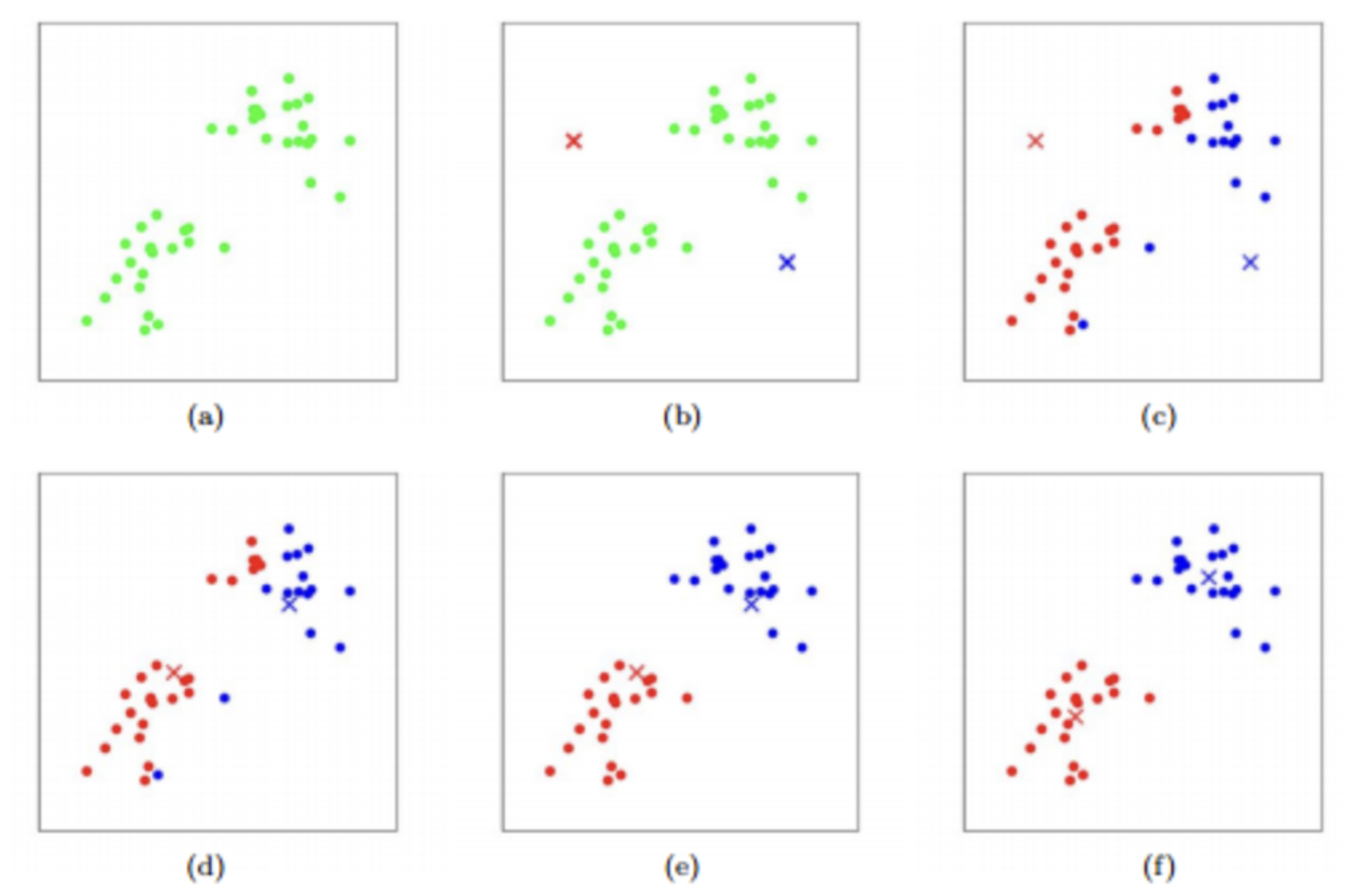
How
- k개 임의의 점 배치
- 군집 형성
- 중심점 업데이트
- 더 이상 중심점이 업데이트 되지 않을 때까지 2번과 3번 반복
코드
from sklearn.cluster import KMeans
km = KMeans(n_clusters = 3).fit(df)
km.labels_, km.cluster_centers_(array([0, 2, 1, 0, 0, 0, 0, 0, 1, 2, 2, 2, 0, 1, 2], dtype=int32),
array([[ 4191629.42857143, 3805868.14285714],
[ 6433742.33333333, 31018896. ],
[ 6245553.6 , 16144968.6 ]]))
- n_clusters = K
- km_labels , data frame index에 대하여 라벨링
- km.clustercenters , K 좌표
스케일링
데이터들을 [평균=0 , 표준편차=1]로 만드는 작업
-return: array
코드
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
df[['피쳐0','피쳐1']] = scaler.fit_transform(df[['피쳐0','피쳐1']])DBSCAN
Density-based spatial clustering of applications with noise
- 중요 포인트: Density-based = 밀도 기반
- k-means는 거리 기반 군집 형성
- 반면, DBSCAN은 반경 내 데이터 개수 기반으로 군집 형성
반경 5 이내, 데이터 개수가 10개 이상이면 군집으로 인정한다!
how

- p를 기준으로 거리 e(epsilon)만큼 설정
- 데이터 개수 5 >= 4 이므로 군집 형성
- p = core point
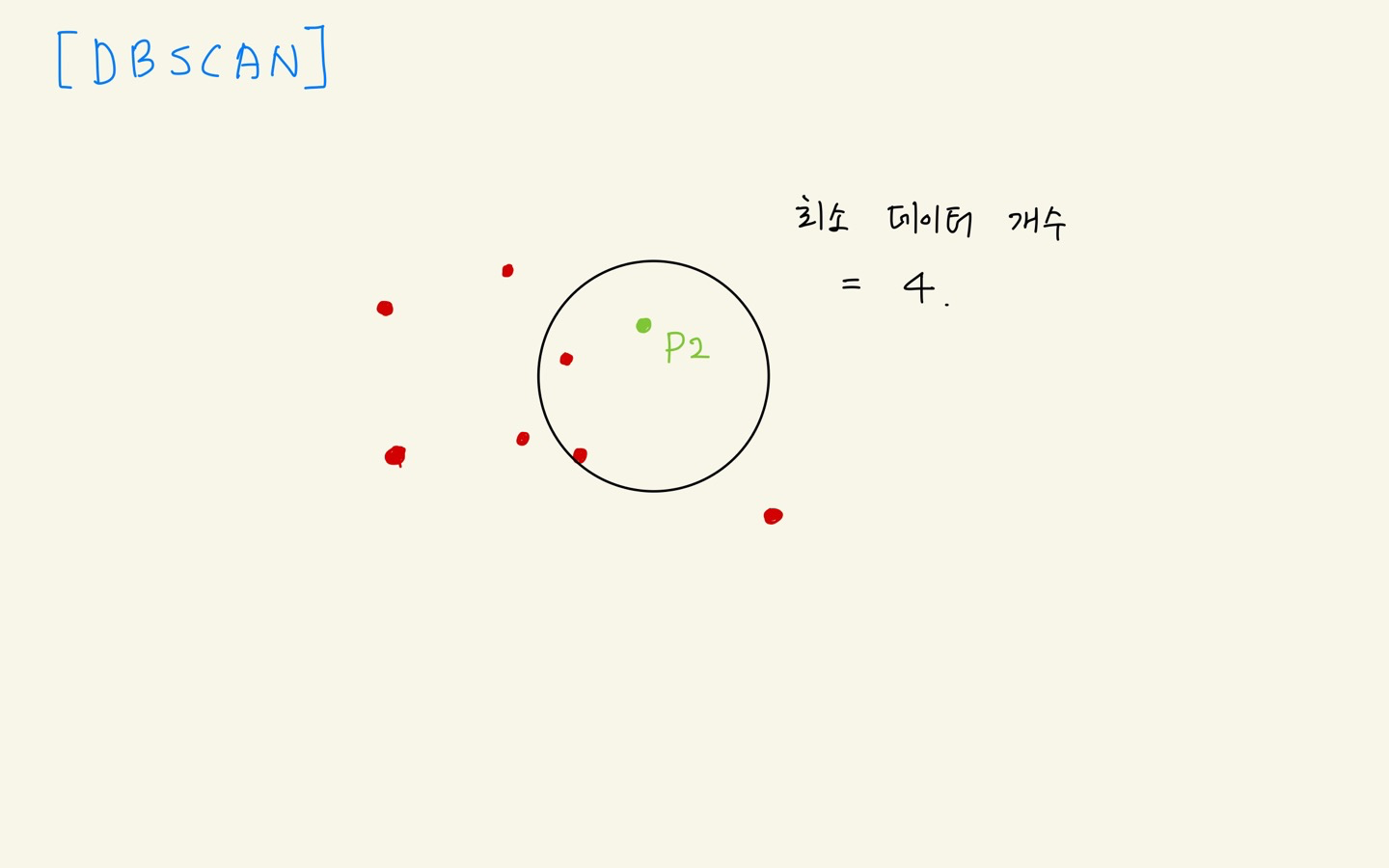
- p2를 기준으로 데이터 개수 3 <= 4 이므로 군집 불가
- p2는 p 군집에 속해있음
- p2 = border point
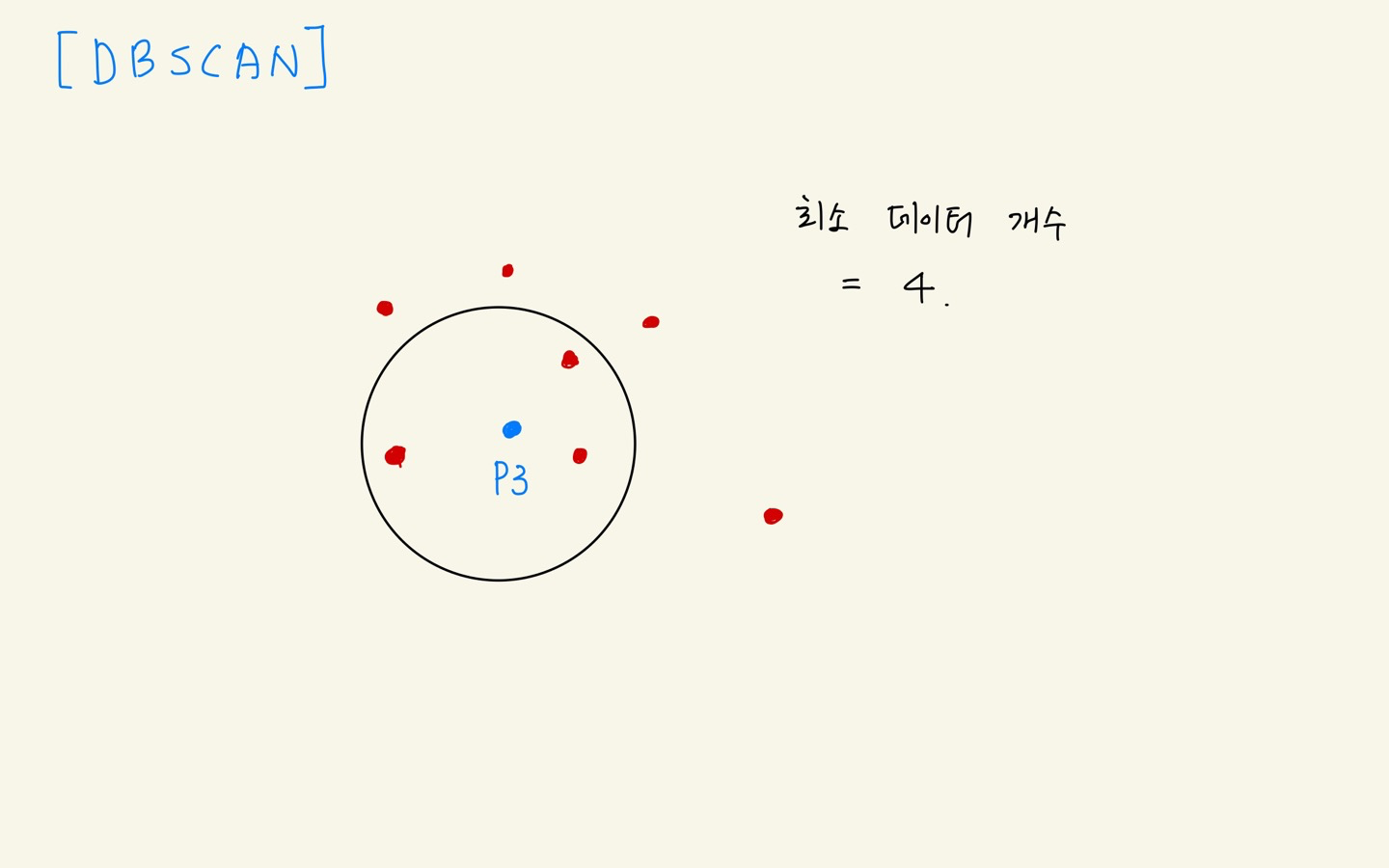
- p3 데이터 개수 4 >= 4 , 군집 형성
- p3 = core point
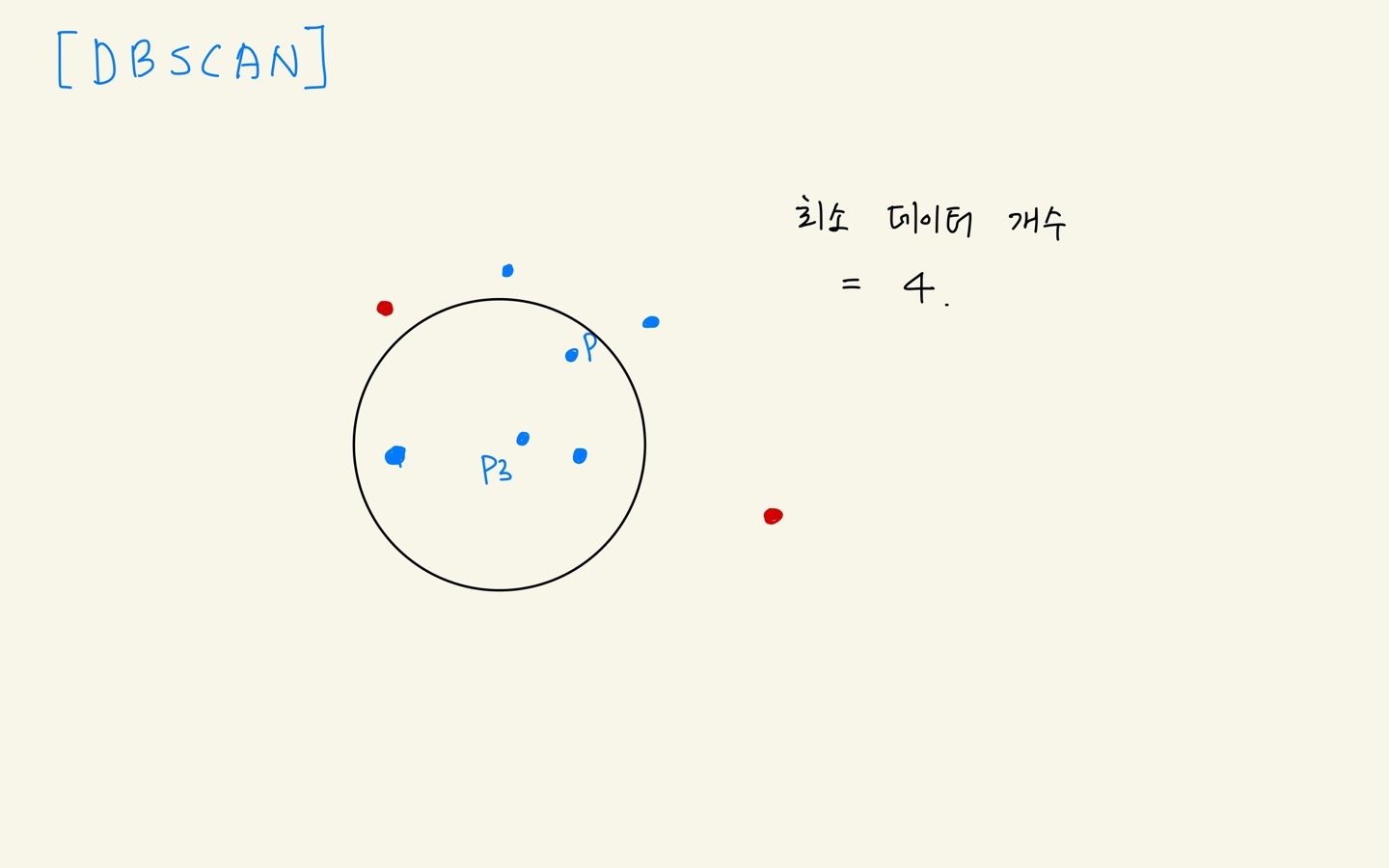
- p in p3 군집
- p 군집과 p3 군집 병합

- p4는 군집 형성 불가 & 어느 군집에도 속하지 않음
- p4 = outlier
최종

코드
dbscan = DBSCAN(eps=거리, min_samples=정수, metric='euclidean')
predict = dbscan.fit_predict(X)
plt.scatter(X[:,0],X[:,1],c=predict)K-Means와 비교
K-Means
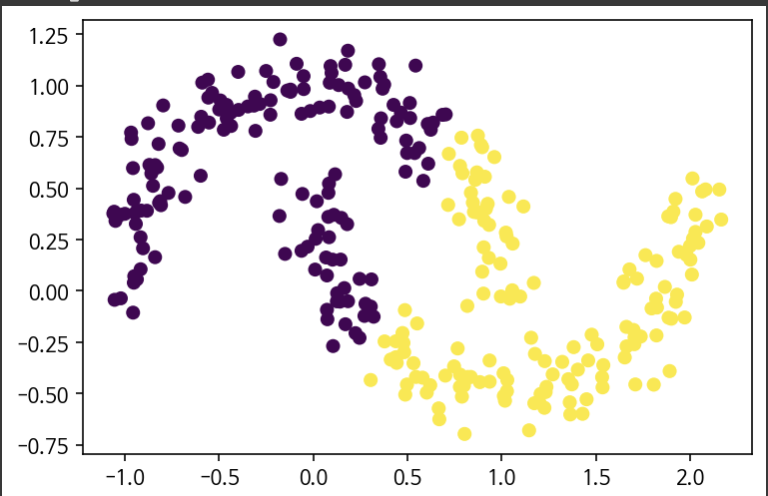
DBSCAN

Dimension Reduction
why???
- 데이타를 분석할때 피쳐가 많으면 데이타 분석이 어렵고, 특히 3개 이상 (3차원)의 피쳐가 존재할 경우 시각화가 어려워진다
- 따라서 feature를 줄여줘야 하는데 이 때 쓰는 여러가지 기법들이 있다.
feature selection
- statistical analysis(f-test) 👉🏻 p-value
- Decision Tree
- Lasso
feature extraction
PCA
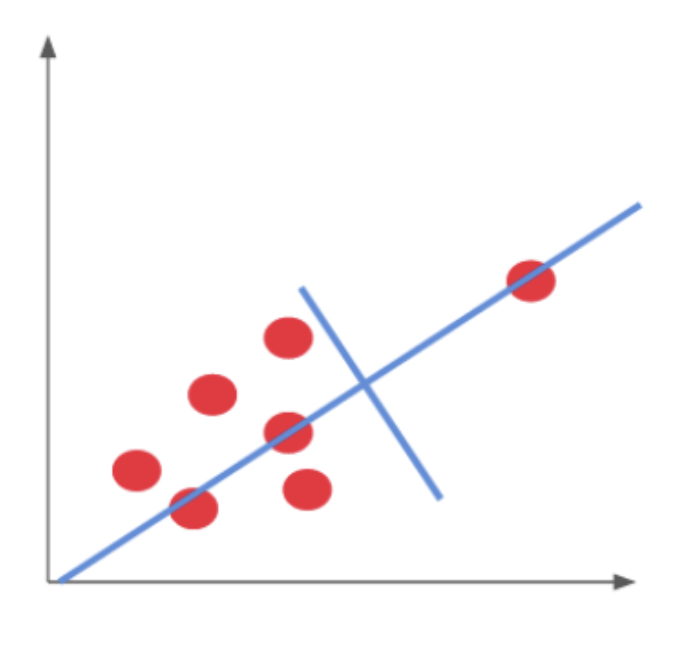
이러한 데이터들을 ...

이렇게 축 회전을 시켜 변화축이 큰 축(x축) 기준으로
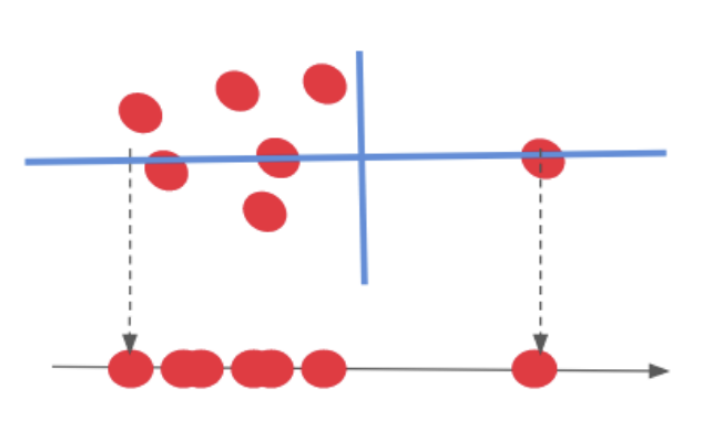
차원을 축소시키는 기법을 말한다. 나도 이해가 잘 안가서 대충 적어보았다.
tSNE
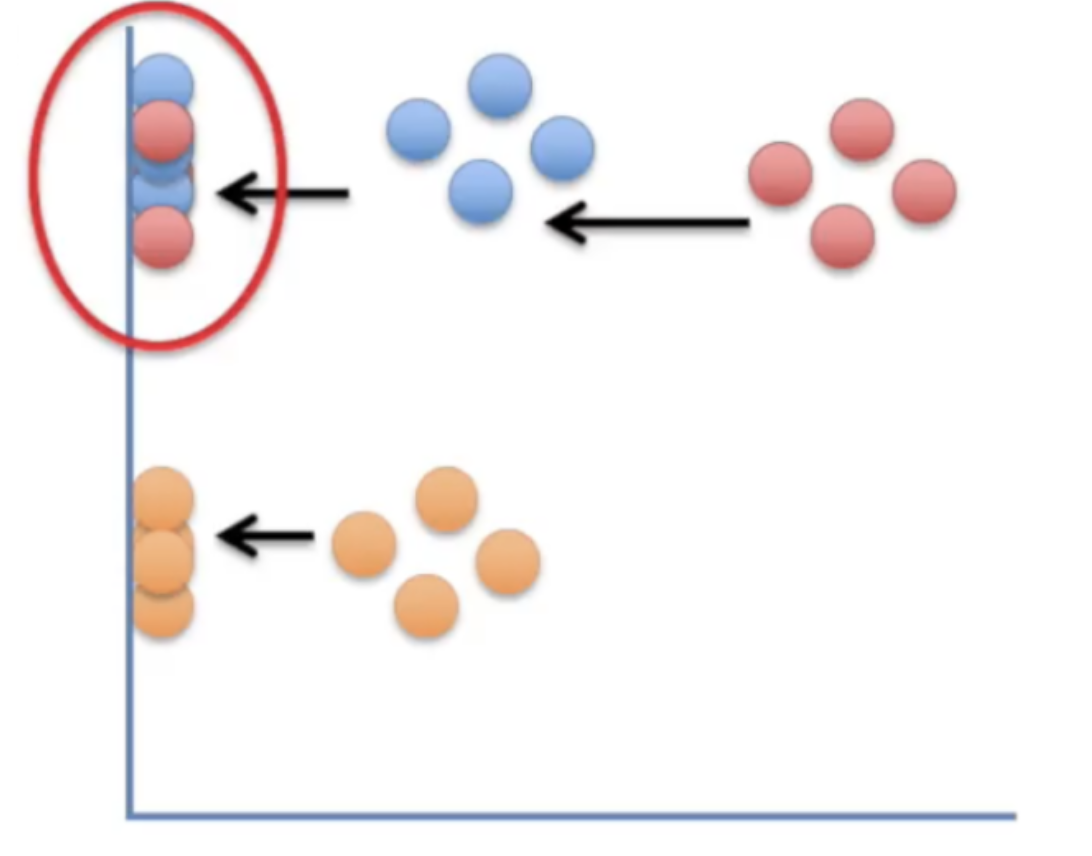
PCA는 위와 같은 문제점이 있다. 분명 잘 구분되는 파랑과 빨강이었지만 차원축소를 한 결과 두 카테고리가 겹치는 불상사가 발생하였다.
t-SNE는 방금과 같은 문제점을 해결하기 위하여 고안되었다.

0x68656C6C6F21