overfitting/underfitting
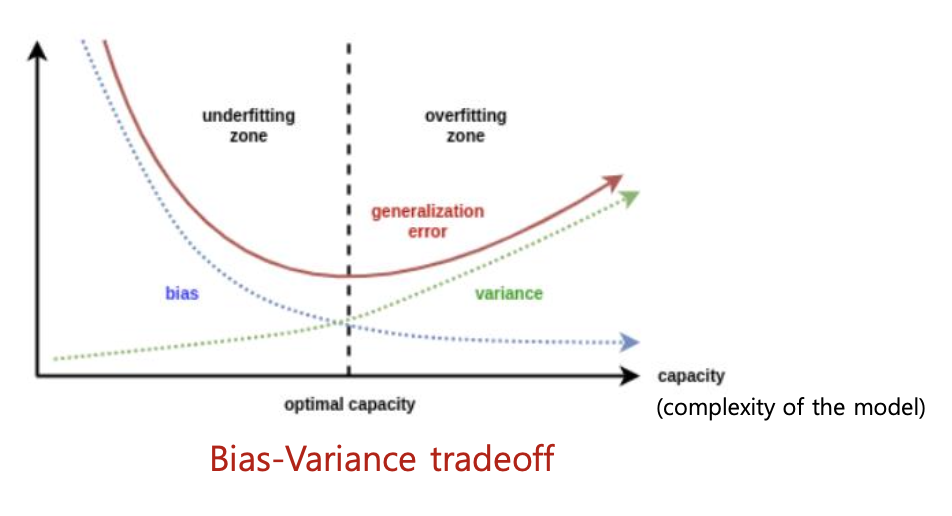
- 모델을 너무 단순화하여 error가 많이 발생할 때: underfitting
- 모델을 테스트 데이터에 대하여 심하게 학습하여 테스트에서만 효율이 좋을때 : overfitting
overfitting 이유
- dataset is too small
- model is too complex
Regularizer
- 모델이 너무 복잡할 때 오버피팅을 방지해주는 해결책
Exam!!
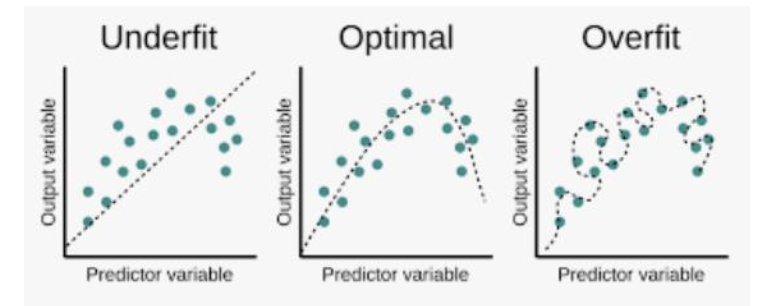
- Overfitting을 Optimal로 변환해주는 것
- 한국어 = 규제화
MSE = sum[(y_predict - y)^2]/N
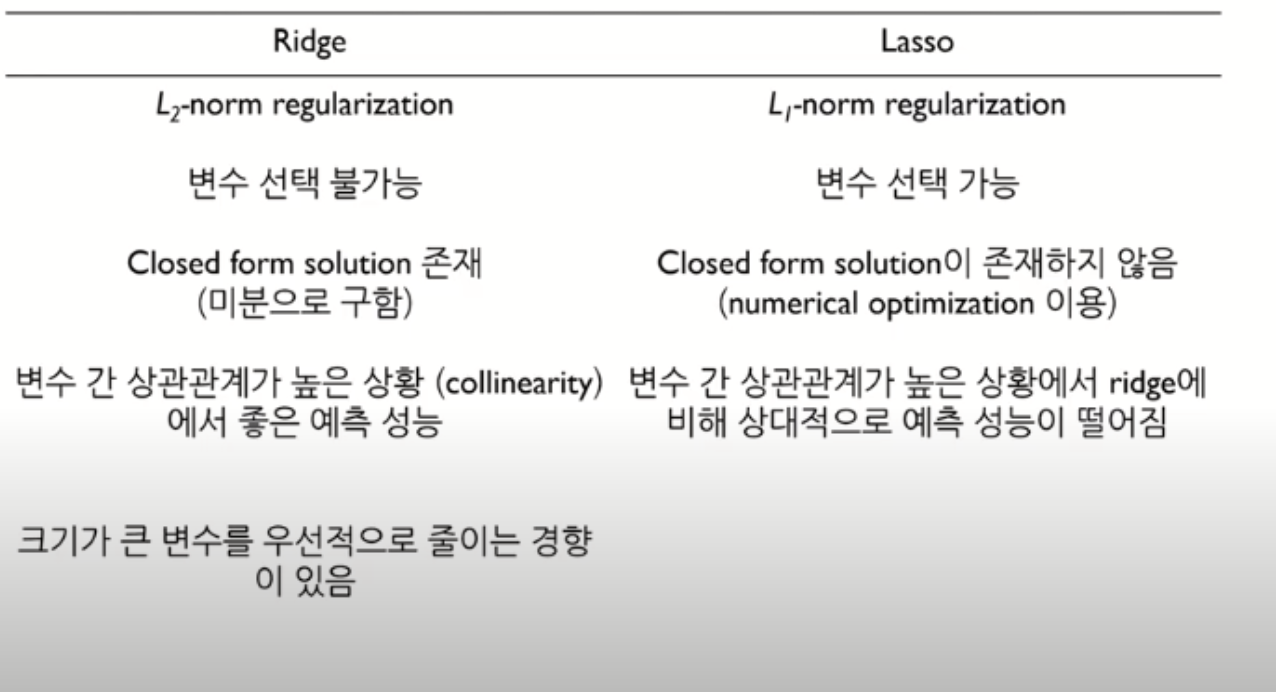
Ridge , L2-Req
- Loss = MSE + alpha*abs(sum(w_i))^2
Lasso, L1-Req
-
Loss = MSE + alpha*abs(sum(w_i))^1
-
alpha에 따라서 규제화 정도를 조절할 수 있다.
-
alpha를 크게 설정할수록 w가 줄어드는 값이 크므로 커브를 더욱 linear하게 펼 수 있다.
Ridge / Lasso
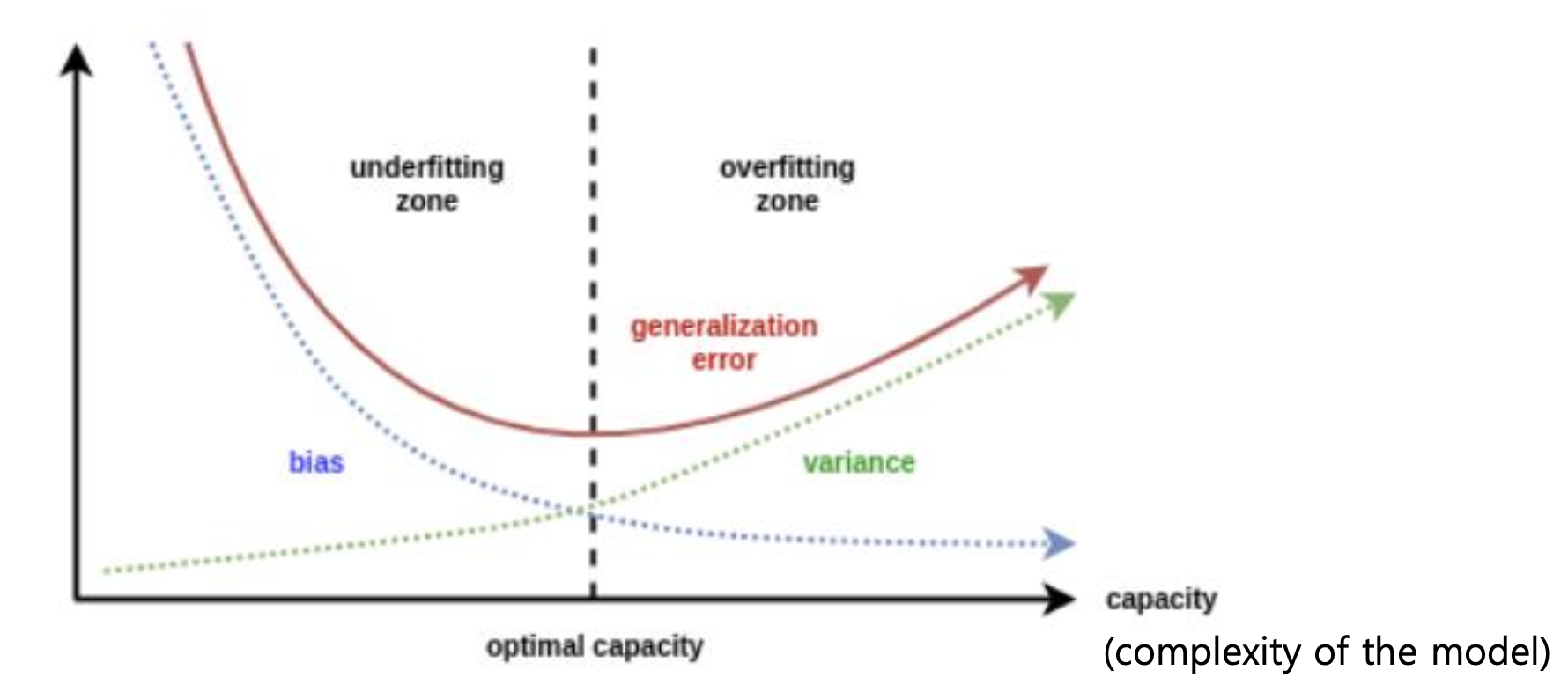
Bias/Variance
-
bias = train data
-
generalization error = test data
-
total error = Bias + Variance + noise
K-Fold
최적의 파라미터를 찾기 위하여
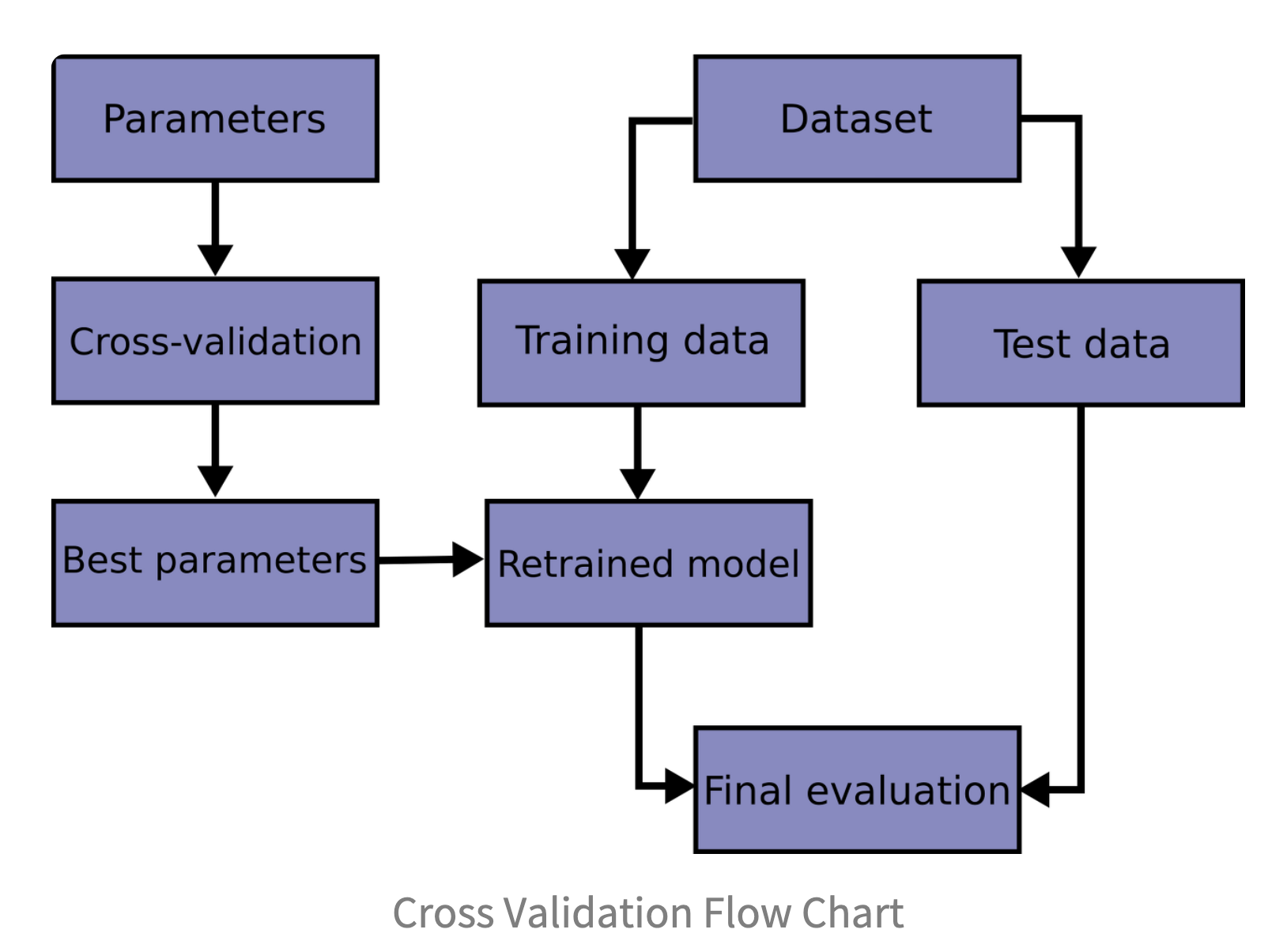
How???
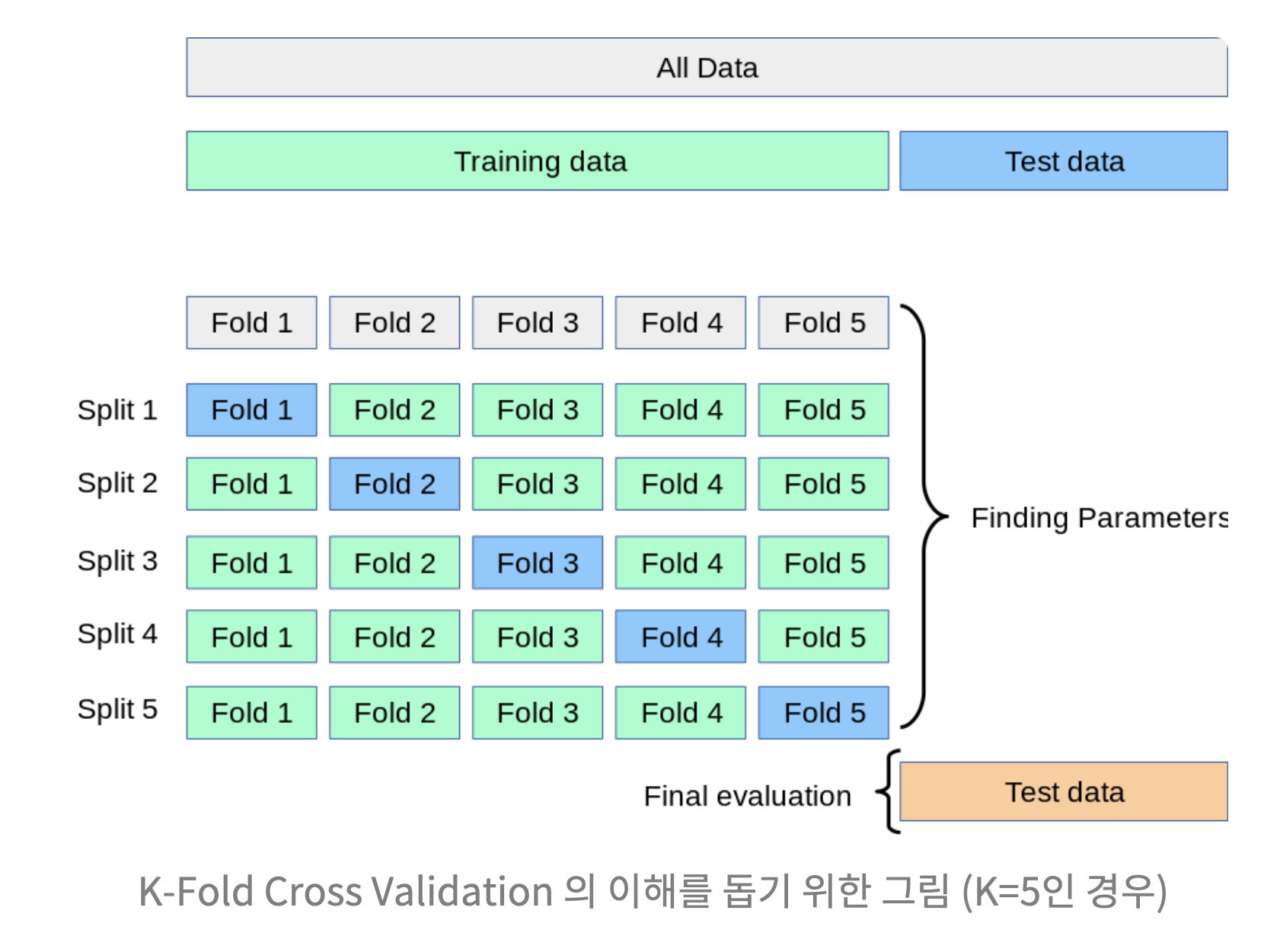
- K 선정
- K-1개 그룹을 훈련 데이터 , 1개 그룹을 테스트 데이터로 사용
- K번 검증된 결과의 평균 측정
Tuning Hyperparameter
하이퍼파라미터 튜닝은 딥러닝에서 최적화를 위해 사용한다.
| HyperParameter | Parameter | |
|---|---|---|
| 설명 | 초매개변수 모델 학습 과정에 반영되는 값 학습 시작 전에 미리 조정 | 매개변수 모델 내부에서 결정되는 변수 데이터로부터 학습 또는 예측되는 값 |
| 예시 | 학습률 손실 함수 배치 사이즈 | 정규분포의 평균 표준편차 선형 회귀 계수 가중치, 편향 |
| 직접 조정 | O | X |
Optimization
딥러닝에서 최적화란 딥러닝 모델이 최적의 파라미터를 찾아가는 것을 의미한다
하이퍼파라미터 설정 세 가지 요소
1. objective function: 최대화 혹은 최소화 해야하는 함수
2. search boundary: 탐색 범위
3. step: 탐색 시 간격
objective function을 optimize 하는 방향으로 범위 및 간격을 설정
Grid Search
- 완전 탐색
- 시간이 오래 걸린다는 단점
Random Search
- 정해진 범위 내에서 랜덤하게 선택
- 시간은 빠르지만 optimized solution이 아닐 수도 있음
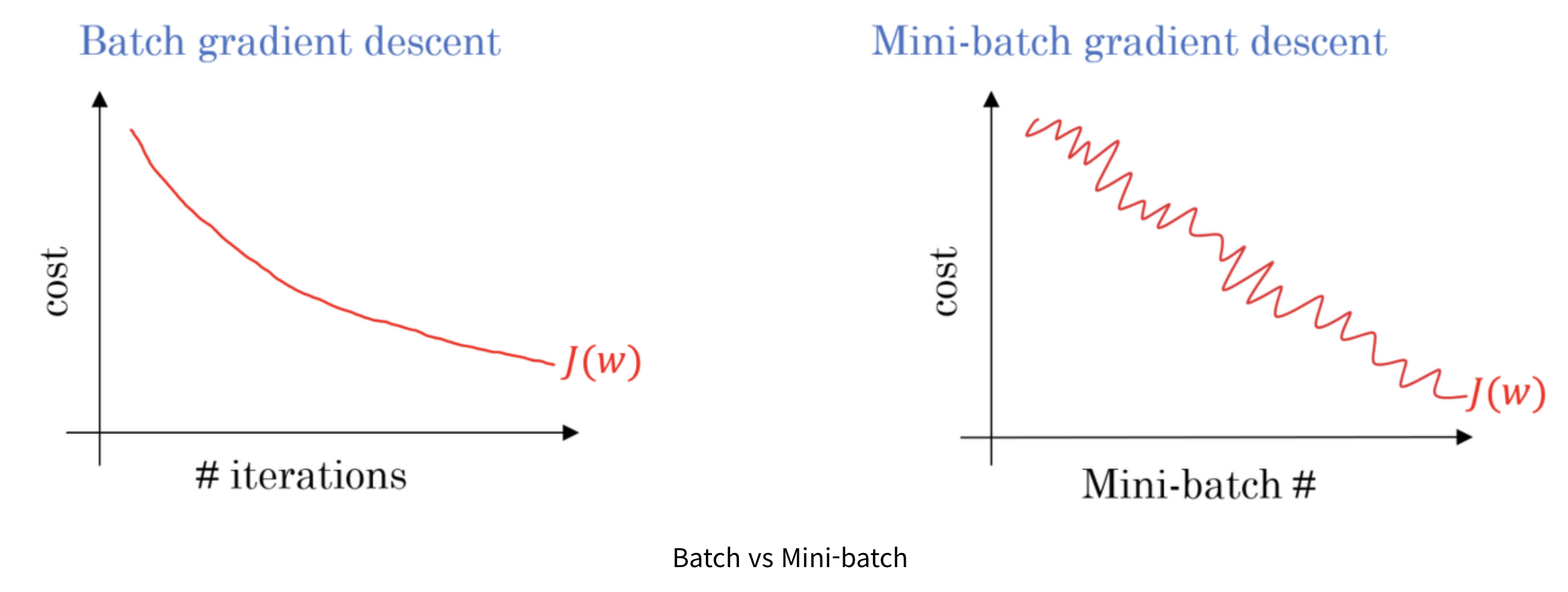
미니 배치
경사 하강법을 더욱 빠르게 수행하여 빠른 최적화를 보장한다. 왜냐하면 배치로 경사하강법을 수행하면 전체 데이터의 개수가 많기 때문에 하나의 에포크에 처리양이 많기 때문이다.
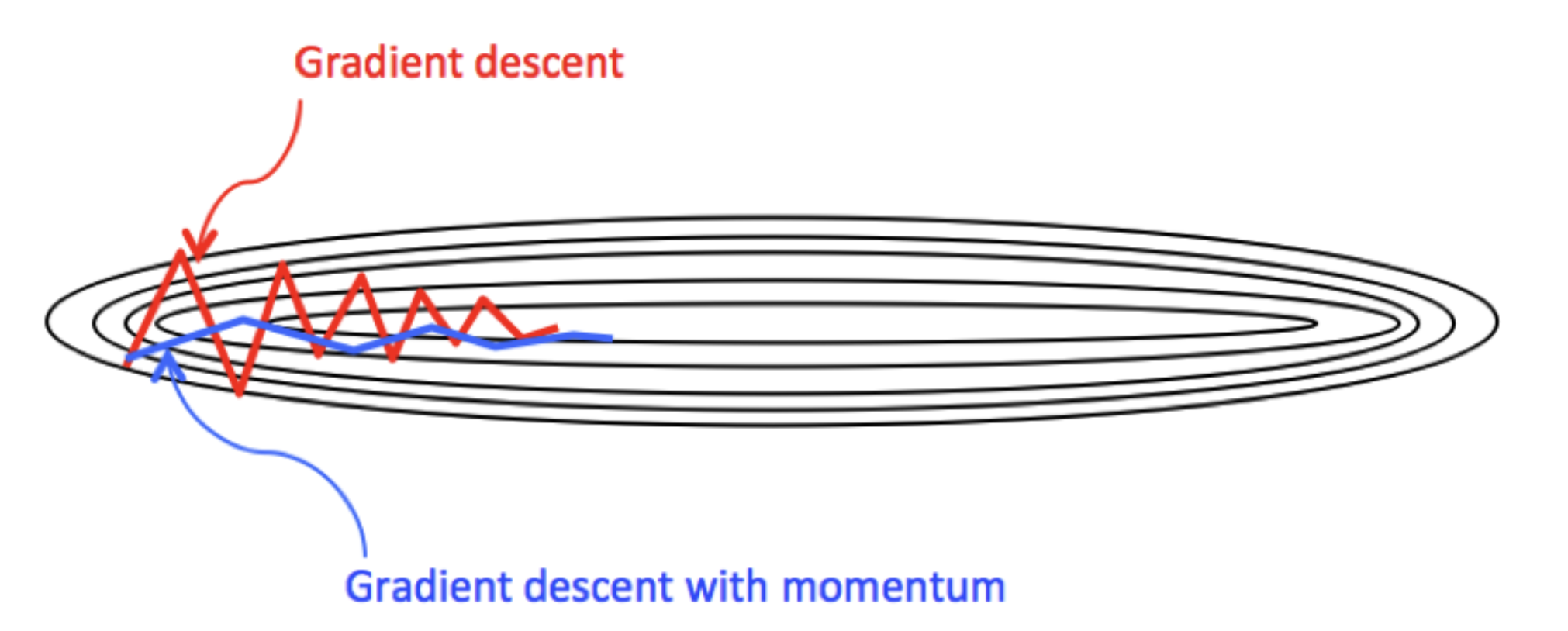
모멘텀
위 아래로 발산하는 폭을 줄여준다. 이를 통해 빠른 최적화를 수행한다.
RMSProp
모멘텀과 마찬가지로 발산하는 폭을 줄여 빠른 최적화를 이끈다.

0x68656C6C6F21