
📌 5차 미니 프로젝트 - AICE 대비

미니프로젝트 5차 10.23.-10.27. 중 10월 23, 24 이틀 동안 AICE 대비를 했습니다!


내용도 복습할 겸, AICE 샘플문항을 통해 정리해보고자 합니다!
1. 파이썬 패키지 불러오기
import sklearn as sk
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt2. 데이터 파일 읽어오기
df = pd.read_json(path)
df = pd.read_csv(path)
3. 분포도 알아보기
count plot
sns.countplot(data = df, x = 'Address1')
plt.show()
idx_address = df.loc[df['Address1'] == '-'].index
df.drop(idx_address, inplace = True)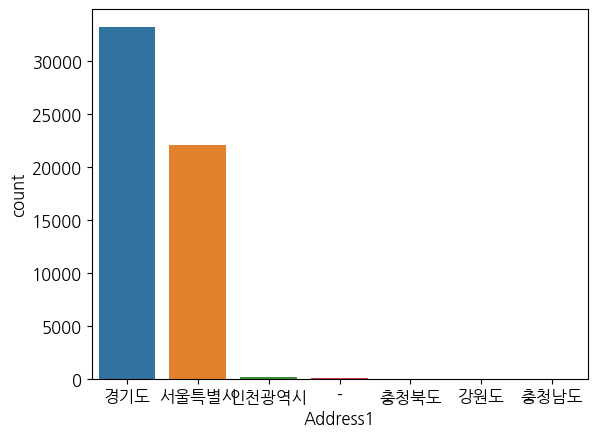
joint plot
sns.jointplot(x='Time_Driving', y='Speed_Per_Hour', data=df)
plt.show()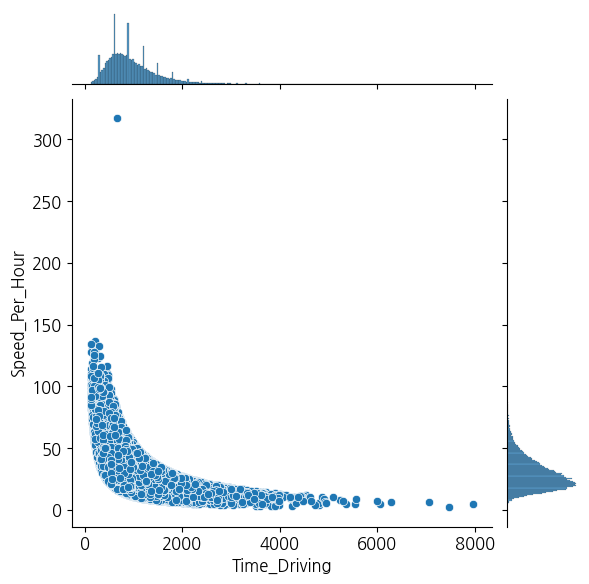
4. jointplot 그래프에서 시속 300이 넘는 이상치 삭제
idx_out = df.loc[df['Speed_Per_Hour'] > 300].index
df.drop(idx_out, inplace = True)
df_temp = df.copy()5. 결측치 처리
print(df_temp.isnull().sum())
df_na = df_temp.dropna()
print(df_na.isnull().sum())6. 불필요한 변수 삭제
df_del = df_na.drop(['Time_Departure', 'Time_Arrival'], axis = 1)7. 원-핫 인코딩(One-hot encoding)
df_del.info()
object_cols = df_del.select_dtypes(include='object').columns
df_preset = pd.get_dummies(df_del, columns=object_cols)원하는 데이터타입 컬럼 추출: select_dtypes
8. target 컬럼에 대해 데이터 셋 분리
from sklearn.model_selection import train_test_split
target = 'Time_Driving'
y = df_preset[target]
X = df_preset.drop('Time_Driving', axis=1)
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.2, random_state=42)9. 머신러닝 및 성능 평가
from sklearn.tree import DecisionTreeRegressor
model = DecisionTreeRegressor(max_depth=5, min_samples_split=3, random_state=120)
model.fit(X_train, y_train)from sklearn.metrics import mean_absolute_error
y_pred = model.predict(X_valid)
dt_mae = mean_absolute_error(y_valid, y_pred)10. 딥러닝
import tensorflow as tf
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.layers import Dense, Activation, Dropout, BatchNormalization
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
from tensorflow.keras.utils import to_categorical
tf.random.set_seed(1)- 모델링하고 학습을 진행
# 여기에 답안코드를 작성하세요.
from sklearn.metrics import mean_squared_error
model = Sequential([
Dense(64, activation='relu',
input_shape=(X_train.shape[1],)),
BatchNormalization(),
Dropout(0.2),
Dense(32, activation='relu'),
BatchNormalization(),
Dropout(0.2),
Dense(16, activation='relu'),
BatchNormalization(),
Dropout(0.2),
Dense(1)
])
model.compile(optimizer = 'adam',
loss = 'mean_squared_error')
history = model.fit(X_train, y_train,
batch_size = 16,
epochs = 30,
validation_data=(X_valid, y_valid))- Matplotlib 라이브러리 활용해서 학습 mse와 검증 mse를 그래프로 표시
mse = history.history['loss']
val_mse = history.history['val_loss']
epochs = range(1, len(mse) + 1)
plt.plot(epochs, mse, 'b', label='mse')
plt.plot(epochs, val_mse, 'r', label='val_mse')
plt.title('Model MSE')
plt.xlabel('Epochs')
plt.ylabel('MSE')
plt.legend()
plt.show()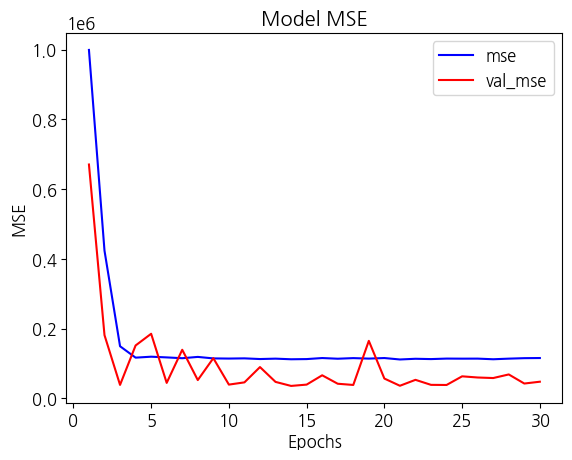
<피드백>
- loss='mean_squeared_error'해서 metrics 안써도 자동으로 되네요!
🧐 후기
AICE 처음이라 걱정 많이했지만!
세 개의 프로젝트? 연습을 진행하며 생각보다 괜찮겠구나! 그래도 지금까지 열심히 공부했구나를 느꼈다!! 그래도 중간중간 원하는 데이터타입 컬럼 추출이나 팀 같은 것들을 팀원들끼리 주고 받으면서 재미있었다!!
연습한 것 보다 어렵게 문제가 나온다고 하니, 시험 전에 세 개 다시 해보고, 추가적으로 공부를 좀 더 해야할 거 같다! 그리고 점점 나만의 머신러닝, 딥러닝 적는 방법이 생기는 거 같아 뭔가 뿌듯하고...신기하고...!
+) 우리 팀원들...익명으로 하니까 말 되게 많아졌어요...
 |  |
|---|

😊
안녕하세요 선배님! 에이블스쿨 DX컨설턴트 5기 교육생입니다!
저희도 다음주 금요일에 AICE 시험이있어서 열심히 준비하던 중에 선배님 블로그를 보게됐네요! ㅎㅎ 덕분에 공부가 한결 수월해졌습니다!
이거 보고 열심히 공부해서 꼭 합격하겠습니다! 좋은 자료 감사합니다! 좋은 하루 보내세요!