High-Resolution Image Synthesis with Latent Diffusion Models
개요
- diffusion model은 image 생성에 있어 SOTA를 달성함
- DM(diffusion model)은 이미지의 pixel space에 직접적으로 작동하므로 대량의 GPU가 필요
- DM이 퀄리티와 유연성을 유지하면서 학습하기 위해 제한된 리소스로
pretrained auto-encoder의 latent space적용
- DM이 퀄리티와 유연성을 유지하면서 학습하기 위해 제한된 리소스로
- complexity reduction과 detail-preservation간의 near-optimal point 찾음
- near-optimal point : 거의 최적점, 최적점에 매우 가까운 해답을 의미
cross-attention layer의 도입으로 general conditioning input(텍스트/bounding box)에 대해 강력하고 유연하게 바꿀 수 있으며, 고해상도 convolution 방식이 가능해짐- Latent Diffusion Model은 (1) image inpainting (2) class-conditional iamge synthesis (3) highly competitive performance (4) text-to-image synthesis (5) unconditional image generation (6) super-resolution 에서 DM 대비 pixel-based에서 computaional requirements 요구를 줄이면서 높은 퍼포먼스를 보임
인사이트
1. Introduction
- 이미지 합성은 cv 분야에서 극적인 발전을 이룬 분야이며 동시에 가자아 큰 계산적 수요가 존재함
likelihood-based모델을 선택함에 따라 DM은 GAN의 모델 붕괴나 학습의 불안전성을 겪지 않고 parameter sharing을 함- DM은 AR 모델처럼 수십억의 파라미터 필요없이 자연스러운 이미지의 복잡함을 모델링 할 수 있음
Democratizing High-Resoultion Image Synthesis : 고해상도 이미지 생성의 민주화
- DM은 여전치 많은 컴퓨팅 리소스를 요함
- 모델이 여전히 RGB 이미지의 높은 차원 공간에서 training and evaluation되고 있음
- DM을 학습시키 위해서 소수만 접근가능한 많은 양의 자원 필요
- 이미 학습된 모델은 시간과 메모리가 많이 필요함
- computational complexity를 줄일 필요가 있으며 성능을 저하시키지 않고 줄이는 것이 key
Departure to Latent Space : Latent Space로의 발전
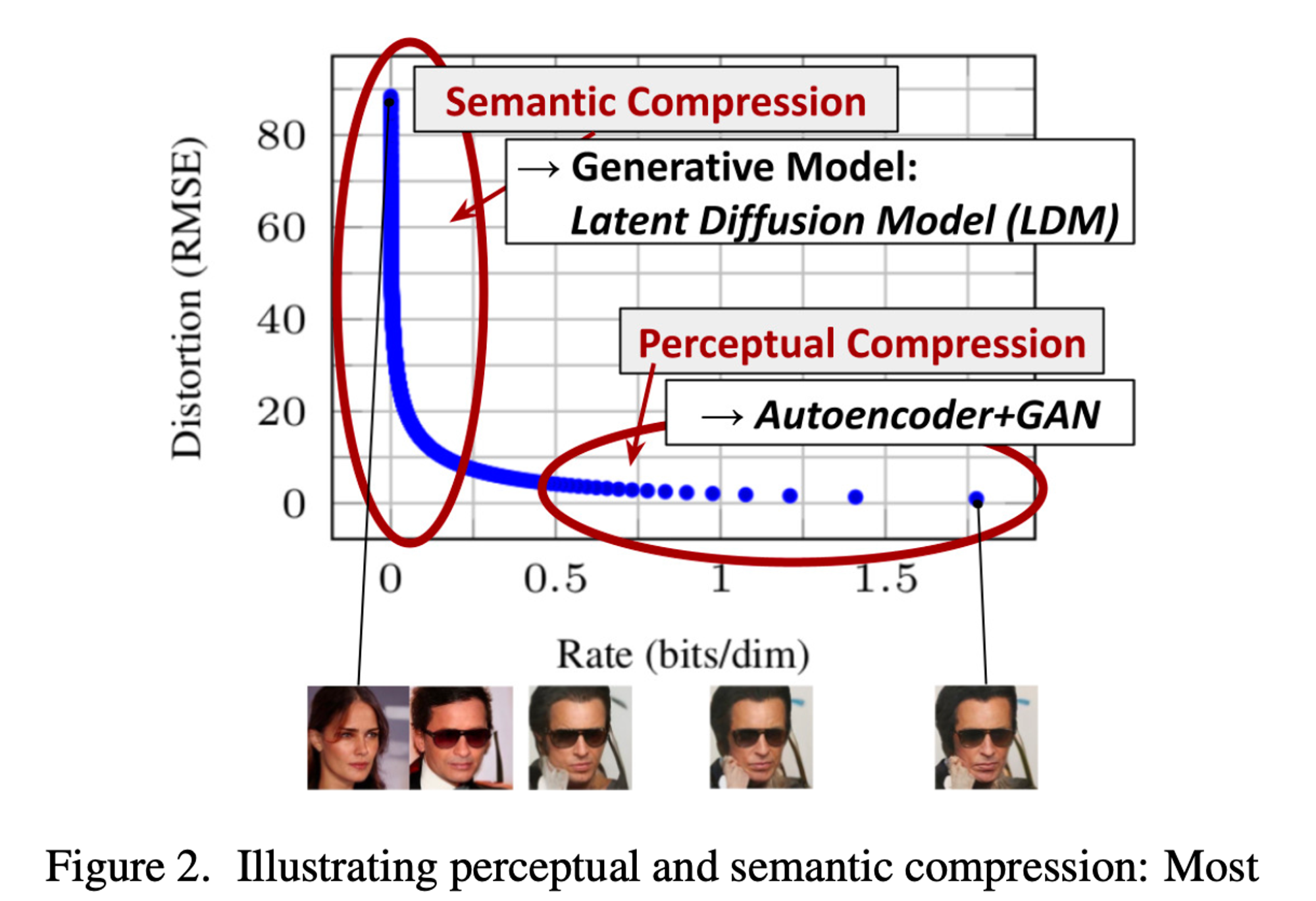
-
이미 학습된 DM의 pixel space에 대해 분석하는 것부터 시작함
-
Figure2는 학습된 모델의 rate distortion trade-off를 보임 : LDM은 눈에 띄지 않는 세부사항만 제거하는 온화한 압축 단계를 가지면서 효과가 좋음
-
학습은 2단계로 나뉨
- 인식 압축(
perceptual compression stage) : high-frequency detail을 제거하지만semantic은 거의 학습하지 않음 - 의미 압축(
semantic compression) : 데이터의 의미론적 구성과 개념(conceptual) 구성을 학습
- 인식 압축(
-
perceptual하게 동등하면서 계산적으로 더 적합한 space 찾는 것을 목표로 하며 high-resolution 이미지를 학습함
-
2개의 phases로 분리
- autoencoder 학습 : 저차원 representational space를 제공하는 autoencoder학습
- 과도한 공간 압축에 의존 x : 감소된 복잡성으로 인하여 network를 한 번만 통과해서 효과적인 image를 생성할 수 있음 > Latent Diffusion Model 이라고 부름
-
범용 encoding 단계를 한 번만 학습하면 되므로 여러 DM 학습에 재사용 가능하고 다양한 task를 탐색할 수 있음
-
transformer를 DM의 UNet backbone + 임의의 유형의 토큰으로 조건을 주는 아키텍처 설계
기여
- 고차원 Data를 더 graceful하게 확장하고 이전 작업보다 더 충실하게 재구성 가능
- cost를 낮춤
- 재구성과 생성의 섬세한 weightning을 요구하지 않음
- convolution fashion을 적용할 수 있고 large images도 가능
- cross-attention 기반의 메커니즘을 design함
2. Related Work
생략
3. Method
- 고해상도 이미지 합성에 대한 DM 학습 계산 요구량을 낮추기 위해 해당 손실 함수를 적게 샘플링하여 perceptual하게 관계없는 디테일을 무시
- 아직 pixel space에서 계산 비용이 많이 요구
- 압축을 명확하게 분리하는 것을 제안
- autoencoding을 모델에 사용
- 이미지 공간과 perceptual하게 동일한 공간을 학습하지만 계산 복잡성을 크게 줄임
- 장점
- 고차원 이미지 space를 남겨둠
- UNet의 아키텍처에 상속된 DM의 inductive bias를 활용
- latent space를 여러 생성 모델 훈련에 사용하여 downstream task에도 활용 가능한 압축 모델을 얻음
3.1 Perceptual Image Compression
-
perceptual compression 모델 = 이전 연구 기반 + perceptual loss + patch based adversarial objective의 조합으로 학습되는 autoencoder로 구성됨
-
local realism이 적용됨
- 재구성이 image manifold에 국한
- 흐릿함 방지 : 와 같은 pixel space loss에 의존해 발생하는 흐릿함
-
주어진 RGB 이미지 에 대해 인코더 에 를
latent representation에 넣음 -
디코더 는 image를 latent에서 reconstruct함
-
인코더는 이미지를 로 downsample하고 에 대해 로 함
-
latent space의 분산이 커지는 것을 막기 위해 두 가지 종류의 정규화로 실험 진행
- KL 정규화 : VAE와 유사하게 학습한 latent에서 표준 정규분포에 대해 KL penality를 적용
- VQ 정규화 : vector 양자화 layer을 사용
- VQGAN으로 해석될 수 있지만 양자화 layer가 디코더에 의해 흡수됨
-
DM이 2차원 구조로 작동하므로 상대적으로 약한 압축률을 사용하고 매우 우수한 재구성이 가능
-
학습된 space 의 임의의 1차원 순서에 의존해 분포를 모델링하는 기존 연구와 차별 > 의 고유 구조를 무시
-
본 연구의 압축은 의 디테일을 더 보존함
3.2 Latent Diffusion Model
Diffusion model
- 정규 분포 변수 noise를 점진적으로 제거하고 data 분포 를 학습하도록 설계한 모델
- 고정 길이가 인 Markov chain의 reverse를 학습함
- 성능이 좋은 모델들을 미러링하는 에 대해 variational lower bound 재가중한 변형에 의존함
- 입력 의 noise가 제거된 변형을 예측하도록 학습된 denoising autoencoder로 해석 가능
- : 입력 에 noise가 추가
Generative Modeling of Latent Representations
- 과 로 구성되어 학습된 perceptual compression 모델을 사용해 low_dimensional latent space에 접근할 수 있으며 likelihood-based generative model에 적합함
- data의 중요한 semantic bit에 집중
- 계산적으로 훨씬 더 효율적으로 낮은 차원에서 학습 가능
- LDM은 이미지별 inductive bias를 활용함
- 2D convolutional layer들로 UNet을 구성하고, reweighted bound를 사용해 관련성이 높은 비트에 목적 함수를 더 집중시킴
- : neural backbone으로 UNet의 time-conditional
- forward process가 고정되어있어 는 학습 과정에서 효율적으로 얻을 수 있음
- 로 부터의 sample은 를 한 번 통과해 이미지 space 가 decoding될 수 있음
3.3 Conditioning Mechanisms
- DM은 형식의 조건부 분포를 모델링 가능
- 조건부 denoising autoencoder 로 구현
- 입력 를 통해 텍스트, semantic map, image to image 변환과 같은 합성 프로세스 제어
- 다양한 입력 양식의 attention기반 모델을 학습하는 데 효과적인 cross attention 메커니즘으로 기본 UNet backbone을 보강해 유연한 조건부 이미지 생성기를 제작
- 다양한 종류의 를 전처리하기 위해 중간 representation 로 보내는 도메인 인코더 를 도입
- cross-attention layer를 통해 UNet의 중간 레이어에 mapped
- 와 는 Dot 연산 후 weight 형태
- 와 내적 > cross attention mechanism
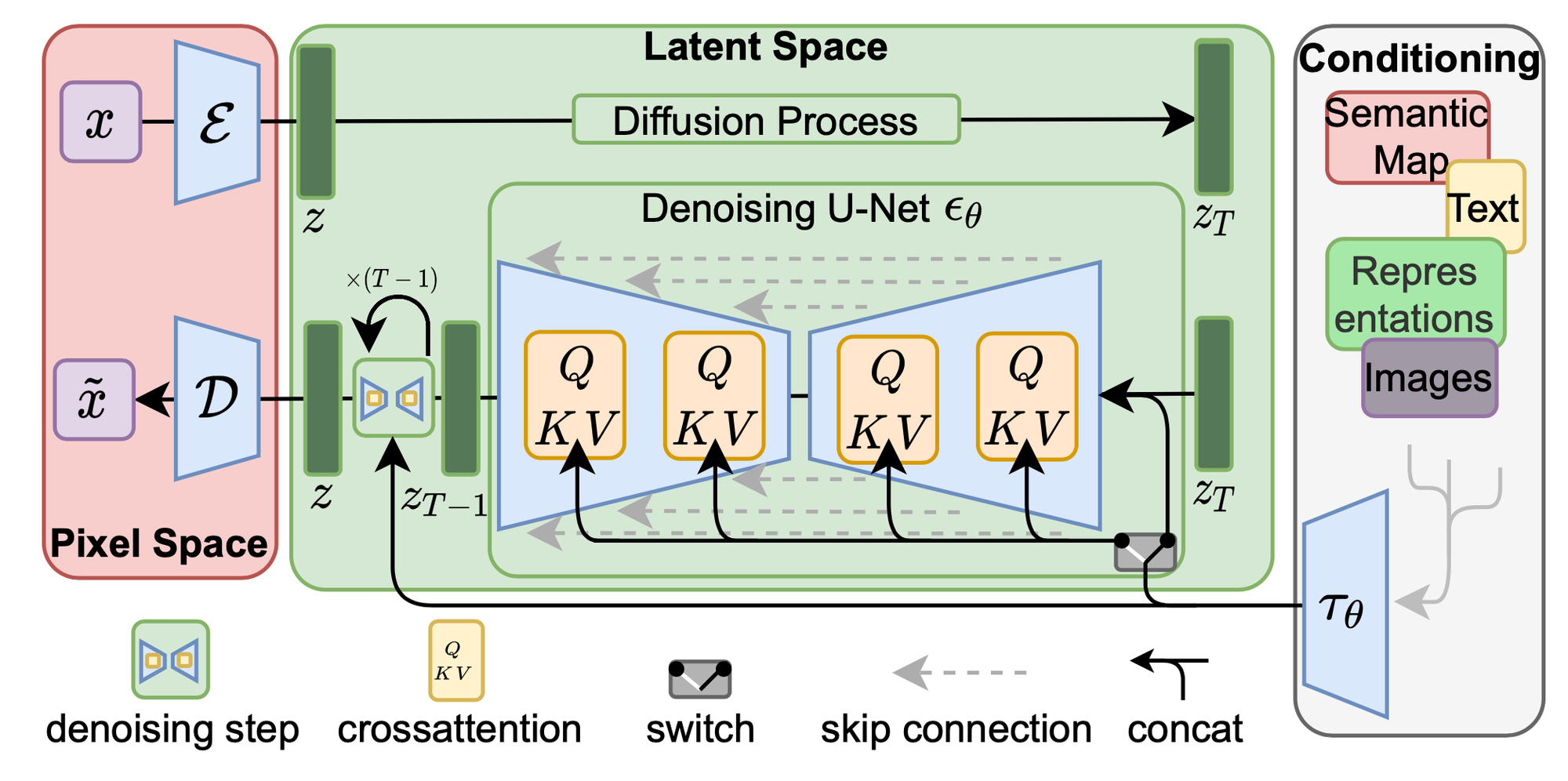
- UNet의 중간 representation
- 는 학습가능한 projection matrix
- 와 는 동시에 최적화되며, 각 도메인별로 파라미터화 될 수 있기에 conditioning 메커니즘은 유연

이하 생략
