[Paper Review] LLaVA: Large Language and Vision Assistant, Visual Instruction Tuning
Paper I should read

Visual Instruction tuning 을 통해 LLM이 general-purpose visual 과 language understanding 을 제안한 LLaVA 논문을 리뷰 해보려 한다. LLaVA 논문의 가장 큰 포인트를 몇 가지 짚고 넘어가봅시다.
1. Generate insturction-following data by language-only GPT-4
2. Instruction tuning LLM using Images with instruction-following data
첫 번째는 GPT-4 를 활용하여 instruction-following 에 활용한 데이터 셋을 준비합니다. 두 번째는 앞서 준비된 데이터를 통해 LLM 에 실제 이미지 insturction tuning 을 통해 학습을 수행합니다. 이제 세부적으로 정확히 어떻게 진행되었는지 살펴보겠습니다.
GPT-assisted Visual Instruction Data Generation
먼저 Insturction tuning 에 사용할 데이터를 구축하는 단계입니다. 사람이 직접 데이터 셋을 구축하는 것은 시간과 비용 그리고 품질 문제가 있기에 제한됩니다. 따라서, 저자는 GPT 모델이 text-annotation tasks 에서 성공을 거둔 것에 영감 받아 해당 방식을 통해 학습 데이터를 생성하였습니다.
이때 당시 GPT-4 는 visual 정보를 입력 값으로 받지 못했기 때문에 이미지를 직접 입력하는 대신에 두 가지 데이터 타입으로 입력 데이터를 주었습니다.
1. Image Captions
2. Bounding Boxes
예시에서 보이는 그림은 예시 그림을 보여주기 위함이지, 실제로 입력 값으로 넣은 것이 아닙니다. 그리고 저자는 3 가지 타입으로 출력하도록 prompting 하였습니다. 그리고 prompting 은 fewshot exmples 를 사용하였습니다.
1. Conversation
2. Detailed description
3. Complex reasoning
아래의 그림은 생성된 학습 데이터의 예시입니다.

의문점이 들었던 부분은 어떻게 3 가지 출력 값을 얻도록 설계했는지 궁금했습니다. 해당 내용은 Appendix 에 첨부 되어 있었습니다. 차례대로 살펴보겠습니다.
1. Generating conversation data
논문에서는 대표로 conversation data 를 생성하는 방법을 보여주었습니다. 아래의 그림은 system message 와 이에 따른 fewshow examples 를 prompting 하는 예시 템플릿을 보여주었습니다.

여기서 examples 에는 아래의 그림의 내용이 들어갑니다. 여기서는 Captions 만 보이지만, 실제로는 Box context type 도 같이 주어집니다. 이렇게 fewshot examples 를 통해 in-context-learning 하였습니다.

Detailed description 과 Complex reasoning 은 code base 를 통해 확인 해보았습니다.
2. Generating detailed description data
먼저 detailed description 을 살펴보겠습니다. System message 는 아래와 같습니다.
You are an AI visual assistant that can analyze a single image. You receive five sentences, each describing the same image you are observing. In addition, specific object locations within the image are given, along with detailed coordinates. These coordinates are in the form of bounding boxes, represented as (x1, y1, x2, y2) with floating numbers ranging from 0 to 1. These values correspond to the top left x, top left y, bottom right x, and bottom right y.
Using the provided caption and bounding box information, describe the scene in a detailed manner.
Instead of directly mentioning the bounding box coordinates, utilize this data to explain the scene using natural language. Include details like object counts, position of the objects, relative position between the objects.
When using the information from the caption and coordinates, directly explain the scene, and do not mention that the information source is the caption or the bounding box. Always answer as if you are directly looking at the image.그리고 fewshot 예시로는 아래와 같이 instruction list 에서 랜덤하게 하나를 뽑아서 설명하도록 지시하고, 그림에 맞는 (사람이 직접 준비해놓은) caption 값이 pair 를 이루어 예시로 주어집니다.

3. Generating complex reasoning
Complex reasoning 데이터를 만들기 위한 system message 는 아래와 같습니다.
You are an AI visual assistant that can analyze a single image. You receive five sentences, each describing the same image you are observing. In addition, specific object locations within the image are given, along with detailed coordinates. These coordinates are in the form of bounding boxes, represented as (x1, y1, x2, y2) with floating numbers ranging from 0 to 1. These values correspond to the top left x, top left y, bottom right x, and bottom right y.
The task is to use the provided caption and bounding box information, create a plausible question about the image, and provide the answer in detail.
Create complex questions beyond describing the scene.
To answer such questions, one should require first understanding the visual content, then based on the background knowledge or reasoning, either explain why the things are happening that way, or provide guides and help to user's request. Make the question challenging by not including the visual content details in the question so that the user needs to reason about that first.
Instead of directly mentioning the bounding box coordinates, utilize this data to explain the scene using natural language. Include details like object counts, position of the objects, relative position between the objects.
When using the information from the caption and coordinates, directly explain the scene, and do not mention that the information source is the caption or the bounding box. Always answer as if you are directly looking at the image.그 후 사전에 준비해둔 구체적인 질문과 답을 fewshot examples 로 주어집니다. 하나의 예로 아래와 같습니다.
Question:
What challenges might this city face?
===
Answer:
The city faces challenges due to the harsh winter conditions and heavy snowfall. In the image, a red fire hydrant is almost buried deep in the snow, which indicates the significant amount of snow the city has experienced. This can lead to various challenges such as difficulties in transportation, increased risk of accidents, and disruptions to daily life. For example, the recently plowed sidewalk near the fire hydrant shows that the city has to constantly clear snow from roads and sidewalks to maintain access and safety for pedestrians and vehicles. Moreover, emergency services, like firefighters, might face challenges accessing crucial equipment, such as fire hydrants, during emergencies due to the snow accumulation. This highlights the importance of effective snow management strategies and preparedness in such cities to minimize the impact of harsh winter conditions on residents and essential services.본 논문에서는 fewshot examples의 개수로 모두 3개의 예시를 주었습니다.
이렇게 conversation 은 58k, detailed description 은 23k, complex reasoning 은 77k 의 instruction-following data 를 생성하여 총 158K 데이터를 얻었습니다. 이제 실제 모델 구조와 학습을 어떻게 하였는지 살펴보겠습니다.
Visual Instruction Tuning
Architecture
LLaVA 의 전체 구조입니다. 사용한 모델을 정리해보겠습니다.
Language Model : Vicuna-V0 (LLaMA-7B)
Vision Encoder: CLIP visual encoder ViT-L/14
Projection W: Learnable Parameter (linear projection layer)
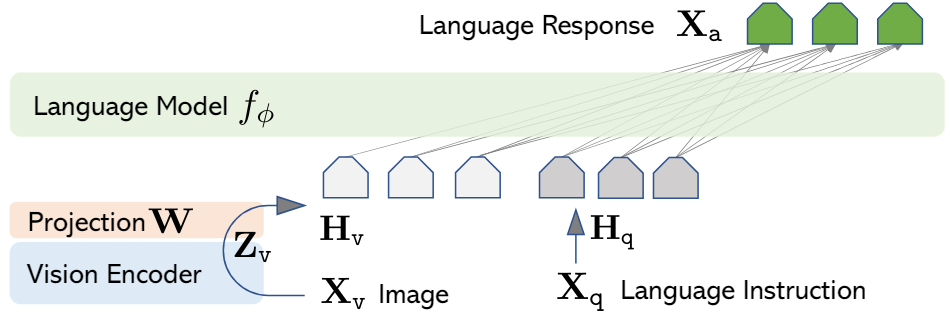
Training
각 이미지 마다 multi-turn conversation data(), T 는 turn 의 총 개수입니다. 명확히 하면 입력값으로 실제 이미지 와 User 의 질문 가 주어지면 앞에서 생성한 instruction-following data 의 출력 값 (Conversation, Detailed description, Complex reasoning) 이 여기서 정답 값 가 되는 것입니다.
아래의 예로 명확히 이해해 보겠습니다.

해당 예시에서 는 Vicuna-V0 의 system message 를 그대로 사용하였습니다. 그리고 앞에서 준비한 multi-turn conversation data 를 랜덤하게 하나씩 뽑아 학습합니다. 첫 data 는 무조건 가 같이 주어집니다. 그리고 위의 그림에서 초록색으로 표시된 부분이 loss 가 계산되어 학습이 일어나는 부분입니다. 어디서 멈춰야할 지 토큰과 어떻게 대답해야할 지 가 예측 변수입니다.
앞에서 machine-generated instruction-following data 의 caption 과 box 는 이렇게 이미지를 이해하고 이에 대해 출력한 caption 을 얻기 위해서 적용되었고 실제 학습에는 이미지가 입력되는 것이 LLaVA 의 핵심입니다. 따라서, LLaVA 는 이미지에 대해서 잘 이해할 수 있고 이미지를 이해한 높은 품질의 답변을 생성할 수 있습니다.
학습 과정은 2 단계로 이루어집니다.
1. Pre-training for Feature Alignment.
이미지 feature 와 language instruction 을 LLM 에 전달하기 위해 를 통해 alignment 를 수행합니다. 이때 Visual Encoder 와 Language Model 은 동결 시키고 projection W 만 학습합니다. 이 단계에서는 CC3M to 595K image-text pairs 데이터를 사용하였고, image describe 을 breifly 답변하도록 하여 학습하였습니다. 그러면 image decribe breifly 가 무엇인지 조금 더 살펴보겠습니다. Appendix 에서 아래의 그림을 통해 설명하였습니다.

위의 그림의 instruction list 를 랜덤하게 뽑아 instruction language 를 CC3M image 와 함께 LLM 의 입력값으로 넣은 후 출력 caption 답변을 CC3M text 정답과 loss 를 계산하여 학습합니다.
2. Fine-tuning End-to-End.
이제 본격적으로 fine-tuning 을 진행합니다. Vision Encoder 는 동결하고, Language model 과 projection W 는 학습 파라미터입니다. 2 가지 시나리오로 fine-tuning 을 진행합니다.
1. Multimodal Chatbot
2. Science QA
Multimodal Chatbot 은 앞서 생성한 158K 데이터를 통해 학습하고, Science QA 는 ScienceQA benchmark 를 통해 질문을 주고 multiple choice 에서 정답을 선택하는 방식으로 학습이 이루어집니다. (문제를 잘 푸는 방향)
Experiments
실험 세팅과 2 가지 시나리오에 대한 실험 결과를 살펴 보겠습니다.
Setting
- 8 X A100s
- Vicuna's hyperparameters
- Adam optimizer with no weight decay
- Cosine schedular with a warmup ratio to 3%
Pre-train
- CC-595K subset for 1 epoch
- Learning rate 2e-3
- Batch size 128
- Completed within 4 hours
Fine-tune
-
LLaVA-Instruct-158K dataset for 3 epochs
-
Learning rate 2e-5
-
Batch size 32
-
Completed within 10 hours
-
ScienceQA 21k multimodal multiple choice questions for 12 epochs
-
3 subjects, 26 topics, 127 categories, and 279 skills
-
train valid test splits with 12726, 4241, 4241 examples
Multimodal Chatbot
LLaVA 는 ~80K unique images 를 가지는 작은 multimodal instruction-following dataset 을 사용하여 학습하였지만, 결과는 놀랍게도 multimodal GPT-4 와 유사한 reasoning 결과가 나왔습니다.

Quantitative Evalutation
GPT evaluation 방식을 사용하였습니다.
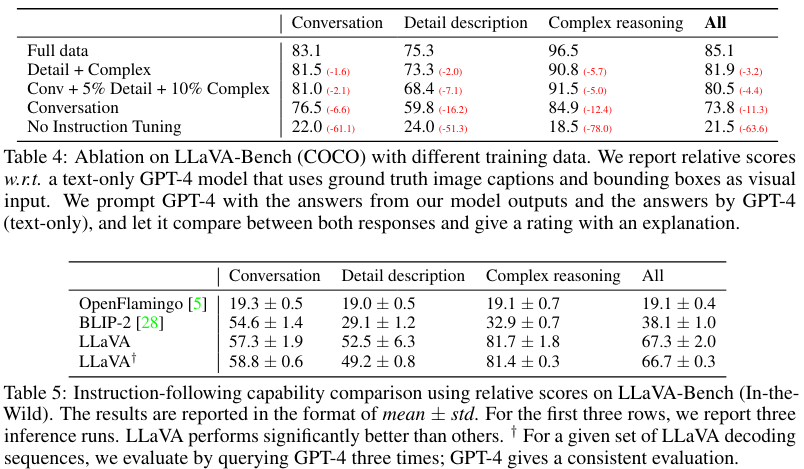
Limitation
한계점 또한 볼 수 있습니다. 왼쪽은 레스토랑 이름이 명시적으로 주어지면 잘 맞추지만, 오른쪽의 strawberry-flavored yogurt 가 있냐는 질문에 냉장고에 없지만, 딸기와 요거트를 보고 라고 답변하였습니다. 아직까지는 이러한 한계점이 있어 보입니다.

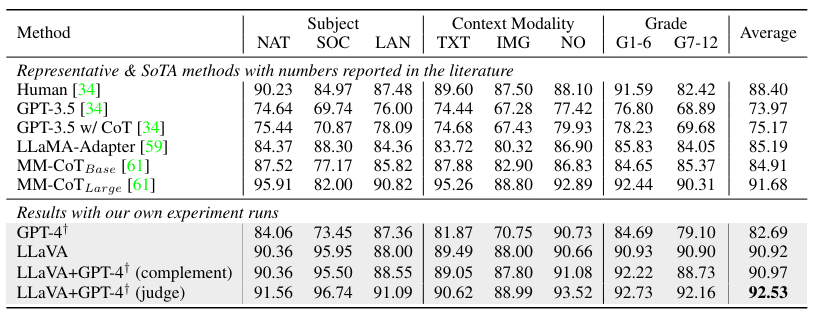
Science QA
해당 실험에서 흥미로운 점은 GPT-4 를 model ensembling 에 활용한 점입니다.
A GPT-4 complement
GPT-4 가 오답을 내면 무조건 LLaVA 의 답을 제출하도록 함
GPT-4 judge
GPT-4 와 LLaVA 모두 오답이더라도 다시 GPT-4 에게 답을 맞추도록 입력함
Abliations
Abliation study 를 살펴보겠습니다. 먼저 아래의 표에서 볼 수 있듯 CLIP vision encoder의 visual features 를 last layer 에서 가져오냐 before layer 에서 가져오냐에 따른 성능 차를 기준으로 table 이 구성되어 있으며 크게 4 가지 실험을 하였습니다.
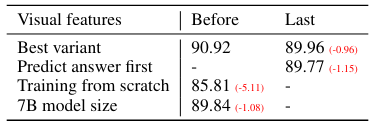
1. Visual features
CLIP vision encoder 의 last layer 를 사용하면 성능이 0.96% 떨어지는 것을 보고 last layer 는 이미지의 global 하고 abstract 한 특징을 지니기에 그런 것 같다고 말하였습니다.
2. Chain-of-thougt
answer-first는 12 epoch 에 걸쳐 89.77% 정확도에 도달한 반면, reasoning-fist 가 6 epoch 만에 89.77% 로 학습을 빠르게 converged 하였습니다. 하지만, final performance 에는 큰 영향을 끼치지 않았다고 합니다.
3. Pre-training
Pre-training 을 skip 하고 Science QA 를 scratch 에서 학습하였을 때, 85.81% 로 정확도가 떨어졌습니다. 5.11% 가 pre-training 의 중요도(설명력) 이라고 말합니다.
4. Model size
13B 모델이 7B 모델보다 1.08% 의 성능 향상 폭을 가지며 모델의 scale 은 여전히 중요하다고 합니다.
More Results

GPT-4 model ensemble

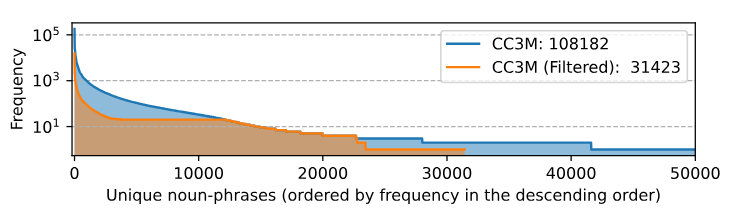
Filtered CC3M
Future Study
1. Improved Baselines with Visual Instruction Tunning (LLaVA 1.5, NeurIPS 2023)
2. LLaVA-RLHF
3. LLaVA-Med: Training a Large Language-and-Vision Assistant for Biomedicine in One Day
추가적인 논문
- LLM trained on Image-Text pairs
BLIP-2
FROMAge
PaLM-E- Instruction-tunning
InstructGPT
ChatGPT
FLAN-T5
FLAN-PaLM
OPT-IML
