[Papaer Review] LLaVA-NeXT: A Strong Zero-shot Video Understanding Model
Paper I should read

LLaVA 후속 논문으로 비디오에 적용한 LLaVA-NeXT 논문을 리뷰하고자 한다. 본 논문은 text-image data로 학습된 오픈 소스 LMM이다. AnyRes 기술을 제안하여 추론, OCR, world knowledge 등 image-based multimodal 을 이해하는 task 에서 Gemini-Pro 를 능가하는 성능을 보였다.
본 논문의 기여점은 크게 4가지로 정리할 수 있다.
1. Zero-shot video representation capabilities with AnyRes
o AnyRes 기술은 high resolution image 를 다중 이미지로 쪼개어 pre-trained VIT 의 입력값으로 넣는 것이다.
o Video 에도 일반화하여 적용하면 multiple frames 를 pre-trained VIT의 입력값으로 넣는 것이다.2. Inference with length generalization improves on longer videos
ㅇ Linear scaling 기술을 통해 영상의 길이 일반화가 가능하다.
ㅇ Long-video 를 효과적으로 처리하여 "max_token_length" 의 한계를 극복할 수 있다.3. Strong video understanding ability
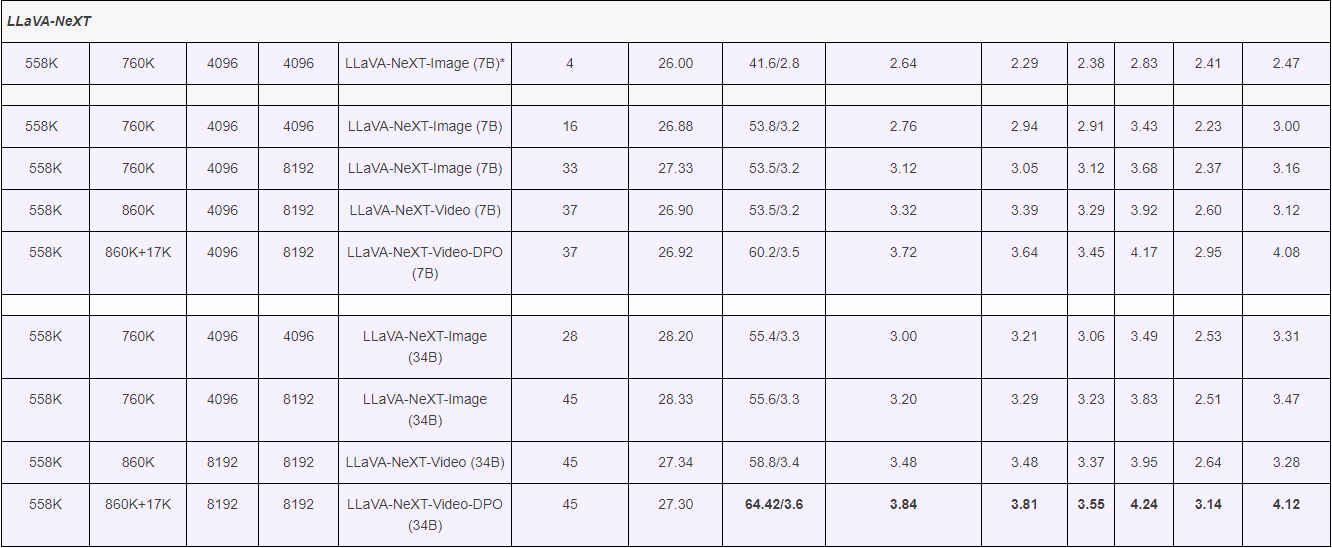
(1) LLaVA-NeXT Image, 앞선 2가지 방법을 사용하여, zero-shot 으로 videos 를 학습한 open-source LLMs 를 뛰어넘었다.
(2) LLaVA-NeXT-Video, Supervised fine-tuning (SFT) 로 LLaVA-NeXT-Image 를 video data에 학습하였다.
(3) LLaVA-NeXT-Video-DPO, AI feedback을 사용하여 direct preference optimization (DPO) 로 상당한 성능 향상을 하였다.4. Efficient deployment and inference
ㅇ SGLang 을 사용하여 5x 빠른 추론 속도를 보여주었다.
Video task 에서의 결과표를 한번 보자.
Results
Technical Insights
LLaVA-NeXT 는 어떻게 image-based multimodal 을 학습하고 video 를 이해할까?
1. AnyRes: From multi-patch to multi-frame
Image task 는 고화질일 수록 자세한 표현이 가능하지만, 용량이 거대해진다는 단점이 존재한다. LLaVA-NeXT-Image 에서는 VIT 가 "소화" 할 수 있도록 resize, multi-patch 로 나눈다. Resize 한 이미지와 원본 이미지를 patch 로 나눈 이미지 모두 VIT 의 입력값으로 들어가는 것이다. 이러한 아이디어를 바탕으로 LLaVA-NeXT-Video 에서는 각 프레임을 패치로 보고 multi-frame 이 VIT 의 입력값으로 들어가는 것이다. 아래의 그림을 통해 이해해보자.
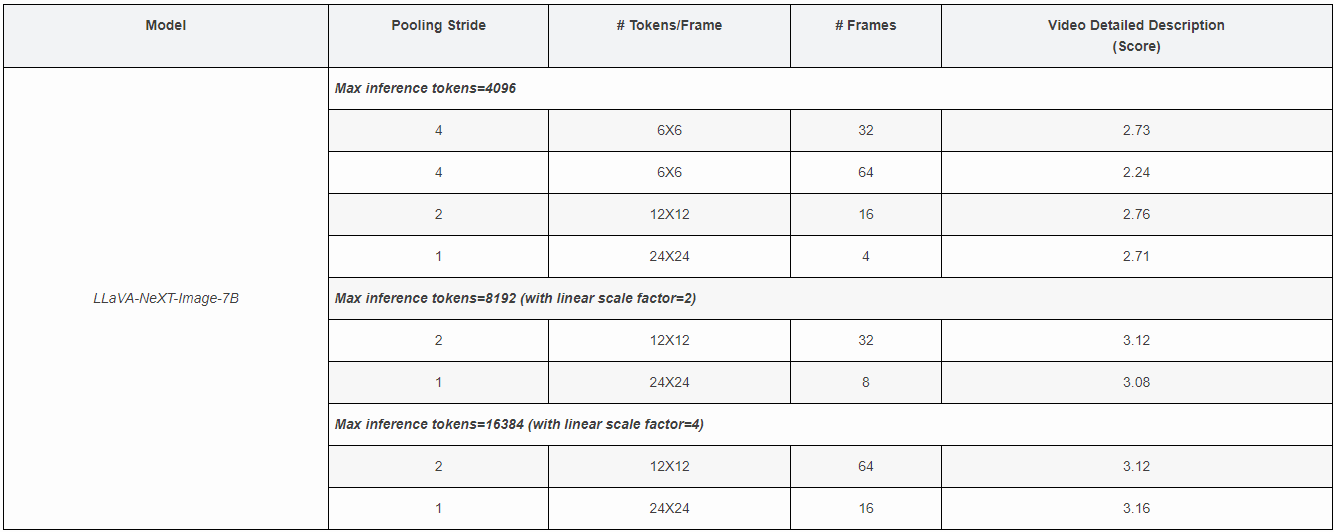
하지만, LLM 의 "max_token_length" 의 4096 토큰 제한 한계에 부딪힌다. 예로, 비디오를 12x12 token 이라면 최대 16 frame 을 입력값으로 넣을 수 있다. 하지만, 16 frame 은 비디오를 충분히 이해하는데 부족함을 알 수 있다. 그렇다면 frame 을 어떻게 다루면 좋을까?
2. Length generalization: From multi-frame to long-video
Rotary position embeddings (RoPE) 에서 구현한 linear scaling 을 "max_token_lenght 의 한계를 극복하기 위해 유사하게 사용하였다. 왜냐하면 RoPE 는 입력 시퀀스의 길이에 유연하게 적용될 수 있기 때문이다.
RoFormer: Rotary position embeddings(RoPE) 에 대한 이해가 필수적이기에 포스트 링크를 걸어두었다.
position embedding 의 차원에 맞추어 scaling factor 를 2 로 주면 dimension 은 2 배 줄어들게 되고 입력 시퀀스의 길이는 2배 더 늘어날 수 있다. 따라서 비디오 프레임은 2배 더 많이 입력값으로 줄 수 있게 된다.

위의 그림처럼 input video 의 길이가 늘어남을 볼 수 있다.
큰 줄기는 다 살펴 보았다!!
abliation study 는 아래에 첨부해 두었다.
(1) How to represent videos? Configurations: (# Tokens/Frame, # Frames)
(2) How to fine-tune on videos?

원문 자료
LLaVA-NeXT
