Abstract
Sparsely-activated Mixture-of-experts(MoE)모델은 연산량을 유지하면서 파라미터의 수를 아주 많이 늘릴 수 있도록 하였습니다. 하지만, expert routing 전략의 부족으로 인해 특정 experts는 학습이 덜 되는 경우가 생기고 이는, expert가 과소/과대 활성화되는 문제로 이어집니다. 이전의 연구는 연관된 서로 다른 토큰들의 중요도를 무시하고 정해진 숫자의 experts를 top-k 함수를 써서 expert를 할당하였습니다. 이 논문에서는 expert 선택 방법으로 heterogeneous mixture-of-experts를 제안하고자 합니다. 그 겨로가 각 토큰은 다양한 수의 experts로 연결되고 각 expert는 fixed bucket size를 가질 수 있습니다. 동일한 computational cost를 유지한체 높은 성능을 보였습니다.
Introduction
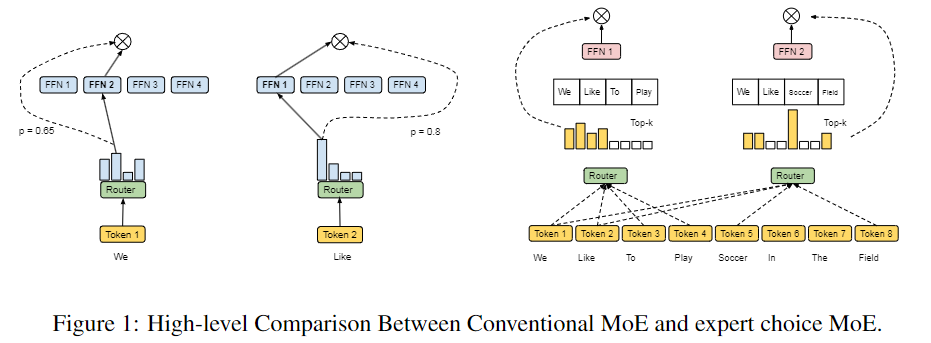
이 논문에서는 매우 간단하지만 효과적인 라우팅 방법인 "expert choice"를 제안합니다. 기존의 Mixture of Experts (MoE)와 달리, 이 방법은 각 토큰이 상위 1~2개의 전문가를 선택하는 것이 아니라, 각 전문가가 상위 k개의 토큰을 선택하는 방식입니다. 이 방법은 완벽한 로드 밸런싱을 보장하며, 각 토큰에 대해 가변적인 수의 전문가를 허용하고, 실험을 통해 훈련 효율성과 다운스트림 성능에서 상당한 향상을 이루었습니다. 주요 기여는 다음과 같습니다:
- 일반적인 MoE의 문제점 식별 및 해결
- 로드 불균형 문제: 기존 MoE에서는 자주 로드 불균형 문제가 발생합니다.
- 이질적인 전문가 선택 방법: 학습된 토큰-전문가 중요도에 기반한 유동적인 모델 파라미터 할당을 제공합니다. 이 방법은 추가적인 손실을 가하지 않고도 본질적으로 로드 밸런스를 보장합니다.
- 훈련 효율성의 향상
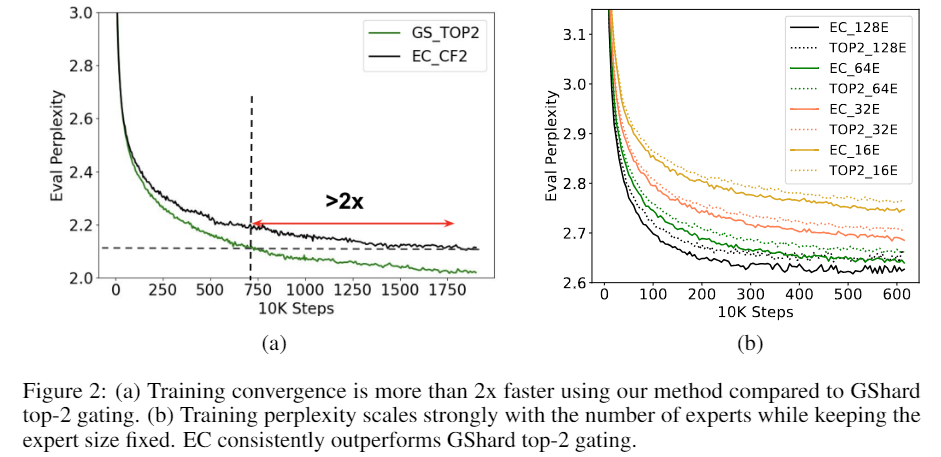
- 훈련 수렴 속도: 8B/64E(80억 개의 활성화된 파라미터, 64개의 전문가) 모델에서, 기존의 상위 1, 2개 게이팅 방식(Switch Transformer 및 GShard)과 비교하여 2배 이상의 훈련 수렴 속도를 제공합니다.
- 전문가 수 증가에 따른 성능 향상
- 강력한 스케일링 성능: 전문가 수를 16개에서 128개로 증가시킬 때, 훈련 난해도(perplexity) 측면에서 강력한 성능을 보입니다.
- 다운스트림 작업에서의 성능
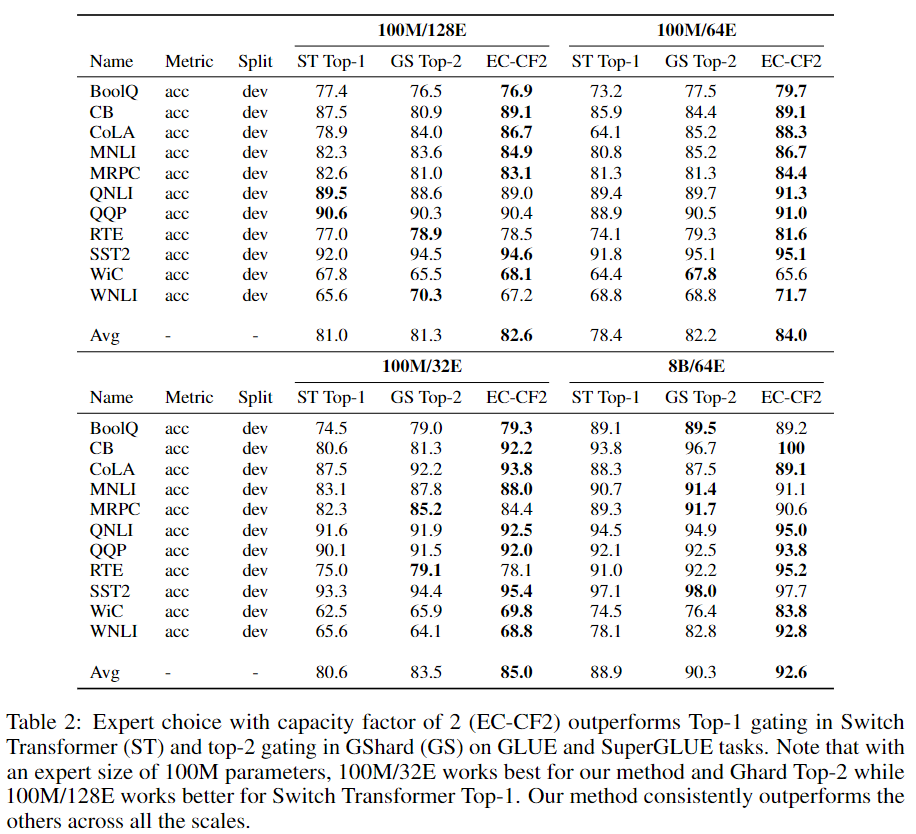
- GLUE 및 SuperGLUE: 평가된 모든 스케일에서 강력한 성능을 나타냅니다. 특히, 8B/64E 모델은 T5 11B 밀집 모델보다 11개의 평가 작업 중 7개에서 더 높은 성능을 보였습니다.
Method
Pitfalls of Token-Choice Routing
Mixture of Experts (MoE) 모델은 dense 모델에 비해 계산적으로 유리할 수 있지만, 각 토큰을 가장 적합한 전문가에게 할당하기 위한 라우팅 전략이 필요합니다. 기존의 MoE 모델은 토큰 선택 라우팅을 사용하여 각 토큰에 대해 독립적으로 상위 k개의 전문가를 선택합니다. 그러나 이 전략에는 몇 가지 함정이 있어 최적의 훈련을 방해할 수 있습니다.
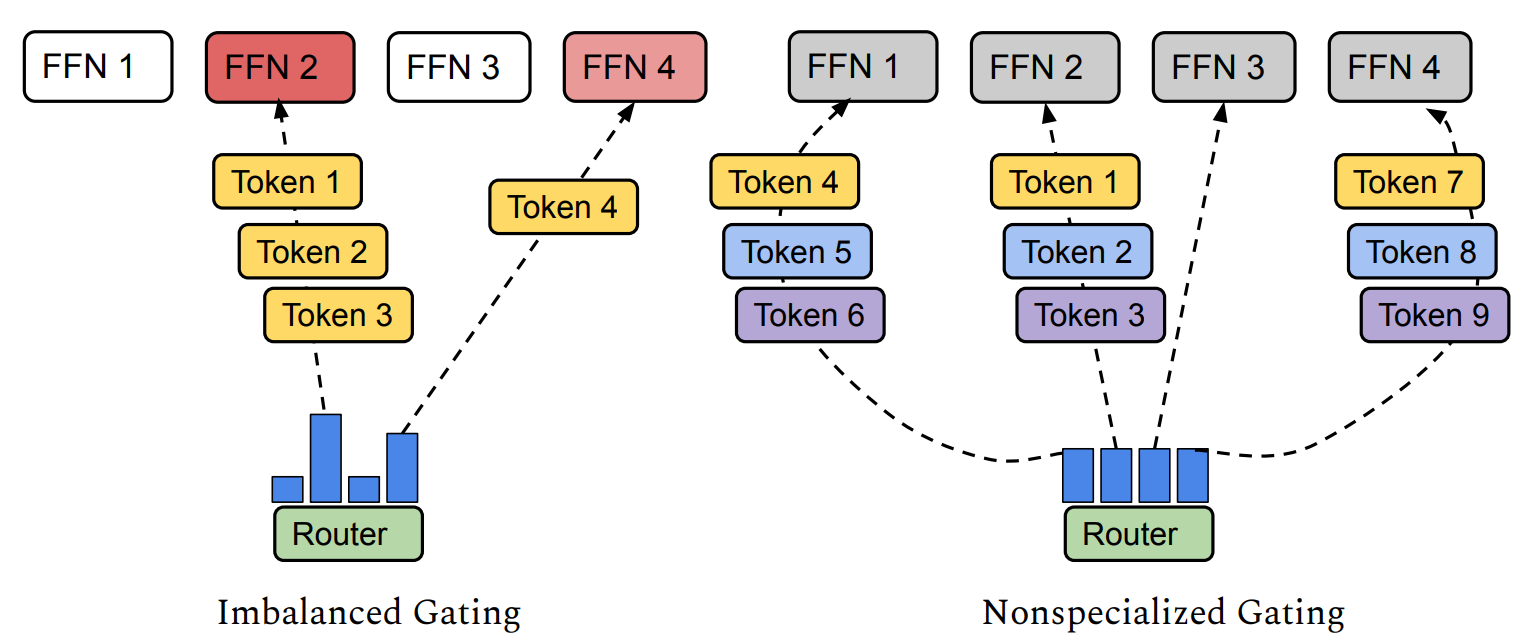
Load Imbalance
토큰 선택 라우팅은 종종 전문가 간의 로드 불균형을 초래합니다. 이는 일부 전문가가 대부분의 토큰을 처리하게 되고, 나머지 전문가들은 충분히 활용되지 않는다는 것을 의미합니다. 활용되지 않는 전문가의 모델 용량은 낭비되며, 반대로 과부하된 전문가들은 메모리 부족을 방지하기 위해 각 단계에서 최대 토큰 수만 처리할 수 있습니다. 로드 불균형은 단계 지연 시간(step latency)과 추론 시간에도 영향을 미쳐, 가장 많이 로드된 전문가에 의해 전체 지연 시간이 결정될 수 있습니다. 이전 방법들은 로드 균형을 맞추기 위해 보조 손실(auxiliary loss)을 추가했지만, 이 보조 손실은 특히 훈련 초기 단계에서 로드 균형을 보장하지 못합니다. 실제로, 우리는 토큰 선택 라우팅에서 일부 전문가의 초과 용량 비율이 20%에서 40%에 이른다는 것을 경험적으로 관찰했습니다. 이는 이러한 전문가들에게 라우팅된 토큰의 상당 부분이 처리되지 않음을 의미합니다.
Under Specialization
각 MoE 레이어는 게이팅 네트워크를 사용하여 토큰과 전문가 간의 친화도를 학습합니다. 이상적으로, 학습된 게이팅 네트워크는 유사하거나 관련된 토큰이 동일한 전문가에게 라우팅되도록 해야 합니다. 그러나 서브 옵티멀한 전략은 중복된 전문가 또는 충분히 전문화되지 않은 전문가를 생성할 수 있습니다. 로드 균형을 맞추기 위해 큰 보조 손실을 가하면 전문화가 부족한 결과를 초래할 수 있습니다. 보조 손실을 통해 로드 균형과 전문화를 모두 촉진하는 올바른 균형을 찾는 것은 토큰 선택 라우팅에서 어려운 문제입니다.
Same Compute for Every Token
마지막으로, 토큰 선택 전략에서는 각 토큰이 정확히 k개의 전문가를 할당받아 동일한 계산량을 차지합니다. 이는 필요하지 않거나 바람직하지 않을 수 있습니다. 대신, MoE 모델은 입력의 복잡도에 따라 유연하게 계산 자원을 할당해야 합니다. 이러한 관찰을 바탕으로, 우리는 전문가 선택에 기반하여 로드 균형 할당을 생성하는 간단하면서도 효과적인 방법을 설명합니다.
Heterogeneous MoE via Expert Choice
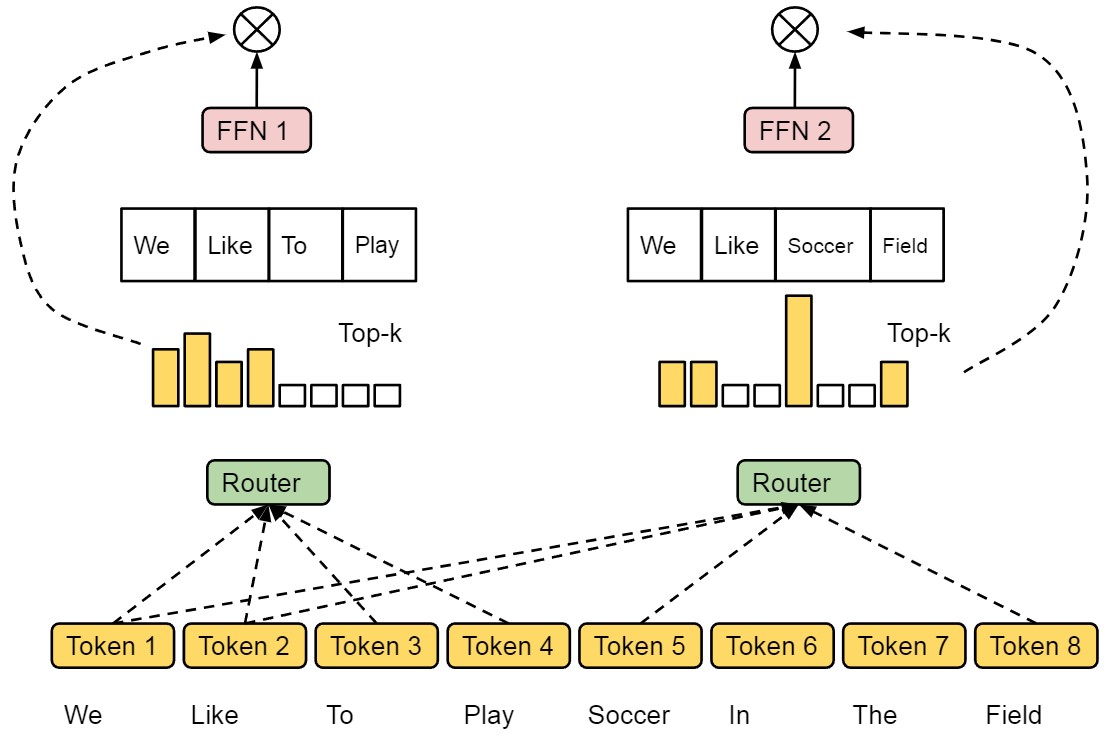
기존의 라우팅 방식과는 다른 Expert Choice 방법을 소개합니다. 이 방법은 각 전문가가 독립적으로 상위 k개의 토큰을 선택하는 방식입니다. k는 각 전문가가 처리할 수 있는 토큰 수를 의미하는 고정된 용량입니다. 이 방법은 단순하면서도 설계상 완벽한 로드 밸런싱을 달성합니다. 또한, 각 토큰이 가변적인 수의 전문가에 의해 처리될 수 있기 때문에 모델 계산 자원의 할당이 더욱 유연해집니다.
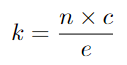
input token이 주어지면 token-to-expert assignment 방식으로 3가지 output인 로 나타낼 수 있습니다. 는 index matrix로 는 j-th 선택된 토큰이 i-th번째 expert에 할당된 것 입니다. 는 선택된 token을 위한 expert의 weight 입니다. 는 의 one-hot version으로 각 expert에 token을 모으기 위해 사용됩니다. 이 matrices는 gating function으로 사용됩니다.
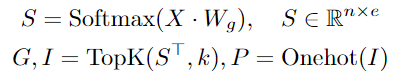
는 token-to-expert affinity score이고 는 expert embeddings, 그리고 는 의 k largets entries를 선택합니다.
Switch Transformer와 GShard와 유사하게, 이 논문은 mixture of experts와 gating function을 dense feed-forward(FFN) layer로 적용하였습니다. 는 i-th expert의 input입니다. 유사하게 는 FFN의 i-th expert 파라미터입니다.
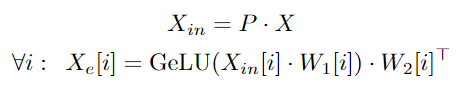
최종 output은 아래의 수식을 통해서 얻어질 수 있습니다. 그리고 이러한 연산은 einsum 연산을 통해서 구현되었습니다.
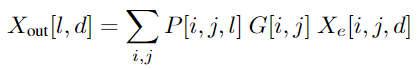
Expert Choice with Additional Constraint
또한, 이 논문에서는 expert choice routing에 각 토큰에 maximum number of experts 제한을 통해 규제를 줍니다. 이 논문은
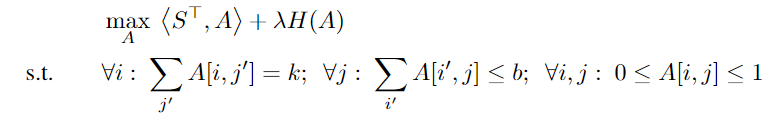
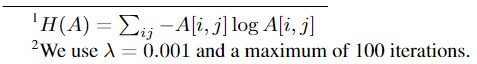
Model Architecture
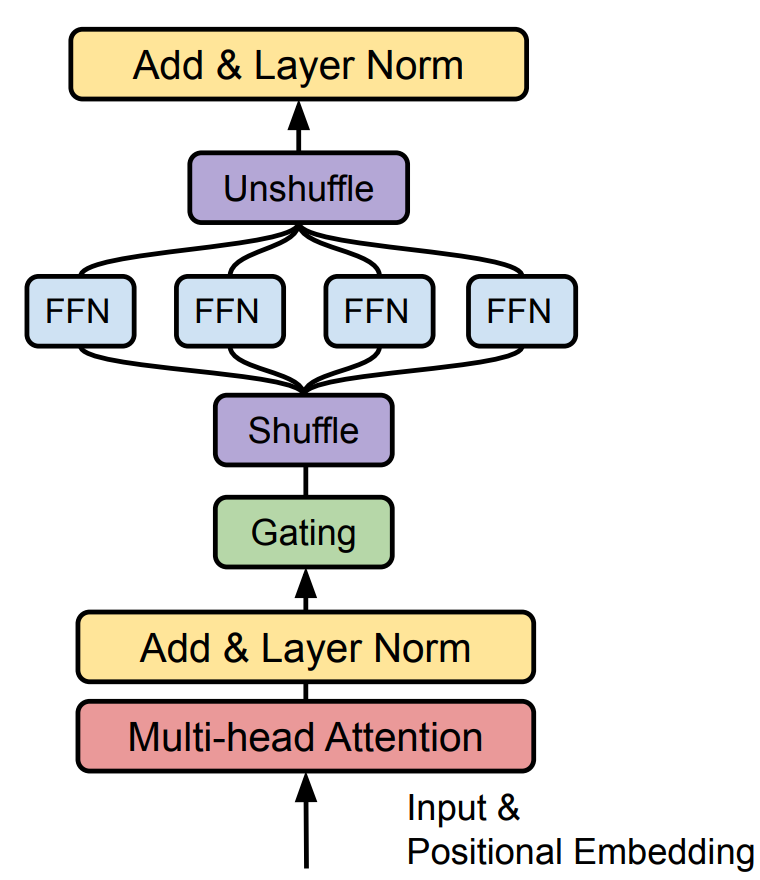
High level에서 Transformer 구조와 feed-forward component를 MoE layer로 대체하였습니다.
Experiments