[Paper Review] Text Is MASS: Modeling as Stochastic Embedding for Text-Video Retrieval (2024)
Paper I should read
목록 보기
3/18

Motivation
- 기존 데이터셋에서 텍스트 콘텐츠는 일반적으로 short and concise하므로, 비디오의 the redundant semantics을 완전히 설명하기 어려움.
--> A single text embedding은 비디오 임베딩을 포착하고 검색 기능을 강화하는 데 있어 표현력이 떨어질 수 있음
Proposed method
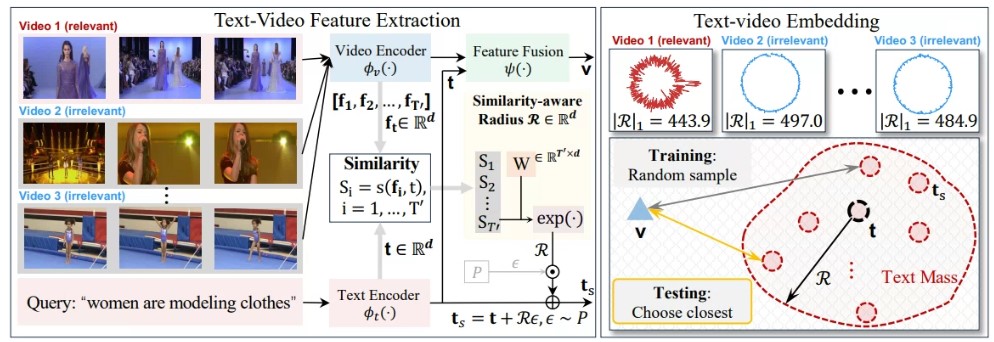
- New stochastic text modeling method T-MASS (text is modeled as a stochastic embeddings)
--> 텍스트 임베딩으로 flexible and resilent semantic range를 가지는, 텍스트 질량(text mass)을 생성함
- A similarity-aware radius module 텍스트-비디오 쌍에 따라 텍스트 질량의 규모(scale)를 결정함
- A support text regularization 훈련 중 텍스트 질량을 더욱 효과적으로 제어함
Contribution
- 관련된 텍스트-비디오 쌍을 효과적으로 attracts하면서 관련 없는 쌍은 거리를 두게 함
- 관련 쌍에 대한 정확한(precise) 텍스트 임베딩을 결정할 수 있게 함
Modalities
Video vs text
- 비디오는 중복된 의미론적 단서(redundant semantic clues)를 제공하는 경향이 있으며, 이는 특징 추출에 불가피한 도전을 제기함
- 텍스트는 일반적으로 short caption, subtiltles, and even hashtages로 나타나며, 비디오에 비해 의미론적으로(sematically) 제한된 것처럼 보임.
Previous research
- CLIP과 같은 강력한 vision-language model을 텍스트 비디오 멀디모달 도메인에 적용함
- 현재의 텍스트-비디오 검색 방법들은 검색을 위한 accurate video or text embedding 특징 추출에 전념함
Limitation of Previous research
- 비디오/텍스트 임베딩 방법의 성공에도 불구하고, 텍스트 콘텐츠는 일반적으로 짧고 간결하여 비디오와 관련된 콘텐츠에 비해 제한된 의미를 포함하기 때문에 하나의 텍스트 임베딩을 학습하여 비디오 내의 모든 의미론과 시각적 변화를 완전히 커버하기 어려움
→ 더 이상 text를 embedding space에 하나의 single point로 나타내는 것이 아닌 "mass"로 projects하여 비디오와 텍스트 임베딩 사이의 잠재적인 불일치를 고려할 수 있는 resilient semantic range를 가능하게 함.

How to project it as a "mass"
- CLIP에 의해 제공된 deterministic text embedding에 대한 reprametrization을 채택함으로써 텍스트 질량을 구현하는 간단한 방법이 있으나, 이러한 텍스트 질량 학습은 다음과 같은 어려움이 존재함.
- text mass의 규모(scale)을 정하는 것은 어려운 문제임. 기본적인 규모는 텍스트에 따라 달라지며, 서로 다른 비디오에 따라 동적일 수 있음
--> scale을 적응형으로 학습하며 similarity-aware radius module을 도입함 - joint embedding space에서 text mass를 어떻게 정규화하고 조정할 것인지는 정해지지 않음. 전체 text mass를 공동으로 처리(joint processing)하지 않고, 훈련 중에 샘플링된 stochastic text points와 video points가 대조학습만으로 학습하여도 좋은 성능을 내었음

꿈 꾸는 디그다