개요
이번 2차 고도화는 지난 1차 고도화에서 발견된 문제를 해결, 실제 운영 환경에서도 안정적으로 동작할 수 있는 구조로 개선을 최우선 목표로 진행되었다.
- SSE 구조의 한계를 극복하기 위해 WebSocket 기반 구조로 전환
- 정답 제출 시 GitHub 저장소로 자동 커밋 & 푸시되는 기능 구현
- 채점 관련 컴포넌트에 대해 단위 테스트를 작성하여 커버리지 100% 달성
또한, 실제 운영 환경에서의 성능을 확인하기 위해 동시 사용자 수에 따른 채점 처리량, 제출 언어별 성능 차이를 측정하고, 그 결과를 그래프 형태로 시각화하여 기록할 계획이다.
1. WebSocket 기반으로 전면 교체
지난 1차 고도화 과정에서는 SSE(Server-Sent Events)의 근본적인 한계를 마주하게 되었다.
SSE는 HTTP 기반 단방향 통신 방식으로, 서버가 클라이언트에게 데이터를 푸시할 수 있는 방식 중 비교적 쉽고 구현이 빠르다는 장점이 있다. 하지만 Spring Security와 Redis Stream을 함께 사용하는 현재 시스템 구조에서는, 다음과 같은 이유로 맞지 않았다.
-
Spring Security와의 호환 문제
SSE는 SseEmitter 객체를 반환해 연결을 유지하는 방식인데, 이 객체를 반환하는 과정에서 시큐리티 핵심 필터 중 하나가clearContext()를 호출, 비동기 흐름 (DispatcherType.ASYNC)에서 SecurityContext가 전파될 수 없는 구조였다. -
Redis Stream과의 부조화:
멀티 서버에서 메시지를 병렬로 소비 가능한 (Kafka-like) 구조상, 클라이언트와 연결되지 않은 서버가 메시지를 가져가 유실되는 문제가 발생할 수 있었다.
이러한 문제들로 인해 기존 SSE 구조는 실시간성, 안정성, 인증 유지라는 핵심 요건을 만족시키지 못했다.
1.1. WebSocket vs Polling
1차 고도화 당시에는 SSE를 대체할 기술로 WebSocket과 Polling 중 어떤 것을 선택할지에 대해 확답을 내리지 못한 상태였다.
일반적으로 코딩 테스트 사이트를 사용해보면, 하나의 문제에 대한 모든 테스트케이스가 한 번에 화면에 나타나고, 각 케이스의 채점 결과가 실시간으로 하나씩 갱신되는 UI를 볼 수 있다.
이러한 방식은 사용자에게 병렬 채점이 진행되고 있다는 인식을 직관적으로 주며, UX 측면에서 매우 중요한 역할을 한다고 판단했다.
이를 고려해 WebSocket과 Polling을 비교해보면 다음과 같다.
- WebSocket은 서버에서 테스트케이스 결과가 나오는 즉시 메시지를 발행하고, 클라이언트가 이를 바로 수신한다.
- Polling은 클라이언트가 주기적으로 서버에 요청을 보내 최신 상태를 확인한다.
예를 들어, 5초 동안 5개의 테스트케이스가 채점되고, Polling 주기가 2초라고 가정하면 다음과 같은 차이가 발생한다.
- WebSocket: 사용자는 5건의 실시간 갱신을 모두 확인할 수 있다.
- Polling: 2~3번의 갱신만 보이며, 타이밍에 따라 일부 채점 결과는 묶여서 한 번에 반영된다.
이처럼 실시간성과 체감 속도 측면에서 Polling은 불리하다고 판단했으며, 서버에 약간의 부하가 있더라도 사용자 경험(UX)을 최우선으로 고려해 WebSocket을 선택하게 되었다.
1.2. 실시간 채점 구조와 WebSocket 메시지 흐름
WebSocket을 도입하면서 가장 중요하게 설계한 부분은 사용자별로 채점 결과를 정확히 전달하고, 메시지 유실 없이 실시간 처리하는 구조를 만드는 것이었다.
전체 흐름은 아래와 같다.
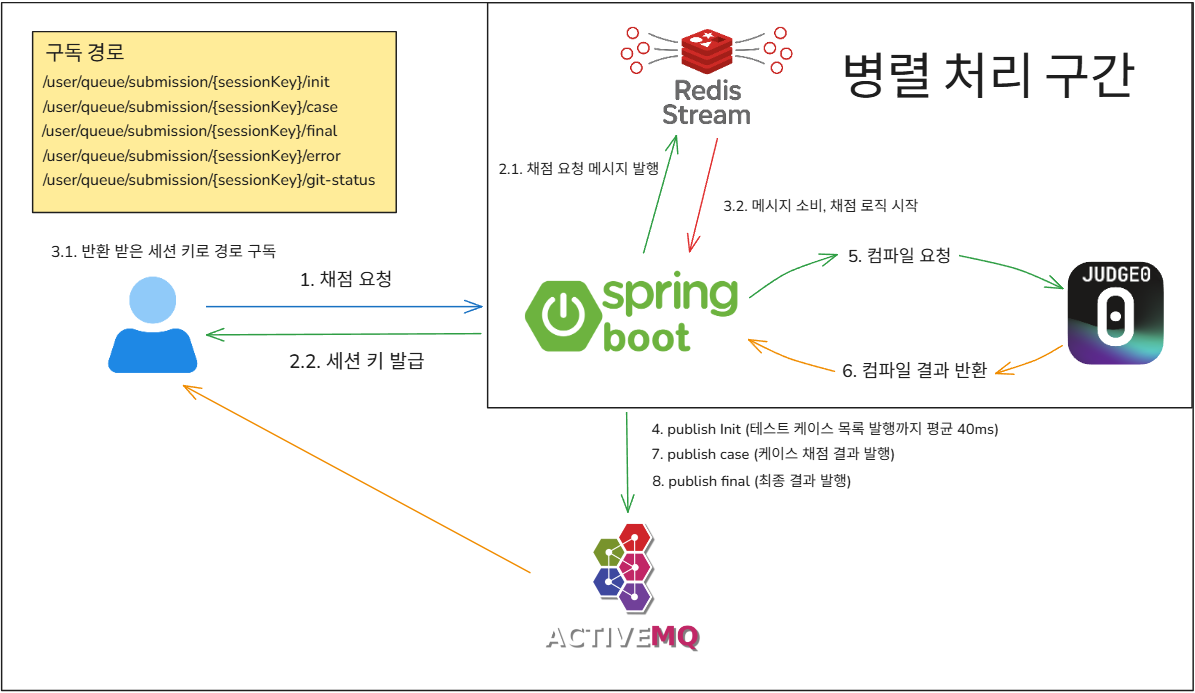
사용자가 문제를 제출하면 서버로 채점 요청이 들어오고, 요청을 받은 서버는 해당 정보를 Redis Stream에 메시지로 발행하며, 동시에 클라이언트에게 sessionKey를 발급해 응답한다.
이후 클라이언트는 발급받은 sessionKey를 기반으로 WebSocket 특정 구독 경로에 연결해 결과 수신을 준비한다.
한편, 서버 측에서는 Redis Stream을 구독 중인 채점 서버가 메시지를 소비하면서 채점 로직이 본격적으로 시작된다.
채점이 시작되면, 가장 먼저 테스트케이스 목록(init) 을 클라이언트에게 전송하는 메시지가 발행된다.
이 작업은 사용자가 채점 요청을 보낸 시점으로부터 평균 40ms 내외로 발생하며, 사용자는 빠르게 UI 상에서 테스트케이스 목록이 갱신되는 것을 확인할 수 있다.
그 다음 채점 서버는 모든 테스트케이스에 대해 병렬로 컴파일 요청을 컴파일 서버(Judge0)에 전송하고, 컴파일 서버는 각 요청에 대해 개별적으로 컴파일 결과를 응답한다.
응답을 수신함과 동시에 채점 서버는 이를 바탕으로 검증을 실시, 테스트케이스별 채점 결과(case)를 실시간으로 발행하며, 모든 케이스의 채점이 완료되면 최종 결과(final) 도 함께 전송된다.
이러한 구조 덕분에 하나의 세션이 여러 테스트케이스 결과를 유실 없이 실시간 수신할 수 있게 되었고,
기존 SSE 구조에서 발생하던 멀티 서버 환경에서의 문제 또한 근본적으로 해결할 수 있었다.
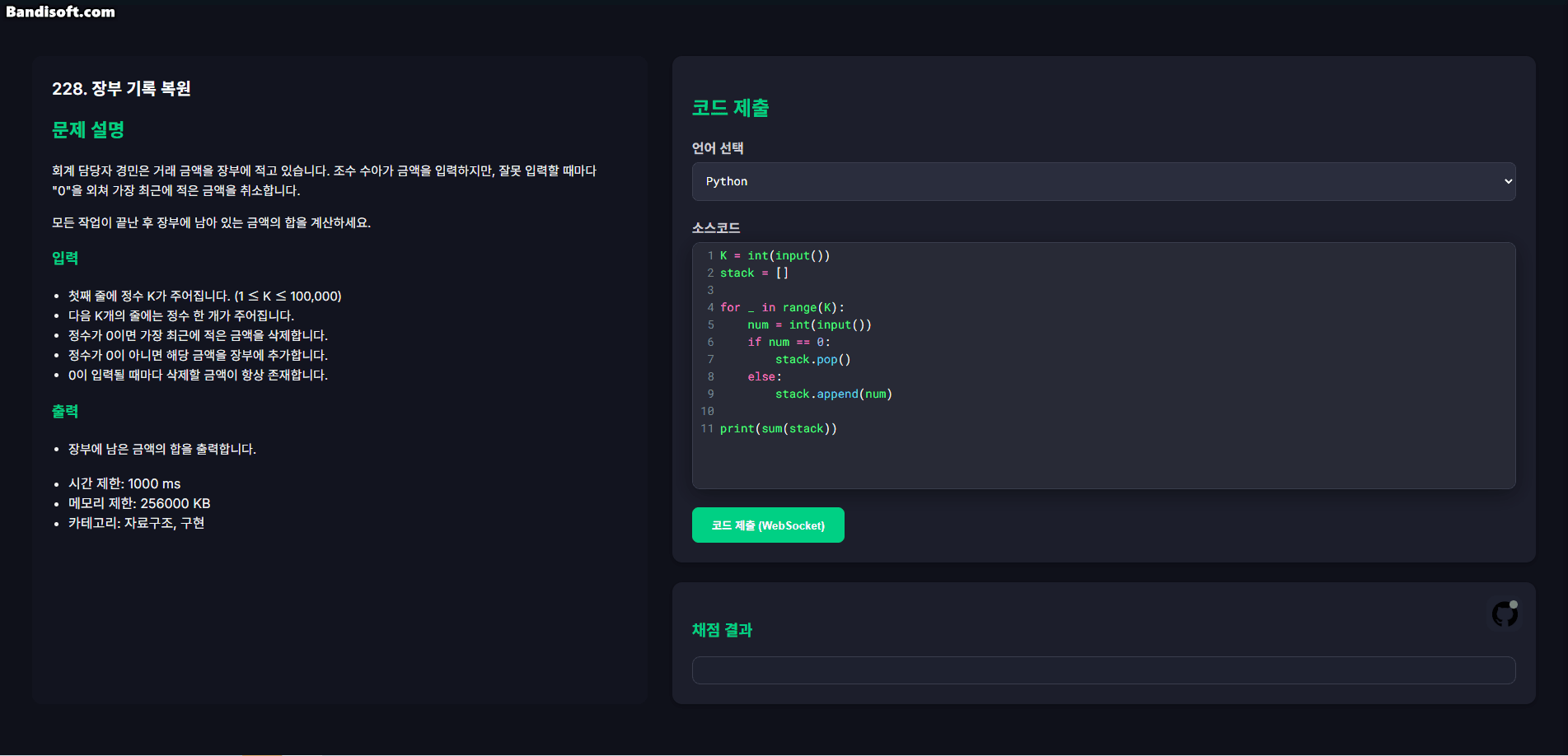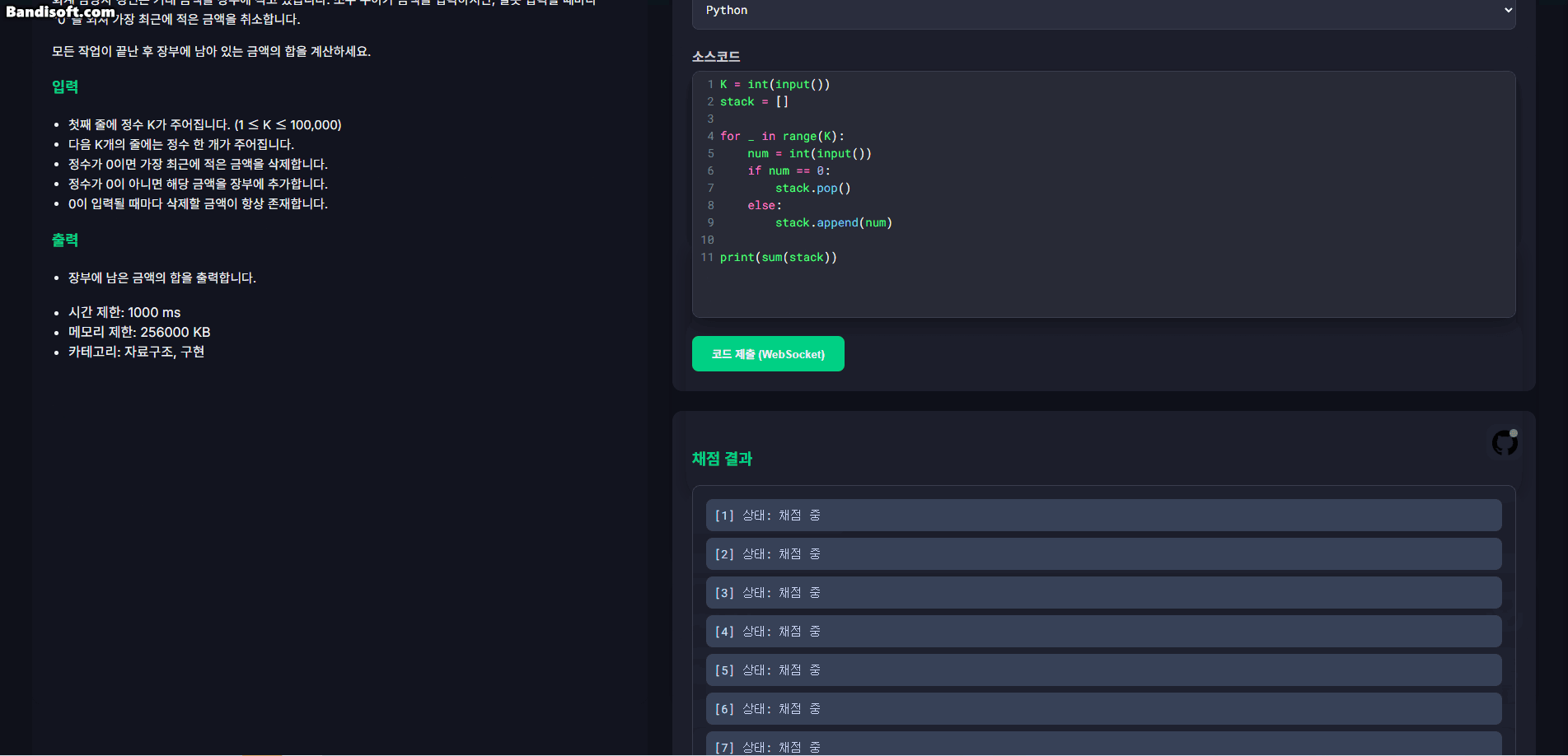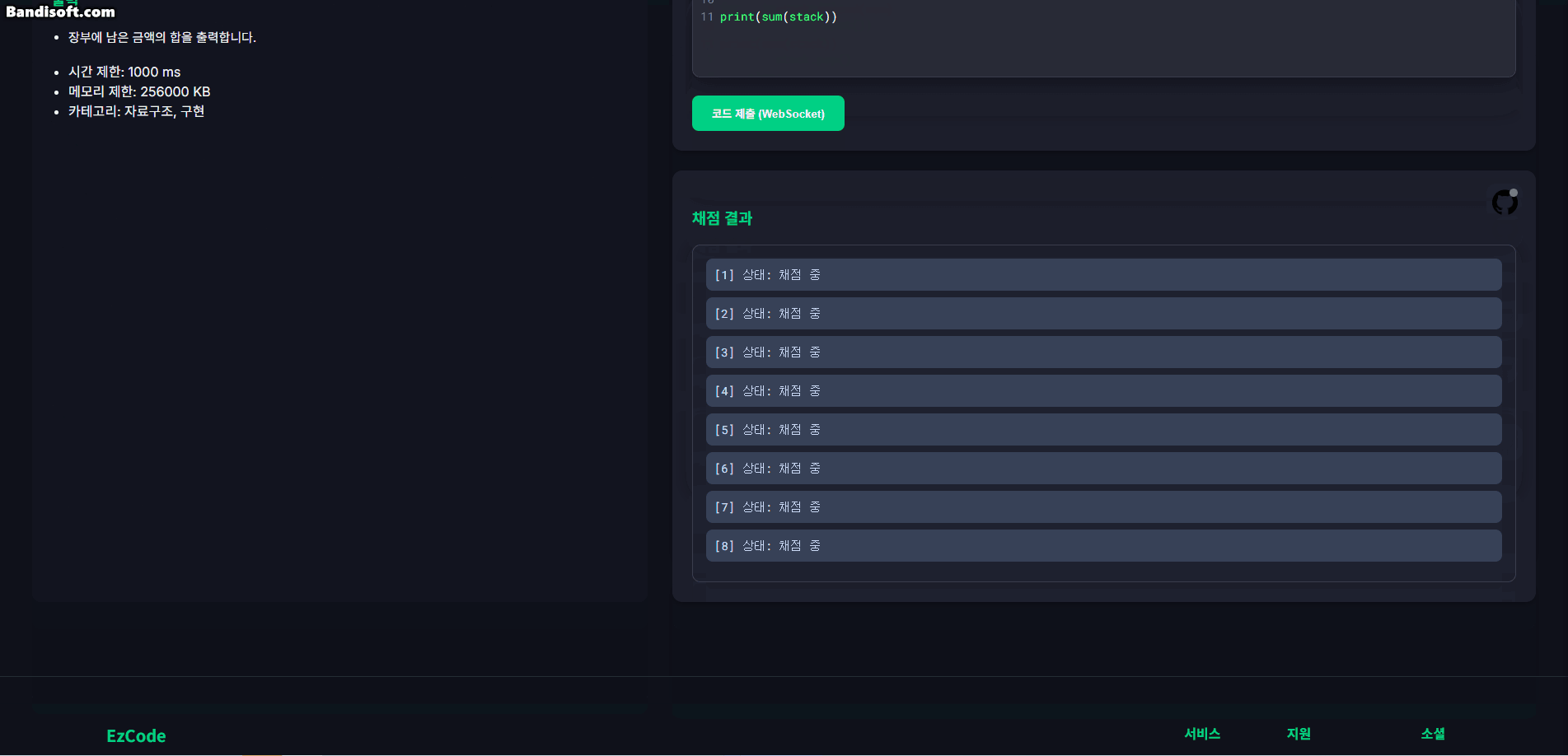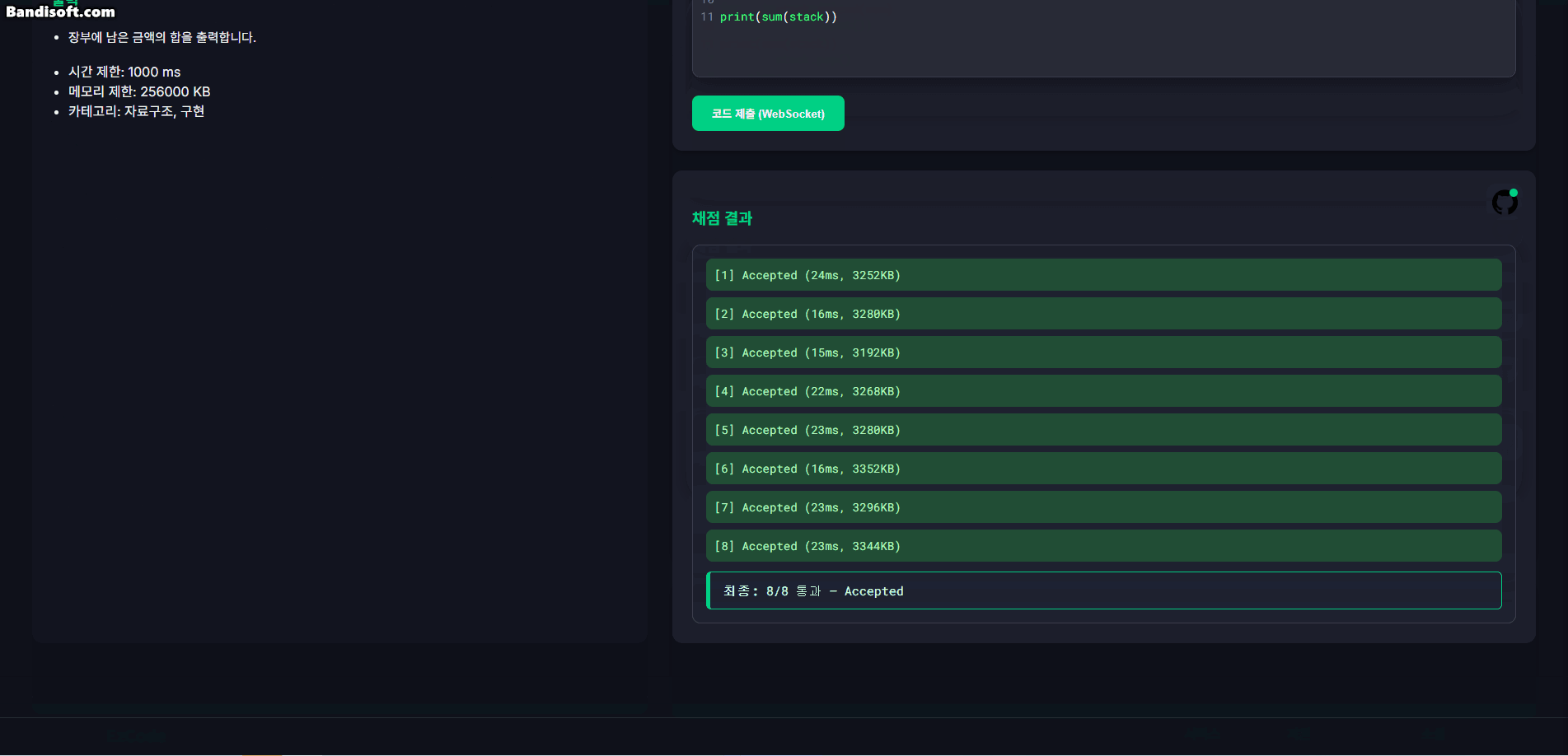
아래는 테스트용 UI 화면에서 테스트케이스 실행 결과가 WebSocket을 통해 실시간으로 갱신되는 모습이다.
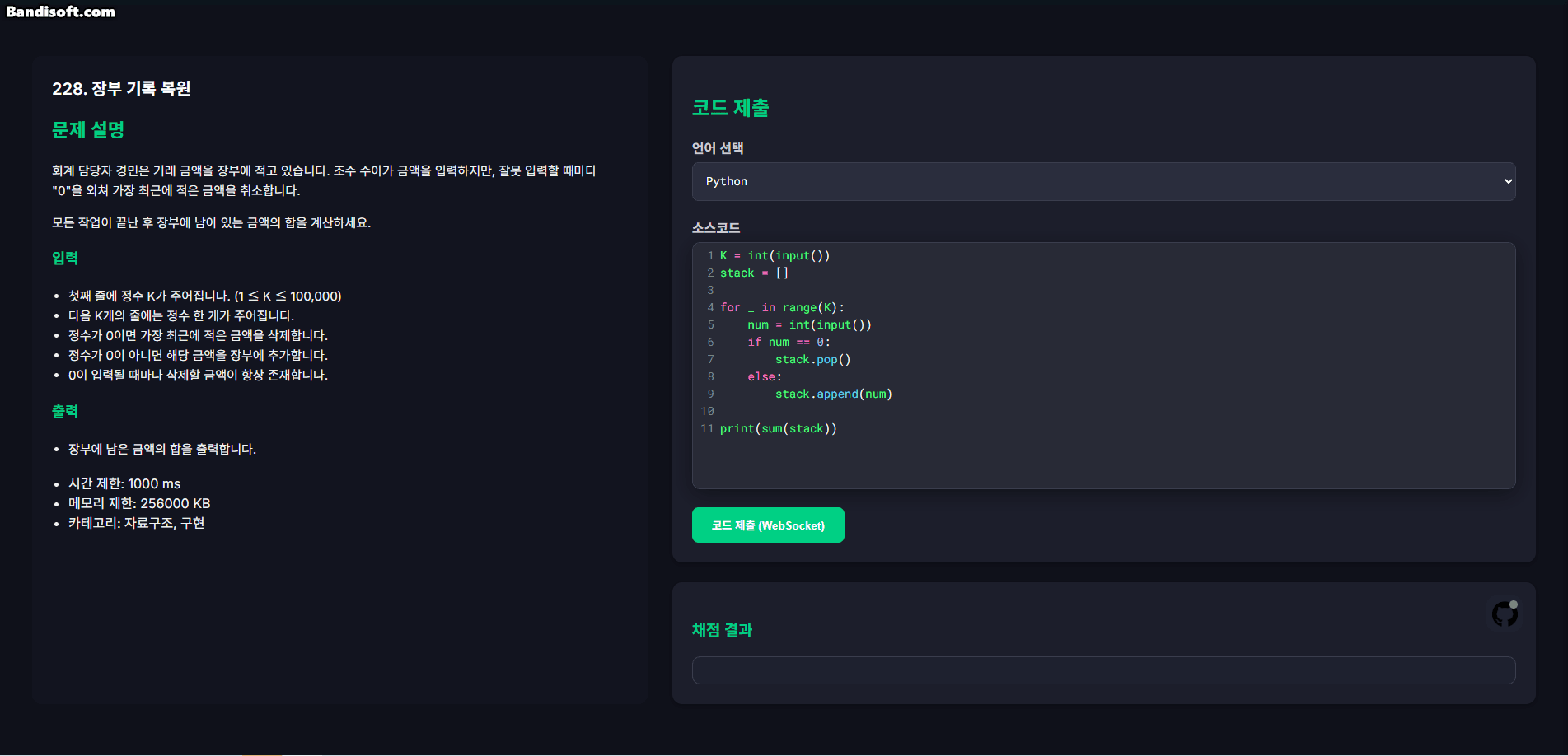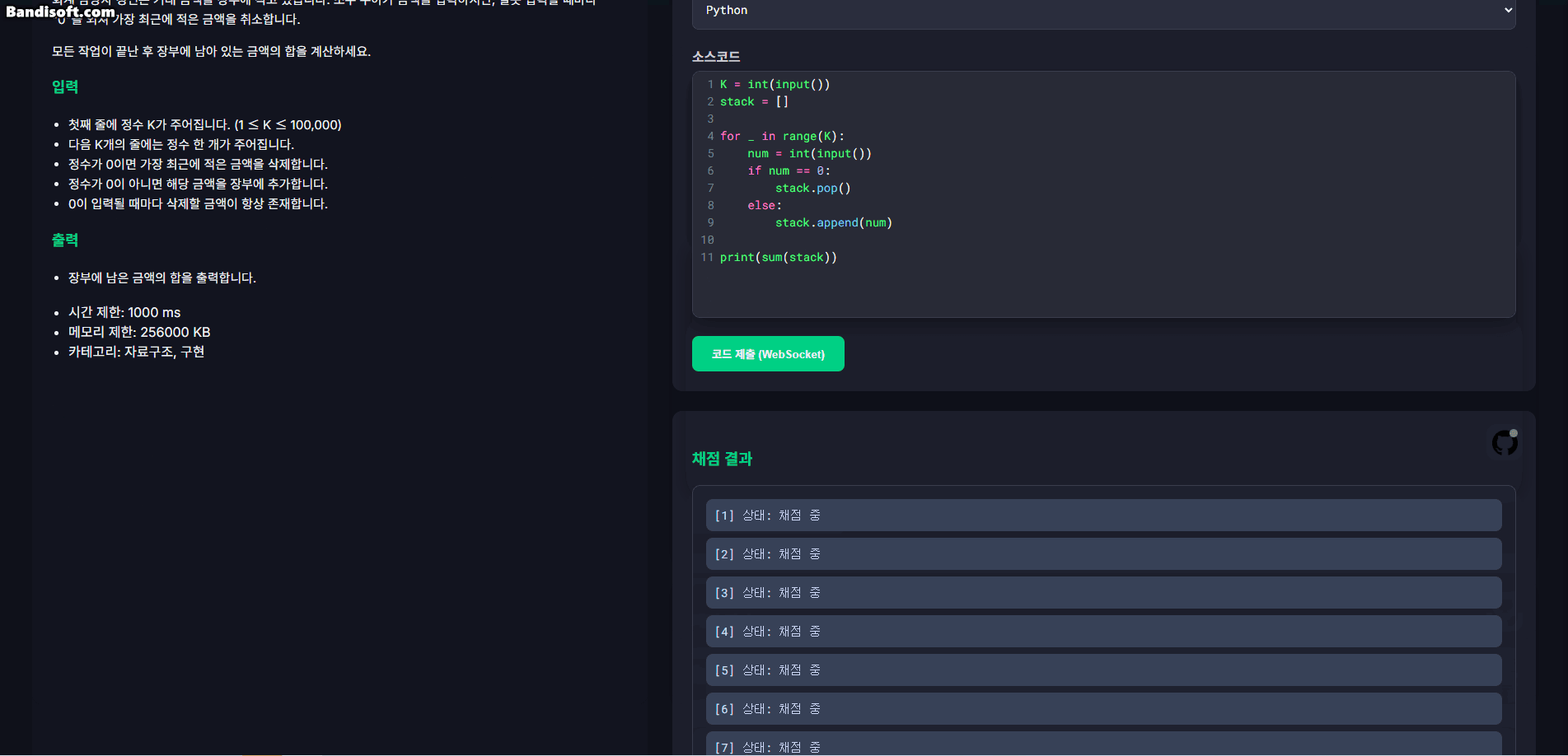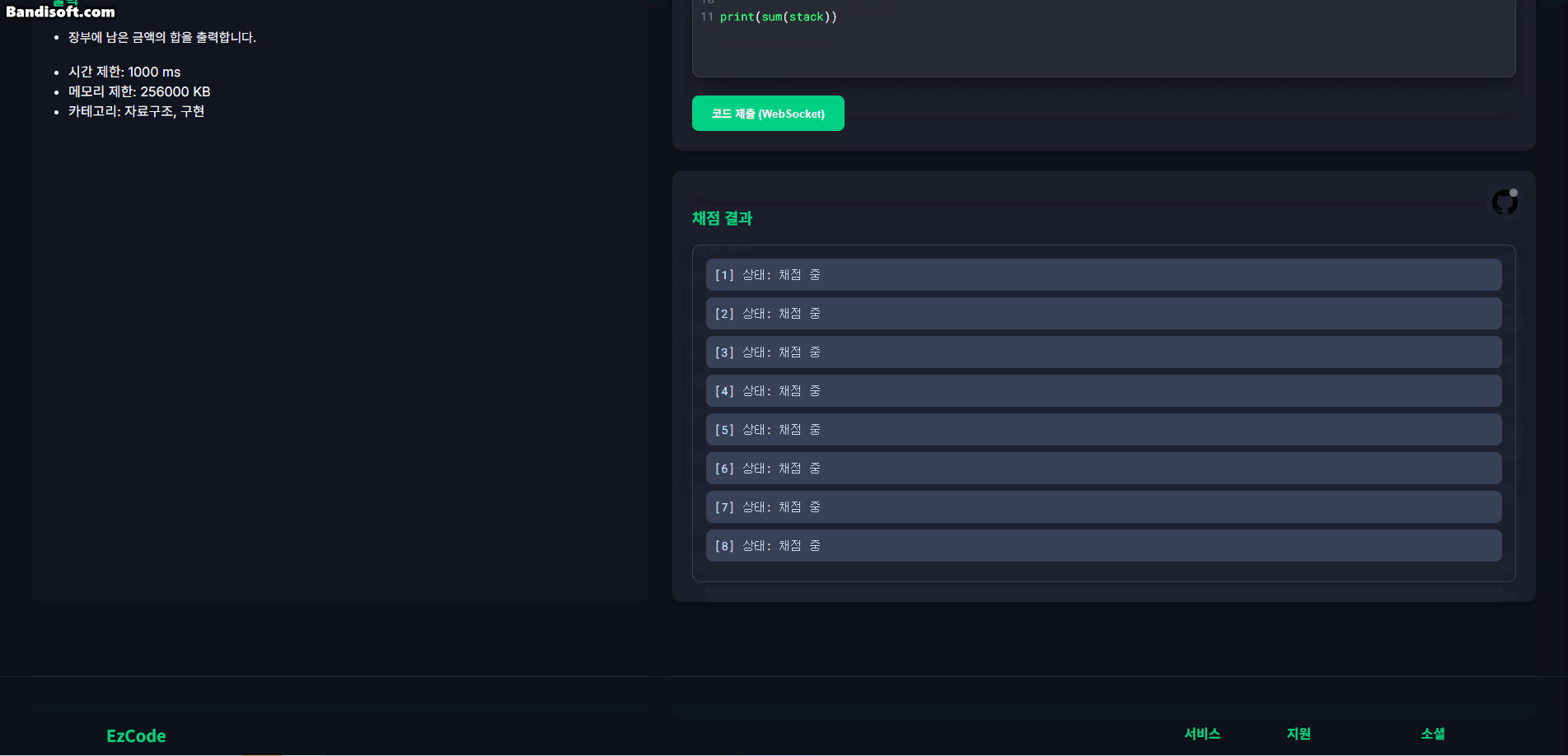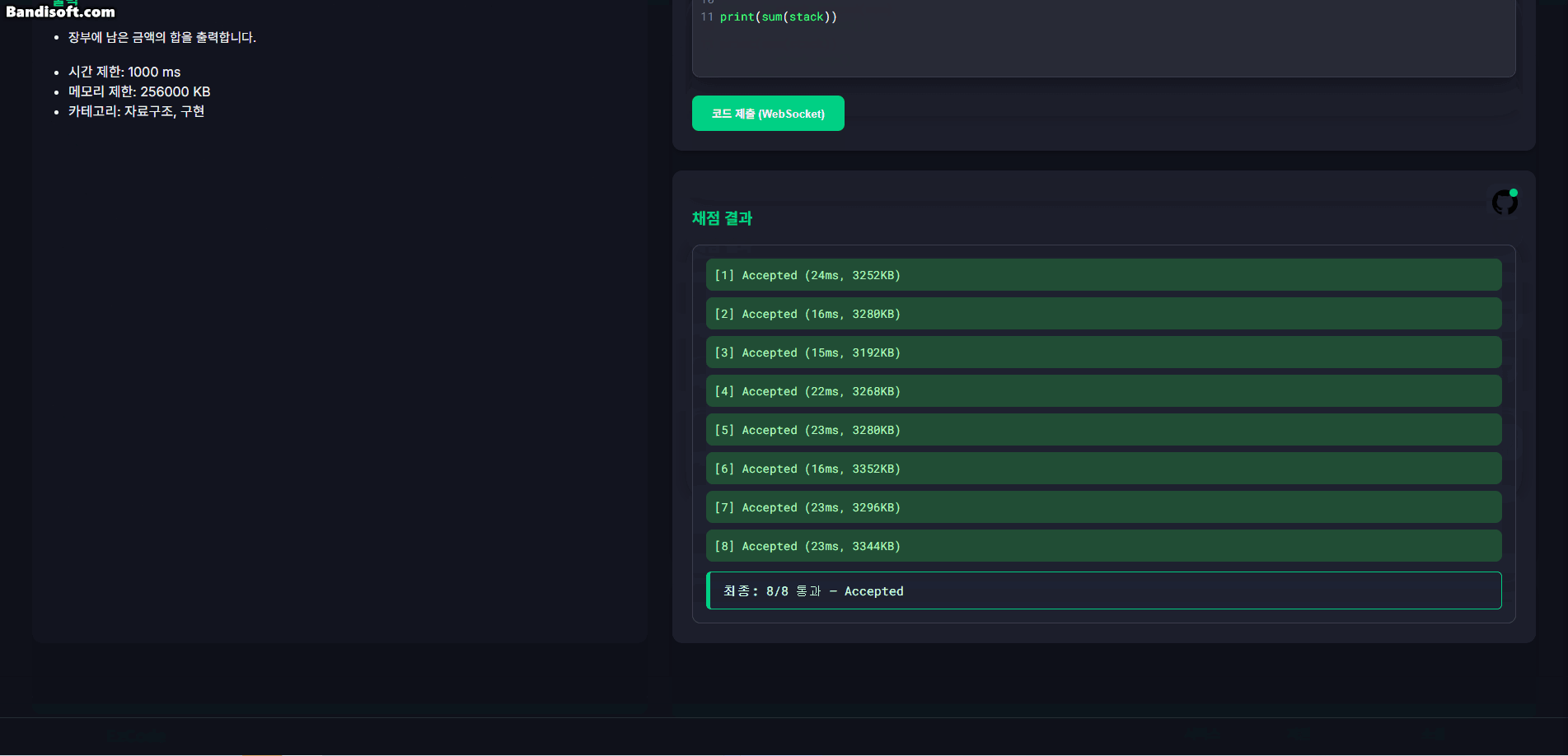
1.3. 트러블슈팅: init 메시지 누락 문제
앞 문단에서는 완성된 WebSocket 구조와 메시지 흐름을 설명했지만, 이 구조를 구현하는 과정에서 예상치 못한 트러블도 있었다.
가장 대표적인 문제가 바로 init 메시지의 간헐적인 누락이었다.
서버 로그를 출력해보면 init 메시지는 분명 정상적으로 발행되고 있었고,
SimpleMessageTemplate.convertAndSendToUser()를 통해 ActiveMQ 브로커로도 잘 전달되고 있었다.
ActiveMQ는 구독이 아직 완료되지 않은 경로로 이벤트가 발행되더라도 큐에 쌓아두었다가, 구독이 시작되면 자동으로 메시지를 전달해주는 구조이기 때문에, 메시지가 유실될 거라고는 생각하지 못했다.
그러나 실제로는 클라이언트 측에서 init 메시지만 종종 수신되지 않는 현상이 발생했다.
이를 확인하기 위해 브라우저의 개발자 도구 → Network 탭 → WebSocket 프레임 로그를 확인해보니, WebSocket 구독이 완료되기 직전에 init 메시지가 먼저 발행되는 상황이 포착되었다.

구독 메시지가 전송된 시각은 17:56:16.430 ~ .431이고, init 메시지 수신은 바로 이어진 17:56:16.486 전에 발생해야 했지만 이 메시지가 도착하지 않았다.
결국 문제는 메시지를 소비하고 전달하는 속도 자체가 너무 빨랐던 것이었다.
앞서 설명한 대로 init 메시지는 채점 요청 후 평균 40ms 내외로 발행되는데, WebSocket 구독 완료 시점과 발행 시점이 수 밀리초 차이로 엇갈릴 경우 메시지가 클라이언트로 전달되지 않을 수 있다.
이 사실을 깨달은 후, 서버에서 init 메시지를 발행하기 전 잠깐의 Thread.sleep() 을 주는 방식으로 급한 불을 끄긴 했지만, 이는 어디까지나 임시방편이다.
WebSocket 구조는 실시간성과 응답 속도가 생명인데, sleep을 넣는 순간 최대 수용 가능한 사용자 수가 감소하게 된다.
따라서 이 문제는 서버 측에서 delay로 해결하기보다는, 클라이언트 쪽에서 먼저 WebSocket 구독을 확실히 완료한 후 채점 요청을 보내는 방향으로 구조를 재정비할 계획이다.
이 경험을 통해, 로그 확인의 중요성과 "메시지 발행 타이밍"이라는 아주 짧은 시간의 이슈가 얼마나 치명적일 수 있는지를 직접 체감할 수 있었다.
2. GitHub 자동 푸시: 개발자스럽게 풀이 기록 남기기
이번 고도화에서 가장 재미있고도 의미 있는 기능 중 하나는 바로, 문제 풀이 결과가 정답일 경우, GitHub 저장소에 풀이 기록을 자동으로 커밋 & 푸시해주는 기능이다.
단순히 서버에만 저장하는 것이 아니라, "한 문제를 풀었다"는 사실을 내 GitHub 저장소에 기록으로 남기고, 잔디와 커밋 로그를 통해 성장 히스토리를 시각화할 수 있다.
2.1. 기능 개요
이 기능은 다음 세 가지 조건을 모두 만족해야 작동한다.
- GitHub OAuth 연동이 완료된 사용자
- 채점 결과가 정답(
isPassed == true) - GitHub Push 기능이 ON 상태(
isGitPushStatus == true)
위 조건을 만족할 경우 내부적으로 GitHubPushService가 동작한다. 암호화되어 저장된 GitHub 토큰은 aesUtil을 통해 복호화되고, 이후 GitHubClient를 통해 API 기반 커밋 & 푸시가 진행된다.
if (!ctx.isGitPushStatus() || !ctx.isPassed()) {
return;
}
String decryptedToken = aesUtil.decrypt(info.getGithubAccessToken());
gitHubClient.commitAndPushToRepo(GitHubPushRequest.of(ctx, info, decryptedToken));2.2. 처리 흐름
동일한 문제에 대해 같은 코드로 제출할 경우 불필요한 커밋이 쌓이지 않도록 SHA 비교를 통해 변경 여부를 감지한다.
String codeBlobSha = blobCalculator.calculateBlobSha(req.sourceCode());
Optional<String> existingSha = gitHubApiClient.fetchSourceBlobSha(req);
if (existingSha.map(codeBlobSha::equals).orElse(false)) {
return; // 동일 코드이므로 커밋 생략
}- 현재 제출된 코드의 SHA-1 해시를 계산
- 저장소에 이미 동일한 내용의 blob이 존재하는지 확인
- 동일하다면 커밋을 생략
이후 실제 커밋 과정을 GitHub API로 수행하는데, 일반적인 git commit → git push 명령어처럼 단순하지 않고 다음과 같은 순서로 진행한다.
- 현재 브랜치의 최신 커밋 SHA 조회
- 해당 커밋의 base tree SHA 조회
- 커밋할 파일 목록 기반으로 새로운 blob 및 tree 객체 생성
- 새 커밋 생성 및 브랜치 HEAD 업데이트
String headCommitSha = fetchHeadCommitSha(req);
String baseTreeSha = fetchBaseTreeSha(req, headCommitSha);
String newTreeSha = createTree(req, baseTreeSha, entries);
String commitSha = createCommit(req, parentSha, treeSha);
updateBranchReference(req, commitSha);이 과정을 통해 실제 Git 내부 구조와 동일하게 commit → tree → blob 흐름이 구성되며, 모든 요청은 WebClient 기반으로 수행된다.
현재는 사용자의 저장소 디폴트 브랜치 기준으로 커밋이 이루어지며, 향후에는 브랜치 선택 기능도 도입할 예정이다.
2.3. 커밋 구조 및 파일 경로
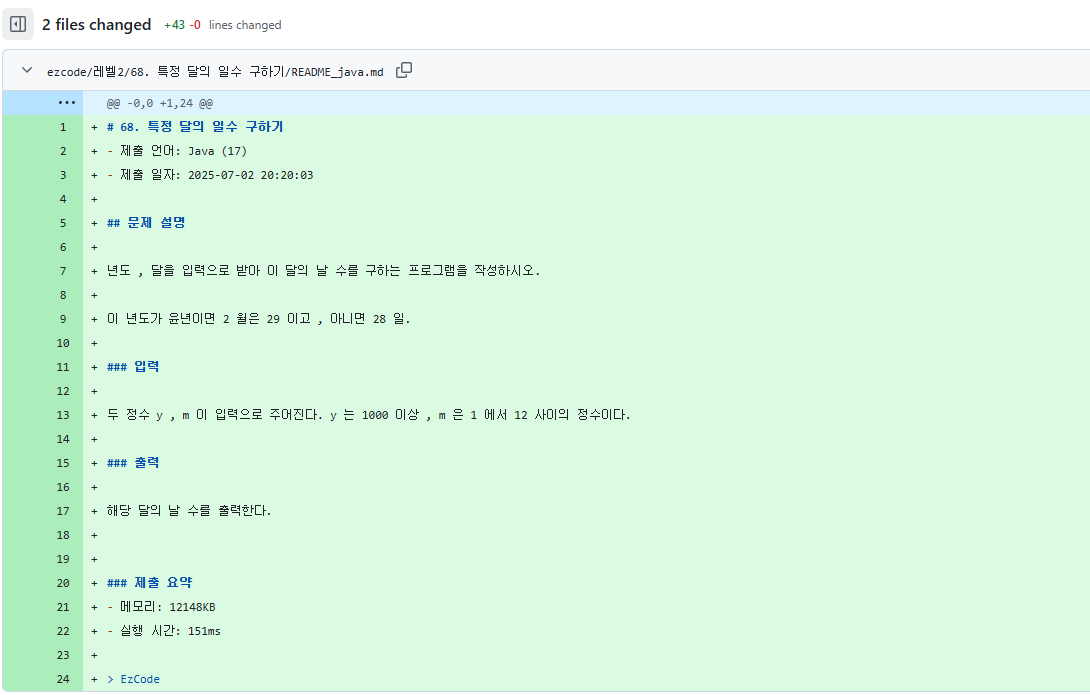
커밋에는 단순한 소스코드뿐 아니라 문제 제목, 설명, 제출 시간, 메모리/시간 사용량 등이 포함된 README_언어이름.md 파일도 함께 저장된다.
예시: README_python.md
# 68. 특정 달의 일수 구하기
- 제출 언어: Python (3.8.1)
- 제출 일자: 2025-07-03 18:21:34
## 문제 설명
년도 , 달을 입력으로 받아 이 달의 날 수를 구하는 프로그램을 작성하시오.
...
### 제출 요약
- 메모리: 3310KB
- 실행 시간: 23ms
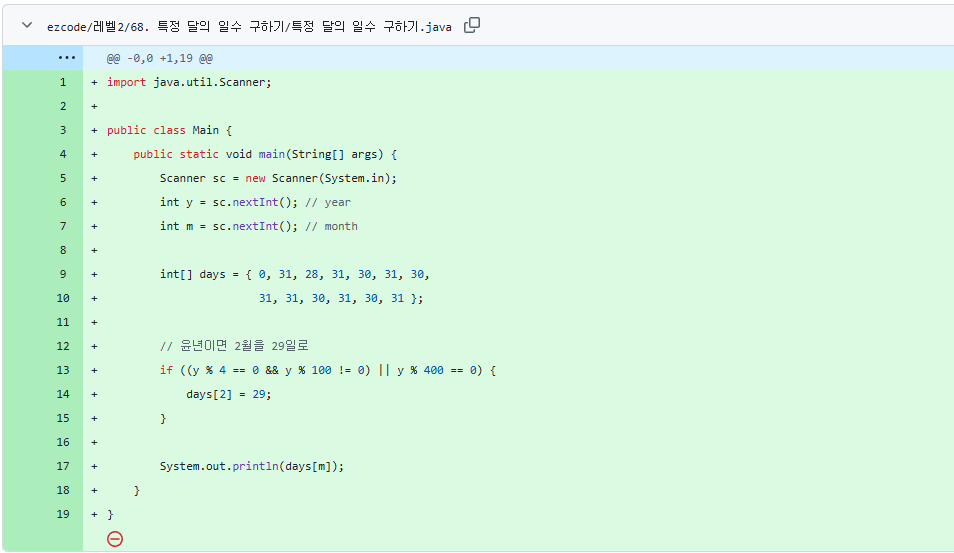
> EzCode파일 저장 경로는 다음과 같은 구조로 구성된다.
/<루트>/<난이도>/<문제번호. 문제제목>/README_언어이름.md
/<루트>/<난이도>/<문제번호. 문제제목>/문제제목.언어별 확장자예를 들어 Java로 제출했다면 아래와 같이 저장된다.
/ezcode/레벨1/1000. A+B/README_java.md
/ezcode/레벨1/1000. A+B/A+B.java해당 파일명 처리는 FileType enum을 통해 처리되며, 언어에 따라 확장자가 자동 결정된다.
public enum FileType {
SOURCE, README;
public String resolveFilename(GitHubPushRequest req) {
return switch (this) {
case SOURCE -> String.format("%s.%s",
req.problemTitle(), Extensions.getExtensionByLanguage(req.languageName())
);
case README -> String.format("README_%s.md",
req.languageName().toLowerCase()
);
};
}
}동일한 문제를 다른 언어로 제출하면 해당 폴더 내에 각 언어별 코드와 README 파일이 누적되어 커밋된다. 이 구조 덕분에 GitHub 커밋 로그를 통해 문제 풀이 히스토리를 시계열로 추적할 수 있다.
2.4. 예외 처리 및 사용자 알림
커밋 한 건을 푸시하기 위해서는 내부적으로 총 6번의 GitHub API 호출이 이루어진다.
단계가 여러 번으로 나뉘기 때문에, 이 중 하나라도 실패하면 전체 커밋 흐름이 그대로 무너질 수 있다. 이를 방지하기 위해, 실제 구현에서는 API별로 발생 가능한 예외를 명확하게 분리해 처리하고 있다.
protected Optional<String> fetchSourceBlobSha(GitHubPushRequest req) {
String fileName = FileType.SOURCE.resolveFilename(req);
String path = String.format("%s/%s/%s/%s", repoRootFolder, req.difficulty(), req.getProblemInfo(), fileName);
return baseBuilder(req.accessToken())
.get()
.uri(uriBuilder -> uriBuilder
.path(CONTENTS_PATH)
.queryParam("ref", req.branch())
.build(req.owner(), req.repo(), path)
)
.retrieve()
.onStatus(status -> status == HttpStatus.UNAUTHORIZED,
resp -> Mono.error(new GitHubClientException(GitHubExceptionCode.INVALID_ACCESS_TOKEN)))
.onStatus(status -> status == HttpStatus.FORBIDDEN,
resp -> Mono.error(new GitHubClientException(GitHubExceptionCode.PERMISSION_DENIED)))
.onStatus(status -> status == HttpStatus.TOO_MANY_REQUESTS,
resp -> Mono.error(new GitHubClientException(GitHubExceptionCode.RATE_LIMIT_EXCEEDED)))
.onStatus(HttpStatusCode::is5xxServerError,
resp -> Mono.error(new GitHubClientException(GitHubExceptionCode.NETWORK_ERROR)))
.bodyToMono(JsonNode.class)
.map(node -> node.get("sha").asText())
.onErrorResume(WebClientResponseException.NotFound.class, e -> Mono.empty())
.onErrorMap(e -> e instanceof GitHubClientException
? e
: new GitHubClientException(GitHubExceptionCode.UNKNOWN_ERROR))
.blockOptional();
}이 외에도 모든 GitHub API 호출에는 상황별로 커스텀 예외 코드가 적용되어 있어, 단순히 실패 여부만 판단하는 것이 아니라, 어디서 어떤 문제가 발생했는지 정확히 추적할 수 있도록 예외 코드를 세분화해 관리하고 있다.
예외가 발생한 경우에는 다음과 같은 방식으로 사용자와 운영자 모두에게 즉시 알림이 전파된다.
- 내부
ExceptionNotifier를 통해 디스코드 등의 운영 채널에 오류 메시지 전송 - 프론트엔드에는 상태 이벤트 (
Started,Succeeded,Failed) 전송 - 사용자는 UI 상에서 GitHub 푸시 상태를 실시간으로 확인 가능
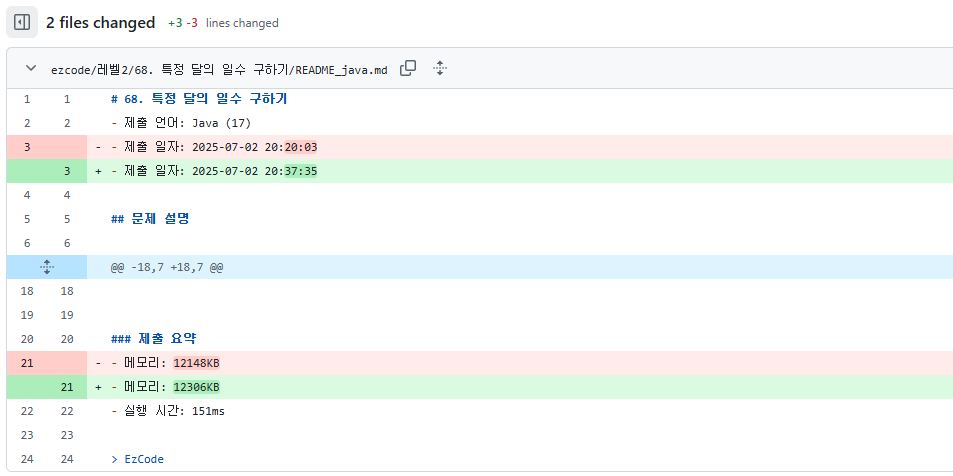
2.5. 실제 사용 예시 및 마무리
실제 GitHub에 반영된 커밋 모습
다른 소스 코드로 다시 제출했을 땐 이렇게 변경 사항도 기록이 된다.
GitHub 자동 푸시 기능은 단순히 소스코드를 저장소에 올리는 기능을 넘어, 개발자의 학습 과정을 자연스럽게 기록으로 전환해주는 역할을 한다.
문제를 풀고 제출하는 순간, 해당 풀이가 GitHub에 커밋되고 히스토리로 남는다는 것은 단지 기술적 편의를 넘어서, 매일의 성장 과정을 시각적으로 축적해 나갈 수 있다는 뜻이다.
이처럼 자동 푸시 기능은 사용자의 풀이 경험을 일회성 활동으로 소비하지 않고, 꾸준히 이어지는 학습 과정의 일부로 만들어준다. 결국 "정답을 맞히는 것"에 그치지 않고, 그 과정을 기억하고 쌓아갈 수 있도록 돕는 구조를 만들어가는 데 목적이 있다.
3. 채점 성능 테스트
프로젝트 구현 과정에서 언어별로 채점 요청을 동시에 보냈을 때, 응답 시간과 최대 채점 수용량에서 큰 차이를 체감한 바 있다.
따라서 언어별 응답 시간(avg_time_ms) 증가 추이와 사용자 수(user_count)에 따른 처리 성능 차이를 측정함으로써,
컴파일 서버 스펙 선정의 기준을 확보하는 것을 목표로 성능 테스트를 진행하였다.
테스트 도구로는 Node.js 기반 사용자 시뮬레이션 스크립트를 직접 작성하였으며, JWT 기반 인증과 WebSocket 수신을 활용해 다중 사용자 채점 요청을 수행하였다.
해당 테스트 스크립트는 GitHub 저장소에서 확인할 수 있다.
3.1 테스트 시나리오
다음과 같은 조건과 절차에 따라 성능 테스트를 설계하였다.
테스트 대상 문제

- 문제 이름: 변경 가능한 구간 합
- 분류: 세그먼트 트리, 자료구조
- 핵심 연산: "원소 변경" + "구간 합 조회"가 반복적으로 혼합
- 테스트케이스 수: 총 8개
- 입력 사이즈: 최대 1,000,000개의 원소, 최대 10,000회의 연산
→ 메모리와 시간 복잡도가 높은 구조로, 서버 부하 유발에 효과적
테스트 목적에 적합하도록, 고부하 문제로 선택했으며 실제 컴파일 서버에서 메모리와 연산량을 강하게 요구한다.
테스트 조건
- 컴파일 서버 사양: 8 vCPUs, 32 GB RAM, 640 GB SSD
- 테스트 언어: Java (1), C (2), C++ (3), Python (4)
- 동시 요청 수: 5명 / 10명 / 20명 / 30명 / 40명
- 반복 횟수: 각 조합당 5회 이상 실행
- 측정 지표:
final_receive_ms,testcase_received_count,loss_rate
loss_rate: 일부 테스트케이스가 수신되지 않은 비율
→ 정상 수신률이 100% 미만이면 동시성 처리에 문제 발생으로 간주
데이터 수집 방식
- 저장 위치:
MySQL테이블test_result_table - 구분 방식:
language_id→ 1~4 (Java, C, C++, Python)test_type→concurrency_5_users,concurrency_10_users등
- 단위: 밀리초(ms) 기준
3.2. 테스트 결과
응답 시간 테이블
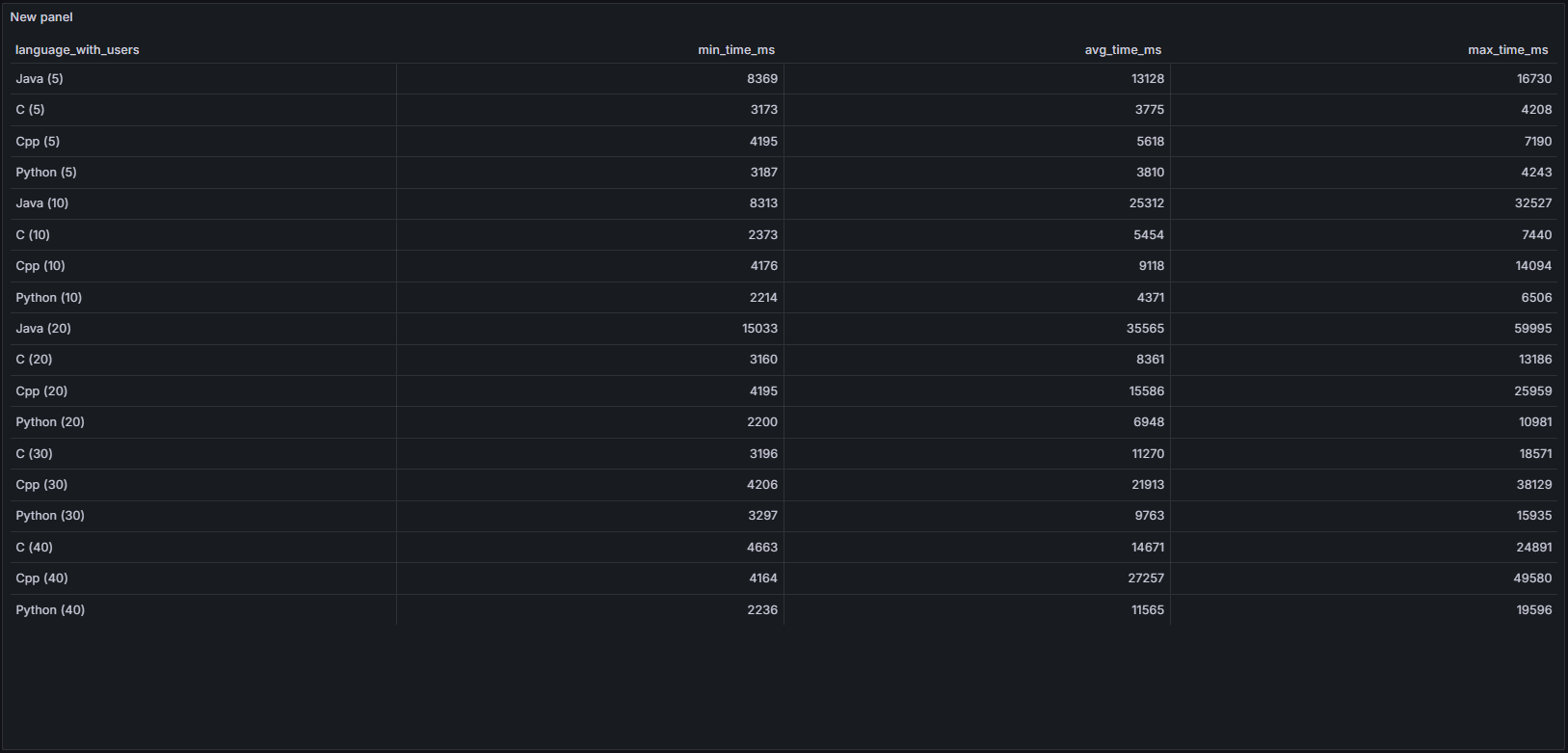
- Java는 동시 요청 수가 증가할수록 응답 시간이 급격히 상승
- 반면 C, Python은 비교적 완만한 상승을 보였으며, 낮은 사용자 수 기준 성능은 우수
- C++은 중간 성능이나, 사용자 수가 많아질수록 Java 다음으로 높은 응답 시간을 기록
전체 성능 그래프 (min/avg/max)
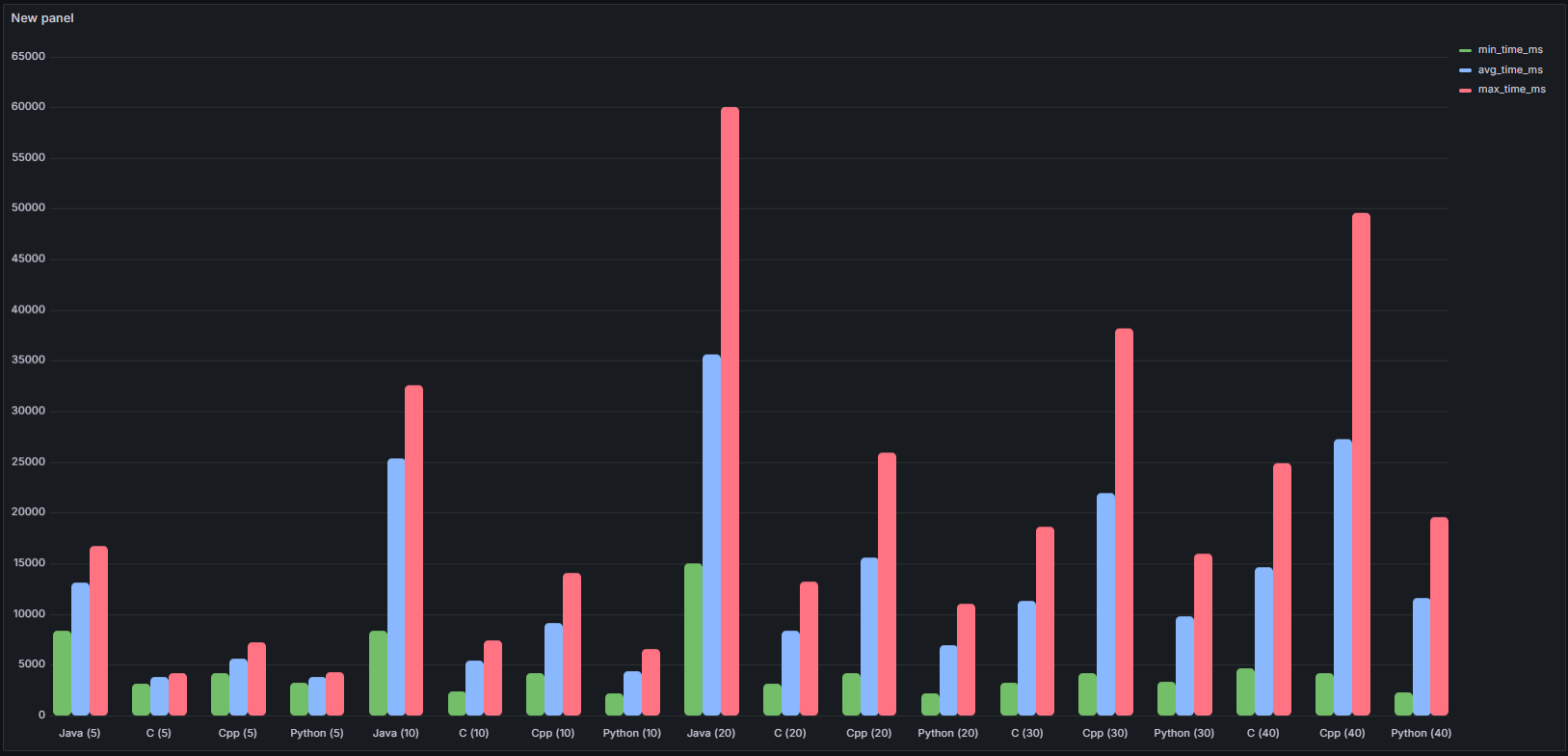
- Java는 일관되게 가장 높은 응답 시간
- 특히 20명 이상부터 급격한 증가, 최대 60초 근접 → 측정 불가 수준
- Python은 거의 모든 케이스에서 안정적인 성능 유지
응답 시간 분포 선 그래프
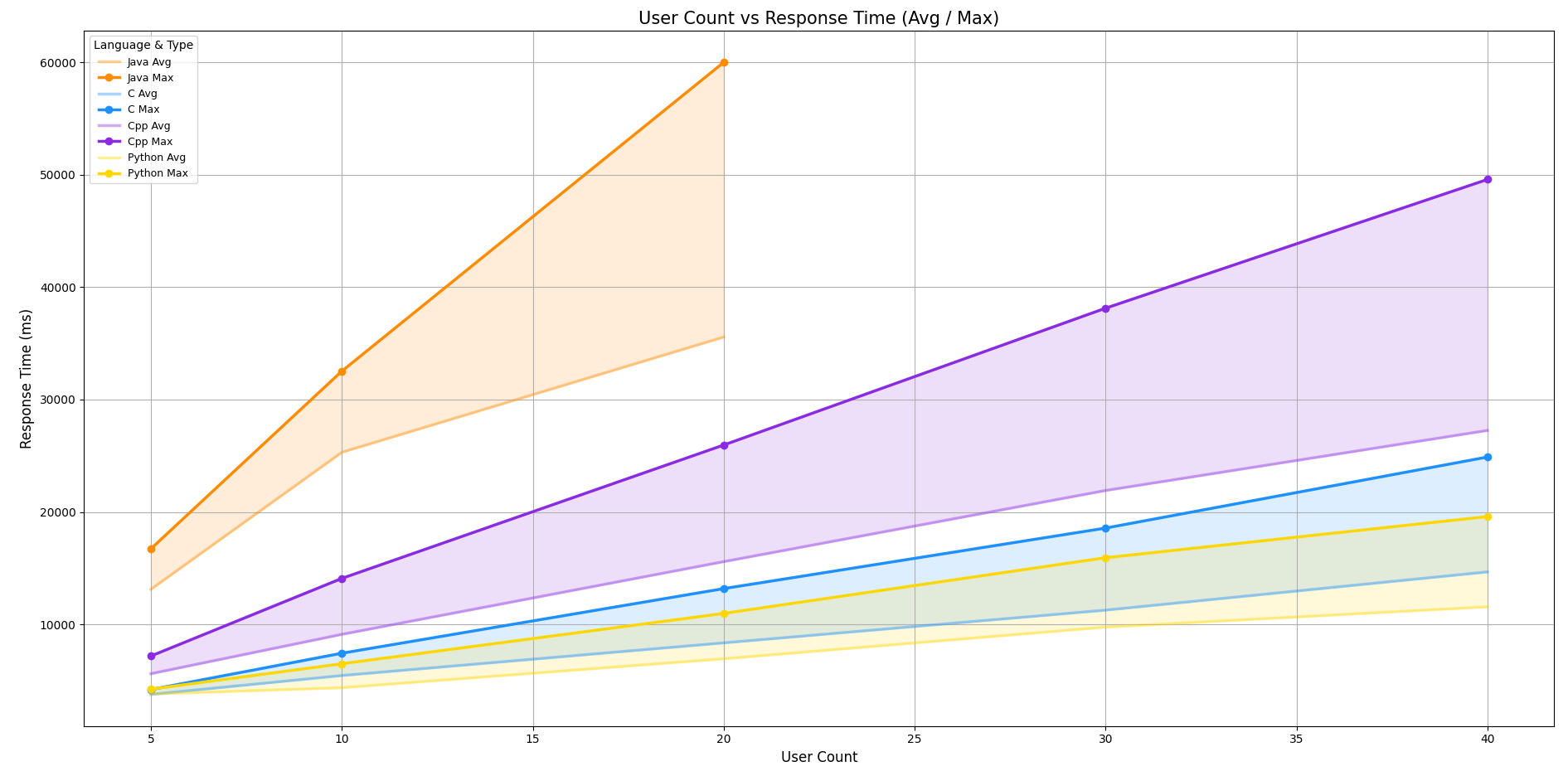
- x축: 사용자 수, y축: 응답 시간(ms)
- 각 언어별 평균(Avg) 과 최대(Max) 응답 시간을 선과 그림자로 시각화
- Java / C++: 사용자 수가 늘어날수록 응답 시간이 급격히 증가, 성능 저하 뚜렷
- Python / C는 성능이 안정적이고 일정하게 유지
메세지 손실율 테이블
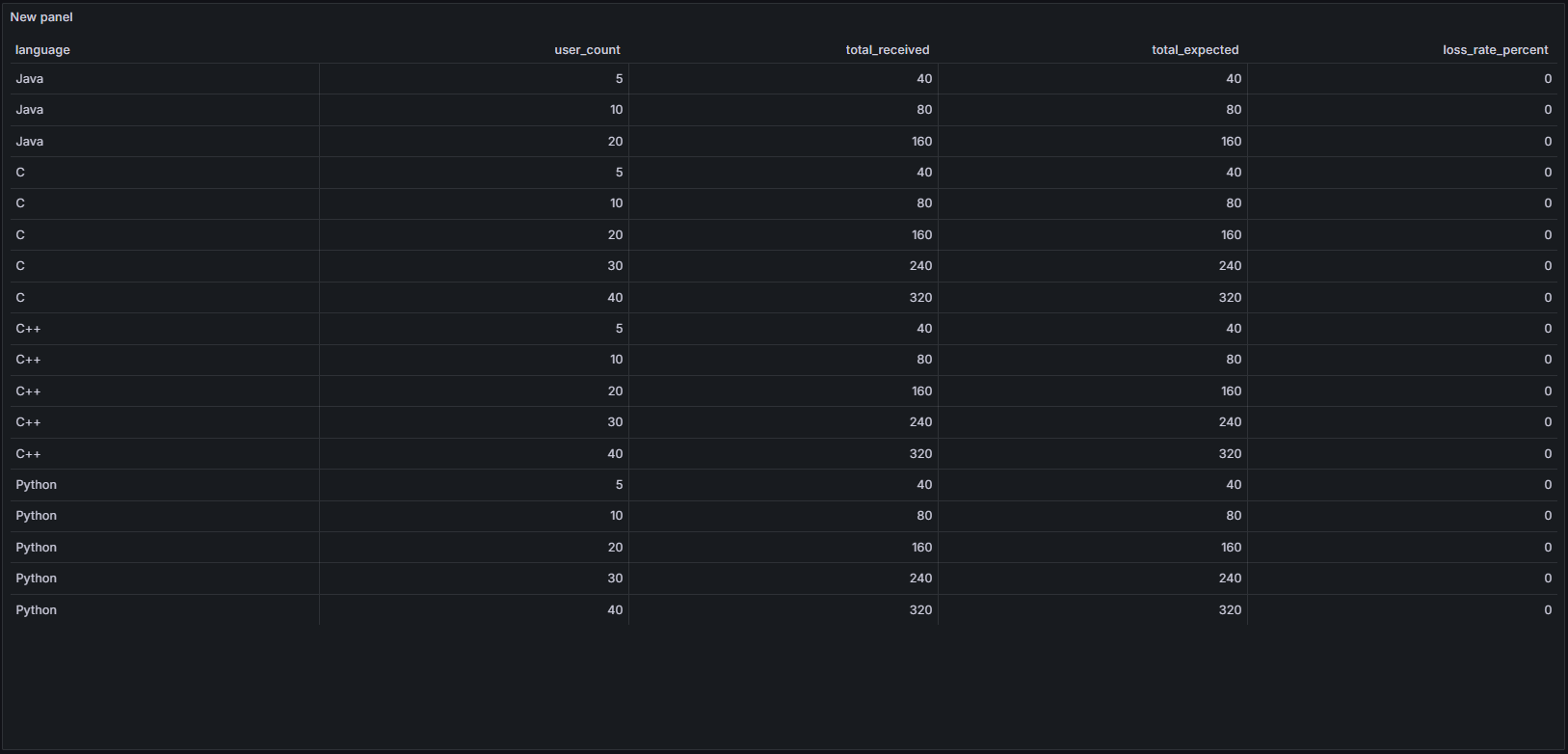
- 모든 언어 및 모든 동시 사용자 수 조합에서 손실률은 0%로 나타났다.
- 즉, 최대 40명의 동시 제출 환경에서도 단 하나의 테스트 케이스 채점 결과도 누락되지 않고 정확히 수신되었음을 의미한다.
3.3. 결과 해석 및 인사이트
1. Java의 느린 응답 속도
테스트 결과를 살펴보면, Java는 다른 언어들에 비해 상대적으로 응답 속도가 가장 느린 편이었다.
그 배경에는 JVM 부팅 시간, GC(Garbage Collection)과 같은 Java 특유의 런타임 환경 구조가 영향을 미친 것으로 보인다.
특히, 사용자 수가 많아지면서 동시에 채점 요청이 몰리는 상황에서는 Java의 성능 저하가 급격히 발생했다.
실제로 20명 이상의 사용자가 동시에 제출한 경우, 일부 요청에서는 응답 시간이 60초에 근접하는 현상도 관찰되었다.
2. Python의 예상 밖 우수한 응답
반면 Python은 테스트 전 예상보다 훨씬 더 안정적이고 빠른 응답을 보였다.
이유를 분석해보면, Python은 기본적으로 CPython 기반의 경량 실행 환경을 가지며, Java처럼 무거운 VM 부팅이나 GC가 없기 때문에 초기 실행이 빠른 것이라 예상된다.
3. 시스템 확장성 분석 지표로 활용 가능
이번 성능 테스트의 목적은 단순히 어떤 언어가 빠르냐를 측정하는 데에 그치지 않는다.
실제 운영 환경에서 발생할 수 있는 다양한 상황에 대해, 서버가 얼마나 확장성 있게 대응할 수 있는지를 확인하는 데 더 큰 의미가 있다.
사용자 수가 증가하거나 고성능 문제에 대한 제출이 많아질 경우, 어떤 언어가 병목을 유발할 수 있는지, 또는 어떤 방식으로 부하를 분산하면 가장 효율적인지를 사전에 예측할 수 있다.
결국 이번 테스트 결과는, 향후 서버 스펙 업그레이드나 실행 제한 정책 설계 등 운영 전략을 수립하는 데 있어 매우 중요한 참고 자료가 될 수 있다.
4. 실제 서비스 기준, 10명 이상 동시 제출 빈도는 낮음
실제 운영 중인 백준(BOJ) 등의 사례를 참고하면, 10명 이상의 동시 제출이 발생하는 빈도는 매우 낮다.
또한 모든 사용자가 동일한 언어(Java)로 제출하는 것도 아니기 때문에, 자바 기반 부하가 집중될 가능성 자체도 낮다.
따라서 이번 테스트 결과를 바탕으로 보면, 실제 서비스 환경에서는 충분히 여유 있는 구조로 볼 수 있다.
특히, 현재 시스템 구조에서는 4코어 또는 2코어 환경에서도 안정적으로 운영이 가능하다는 점에서, 서버 사양에 대한 가성비 최적화 측면에서도 긍정적인 신호로 해석된다.
5. WebClient Pool 한계 인식 및 해결
채점 로직에서는 하나의 제출에 대해 여러 개의 테스트케이스를 병렬로 처리하기 때문에, 내부적으로는 상당히 많은 HTTP 요청이 발생한다.
예를 들어 테스트케이스가 8개이고, 동시 제출 사용자 수가 20명이라면 단순 계산만 해도 160개의 HTTP 요청이 한꺼번에 발생하게 된다. 여기에 각 요청 결과를 Polling 방식으로 다시 가져오게 되면, 전체 커넥션 수는 최대 320개 이상으로 증가한다.
이 상황에서 WebClient의 커넥션 풀 크기가 부족하면, 커넥션 병목이나 타임아웃 등의 문제가 발생할 수 있고, 실제로 발생했다.
이 문제를 해결하기 위해, 내부적으로 비동기 작업을 실행하는 쓰레드 풀의 크기를 제한하고, 동시에 실행되는 요청 수를 제어하는 구조로 리팩토링했다.
6. DeadLock 문제 발견
정답 여부를 판단한 뒤, 해당 문제(Problem)의 제출 횟수, 정답 횟수를 갱신하는 로직이 존재하는데, 여러 쓰레드가 접근하는 과정에서 발생한 데드락(Deadlock) 문제였다.
동시성 이슈에 매우 민감한 지점이라는 것을 테스트 과정에서 발견하게 되었고, 현재는 해결을 한 상태다. 해결 과정은 이후 3차 고도화 글에서 더 구체적으로 다룰 예정이다.


정말 고생 많으셨습니다!
블로그 계속 작성하실 때 마다 꾸준히 보러 올게요