개요
이전 글에서 정리했던 기존의 채점 시스템은 동시 처리 부재로 여러 사용자를 동시에 처리하지 못하고 다중 제출 시 불필요한 서버 리소스 낭비와 일관된 결과 제공이 되지 않는 한계를 가지고 있었다.
2주간의 고도화 과정을 통해
- 비동기 병렬 처리로 여러 제출을 순차가 아닌 동시에 처리
- AI 코드 리뷰 프롬프트 정형화로 리뷰 일관성 확보
- 간단한 락으로 중복 채점 "따닥" 이슈 제어
등의 주요 개선을 적용했고, 실제로 짧은 시간 내에 4명 동시 제출까지 단일 서버에서 안정적으로 처리함을 확인했다.
이번 포스팅에서는 구현 과정과 거기서 마주한 이슈, 해결 방법을 정리하고 2차로 계획 중인 고도화 작업까지 기록해보려고 한다.
1. 비동기 병렬 처리
기존 채점 시스템은 다음과 같은 흐름을 따라 동작했다.
사용자 제출 요청 → 외부 컴파일 서버(Judge0)에 소스 코드 전송 → 컴파일 결과 수신 → 테스트케이스마다 채점 → SSE로 결과 전송 → 최종 채점 결과 저장 및 Final SSE 전송
하지만 이 전체 과정이 동기식(Synchronous)으로 처리되고, 내부적으로는 new Thread()로 직접 쓰레드를 생성해 채점 로직을 실행하고 있었기 때문에 다음과 같은 문제들이 발생했다.
-
요청 병목
하나의 요청이 끝나야 다음 요청이 처리되는 구조였기 때문에, 여러 사용자가 동시에 제출하면 응답 속도가 급격히 저하되었다. -
테스트케이스 순차 처리
하나의 제출이 여러 테스트케이스를 포함할 경우, 순차적으로 처리되어 전체 채점 시간이 길어졌다. -
스레드 폭주로 인한 서버 리스크
new Thread()방식으로 채점 쓰레드를 직접 생성하다 보니, 사용자가 많아지면 JVM 스레드 수가 기하급수적으로 증가하면서 OOM(Out Of Memory) 또는 서버 다운 위험이 있었다. 제어할 수 있는 장치가 없었다.
이런 구조에서는 실제 테스트 환경에서 단 2~3명의 사용자 동시 제출만으로도 전체 시스템 응답이 지연되는 현상이 나타났다.
이를 해결하기 위해 채점 시스템을 역할별로 분리하고, 각 단계를 비동기 & 병렬 처리 구조로 전환했다.
그 첫 단계로 도입한 것이 Executor 기반 스레드 풀 구성이다.
1.1. ExecutorConfig 기반 스레드 풀 설계
ThreadPoolTaskExecutor()를 이용해, 서로 다른 역할(메시지 소비, 제출 처리, 테스트케이스 처리)별로 별도의 스레드 풀을 정의했다.
이렇게 하면 각 작업 종류에 맞춘 동시성 제어가 가능하고, 하나의 풀에 부하가 몰려 전체 시스템이 정체되는 상황을 방지할 수 있다.
ExecutorConfig
@EnableAsync
@Configuration
public class ExecutorConfig {
@Bean(name = "consumerExecutor")
public Executor consumerExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(5);
executor.setMaxPoolSize(10);
executor.setQueueCapacity(100);
executor.setThreadNamePrefix("consumer-");
executor.initialize();
return executor;
}
@Bean(name = "judgeSubmissionExecutor")
public Executor judgeSubmissionExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(5);
executor.setMaxPoolSize(10);
executor.setQueueCapacity(100);
executor.setThreadNamePrefix("submission-");
executor.initialize();
return executor;
}
@Bean(name = "judgeTestcaseExecutor")
public Executor judgeTestcaseExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(25);
executor.setMaxPoolSize(50);
executor.setQueueCapacity(500);
executor.setThreadNamePrefix("testcase-");
executor.initialize();
return executor;
}
}@EnableAsync@Async어노테이션이 붙은 메서드를 별도의 스레드 풀에서 실행할 수 있도록 활성화
corePoolSize- 애플리케이션 시작 시 미리 생성해 대기시키는 기본 스레드 개수
maxPoolSize- 처리량이 급증할 때 확장 가능한 최대 스레드 수
queueCapacity- 스레드가 모두 사용 중일 때, 대기열에 버퍼링할 수 있는 작업 수
- 일정 수준까지만 대기열에 쌓이도록 제한
threadNamePrefix- 로그에 찍히는 스레드 이름 접두사
consumer-1,submission-3같은 이름으로 구분되어 디버깅, 모니터링에 유용
사용 예시
@Slf4j
@Service
@RequiredArgsConstructor
public class SubmissionService {
@Async("judgeSubmissionExecutor")
public void submitCodeStream(SubmissionMessage msg) {
// judgeSubmissionExecutor 풀에서 실행됨
}
}1.2. Redis Stream 도입
기존에는 사용자 제출 요청이 들어오면 애플리케이션이 즉시 채점 로직을 처리했다.
이 구조는 동기 처리 방식이었고, 다수 요청이 들어오면 순차적으로 밀리게 되어 전체 시스템이 쉽게 병목에 걸렸다.
이런 문제를 해결하고 추후에 확장 가능성을 고려해 Redis Stream을 도입하여 비동기 이벤트 기반 처리 구조로 전환했다.
Redis Stream은 Kafka처럼 메시지를 순서대로 쌓고, 컨슈머 그룹을 통해 메시지를 분산 처리할 수 있는 구조를 지원한다.
이를 통해 요청이 들어오면 Stream에 메시지를 발행(Publish) 하고, 비동기적으로 여러 스레드가 동시에 메시지를 소비(Consume) 하도록 만들었다.
메시지 발행 → judge-queue Stream → consumer 그룹 → 멀티 스레드 분산 처리 → 채점 로직 실행
적용 구조 요약
- Stream 이름:
judge-queue - Consumer Group:
judge-group - Consumer 수: 현재는 단일
- 메시지 내용:
SubmissionMessage(emitterKey, problemId, languageId, userId...)
RedisJudgeQueueConsumer
@Slf4j
@Component
@RequiredArgsConstructor
public class RedisJudgeQueueConsumer implements StreamListener<String, MapRecord<String, String, String>> {
private final SubmissionService submissionService;
private final StringRedisTemplate redisTemplate;
@Override
public void onMessage(MapRecord<String, String, String> message) {
Map<String, String> values = message.getValue();
SubmissionMessage msg = new SubmissionMessage(
values.get("emitterKey"),
Long.valueOf(values.get("problemId")),
Long.valueOf(values.get("languageId")),
Long.valueOf(values.get("userId")),
values.get("sourceCode")
);
try {
log.info("[컨슈머 수신] {}", msg.emitterKey());
submissionService.submitCodeStream(msg);
log.info("[컨슈머 ACK] messageId={}", message.getId());
redisTemplate.opsForStream().acknowledge("judge-group", message);
} catch (Exception e) {
log.error("채점 메시지 처리 실패: {}", message.getId(), e);
throw new SubmissionException(SubmissionExceptionCode.REDIS_SERVER_ERROR);
}
}이 RedisJudgeQueueConsumer는 consumerExecutor 스레드 풀에서 실행되며, 실제 채점 로직은 judgeSubmissionExecutor로 위임된다. 이렇게 계층적으로 스레드를 분산함으로써, 메시지 수신과 채점 실행의 책임을 분리했다.
하지만 여기서 해결해야할 문제점이 두 가지 있다.
1. ACK처리 시점 문제
현재는 submitCodeStream() 호출 이후, 콜백이나 실행 결과를 확인하지 않고 바로 ACK를 날리는 구조다. 이렇게 되면 내부에서 예외가 발생해도 Redis 입장에서는 "정상 처리됨"으로 간주되기 때문에, 재시도 메커니즘을 활용하지 못한다. Stream을 사용하는 의미가 퇴색되는 구조다.
추후 ACK 시점을 submitCodeStream()이 정상적으로 끝났을 때 명시적으로 호출하도록 개선이 필요하다.
2. SSE와 Redis Stream 구조의 충돌
테스트 도중 Redis Stream이 SSE 구조와 맞지 않다는 점을 명확히 깨달았다.
로컬 개발 환경에서는 팀원 모두 같은 코드를 실행하기 때문에, StreamMessageListenerContainer가 각자 등록되며, 같은 컨슈머 그룹 안에서 5개의 인스턴스가 메시지를 소비하게 된다.
이때 문제가 발생한다.
예를 들어 내가 제출한 코드에 대한 SSE 연결이 내 서버에 활성화되어 있어도, 다른 팀원의 리스너가 메시지를 가져가면, 그쪽에서는 submitCodeStream() 내부에서 SSE emitter를 찾지 못하고 예외가 발생한다.
즉, SSE가 연결된 인스턴스와 메시지를 소비하는 인스턴스가 일치하지 않을 수 있다는 점이 Redis Stream 구조와 치명적으로 맞지 않았다.
이 문제는 단순 로컬 개발뿐 아니라 서버 scale-out 상황에서도 마찬가지로 발생한다.
여러 서버 인스턴스가 컨슈머로 참여하게 되면, SSE emitter가 연결된 인스턴스와 관계없이 메시지가 소비되기 때문에, "SSE 연결된 서버가 메시지를 반드시 소비한다"는 전제가 깨진다.
물론 Redis Stream의 장점인 재시도를 활용할 수도 있지만, 이건 "운에 맡기는 구조"가 되어버리고, 시스템 신뢰도를 떨어뜨리게 된다.
이 문제 때문에 현재 구조에서는 Redis Stream의 장점을 온전히 사용하기 어렵다고 판단했고, SSE를 대체할 필요성을 느끼게 된 첫 번째 계기가 되었다.
1.3. Judge0 컴파일 서버 비동기 요청 확장
Redis Stream과 스레드 풀 기반 구조를 통해 요청 분산 및 비동기 분기까지는 가능해졌지만, 채점 시스템 내부에서는 여전히 병목이 존재했다. 바로 외부 컴파일 서버에 대한 API 호출 부분이 동기적으로 처리되고 있었다는 점이다.
- 사용자가 제출한 코드를 컴파일 서버로 전송
- 컴파일 결과가 오면 내부 채점 로직 수행 및 SSE로 응답 전송
이 모든 과정을 한 쓰레드에서 순차적으로 처리하면, 컴파일 서버 응답이 지연될 경우 전체 채점 흐름이 막히게 된다.
사용자 경험 측면에서 하나라도 빠르게 결과를 보여주는 것이 중요하다고 판단해 CompletableFuture.runAsync()와 ThreadPoolTaskExecutor를 직접 조합해 각 테스트케이스의 채점 로직을 완전히 분리된 스레드에서 병렬 실행하도록 개선했다.
runTestcaseAsync
private void runTestcaseAsync(
Testcase tc, SubmissionMessage msg, Long judge0Id,
ProblemInfo problemInfo, SubmissionContext context, SseEmitter emitter
) {
CompletableFuture.runAsync(() -> {
try {
log.info("[Judge RUN] Thread = {}", Thread.currentThread().getName());
// 1. Judge0 제출 및 응답 대기
String token = judgeClient.submitAndGetToken(
new CodeCompileRequest(msg.sourceCode(), judge0Id, tc.getInput())
);
JudgeResult result = judgeClient.pollUntilDone(token);
// 2. 평가 및 채점 통계 업데이트
AnswerEvaluation evaluation = submissionDomainService.handleEvaluationAndUpdateStats(
TestcaseEvaluationInput.from(tc, result), problemInfo, context
);
// 3. SSE로 전송
emitter.send(JudgeResultResponse.fromEvaluation(result, evaluation));
} catch (Exception e) {
// 예외 발생 시 최초 한 번만 처리
if (context.notified().compareAndSet(false, true)) {
emitter.completeWithError(e);
emitterStore.remove(msg.emitterKey());
exceptionNotificationHelper(e);
}
} finally {
context.countDown();
}
}, judgeTestcaseExecutor);
}이런 장점을 얻을 수 있었다.
- 테스트케이스별 채점이 완전 병렬화 → 전체 채점 속도 개선
- 각 채점 결과를 개별적으로 SSE 스트리밍 응답 가능
CountDownLatch로 모든 테스트케이스 완료 여부 체크 가능
이전 구조에서는 5개 테스트케이스가 순차적으로 채점되며 지연이 있었다면 이제는 동시에 컴파일 서버에 요청이 들어가고, 먼저 컴파일 결과가 반환되는 것부터 채점이 진행되어 사용자가 채점 사이사이 기다리는 시간이 줄어들었다.
1.4. 여전히 남은 병목 현상
앞서 개요에서 언급했듯이, 짧은 시간 내에 4명 동시 제출까지 안정적으로 처리되는 구조를 만들었다. 하지만 이 수치만 보고 "대단한 개선"이라고 보기는 어렵다.
실제로도 병렬 + 병렬 구조를 사용하면서 병목이 완전히 해결되리라 기대했지만, 드라마틱한 변화는 없었다.
그렇다면, 무엇이 병목을 발생시키고 있을까?
병목의 원인은 바로 Judge0 컴파일 서버의 물리 리소스였다.
Judge0는 비동기 요청을 받으면 내부 Redis 큐에 요청을 쌓고, worker가 이를 처리하는 구조를 가지고 있다.
이를 실제로 확인하기 위해 docker stats 명령어로 Judge0 컨테이너의 리소스 사용률을 모니터링했다.

당시 테스트는 아래와 같은 상황에서 진행되었다.
- 클라이언트 1, 2, 3이 각각 7개의 테스트케이스가 있는 문제를 제출 → 총 21개의 컴파일 요청
이때 관찰된 현상은,
judge0_server는 안정적이고 낮은 CPU 사용률을 유지judge0_worker는 CPU 사용률이 190~200%까지 치솟음
→ Redis 큐가 정상적으로 작동하며 worker가 병렬로 컴파일 요청을 처리 중이라는 뜻
여기서 중요한 사실 하나가 있다.
Judge0는 서버의 코어 수에 따라 worker 수가 결정되며, 병렬 처리 성능 역시 코어 수에 직접적으로 비례한다.
예를 들어 같은 21개의 요청을 처리할 때,
- 2코어 2 worker → worker당 10.5회 수행
- 4코어 4 worker → worker당 5.25회 수행
- 8코어 8 worker → worker당 2.625회 수행
즉, 병렬 처리 로직을 아무리 정교하게 짜도,
기저에 깔린 물리적 리소스가 병목이면 성능은 그 이상 올라가지 않는다.
현재 내가 사용하는 컴파일 서버는 2코어다.
이 상황에서 병렬 병렬 구조를 아무리 최적화하더라도, worker 자체가 감당해야 할 작업량이 많아 CPU 한계에 부딪힐 수밖에 없었다.
성능은 분명히 조금 향상되었지만, 채점 시스템의 로직 효율성을 온전히 평가하려면 최소한의 서버 사양이 먼저 받쳐줘야 한다는 점을 실감했다.
2. 트러블슈팅: 시큐리티 컨텍스트 전파 이슈
모든 채점 결과가 정상적으로 클라이언트에게 전달됐음에도 불구하고,
애플리케이션 로그에는 아래와 같은 예외가 반복적으로 남았다.


AccessDeniedException3건AlreadyCommittedException1건
이 로그들은 채점 결과 자체에는 전혀 영향을 주지 않았지만,
스택트레이스가 너무 길게 출력되면서 로그를 심각하게 오염시키는 문제가 있었다.
문제를 추적하기 위해 관련 키워드로 로그 분석과 검색을 반복한 끝에, Spring Security는 인증 정보를 SecurityContext라는 ThreadLocal 기반 객체에 저장하고 있으며,
이 SecurityContext는 기본적으로 비동기 스레드에 자동 전파되지 않는다는 점을 확인할 수 있었다.
결국 SecurityContext가 존재하지 않아서 생기는 문제였던 것이다.
2.1. 첫 번째 접근: DelegatingSecurityContextAsyncTaskExecutor
비동기 메서드에서 SecurityContext가 전파되지 않는 문제를 해결하기 위해 Spring에서 공식적으로 제공하는 방식 중 하나가 DelegatingSecurityContextAsyncTaskExecutor이다.
공식 문서와 여러 블로그에서,
"
@Async로 실행되는 메서드에 컨텍스트를 자동으로 전파하려면 이 Executor로 래핑해야 한다."
라고 설명하고 있어 아래와 같이 적용해봤다.
@Bean(name = "judgeSubmissionExecutor")
public Executor judgeSubmissionExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(5);
executor.setMaxPoolSize(10);
executor.setQueueCapacity(100);
executor.setThreadNamePrefix("submission-");
executor.initialize();
return new DelegatingSecurityContextAsyncTaskExecutor(executor);
}이제 이 Executor를 사용하는 비동기 메서드에서 SecurityContextHolder.getContext()를 호출하면 인증 정보가 담겨 있어야 정상이다.
하지만 실제 테스트 결과, @Async("judgeSubmissionExecutor")가 붙은 메서드 내부에서
SecurityContextHolder.getContext().getAuthentication()은 여전히 null로 출력되었다.
즉, 이 방식은 실패했다.
2.2. 두 번째 접근: SecurityContext 수동 전파
자, 다시 구조를 살펴보자.
처음에는 컨트롤러에서 다음과 같은 메서드가 호출된다.
public SseEmitter enqueueCodeSubmission(Long problemId, CodeSubmitRequest request, AuthUser authUser) {
// 큐에 담는 부분
return emitter;
}여기까지는 일반적인 Spring MVC의 로컬 스레드 흐름이다.
문제는 그 이후 Redis Stream을 거치면서 흐름이 완전히 바뀐다는 점이다.
전체 호출 흐름
enqueueCodeSubmission()→ 요청 수신 (로컬 스레드)- Redis Stream에 메시지 발행 → (외부 시스템)
- 컨슈머 리스너에서 메시지 수신 및 비동기 메서드 실행 → (별도 스레드 풀)
submitCodeStream()→ (별도 스레드 풀)
이제야 살짝 감이 잡히기 시작한다.
Spring에서 제공한 비동기 메서드 컨텍스트 전파는 기본적으로 "로컬 스레드 → 비동기 스레드" 간 흐름을 기준으로 동작한다.
하지만 여기는 외부 시스템(Redis) 을 경유한 완전히 분리된 실행 경로이기 때문에,DelegatingSecurityContextAsyncTaskExecutor를 사용해도 적용이 되지 않는 것이었다.
그래서 다음과 같은 대안을 생각했다.
"차라리 인증된 유저 정보를 메시지에 직접 담아서, 리스너 쪽에서 다시 Context를 구성하면 어떨까?"
실제로 userId, username, role, tier 등을 메시지에 포함시킨 뒤, 리스너에서 AuthUser를 다시 생성하고, 이를 기반으로 SecurityContextHolder.setContext(...) 를 수동으로 설정했다.
예상대로 SecurityContext 자체는 정상적으로 구성되었다.
하지만 여전히 동일한 예외가 발생해서,
"수동으로 만든 Authentication 객체가 이전과 다르니까, 내부적으로 equals() 비교에 실패해서 생기는 문제일 수도 있겠다."
라고 생각했다.
그런데 다시 생각해보니, 지금 발생하고 있는 예외는 "사용자가 일치하지 않는다"는 예외가 아니라, "인증 정보가 없다"는 예외였다. 그렇다면 유저 정보가 일치하지 않더라도, Context가 존재하기만 하면 에러는 발생하지 않아야 한다.
왜 Context를 분명히 구성했는데도, Spring Security는 그것을 "없다"라고 판단하는 것일까?
원인을 더 깊이 파고들기 시작했다.
2.3. SSE 스트리밍과 컨텍스트 충돌 원인 분석
앞선 2.2에서의 코드를 참고 해보면, SseEmitter 객체를 컨트롤러에서 즉시 반환하는 구조를 사용하고 있었다.
SseEmitter는 HTTP 연결을 유지하면서 서버가 클라이언트에게 데이터를 스트리밍으로 보내기 위해 사용하는 객체다. 컨트롤러에서 SseEmitter를 반환하면, 해당 HTTP 요청은 완료되지 않고 오랫동안 열려 있는 상태로 유지된다.
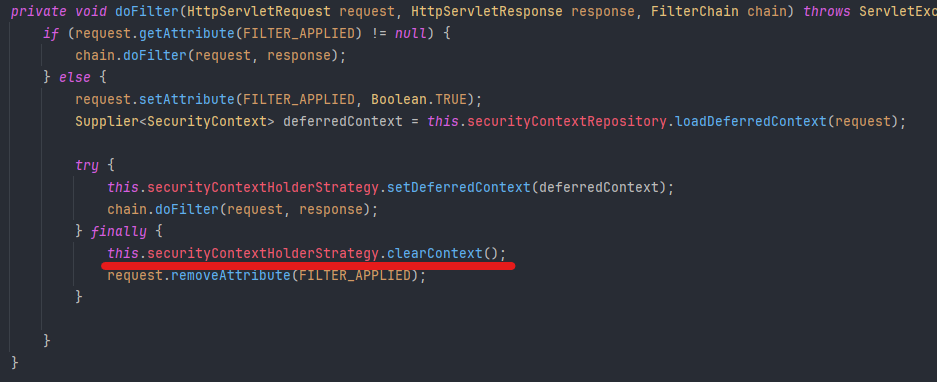
아래의 Spring Security의 핵심 필터 중 하나를 보면,
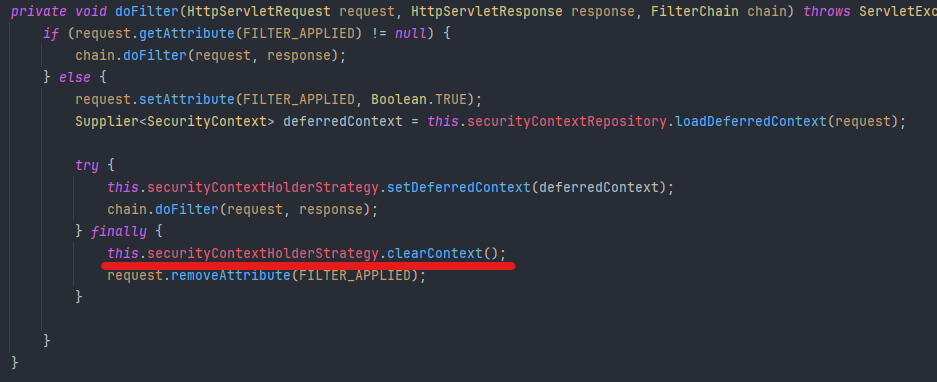
문제는 바로 finally 블록의 this.securityContextHolderStrategy.clearContext() 호출에 있었다.
이 구문은 HTTP 요청이 종료되는 시점에 SecurityContext를 초기화(제거) 하는 동작이며, 일반적인 요청-응답 처리에서는 문제가 없다.
그러나 현재 구조는 SseEmitter를 반환하면서 HTTP 연결을 끊지 않고 유지하는 구조인데, 컨트롤러에서 SseEmitter를 반환하는 순간에도 Spring Security는 해당 요청이 종료되었다고 판단하고 SecurityContext를 비워버린다.
결국 이 구조에서는 요청 스레드(Request Thread)가 종료됨과 동시에 SecurityContext도 함께 사라지게 되는 것이다.
이전 2.2의 비동기 메서드 안에서 수동으로 SecurityContext를 구성했지만, 문제는 서블릿 요청 스레드가 이미 종료되었기 때문에 Spring Security 관점에서는 "이미 SecurityContext는 클리어된 상태"가 된다.
Spring Security의 내부적인 설계 때문에 수동으로 SecurityContextHolder.setContext(...)를 해도, SseEmitter가 연결된 요청 스레드와 컨텍스트를 연결할 방법이 사라져버린 것이 근본적인 원인이었다.
2.4. 세 번째 접근: 인증 URL 범위 설정
다시 한 번 정리 해보자면,
SseEmitter는 클라이언트와 서버 간의 연결을 장시간 유지해야 하기 때문에, 일반적인 HTTP 요청과는 달리 컨트롤러가 종료되어도 응답 흐름이 살아 있는 구조다.
그러나 Spring Security는 컨트롤러가 SseEmitter를 반환한 순간, 요청 처리가 끝났다고 판단하여 필터 체인의 clearContext()를 통해 SecurityContext를 비워버린다.
그 결과, 이후 실행되는 모든 비동기 로직은 이미 비워진 SecurityContext 상태에서 실행되며, 이때 SseEmitter.send()나 complete() 등이 서블릿 응답을 한 번 더 커밋하려고 하면, Spring Security는 이를 인증되지 않은 요청으로 간주하여 AccessDeniedException을 발생시킨다.
이미 응답이 커밋된 상태에서의 응답 시도는 AlreadyCommittedException까지 유발한다.
이 문제는 결국 "비동기 흐름에서 Security를 무시할 수 있게 설정하는 방식"으로 해결 가능했다. Spring Security의 설정에 다음 구문을 추가했다.
.requestMatchers(new DispatcherTypeRequestMatcher(DispatcherType.ASYNC)).permitAll()이 설정은 DispatcherType이 ASYNC인 요청 (즉, 비동기 서블릿 흐름으로 전환된 요청)을 인증 없이 모두 허용하겠다는 의미다. 이를 통해 SecurityContext가 초기화되었더라도 추가적인 인증 예외가 발생하지 않도록 방지할 수 있다.
즉, 비동기 흐름 안에서는 인증을 검사하지 않도록 우회함으로써, 이 문제를 해결할 수 있었다.
이번 이슈를 통해 단순한 컨텍스트 전파 문제로 보였던 오류가, 사실은 Spring Security와 SSE 구조 간의 근본적인 설계 충돌에서 비롯되었음을 알 수 있었다.
이는 단순한 설정의 문제가 아닌, "SSE를 사용하는 설계가 인증 보안과 충돌할 수 있음"을 체감하게 한 사례였다.
앞선 Redis Stream에서의 구조적 한계에 이어, 이번 SSE와 Spring Security의 충돌 문제까지 경험하며 확신할 수 있었다.
SSE는 본질적으로 단일 인스턴스 환경에 적합한 구조이며, 확장성과 인증 흐름 보장을 동시에 요구하는 분산 아키텍처로의 확장을 고려하면 대체가 불가피하다는 것이다.
아직 완전한 구조 전환을 이루진 않았지만, WebSocket 또는 Polling 기반으로의 전환 필요성은 분명해졌으며, 이후 고도화 작업의 핵심 방향으로 고려되고 있다.
3. AI 코드 리뷰 프롬프트 정형화
MVP 단계에서 급하게 만들어둔 코드 리뷰 기능은 실행할 때마다 출력 포맷도 들쭉날쭉하고, 일관성 없는 답변이 나오는 문제가 있었다.
가장 큰 이유는 프롬프트 구조가 정형화되어 있지 않았고, 모델이 스스로 정답 여부를 판단하려 들기도 했기 때문이다.
이번 고도화 작업에서는 다음 세 가지 원칙을 중심으로 프롬프트를 정비했다.
- 절대 코드의 일부분을 출력하지 말 것
- 정오답 여부는 모델이 판단하지 않도록 할 것 (→ 채점 결과 기반)
- 리뷰는 반드시 지정한 템플릿에 맞게 출력할 것
3.1. 프롬프트 템플릿 구조 설계
우선 시스템 프롬프트와 유저 프롬프트를 명확히 분리했다.
- 시스템 프롬프트는 AI에게 리뷰 기준, 출력 형식 등을 지정하는 설정 역할
- 유저 프롬프트는 실제 코드, 문제 설명, 언어 정보 등을 포함하는 질의
유저 프롬프트
private String buildUserPrompt(ReviewPayload request) {
return "문제: "
+ request.problemDescription()
+ "\n"
+ "언어: "
+ request.languageName()
+ "\n"
+ "정답 여부: "
+ (request.isCorrect() ? "정답" : "오답")
+ "\n"
+ "```"
+ request.languageName().toLowerCase()
+ "\n"
+ request.sourceCode() + "```";
}시스템 프롬프트
private String buildSystemPrompt(boolean isCorrect) {
String body;
if (isCorrect) {
body = """
<정답일 경우>
- 시간 복잡도: Big-O 표기법으로만 답하세요. **단, N과 M을 같다고 가정하고 n으로 표기하세요.**
- 코드에 포함된 중첩 루프(depth)에 따라 O(N^k) 형태로 정확히 표기해주세요.
**for 루프뿐만 아니라 while 루프도 모두 중첩(depth)에 포함**하여, 코드에 실제로 있는 루프 개수만큼 exponent를 세십시오.
예) for-for-for ⇒ O(n³), for-for-while ⇒ O(n³), for-for-for-for-while ⇒ O(n⁵)
- 코드 총평:
각 문장은 한 탭(\t) 들여쓰기 + '- ' 로 시작.
문장 끝에만 마침표를 붙이세요.
- 조금 더 개선할 수 있는 방안:
각 문장은 한 탭(\t) 들여쓰기 + '- ' 로 시작.
문장 끝에만 마침표를 붙이세요.
""".stripIndent();
} else {
body = """
<오답일 경우>
코드 총평:
각 문장은 한 탭(\t) 들여쓰기 + '- ' 로 시작.
문장 끝에만 마침표를 붙이세요.
- 공부하면 좋은 키워드:
1. 첫 번째 키워드
2. 두 번째 키워드
3. 세 번째 키워드
… 필요한 만큼 번호를 늘려주세요.
""".stripIndent();
}
return PREFIX + "\n" + body + "\n" + SUFFIX;
}이외에도 추가적으로 붙는 시스템 지시 프롬프트는 있지만, 내용이 길어져 생략한다.
참고로, 처음에는
StringBuilder를 써야 하나 고민했지만
Java 버전이 올라가면서 문자열+연결은 내부적으로StringBuilder로 최적화되고,
텍스트 블록(""") 사용 시 불필요한 공백 문자도 제거되어 오히려 더 효율적이라는 점을 확인했다.
3.2. AI 응답 포맷 검증 및 재시도 처리
AI 리뷰 응답은 항상 동일한 템플릿 구조로 출력되어야 한다.
하지만 AI는 때때로 엉뚱한 응답을 하기도 하고, 우리가 기대한 형식이 아닌 경우가 많았다.
이에 따라 프롬프트 응답이 명확한 기준을 만족하지 않을 경우, 최대 3회까지 재요청한 뒤,
끝내 실패할 경우 사용자에게는 오류 메시지를 전송하고 트랜잭션을 롤백하도록 처리했다.
만약 AI 서버 자체가 응답을 보내지 못하는 장애 상황에서는, 아래 6. 서버 장애 예외 처리 및 대응 전략에서 설명할
Retry정책이 함께 적용된다.
응답 포맷 검증 코드
@Component
class OpenAIResponseValidator {
protected boolean isValidFormat(String content, boolean isCorrect) {
if (content == null)
return false;
if (isCorrect) {
return content.contains("시간 복잡도:") &&
content.contains("코드 총평:") &&
content.contains("조금 더 개선할 수 있는 방안:");
}
return content.contains("코드 총평:") &&
content.contains("공부하면 좋은 키워드:");
}
}전체 흐름
@Override
public ReviewResult requestReview(ReviewPayload reviewPayload) {
Map<String, Object> requestBody = openAiMessageBuilder.buildRequestBody(reviewPayload);
String content;
int maxAttempts = 3;
for (int attempt = 1; attempt <= maxAttempts; attempt++) {
try {
content = callChatApi(requestBody);
} catch (CodeReviewException e) {
log.error("OpenAI API 호출 실패: {}, {}", e.getHttpStatus(), e.getMessage());
TransactionAspectSupport.currentTransactionStatus().setRollbackOnly();
return new ReviewResult(openAiMessageBuilder.buildErrorMessage());
}
if (openAiResponseValidator.isValidFormat(content, reviewPayload.isCorrect())) {
return new ReviewResult(content);
}
log.warn("[{}/{}][isCorrect={}] 포맷 검증 실패:\n{}", attempt, maxAttempts, reviewPayload.isCorrect(), content);
}
// 최종 실패
TransactionAspectSupport.currentTransactionStatus().setRollbackOnly();
return new ReviewResult(openAiMessageBuilder.buildErrorMessage());
}실패 시 반환 메시지
protected String buildErrorMessage() {
return "현재 리뷰 생성에 일시적인 문제가 발생했습니다. 잠시 후 다시 시도해 주세요.";
}이 과정을 통해 모델이 임의로 형식을 깨뜨리거나 잘못된 응답을 주더라도, 사용자에게는 안정적인 출력만 전달되도록 방어 로직을 갖추었다.
아래는 실제 로그에서 확인된 AI 응답의 포맷 검증 실패 예시이다.
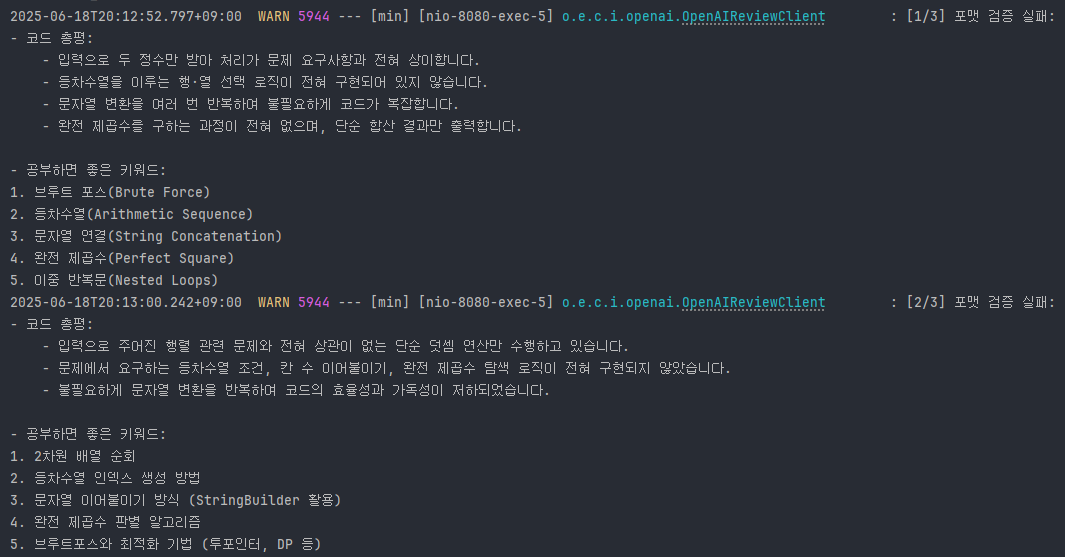
사용자는 아래와 같이 통일된 템플릿 구조로 AI 리뷰 결과를 확인할 수 있다.

3.3. setRollbackOnly()를 활용한 트랜잭션 제어 전략
바로 다음 장에서 얘기할 토큰 부여 시나리오에 관련한 얘기인데, 코드가 나온 김에 살짝 얘기하고 넘어가려고 한다.
OpenAI API 호출이 실패하거나, AI 응답 포맷이 유효하지 않을 경우에는 전체 트랜잭션을 롤백시키도록 setRollbackOnly()를 사용했다.
이 트랜잭션은 사용자 리뷰 토큰 차감과 연관되기 때문에, AI 응답이 실패했음에도 불구하고 토큰이 차감되는 부작용을 막는 것이 목적이다.
@Transactional
@CodeReviewLock(prefix = "review")
public CodeReviewResponse getCodeReview(Long problemId, CodeReviewRequest request, AuthUser authUser) {
User user = userDomainService.getUserById(authUser.getId());
userDomainService.decreaseReviewToken(user);
Problem problem = problemDomainService.getProblem(problemId);
Language language = languageDomainService.getLanguage(request.languageId());
ReviewResult reviewResult = reviewClient.requestReview(ReviewPayload.of(problem, language, request));
// userDomainService.decreaseReviewToken(user); < 여기다 하면 안 되나?
return new CodeReviewResponse(reviewResult.reviewContent());
}"토큰 차감을 아래에 두면 setRollbackOnly() 필요가 없지 않나"라고 생각할 수 있다.
하지만 이 구조는 사실상 "OpenAI 서버가 장애일 확률"과 "토큰이 부족할 확률" 중 어떤 쪽이 높은가"를 기준으로 생각한 것이다.
유저의 리뷰 토큰 부족은 자주 발생하지만, OpenAI 서버 장애는 드물다.
따라서 토큰 차감을 가장 먼저 실행하고, 그 이후 단계에서 문제가 발생하면 setRollbackOnly()를 호출해 전체 트랜잭션을 명시적으로 롤백하도록 설계했다.
이 방식이 실제 운영 환경에서의 리소스 낭비를 최소화하는 데 더 유리하다고 판단했다.
4. 리뷰 요청 토큰 부여 시나리오
OpenAI API는 사용량 기반으로 비용이 청구되는 구조다.
AI 코드 리뷰는 사용자 입장에선 클릭 한 번으로 편하게 실행할 수 있지만, 요청이 많아질수록 서비스 운영 비용이 기하급수적으로 증가한다.
현재는 별도의 수익 구조 없이 MVP 기능을 제공 중이기 때문에, 무제한 요청을 허용하기엔 감당할 수 없는 수준의 비용 문제가 발생할 수 있다.
이에 따라 모든 사용자에게 리뷰 요청 토큰 개수를 제한하는 정책을 도입했다.
4.1. 주간 토큰 지급 조건
리뷰 토큰은 매주 월요일 00시에 자동으로 지급된다.
다만, 무조건 동일한 수량을 지급하는 것이 아니라, 사용자의 지난 일주일간 학습 활동을 기준으로 토큰 수량이 달라진다.
- 일주일 내내, 즉 월요일부터 일요일까지 매일 최소 1문제 이상 문제 풀이 기록이 있는 사용자는 다음 주에 리뷰 토큰 40개를 받는다.
- 반면, 하루라도 문제 풀이 기록이 없는 날이 있었다면 다음 주에는 리뷰 토큰 20개만 지급된다.
이렇게 설계한 이유는 단순한 사용 제한을 넘어서, 꾸준한 학습 습관을 형성할 수 있도록 유도하기 위함이다. 사용자는 매일 최소 한 문제만 풀어도 더 많은 리뷰 혜택을 받을 수 있기 때문에, 자연스럽게 학습 동기를 유도할 수 있는 구조가 될 수 있다.
4.2. 리뷰 토큰 지급을 위한 스케줄러 설계
리뷰 토큰은 매주 월요일 00시, 전 주의 학습 활동을 기반으로 일괄 지급된다.
이 기능은 WeeklyTokenResetScheduler 클래스에 구현된 스케줄러에서 실행된다.
CronTrigger trigger = new CronTrigger(
"0 0 0 * * MON",
TimeZone.getTimeZone("Asia/Seoul")
);이 트리거는 서울 시간대 기준으로 매주 월요일 자정에 동작하며,
그 주 월요일~일요일(7일간)의 기록을 기준으로 토큰 지급 여부를 결정한다.
예를 들어, 6월 17일(월)에 실행되는 스케줄러는 6월 10일(월)부터 6월 16일(일)까지의 기록을 분석하여 토큰을 지급한다.
이때 고려되는 조건은 다음과 같다.
- 오직
testcase_passed_count == testcase_total_count인 제출만 인정된다. - 즉, 정답으로 채점된 문제만 학습 기록으로 간주한다.
스케줄러 내부에서는 UserService.resetAllUsersTokensWeekly()를 호출해 토큰 로직을 수행하고, 기간 계산은 다음과 같이 안전하게 처리한다.
LocalDate lastMonday = LocalDate.now(ZoneId.of("Asia/Seoul"))
.with(TemporalAdjusters.previousOrSame(DayOfWeek.MONDAY));
LocalDateTime startDateTime = lastMonday.atStartOfDay();
LocalDateTime endDateTime = lastMonday.plusDays(7).atStartOfDay();4.3. QueryDSL + Bulk Update로 DB I/O 최소화
유저 수가 많아질수록 매 사용자마다 DB를 개별적으로 읽고 쓰는 구조는 I/O 병목의 가장 큰 원인이 된다. 단순히 수천 건의 업데이트라도 트랜잭션 내에서 순차적으로 처리되면, 데이터베이스 입장에서는 수천 번의 I/O 요청을 처리해야 하는 상황이 된다.
따라서 이번 구조에서는 애초에 필요한 데이터를 한 번에 계산하고, 단 2번의 Bulk Update만으로 처리하는 전략을 선택했다.
QueryDSL
주간 토큰 지급 로직에서는 유저가 일주일 동안 하루도 빠짐없이 문제를 풀었는지를 판단하기 위해, Submission 테이블에서 정답 제출 기록을 기준으로 분석한다.
QSubmission s = QSubmission.submission;
var dateOnly = Expressions.dateTemplate(
java.sql.Date.class, "function('date',{0})", s.createdAt
);
var cntExpr = dateOnly.countDistinct();위와 같이 submission.createdAt 컬럼에 date() 함수를 적용하여 시간 정보를 제거한 날짜 기준으로 처리하고, countDistinct()를 사용해 유저별로 정답 제출이 있었던 날짜의 수를 계산한다.
return jpaQueryFactory
.select(constructor(
WeeklySolveCount.class,
s.user.id,
cntExpr
))
.from(s)
.where(
s.createdAt.goe(startDateTime),
s.createdAt.lt(endDateTime),
s.testCasePassedCount.eq(s.testCaseTotalCount)
)
.groupBy(s.user.id)
.fetch();여기서 중요한 점은 단순한 제출 기록이 아닌, 테스트케이스를 모두 통과한 정답 제출만을 기준으로 집계한다는 것이다. 오답 제출만 있던 날은 인정되지 않으며, 정답 제출이 한 건이라도 있었던 날짜만 유효 날짜로 간주된다.
이렇게 해서, 단 한 번의 쿼리로 각 유저가 일주일 동안 며칠간 정답을 제출했는지를 계산할 수 있게 된다.
Bulk Update
이전 단계에서 QueryDSL을 통해 각 사용자별로 정답 제출이 있었던 날짜 수를 구했다면, 이제 이 정보를 활용해 리뷰 토큰 지급 대상자를 분류하고 일괄적으로 DB 업데이트를 수행해야 한다.
우선 WeeklySolveCount 리스트를 기반으로, 사용자들을 아래와 같이 두 그룹으로 나눈다.
- 일주일 동안 매일 정답을 제출한 사용자
- 하루라도 빠진 사용자
public static UsersByWeek from(List<WeeklySolveCount> counts, long weekLength) {
List<Long> fullWeek = counts.stream()
.filter(c -> c.solveDayCount() == weekLength)
.map(WeeklySolveCount::userId)
.toList();
List<Long> partialWeek = counts.stream()
.filter(c -> c.solveDayCount() != weekLength)
.map(WeeklySolveCount::userId)
.toList();
return new UsersByWeek(fullWeek, partialWeek);
}이렇게 분류된 사용자 ID 리스트를 가지고, 다음과 같이 두 번의 Bulk Update를 수행한다.
public void resetReviewTokensForUsers(UsersByWeek users) {
userRepository.updateReviewTokens(users.fullWeek(), 40);
userRepository.updateReviewTokens(users.partialWeek(), 20);
}이 방식은 전체 사용자의 토큰 초기화를 단 2개의 쿼리로 처리할 수 있기 때문에, 데이터베이스 자원을 효율적으로 사용하면서도 안정적으로 주간 토큰 리셋 작업을 완료할 수 있다.
5. 동시성 문제, "따닥" 이슈 처리
테스트 도중, 코드 제출 버튼을 빠르게 두 번 클릭했을 때 동일한 코드가 두 번 제출되는 현상이 발생했다. 소위 "따닥 이슈"라고 불리는 현상이다.
이는 실제 사용자와 서버에 다음과 같은 문제를 일으킨다.
- 동일한 코드가 중복으로 채점되며 서버 리소스를 이중 소비
- 리뷰 토큰이 두 번 소모되거나, 시스템에 불필요한 중복 데이터가 저장
- 응답 지연 시 사용자가 다시 클릭할 수밖에 없는 UI 흐름과 맞물려 결과가 이중으로 수신
이런 문제를 해결하기 위해 서버 측에서 간단한 락 처리를 도입했고, 이후에는 AOP로 추상화하여 동기 메서드에는 AOP를 사용한 락을 적용할 수 있는 구조로 개선했다.
5.1. Redis 기반 간단 락 구현
Component
@RequiredArgsConstructor
public class RedisLockManager implements LockManager {
private final StringRedisTemplate redisTemplate;
private static final String LOCK_KEY_FORMAT = "%s-lock:user:%d:problem:%d";
private static final Duration LOCK_DURATION = Duration.ofMinutes(5);
@Override
public boolean tryLock(String prefix, Long userId, Long problemId) {
String key = getKey(prefix, userId, problemId);
Boolean success = redisTemplate.opsForValue().setIfAbsent(key, "LOCKED", LOCK_DURATION);
return Boolean.TRUE.equals(success);
}
@Override
public void releaseLock(String prefix, Long userId, Long problemId) {
redisTemplate.delete(getKey(prefix, userId, problemId));
}
private String getKey(String prefix, Long userId, Long problemId) {
return LOCK_KEY_FORMAT.formatted(prefix, userId, problemId);
}
}해당 구조는 Redis의 SETNX (set if not exists) 명령어를 활용하여, 같은 유저가 동일한 문제에 대해 중복 요청을 보내는 경우 첫 요청만 처리되도록 제어하는 방식이다.
Redisson이나 Redlock 같은 복잡한 분산락 프레임워크를 사용하지 않은 이유는 다음과 같다.
-
락의 정합성이 완벽하지 않아도 되는 상황이다.
채점 요청이나 리뷰 요청이 중복되더라도 시스템 전체에 치명적인 부작용은 없다.
-
비교적 가벼운 로직이며, 락 점유 시간이 매우 짧다.
별도의 Watchdog, LeaseTime 등을 관리할 필요 없이 단순 TTL 기반 락으로 충분하다.
-
Redisson은 스레드 풀을 다르게 설정한 환경에서는 락이 전파되지 않는 이슈가 있다.
실제로
@Async나 TaskExecutor로 동작하는 비동기 로직에서는 동일한 Redisson 객체를 공유하지 않아 락 충돌이 발생하지 않는 경우가 있다.
따라서 단일 Redis 인스턴스를 기준으로 Key 기반으로만 처리하는 것이 더 명확하고 안정적인 선택이 될 수 있다고 판단했다.
Redisson 공식 문서: Locks and synchronizers
또한 이 락 구조는 prefix를 받아 사용하므로, 채점 요청(submission)과 코드 리뷰 요청(review) 등 락의 사용 목적에 따라 Key를 구분할 수 있는 유연함도 갖추고 있다.
submission-lock:user:{userId}:problem:{problemId}
review-lock:user:{userId}:problem:{problemId}
이후 AOP를 통해 이 락을 공통 관심사로 추상화하면, 서비스 코드에서는 락을 직접 다루지 않고 선언적으로 적용할 수 있다.
5.2. AOP 추상화를 통한 락 적용
Redis를 기반으로 락을 직접 거는 구조는 간단하지만, 채점 요청 또는 코드 리뷰 요청마다
tryLock() releaseLock()을 일일이 작성하게 되면 비즈니스 로직과 락 처리 로직이 얽히게 된다.
그래서 AOP(Aspect-Oriented Programming) 를 활용해 "선언적으로 락을 걸 수 있는 구조" 를 설계했다. 락을 걸고 싶은 메서드에 어노테이션만 붙이면 내부에서 자동으로 락을 시도하고 해제하도록 추상화한 것이다.
@Aspect
@Component
@RequiredArgsConstructor
@Order(Ordered.HIGHEST_PRECEDENCE)
public class CodeReviewLockAspect {
private final LockManager lockManager;
@Around("@annotation(org.ezcode.codetest.application.submission.aop.CodeReviewLock)")
public Object lock(ProceedingJoinPoint joinPoint) throws Throwable {
MethodSignature signature = (MethodSignature)joinPoint.getSignature();
String prefix = signature.getMethod().getAnnotation(CodeReviewLock.class).prefix();
Object[] args = joinPoint.getArgs();
Long problemId = null;
Long userId = null;
for (Object arg : args) {
if (arg instanceof Long) {
problemId = (Long)arg;
} else if (arg instanceof AuthUser) {
userId = ((AuthUser)arg).getId();
}
}
if (problemId == null || userId == null) {
throw new CodeReviewException(CodeReviewExceptionCode.REQUIRED_ARGS_NOT_FOUND);
}
boolean locked = lockManager.tryLock(prefix, userId, problemId);
if (!locked) {
throw new CodeReviewException(CodeReviewExceptionCode.ALREADY_REVIEWING);
}
try {
return joinPoint.proceed();
} finally {
lockManager.releaseLock(prefix, userId, problemId);
}
}
}@CodeReviewLock라는 커스텀 어노테이션만 붙이면 해당 메서드에 락이 자동으로 적용된다.prefix는 락의 용도 구분을 위해 사용되며, 락 키는"review-lock:user:{userId}:problem:{problemId}"형태로 구성된다.- 메서드 인자 중에서
AuthUser와Long타입을 찾아userId,problemId를 추출한다.
왜 채점 요청에는 AOP를 적용하지 않았을까?
채점 요청 로직은 Redis Stream 기반으로 큐에 메시지를 보내고, 수신 Consumer에서 비동기적으로 채점을 진행하는 구조를 가지고 있다.
즉, 요청을 보내는 메서드와 실제 로직을 실행하는 메서드가 스레드, 실행 시점 모두 다르기 때문에 AOP로 묶어서 처리하기 어려운 구조이다.
반면 코드 리뷰는 단일 스레드에서 동기적으로 진행되기 때문에 AOP 방식이 적합했다.
6. 서버 장애 예외 처리 및 대응 전략
코드 리뷰나 채점 요청은 외부 서버(OpenAI, 채점 서버 등)와의 통신을 기반으로 작동하기 때문에, 네트워크 지연이나 서버 다운과 같은 외부 장애가 발생할 경우 사용자 경험에 영향을 줄 수 있다.
특히 채점 시스템은 Redis Stream 기반의 비동기 큐 처리 구조로 되어 있기 때문에, 예외 발생 시 운영자가 즉시 인지하고 대응할 수 있는 체계가 필요하다.
6.1. 장애 유형별 대응 전략 (타임아웃, 서버 다운)
HTTP 요청은 네트워크 불안정, 서버 다운, 응답 지연 등 여러 원인으로 실패할 수 있다.
HTTP 통신에서 발생 가능한 대표적인 장애는 다음과 같다.
TimeoutException→ 일정 시간 동안 응답이 없을 때 발생WebClientResponseException→ 서버가 4xx/5xx 응답을 반환했을 때 발생
이러한 장애를 구분하고 상황별로 처리하기 위해 Retry와 onErrorMap을 사용하여 다음과 같이 구성했다.
.retryWhen(
Retry.backoff(3, Duration.ofSeconds(1))
.maxBackoff(Duration.ofSeconds(5))
.filter(ex -> ex instanceof WebClientResponseException
|| ex instanceof TimeoutException)
.onRetryExhaustedThrow((spec, signal) -> signal.failure())
)
.onErrorMap(WebClientResponseException.class,
ex -> new CodeReviewException(CodeReviewExceptionCode.REVIEW_SERVER_ERROR))
.onErrorMap(TimeoutException.class,
ex -> new CodeReviewException(CodeReviewExceptionCode.REVIEW_TIMEOUT))- 최대 3회까지 재시도를 수행하고, 중간에 응답이 오면 즉시 종료된다.
- 반복 실패 시에는 원인에 따라 커스텀 예외를 발생시켜 이후 처리 흐름에서 활용한다.
이렇게 분리된 예외는 내부 로깅 또는 알림 시스템에서 구체적인 원인 파악에 활용된다.
6.2. 장애 발생 시 실시간 알림 처리
채점이나 코드 리뷰 요청 과정에서 장애가 발생하더라도, 사용자에게는 "요청이 실패했다"는 결과만 알려주고, 그 상세한 원인을 노출할 필요는 없다.
예외 메시지나 서버 상태 같은 내부 시스템 정보는 보안 및 사용자 경험(UX) 측면에서 숨기는 것이 더 바람직하다.
대신, 백엔드에서 어떤 문제가 발생했는지를 운영자가 실시간으로 인지할 수 있어야 한다.
이를 위해 Discord 웹훅 기반의 서버 알림 시스템을 도입했다.
채점 중 예외가 발생하면, 다음과 같이 알림이 전송된다.
exceptionNotifier.sendEmbed(
"채점 예외",
"채점 중 SubmissionException 발생",
"""
• 성공 여부: %s
• 상태코드: %s
• 메시지: %s
""".formatted(code.isSuccess(), code.getStatus(), code.getMessage()),
"submitCodeStream"
);- 알림은
Discord Embed형태로 발송되며, 예외 메시지, 메서드명, 발생 시각 등의 정보를 함께 담아 문제 추적에 활용할 수 있다.
Slack등의 대안도 존재하지만, 현재 팀 상황이나 채점 시스템 담당인 내 입장에서는 Discord 채널이 가장 빠르고 즉각적인 커뮤니케이션 수단이었기 때문에 선택했다.
실제 알림 예시 (Discord Embed)
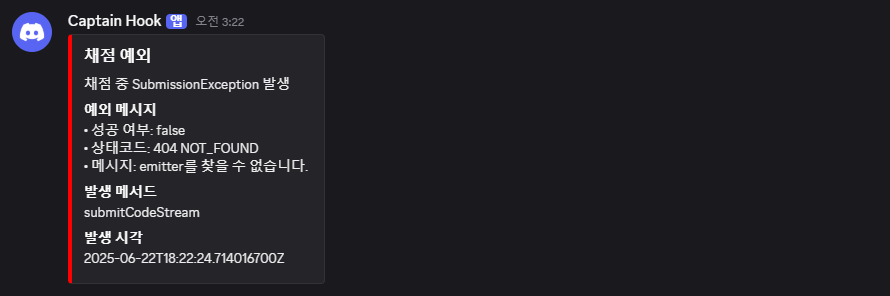
위 메시지는"emitter를 찾을 수 없습니다." 라는 예외가 발생했을 때 Discord로 전송된 실제 알림이다. 운영자는 이 알림을 통해 실시간으로 이슈를 인지하고, 빠르게 복구나 조치를 수행할 수 있다.
참고로, 이 알림을 통해 SSE와 Redis Stream 간의 구조적 충돌 가능성을 인지하게 되었다.
7. 다음 고도화 계획
지금까지 SSE 기반의 채점 시스템, 분산 락 처리, 장애 대응 체계 등 다양한 기능들을 구현하며 안정적인 서비스 기반을 마련했다. 하지만 실제 테스트 과정에서 발견된 한계점과 더 나은 사용자 경험을 위해 다음과 같은 고도화를 계획하고 있다.
7.1. SSE 대체 방안 (WebSocket 또는 Polling 검토)
현재 채점 결과는 Server-Sent Events(SSE)를 이용해 스트리밍 방식으로 전달하고 있다.
하지만 앞서 설명했던 SSE와 Redis Stream 간의 구조적 충돌과 시큐리티 컨텍스트 전파 문제로 인해 SSE를 대체할 수 있는 통신 방식에 대한 검토가 필요해졌다.
-
WebSocket
- 양방향 통신이 가능하고, 메시지 기반 구조에 적합
- 클라이언트가
subscribe()만 해두면, 서버는 각 테스트케이스의 결과를 완료되는 즉시 실시간 푸시 가능 - 인증 처리 구조에 대한 보완은 필요하지만, 성능, 실시간성, 확장성 측면에서 강점
-
Polling
- SSE나 WebSocket 대비 구현이 단순하고, 브라우저 호환성이 뛰어남
- REST API 기반 주기적 조회(GET) 방식으로 서버 제어가 쉬움
- 하지만 채점 결과가 바뀌지 않아도 계속 요청이 발생하고, 실시간성이 떨어지는 한계가 있음
현재 SSE 구조에서도 각 테스트케이스 결과를 서버에서 클라이언트로 개별 전송하는 방식은 구현돼 있다. 하지만 클라이언트는 이를 단순히 순차적으로 수신만 할 뿐, 개별 테스트케이스의 상태를 실시간으로 UI에 반영하지는 않는 구조다.
이에 따라, 앞서 제기된 구조적 문제를 해결하는 동시에, 테스트케이스별 채점 결과를 UI에 동적으로 반영하고, 사용자가 실시간으로 처리 상태를 확인할 수 있는 구조로 확장하기 위해 WebSocket 기반 구조로의 전환을 적극 검토하고 있다.
7.2. GitHub 자동 푸시 연동 기능
내가 예전에 포스팅한 BaekjoonHub를 사용해 본 사람이라면, 문제 풀이가 정답 처리되었을 때 자동으로 GitHub 활동에 기록되는 것이 얼마나 편리한지 알 것이다.
그와 유사한 방식으로, 현재 서비스 내에서도 문제 풀이 결과를 GitHub에 자동 커밋/푸시할 수 있도록 기능 구현을 계획 중이다.
계획 중인 기능 흐름
- 사용자가 GitHub 계정을 연동하면,
GitHub OAuth를 통해 토큰 저장 - 문제 제출 시, 소스코드와 채점 결과를 기반으로 Markdown 형식의
.md또는.java파일 생성 GitHub API를 이용해 해당 파일을 사용자의 저장소에 자동 커밋 및 푸시
고려 중인 이슈
- GitHub 토큰 암호화 저장 및 관리
- OAuth 연결 해제 시, 연동 해제 및 토큰 폐기 처리
- 사용자가 푸시 기능을 직접 ON/OFF할 수 있도록 옵션 제공
- 커밋/푸시 실패 시 재처리 또는 사용자 알림 방식
이 기능을 통해, 사용자는 자신의 문제 풀이 기록을 손쉽게 GitHub에 관리할 수 있게 되며, 이후 포트폴리오나 학습 이력 관리에도 활용할 수 있을 것으로 기대하고 있다.
