개요
이번 프로젝트의 목표는 팀원 모두가 새로운 기술과 도메인에 도전해볼 수 있는 서비스 개발이었다.
여러 아이디어를 논의한 끝에, 코딩 테스트 사이트를 최종 주제로 선정하게 되었다.
이 주제는 대부분의 개발자에게 익숙한 서비스이기 때문에, 핵심 기능(MVP)을 빠르게 정의할 수 있었고, 실무에서 자주 사용되는 기술 스택과 설계 방식을 적용해보기에도 적절했다.
무엇보다도 주변 지인들을 통해 사용자 테스트가 용이하고, 프로젝트 종료 이후에도 지속적인 운영과 개선이 가능하다는 점이 큰 장점으로 작용했다.
내가 맡은 역할: 채점 시스템 설계 및 구현
최종적으로 주제가 코딩 테스트 사이트로 결정되었고, 나는 그중에서도 사용자의 코드 제출을 자동으로 채점하는 "채점 시스템"의 설계와 구현을 맡았다.
다른 기능 개발에도 여러 부분 참여했지만, 채점 시스템은 프로젝트의 가장 핵심적인 기능이자, 내가 가장 많은 시간과 고민을 쏟아부은 영역이었다.
단순히 실행 결과만 확인하는 수준을 넘어서, 다양한 언어 지원, 다건 테스트케이스 처리, 동시 요청 처리, 채점 결과의 실시간 전달 등 고도화된 기능까지 고려해야 했기 때문에 설계와 구현 모두 쉽지 않았다.
이 글에서는 기본적인 채점 기능을 완성하고, 고도화를 앞두기까지의 과정을 중심으로 정리해보려고 한다.
1. 애플리케이션 아키텍처 설계
이번 프로젝트에서는 기존의 3계층(3-Layer) 아키텍처에서 벗어나, 4계층 구조를 기반으로 DDD 스타일의 아키텍처를 도입해보고자 했다.
가장 큰 이유는 도메인 로직과 애플리케이션 유스케이스를 명확히 분리하여, 구조적으로 더 유연하고 변경에 강한 시스템을 만들기 위함이었다.
1.1. 왜 4-Layer인가?
기존의 3Layer (Controller → Service → Repository) 구조에서는 서비스 계층(Service Layer)에 도메인 로직, 비즈니스 유스케이스, 인프라 의존 코드가 섞여 들어가는 경향이 있다.
이를 분리하지 않으면 다음과 같은 문제가 발생할 수 있다.
- 변경 전파가 넓어진다 (한 영역의 변화가 다른 계층에 쉽게 영향을 준다)
- 테스트 코드 작성이 어려워진다 (순수한 도메인 로직만 분리하기 어려움)
- 도메인 중심 설계가 어려워진다
이러한 문제를 줄이기 위해, 다음과 같은 초안이 나왔다.
Presentation → Application → Domain ← Infrastructure- Presentation: 외부 요청을 수신하고, Application 계층에 전달
- Application: 유스케이스(사용자 시나리오) 수행
- Domain: 순수한 비즈니스 로직을 담당
- Infrastructure: 외부 시스템(JPA, Redis 등)과 실제로 통신하는 구현체
1.2. 헥사고날 아키텍처?
아키텍처 토론 중, 외부 API나 써드파티 연동이 많을 것이라는 점을 고려해 헥사고날 아키텍처(Hexagonal Architecture, Ports & Adapters) 적용 의견도 나왔다.
헥사고날 아키텍처는 위 구조에 "포트(Port)"와 "어댑터(Adapter)"라는 개념을 도입한 것이다.
- Port: 내부에서 외부로 의존성을 열어둔 인터페이스. 주로 도메인이나 애플리케이션 계층에서 정의
- Adapter: 외부 시스템과 실제 연결되는 구현체. 외부 API, JPA, 메시지 큐 등
예를 들어, Redis를 이용한 캐시 저장 기능을 생각해보자.
Application 계층에서는 캐시 저장이라는 기능이 필요하지만, Redis를 직접 사용할 필요는 없다.
대신 다음과 같이 포트와 어댑터를 분리하여 구현할 수 있다.
ApplicationPort
└─ CacheStorePort (Interface)
InfrastructureAdapter
└─ RedisCacheAdapter (implements CacheStorePort)이렇게 하면 나중에 Redis 대신 Memcached나 로컬 캐시 구현체로 변경하더라도, RedisCacheAdapter만 교체하면 되므로, 애플리케이션 로직에는 전혀 영향을 주지 않는다.
이런 구조 덕분에 변경에 강하고 테스트하기 쉬운 구조를 만들 수 있다.
포트는 항상 내부 계층에서 정의하고, 외부 계층에서 구현한다는 점에서 의존성 역전 원칙(DIP)을 실현하는 핵심 수단이다.
1.3. 최종 구조와 의사 결정
아키텍처 논의는 무려 3일 동안 이어졌고, 최종적으로는 다음과 같은 기준으로 정리되었다.
- Application Port: 외부 API, Redis 등 비즈니스 로직과 직접 관련은 없지만, 유스케이스 실행에 필요한 기술 의존성을 분리하기 위해 사용
- Domain Port: JPA를 사용하는 Repository를 도메인에서 분리하기 위해 사용
- 완벽한 헥사고날 분리는 어렵지만, 도메인의 JPA 의존도를 최소화하는 방식으로 구현
구조는 다음과 같이 정리되었다.
Client
↓
Presentation
↓
Application
↓
Domain
↓
(Domain Port) ← Infrastructure (예: UserJpaRepository)
Application
↓
(Application Port) ← Infrastructure (예: RedisCacheAdapter)
즉, 이번 프로젝트에서의 구조는 도메인과 애플리케이션이 외부 기술 구현체와의 의존을 완전히 분리할 수 있도록 하는 데에 중점을 두었다.
이를 위해 Port를 계층별로 구분해 정의했고, 외부 구현체는 Adapter로써 주입받아 사용하는 방식으로 설계했다.
하지만 여기서 하나의 근본적인 의문이 남는다.
과연 JPA를 사용하면서도 완벽한 헥사고날 아키텍처를 구현할 수 있을까?
JpaRepository는 도메인 포트(Domain Port)로 주입받아 사용하고 있지만, 사실상 엔티티 설계 시점부터 이미 JPA에 깊이 의존하는 구조가 되어 버린다.
예를 들어, JPA의 어노테이션이나 영속성 컨텍스트의 생명주기에 도메인이 영향을 받는 구조라면, 그것을 과연 순수한 도메인이라 부를 수 있을까?
DDD 관점에서는 여전히 고민이 필요한 지점이다.
2. 자료 조사부터 맞닥뜨린 문제들
프로젝트는 정해진 MVP 기한 내에 완성해야 했기 때문에, 초기 기획과 자료 조사 단계에서부터 여러 현실적인 제약과 마주해야 했다. 그 중 두 가지 가장 큰 문제가 있었다.
2.1. 문제 콘텐츠 확보
첫 번째 문제는, 다양한 유형의 코딩 테스트 문제가 필요하다는 점이었다.
하지만 직접 문제를 만들기엔 시간과 리소스가 부족했고, 검증된 문제를 구성하기엔 한계가 명확했다.
이에 따라 국내에서 코딩 테스트 문제를 제공하는 플랫폼 7군데에 메일을 보냈다.
메일에는 다음과 같은 내용을 담았다.
- 해당 플랫폼의 문제를 학습용으로 활용할 수 있는지 여부
- 수익 목적이 없으며, 부트캠프 과제로 학습 경험을 위한 비영리 프로젝트임
- 팀 Notion 링크와 내 GitHub 주소 첨부
결과적으로 2곳에서 회신을 받았고,
한 곳은 "문제 저작권이 출제자에게 있어서 제공이 어렵다"고 답변했다.
다른 한 곳에서는 조건부로 문제 사용을 허가해주셔서, 큰 난관이었던 문제 확보는 해결되었다.
단, 테스트케이스까지는 따로 제공받을 수 없었기 때문에, 직접 문제를 풀거나 AI의 도움을 받아 문제당 3~5개의 테스트케이스를 직접 구성하기로 했다.
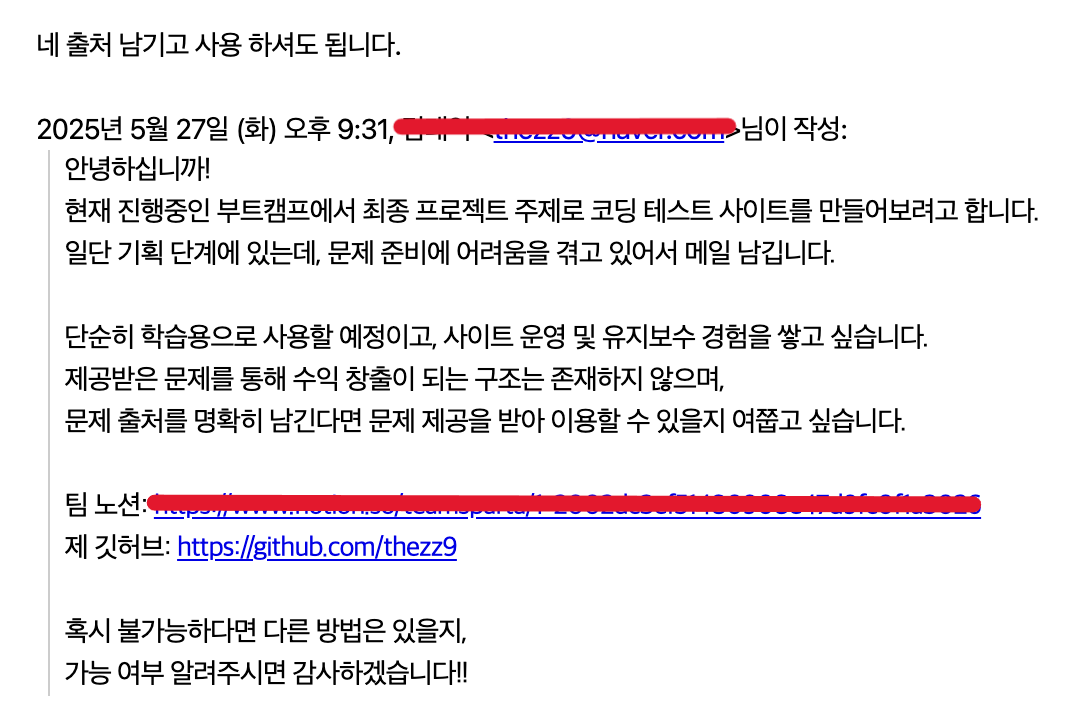
실제로 문제 사용 요청 메일을 보낸 뒤 받은 답변입니다.
출처를 명시하는 조건 하에 문제 사용을 허락받았습니다. 정말 감사드립니다.
2.2. 컴파일러 구현 vs 외부 API 활용
두 번째 문제는, 채점 시스템에서 사용할 컴파일러를 직접 구현하기에는 현실적인 제약이 너무 많았다는 점이다.
난이도, 실행 환경 격리, 언어별 런타임, 보안, 리소스 제한 등 고려해야 할 요소들이 너무 많았고, 무엇보다 시간도 부족했다.
그래서 외부 코드 실행 API나 라이브러리 도입을 검토하게 되었고, 다음과 같은 서비스들을 조사했다.
- JDoodle:
- 다양한 언어 지원, 간단한 API
- 무료 플랜의 호출 수 제한이 큼
- Sphere Engine:
- 안정적인 플랫폼, 고급 기능 제공
- 가격이 비싸고, 실시간성이 다소 떨어짐
- Paiza.IO:
- 클라이언트에서 직접 실행 가능
- 언어/기능 제한, 일본어 기반 문서
- Judge0:
- 오픈소스로 제공되며 self-hosted 가능
- Docker 기반 초기 셋업 필요
이 중에서 우리는 Judge0를 선택했다.
가장 큰 장점은 오픈소스로 제공되어 self-hosted 환경에서 무료로 사용할 수 있다는 점이었다.
SaaS 방식도 제공되지만 사용량에 따라 요금이 부과되며, 공식 문서에서는 Docker 기반으로 온프레미스 설치가 가능하다는 점을 안내하고 있었다.
이에 따라 우리는 AWS EC2 인스턴스에 Docker 컨테이너를 띄워, 내부적으로 Judge0를 실행할 수 있는 컴파일 서버를 직접 구축했다.
docker-compose로 API 서버 및 worker 구성- PostgreSQL, Redis 등 Judge0 의존 DB도 함께 구성
- 기본 언어 세트는 Java, Python, C, C++ 등으로 설정
결과적으로, 외부 API에 종속되지 않으면서도 확장 가능한 온라인 컴파일 인프라를 안정적으로 구성할 수 있었다.
3. Judge0란?
Judge0는 오픈소스 기반의 온라인 코드 실행 엔진(Online Judge Engine)이다.
REST API를 통해 소스코드, 입력값(stdin), 언어 ID 등을 보내면, 실제로 컴파일 및 실행 결과(stdout, stderr, memory, time 등)를 반환해준다.
- 약 50개 이상의 프로그래밍 언어 지원
- 비동기 API 기반
- Docker 컨테이너 격리 환경
- Self-hosted 형태로도 운영 가능
현재 프로젝트에서는 이 Judge0의 Self-hosted 버전을 채점 시스템의 핵심 컴파일러로 활용하고 있으며, 실제 요청 흐름, 응답 구조 처리 방식은 다음 장에서 자세히 설명할 예정이다.
공식 문서 및 저장소 링크
4. Judge0 컴파일 요청
Judge0에서는 코드 실행 요청을 다음과 같이 두 단계로 나누어 처리할 수 있다.
-
POST /submissions
→ 소스코드, 언어 ID, 입력값(stdin) 등을 담아 Judge0에 실행 요청을 전송한다.
→ 이때wait=true또는wait=false옵션을 통해 동기/비동기 처리 방식을 선택할 수 있다. -
GET /submissions/{token}
→wait=false로 요청한 경우, 응답으로 받은token을 이용해 결과를 나중에 조회(polling) 한다.
현재 프로젝트에서는
wait=true를 사용하여, 요청과 동시에 결과를 기다리는 구조로 구현했다.
이 방식은 MVP 단계에서는 구현이 간단하고 빠른 응답 흐름을 설계하기에 유리하다.
하지만 테스트케이스 수가 많아지거나 동시 사용자가 증가하면,wait=false를 활용한 비동기 polling 구조로의 전환을 고려하고 있다.
4.1. Judge0 포트 인터페이스와 어댑터 구현체
Hexagonal Architecture(헥사고날 아키텍처) 스타일을 따르기 위해,
애플리케이션 계층은 Judge0 클라이언트를 직접 의존하지 않고 인터페이스(Port)만 알고 있도록 설계했다.
judgeClient (Application Port)
public interface JudgeClient {
JudgeResult execute(CodeCompileRequest request);
}- 비즈니스 로직은
JudgeClient인터페이스만 알고 있음 - 실제 Judge0와 통신하는 구현체는 Infrastructure 계층에 있음
judge0Client (Infrastructure Adapter)
@Component
@RequiredArgsConstructor
public class Judge0Client implements JudgeClient {
@Value("${external.judge0.url}")
private String judge0ApiUrl;
private WebClient webClient;
private final Judge0ResponseMapper interpreter;
@PostConstruct
private void init() {
this.webClient = WebClient.create(judge0ApiUrl);
}
public JudgeResult execute(CodeCompileRequest request) {
ExecutionResultResponse executionResultResponse = webClient.post()
.uri("/submissions?base64_encoded=false&wait=true")
.contentType(MediaType.APPLICATION_JSON)
.bodyValue(request)
.retrieve()
.bodyToMono(ExecutionResultResponse.class)
.block();
return interpreter.toJudgeResult(executionResultResponse);
}
}WebClient로 HTTP 요청을 보냄ExecutionResultResponse는 Judge0의 응답 DTOJudge0ResponseMapper를 통해 JudgeResult로 변환
4.2. 레이어별 DTO 분리
Judge0는 외부 시스템이기 때문에, 해당 응답 구조를 애플리케이션 내부에 직접 노출하지 않았다.
외부 응답을 내부 로직에 그대로 연결할 경우, API 구조 변경이나 구현체(Judge0 등)의 교체가 상위 계층까지 영향을 미칠 수 있기 때문이다.
이를 방지하기 위해, Infrastructure 계층에서 받은 응답을 내부용 DTO로 변환하여 처리하는 방식으로 계층 간 의존성을 분리했다.
애플리케이션 레이어는 stdout, status.id 같은 외부 필드를 직접 알지 않고,
actualOutput, success와 같은 의미 중심의 필드만 참조하게 된다.
이 구조는 외부 API 변경 시 내부 로직이 영향을 받지 않도록 돕는다.
Request 계층 흐름
// Presentation → Application
public record CodeSubmitRequest(
@NotNull(message = "언어 번호는 필수 입력 값입니다.")
Long languageId,
@NotBlank(message = "소스 코드는 필수 입력 값입니다.")
String sourceCode
) {}
// Application → Infrastructure
public record CodeCompileRequest(
String source_code,
Long language_id,
String stdin
) {}
// 흐름
[Presentation] CodeSubmitRequest
↓ 변환
[Application → Infra] CodeCompileRequestResponse 계층 흐름
// Third-party → Infrastructure
public record ExecutionResultResponse(
String stdout,
Double time,
Long memory,
String stderr,
String token,
String compile_output,
int exit_code,
ExecutionStatus status
) {
public long getMemory() {
return this.memory == null ? 0L : memory;
}
public double getTime() {
return this.time == null ? 0.0 : time;
}
public record ExecutionStatus(
int id,
String description
) {}
}
// Infrastructure → Application
@Builder
public record JudgeResult(
String actualOutput,
double executionTime,
long memoryUsage,
boolean success,
String message
) {
}
// 흐름
[Infra] ExecutionResultResponse (Judge0 원본 응답)
↓ 매핑
[Application] JudgeResult4.3. Judge0 → JudgeResult 변환 로직 (Mapper)
@Component
public class Judge0ResponseMapper {
public JudgeResult toJudgeResult(ExecutionResultResponse executionResultResponse) {
String output = extractActualOutput(executionResultResponse);
boolean success = isSuccessful(executionResultResponse);
return JudgeResult.builder()
.actualOutput(output)
.executionTime(executionResultResponse.getTime())
.memoryUsage(executionResultResponse.getMemory())
.success(success)
.message(executionResultResponse.status().description())
.build();
}
private String extractActualOutput(ExecutionResultResponse executionResultResponse) {
if (executionResultResponse.stdout() != null) return executionResultResponse.stdout();
if (executionResultResponse.compile_output() != null) return executionResultResponse.compile_output();
if (executionResultResponse.stderr() != null) return executionResultResponse.stderr();
return "(No output)";
}
private boolean isSuccessful(ExecutionResultResponse executionResultResponse) {
return executionResultResponse.stdout() != null && executionResultResponse.status().id() == 3;
}
}위에서 설명한 것처럼, JudgeResult는 Judge0 응답을 내부적으로 해석한 DTO다.
이 Mapper 클래스는 그 변환 과정을 실제로 담당하며, 외부 구조를 몰라도 되는 의미 중심의 필드만을 Application에 전달할 수 있게 한다.
전체 흐름으로 보면 이렇게 된다.
[Client]
↓ CodeSubmitRequest
[Controller]
↓
[ApplicationService]
↓ CodeCompileRequest
[JudgeClient (Interface)]
↓
[Judge0Client (WebClient)]
↓ HTTP POST to Judge0 (/submissions)
↓ Judge0 응답 (ExecutionResultResponse)
↓ Judge0ResponseMapper
↓ JudgeResult
[ApplicationService]
↓ 테스트케이스의 기대값과 실제 출력값 비교
↓ SseEmitter.send()로 클라이언트에 결과 전송아래는 Judge0로부터 실제로 수신한 응답 캡처 화면이다.
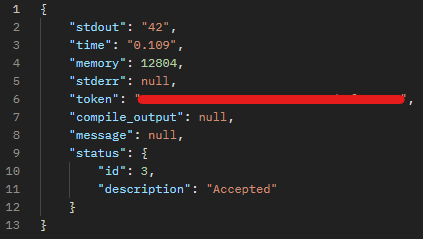
위 응답은 status.id == 3이므로 성공 판정,
stdout이 있으므로 actualOutput은 "42"가 된다.
4.4. 트러블슈팅: /box 디렉토리 접근 불가 이슈
Judge0를 self-hosted로 설치해 사용하면서 가장 당황했던 순간이 있었다.
정상적으로 소스코드와 언어 ID를 담아 요청을 보냈음에도, 다음과 같은 알 수 없는 에러가 발생했다.
No such file or directory @ rb_sysopen - /box/main.c - Internal Error처음에는 단순히 경로 설정이 잘못된 건가 싶었지만, 공식 GitHub 이슈나 StackOverflow에서도 동일한 현상이 반복적으로 언급되고 있었다.
4.4.1. Judge0는 왜 /box 디렉토리를 사용하는가?
Judge0는 내부적으로 isolate라는 샌드박스 도구를 사용한다.
이 isolate는 제출된 코드를 완전히 격리된 환경에서 실행하기 위해, 매번 /box라는 실행 전용 디렉토리를 생성하고 그 안에서 컴파일과 실행을 진행한다.
이 디렉토리는 매우 제한된 권한과 리소스 안에서 동작하며, 사용자의 악의적인 코드로부터 시스템을 보호하는 중요한 역할을 한다.
즉, /box/main.c 같은 경로는 isolate가 직접 만든 "가상 격리 공간"이며, Judge0가 코드를 안전하게 실행하기 위해 꼭 필요한 구조이다.
4.4.2. 원인은 무엇이었나?
내가 사용한 EC2 인스턴스는 Ubuntu 24.04 (Noble Numbat) 버전이었는데,
이 버전부터는 리눅스 시스템에서 기본적으로 cgroup v2를 사용한다.
하지만 문제는 isolate가 아직 완전하게 cgroup v2를 지원하지 않는다는 점이다.
이로 인해 샌드박스 디렉토리(/box)가 제대로 생성되지 않거나 접근이 불가능해지는 현상이 발생한다.
결국 main.c 파일을 생성하려다 실패하고, 위와 같은 rb_sysopen 오류를 발생시키는 것이다.
내부적으로 Ruby 스크립트를 통해
/box/main.c등 파일을 생성하는데, cgroup v2 환경에서는 해당 위치가 제대로 마운트되지 않아No such file or directory에러가 발생한다.
4.4.3. 해결 방법: cgroup v1로 전환
해결은 의외로 단순했다.
Ubuntu에서 cgroup을 v1 모드로 되돌리기 위해, 아래 설정을 추가하고 시스템을 재부팅했다.
sudo vim /etc/default/grubGRUB_CMDLINE_LINUX="systemd.unified_cgroup_hierarchy=0"그리고 나서 grub 설정을 반영하고 재부팅한다.
sudo update-grub
sudo reboot재부팅 이후, 기존에 발생하던 /box 디렉토리 관련 에러는 완전히 사라졌다.
이제 Judge0는 정상적으로 코드 파일을 생성하고 컴파일 결과를 반환할 수 있게 되었다.
Ubuntu 24.04는 기본적으로 cgroup v2를 사용하지만, systemd.unified_cgroup_hierarchy=0 옵션을 통해 v1으로 전환해도 현재 시점에서는 정상 동작하며 별다른 부작용은 없다.
다만 장기적으로는 v2가 표준으로 자리잡는 추세이므로, Judge0와 같은 시스템의 업데이트 여부를 주기적으로 확인하고 v2 호환성을 점검하는 것이 바람직하다.
4.4.4. 트러블슈팅을 통해 느낀 점
이번 이슈를 겪으며 가장 크게 느낀 점은, 오픈소스를 직접 self-hosted로 운영할 때는 단순히 잘 설치된다는 것만으로 끝나는 게 아니라는 사실이었다.
Judge0처럼 시스템 리소스와 맞물려 돌아가는 도구는, 운영체제의 커널 수준 설정(cgroup 등)과도 밀접하게 연결돼 있다는 점을 체감했다.
특히 Ubuntu 24.04처럼 최신 버전 환경을 사용할 경우, 공식 문서에서 명시되지 않은 의존성 문제나 호환성 이슈가 발생할 수 있으며, 이럴 때는 단순히 에러 메시지만으로는 원인을 알기 어렵기 때문에, 관련 오픈소스 프로젝트의 이슈 트래커와 커뮤니티를 탐색하는 습관이 매우 중요하다는 걸 배웠다.
참고: Judge0 GitHub 이슈 #325,
StackOverflow - rb_sysopen /box/main.c 오류
5. 다건 테스트 케이스 채점 로직
이번 목차에서는 앞서 생성된 JudgeResult를 기반으로, 각 테스트 케이스의 기대값과 비교하여 개별 채점 결과를 구성하고, 이를 클라이언트에게 실시간으로 전송하는 구조를 설명하려고 한다.
모든 테스트 케이스에 대한 채점이 완료되면, 최종 결과(전체 통과 여부, 평균 메모리 사용량, 평균 실행 시간)를 종합하여 응답으로 반환한다.
아래는 전체 채점 흐름을 담당하는 메서드의 실제 구현 코드다.
아래에서 각 컴포넌트 설명과 함께 순차적으로 설명할 예정이다.
public SseEmitter submitCodeStream(Long problemId, CodeSubmitRequest request, AuthUser authUser) {
SseEmitter emitter = new SseEmitter();
new Thread(() -> {
try {
SubmissionAggregator aggregator = new SubmissionAggregator();
User user = userDomainService.getUserById(authUser.getId());
Language language = languageDomainService.getLanguage(request.languageId());
ProblemInfo problemInfo = problemDomainService.getProblemInfo(problemId);
int passedCount = 0;
String message = COMPILE_MESSAGE;
for (Testcase tc : problemInfo.testcaseList()) {
JudgeResult result = judgeClient.execute(
new CodeCompileRequest(
request.sourceCode(),
language.getJudge0Id(),
tc.getInput()
)
);
AnswerEvaluation evaluation = submissionDomainService.evaluate(
tc.getOutput(),
result.actualOutput(),
result.success(),
result.executionTime(),
result.memoryUsage(),
problemInfo
);
if (evaluation.isPassed()) {
passedCount++;
} else {
message = result.message();
}
submissionDomainService.collectStatistics(
aggregator,
result.executionTime(),
result.memoryUsage()
);
emitter.send(JudgeResultResponse.fromEvaluation(result, evaluation));
}
SubmissionData submissionData = SubmissionData.base(
user,
problemInfo,
language,
request.sourceCode(),
message
);
submissionDomainService.finalizeSubmission(submissionData, aggregator, passedCount);
emitter.send(SseEmitter.event()
.name("final")
.data(new FinalResultResponse(
problemInfo.getTestcaseCount(),
passedCount,
message
))
);
emitter.complete();
} catch (Exception e) {
emitter.completeWithError(e);
}
}).start();
return emitter;
}5.1. 전체 흐름 개요
채점 요청이 들어왔을 때, 하나의 제출은 다음과 같은 흐름을 따라 처리된다.
- 사용자/문제/언어 등 채점에 필요한 정보 조회
- 각 테스트 케이스 별로 Judge0 실행 및 결과 수신
- 결과 비교 및 통계 수집
- 테스트 케이스 별 응답 실시간 전송 (SSE)
- 최종 채점 결과 집계 및 제출 기록 저장
- 최종 결과 클라이언트 전송
5.2. 핵심 컴포넌트 설명
아래에서는 각 단계에서 활용된 주요 컴포넌트의 역할과 책임을 설명한다.
코드의 양이 많아 스니펫은 생략하고, 핵심 기능 위주로 정리했다.
5.2.1. SubmissionAggregator: 통계 수집 객체
- 테스트 케이스 단위의 실행 시간, 메모리 사용량을 누적 집계하여, 통계 정보로 활용
finalizeSubmission()에서 평균 계산에 사용됨
5.2.2. UserDomainService, LanguageDomainService, ProblemDomainService
- 각각 사용자, 언어, 문제에 대한 정보를 도메인 레벨에서 조회
- ApplicationService에서는 DB 직접 접근 없이 도메인 서비스만 사용
5.2.3. JudgeClient와 CodeCompileRequest
- 외부 시스템(Judge0) 호출을 위한 인터페이스/DTO
- 테스트 케이스 단위로 요청하여 결과를 개별 수신
5.2.4. AnswerEvaluation
- 사용자가 제출한 소스 코드의 출력값과 테스트 케이스에 등록된 기대값을 비교
- 실행 성공 여부, 문제 제한 사항 준수 여부 판단
5.2.5. SubmissionDomainService
evaluate(): 기준에 맞춰 채점collectStatistics(): 통계 수집finalizeSubmission(): 최종 제출 처리
5.2.6. SseEmitter 사용 방식
- 테스트케이스별 결과 →
emitter.send() - 최종 결과 →
.name("final")이벤트로 별도 전송 - 예외 발생 시
completeWithError()
5.3. 실시간 채점 결과 예시 (테스트용 UI 캡처)
아래는 클라이언트 측에서 실시간으로 채점 결과를 수신하고 렌더링하는 모습을 보여주는 캡처 예시다.
테스트 케이스별로 응답이 도착할 때마다 바로바로 결과가 반영되며, 마지막에 최종 결과도 함께 표시된다.
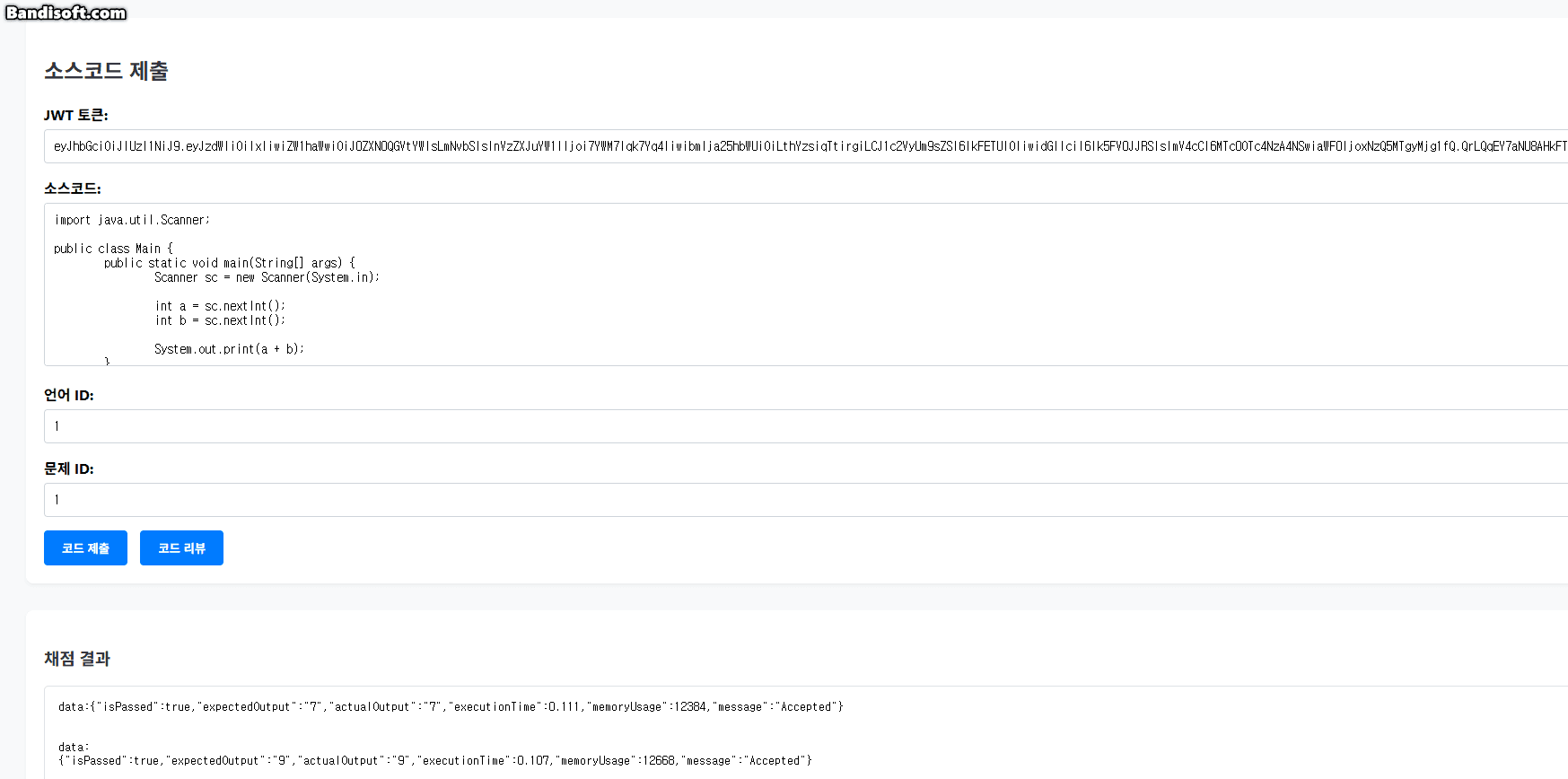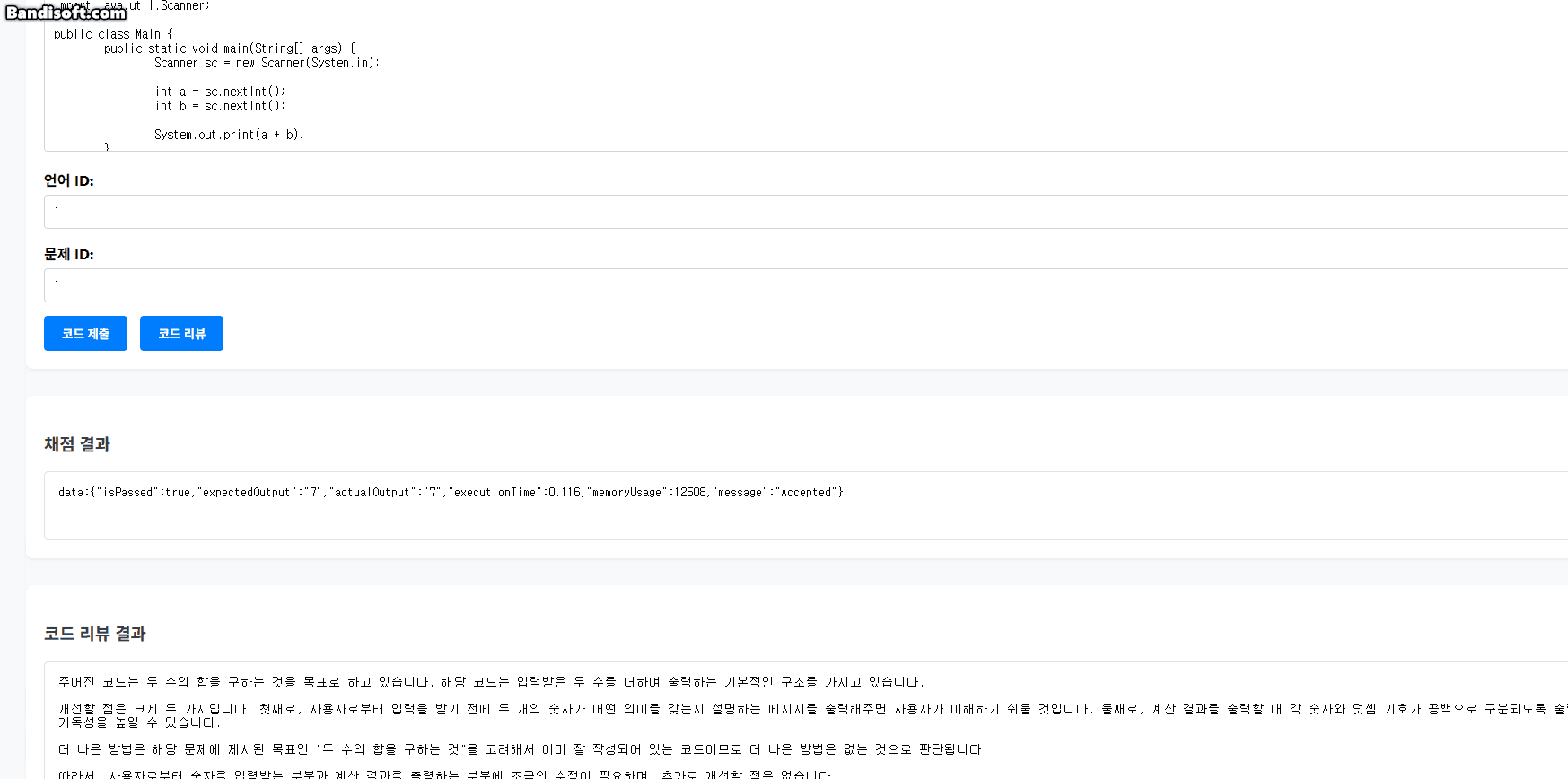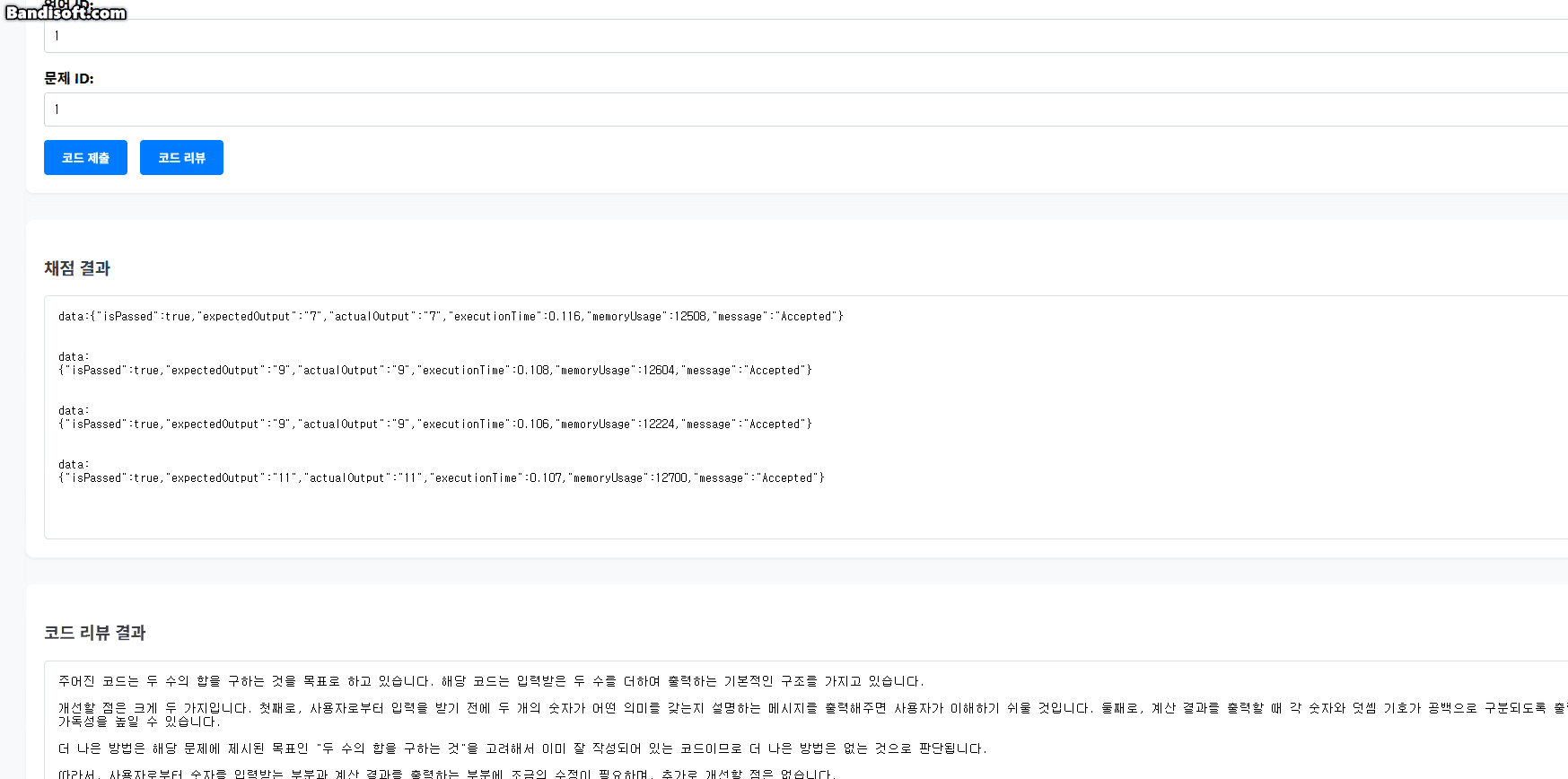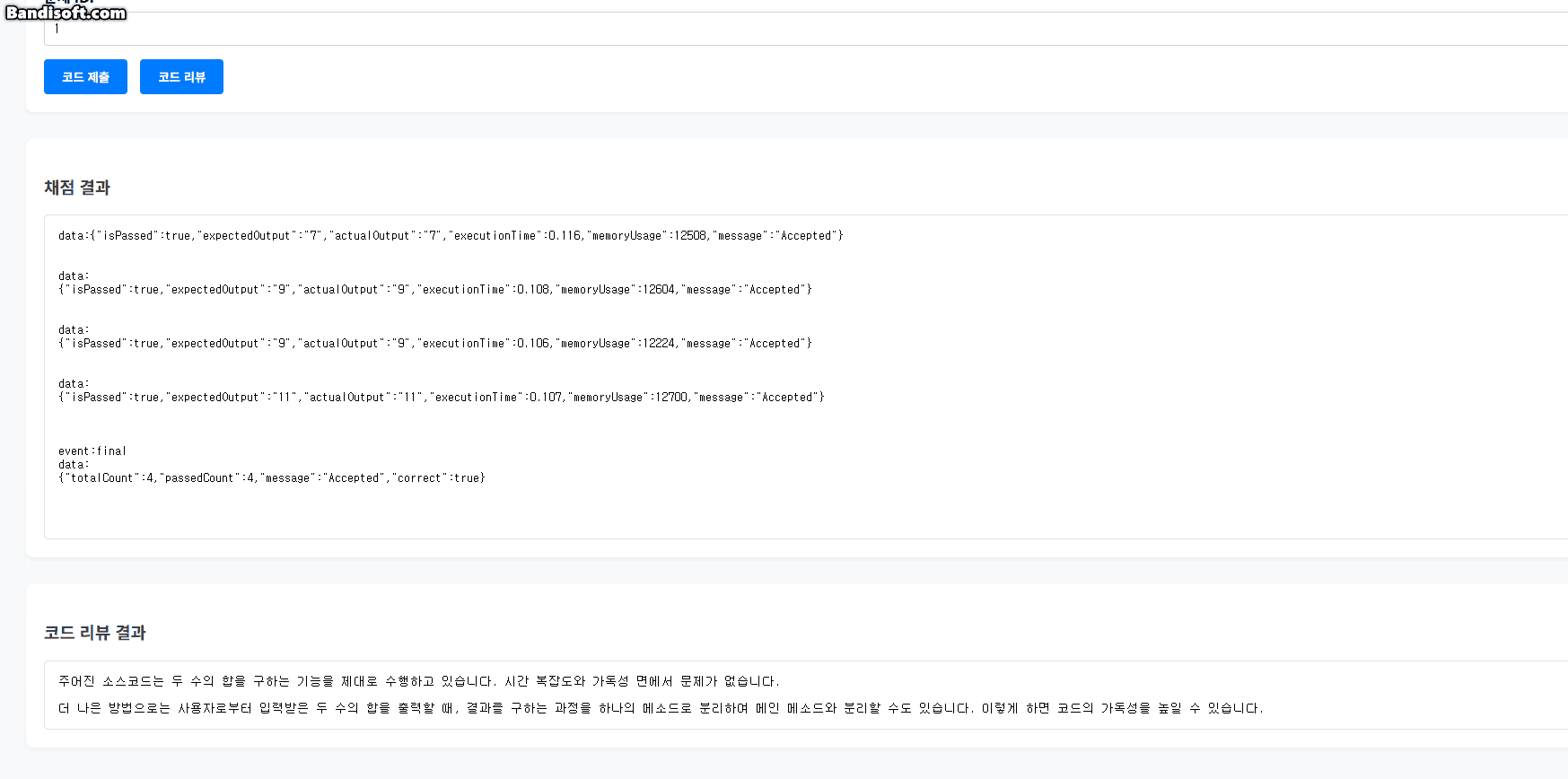
단일 요청에 대해 여러 개의 테스트 결과를 순차적으로 전송하기 위해 SSE(Streamed Event) 방식이 사용되었다.
이는 사용자에게 채점 진행 상황을 실시간으로 보여주는 경험을 제공하기 위한 설계적 선택이다.
5.4. 왜 SSE를 선택했는가?
채점 결과를 사용자에게 실시간으로 보여주기 위해 여러 통신 방식이 고려되었다.
이 프로젝트에서는 그중 SSE(Server-Sent Events) 방식을 선택했다.
총 세 가지 후보가 있었다.
- Polling
- 일정 시간마다 서버에 요청, 구현 단순
- 서버에 부하, 실시간성 부족
- WebSocket
- 양방향 통신 (Full Duplex) 가능, 높은 실시간성, 제어 유연
- 복잡한 설정, 서버 자원 소모 큼
- SSE
- 서버 → 클라이언트 단방향 지속 전송, 브라우저 지원 좋음
- 단방향만 가능, IE 미지원
선택 이유
- 채점 결과는 서버 → 클라이언트 방향의 일방향 흐름이기 때문에 WebSocket처럼 양방향 통신은 과한 스펙이었다.
- SSE는 HTTP 기반 프로토콜이기 때문에 방화벽이나 프록시 환경에서도 잘 작동하고, 추가 설정이 필요 없다.
- 대부분의 최신 브라우저(Chrome, Firefox, Edge, Safari)에서
EventSource라는 내장 API로 쉽게 구현 가능하다.- 예를 들어, 클라이언트는
new EventSource("/채점")으로 손쉽게 구독할 수 있고, - 서버는 Spring의
SseEmitter.send()로 응답을 전송하는 간단한 구조다.
- 예를 들어, 클라이언트는
- 사용자에게 채점 결과를 한꺼번에가 아니라, 테스트 케이스별로 순차적으로 보여주는 실시간 UX에 매우 적합하다.
- Internet Explorer는 미지원이지만, 실사용 환경에서는 큰 제약이 되지 않는다.
물론 향후 실시간 피드백이 양방향성을 필요로 하거나, 제어 흐름이 더 복잡해진다면 WebSocket으로의 전환도 고려해볼 생각이다.
6. 사용자 제출 코드, AI가 리뷰해준다!
단순히 통과 여부만 알려주는 채점 시스템에서 한 걸음 더 나아가,
"사용자가 제출한 코드에 대해 AI가 직접 코드 리뷰를 제공하는 기능"도 함께 기획하고 있다.
이 기능은 코드 제출 이후, 사용자가 원할 경우에만 AI 리뷰를 요청할 수 있도록 설계되어 있다. 기본적으로 자동 실행되지 않으며, 리뷰는 사용자의 선택에 따라 요청된다.
현재는 OpenAI의 GPT 모델에게 사용자 코드를 전달하여, 간단한 피드백을 생성하는 구조로 구현되어 있다.
기본적인 동작 흐름은 기존 Judge0 채점 로직과 거의 유사하며, 다음과 같은 순서로 진행된다.
- 사용자가 문제에 대해 코드를 제출한다.
- Judge0를 통해 실행 결과 및 채점이 완료된다. (필수)
- 제출한 소스코드를 AI에게 전달하여 다음 내용을 분석하게 한다.
- 코드 스타일, 중복, 복잡도 등 품질 피드백
- 더 나은 알고리즘 제안
- 시간/공간 복잡도 분석
- 분석 결과는 별도 UI 영역에 리뷰 형태로 표시된다.
예를 들어, 사용자가 반복문을 여러 번 중첩해 단순하게 문제를 해결했다면,
AI는 "반복문을 여러 번 사용하는 대신, 정렬 후 한 번의 순회로 해결하는 방식이 더 효율적일 수 있어요. 또는, HashMap을 이용하면 시간 복잡도를 줄일 수 있습니다." 와 같은 피드백을 줄 수 있다.
현재는 아래와 같이 OpenAI에 요청을 보내는 간단한 클라이언트 형태로 구현되어 있다.
기본적인 구조는 앞서 소개한 Judge0 호출 방식과 거의 동일하다.
@Component
@RequiredArgsConstructor
public class OpenAiClient implements ReviewClient {
@Value("${OPEN_API_URL}")
private String openApiUrl;
@Value("${OPEN_API_KEY}")
private String openApiKey;
private WebClient webClient;
@PostConstruct
private void init() {
this.webClient = WebClient.create(openApiUrl);
}
@Override
public ReviewResult requestReview(ReviewPayload request) {
String userPrompt = buildPrompt(request);
Map<String, Object> requestBody = Map.of(
"model", "gpt-3.5-turbo",
"messages", List.of(
Map.of("role", "system", "content", "코딩 테스트 사이트의 코드 리뷰를 담당하는 역할을 해주세요."),
Map.of("role", "user", "content", userPrompt)
)
);
return webClient.post()
.uri("/v1/chat/completions")
.header("Authorization", "Bearer " + openApiKey)
.contentType(MediaType.APPLICATION_JSON)
.bodyValue(requestBody)
.retrieve()
.bodyToMono(OpenAiResponse.class)
.map(response -> new ReviewResult(response.getReviewContent()))
.block();
}
private String buildPrompt(ReviewPayload request) {
String status = request.isCorrect() ? "정답" : "오답";
return """
문제: %s
아래는 %s 언어로 작성된 소스코드입니다.
사용자가 제출한 코드이고, %s 입니다.
```
%s
```
- 정답일 경우: 시간 복잡도와 가독성, 더 나은 방법이 있다면 조언을 주세요. (코드를 보여주는 것 제외)
- 오답일 경우: 오답 코드 부분과 오답 원인과 관련된 키워드 (예: 메서드 이름, 알고리즘 종류, 자료구조 등)를 알려주세요.
""".formatted(request.problemDescription(), request.languageName(), status, request.sourceCode());
}
}외부 API(OpenAI)와의 직접적인 의존을 피하기 위해, ReviewClient라는 Application Port 인터페이스를 정의하고, 실제 API 호출은 Infrastructure 계층의 Adapter에서 구현하는 방식으로 분리하였다.
이 기능은 아직 MVP 수준의 단순한 구조지만, 향후 개선과 확장을 고려하고 있으며, 그 내용은 다음 장에서 소개할 예정이다.
7. 예정하고 있는 고도화 목록
채점 시스템의 기본적인 동작은 구현을 완료했지만, 실제 서비스 수준으로 끌어올리기 위해서는 다양한 고도화와 안정화 작업이 필요하다. 현재까지 고민 중인 부분은 다음과 같다.
물론 이 모든 기능을 당장 구현하긴 어렵지만, 일부는 구현 이후 블로그 포스팅으로 기록을 계속 남길 예정이다.
7.1. 시스템 부하와 통신 최적화
- 사용자 요청이 몰리거나 컴파일 서버의 scale-out이 어려운 상황에 대비해, 성능 최적화 및 대기열 기반 처리 방식도 필요할 수 있다.
- 예를 들어, 메시지 큐(RabbitMQ, Kafka 등)를 활용한 비동기 처리 구조로 전환하거나, 채점 요청 우선순위 설정 방식도 가능하다.
- 현재는
wait=true방식으로 동기 요청을 처리하고 있으나, 추후에는wait=false+ polling 구조나 비동기 알림 기반 응답 구조로 전환할 수 있다.
7.2. 장애 대응 및 예외 처리 강화
- 채점은 서비스의 핵심 기능인 만큼, 세분화된 예외 처리와 장애 발생 시 복구 전략이 필수적이다.
- 예를 들어, Judge0가 특정 요청에 대해 응답하지 않거나 오작동할 경우, 자동 재시도 및 대체 응답 제공 등의 로직이 필요하다.
- 해당 영역만으로도 단일 포스트로 분리해 다룰 만큼 많은 고민거리가 나올 것 같다.
7.3. AI 리뷰 정밀도 향상 (프롬프트 정형화)
- 현재는 간단한 형태의 프롬프트를 사용하고 있지만, 향후 문제 유형, 정답/오답 여부, 언어 특성 등을 반영한 정형화된 프롬프트 템플릿을 개발할 계획이다.
- 코드에 포함된 주요 키워드, 메서드, 시간복잡도 등의 정보도 함께 추출해 AI가 보다 정확한 리뷰를 제공할 수 있도록 개선할 수 있다.
- 프롬프트의 품질을 개선하는 것만으로도 AI 리뷰 결과의 질이 크게 향상된다.
이는 곧 사용자의 학습 효과를 높이는 결과로 이어질 수 있기 때문에, 매우 중요한 개선 항목이다.
7.4. 유사 제출 캐싱 및 중복 방지
- 동일한 문제에 같은 코드를 반복 제출할 경우, 매번 채점 요청을 보내는 것은 불필요한 리소스 낭비다.
- 이를 방지하기 위해, 문제 ID + 소스 코드 해시 기준의 캐싱 전략을 도입하면 일부 요청을 빠르게 응답할 수 있다.
- 이와 함께 연속 클릭 방지(디바운싱) 기능도 프론트엔드/백엔드 양쪽에서 고려 중이다.
7.5. 코드 악의적 제출 방어
- 무한 루프, 메모리 폭주 코드, 시스템 자원 고갈을 유도하는 악성 코드가 제출될 수 있다.
- 현재 Judge0에서 메모리/시간 제한을 설정하고 있으나, 사용자 입력을 분석해 사전 차단하는 방법도 검토할 필요가 있다.
- 예를 들어, 특정 패턴(예:
while(true))에 대해 선제적 경고 메시지를 제공할 수도 있다.
7.6. 성능 및 로그 모니터링 체계
- 실시간 사용자 수가 늘어나면 서버 성능, 응답 시간, 오류율 등을 시각화하여 지속적으로 개선할 필요가 있다.
- 간단한 수준의 Application 로그 외에도, JMeter 또는 k6를 활용한 부하 테스트 및 지표 기반 모니터링을 도입할 계획이다.
- 이 부분은 인프라 담당과 협업하여 역할을 분리하고 관리체계를 정립할 필요가 있다.
7.7. 문제 정답 시 GitHub 레포 자동 커밋 기능
- 사용자가 문제를 통과하면, 해당 문제 ID와 소스코드를 자동으로 사용자의 GitHub 레포지토리에 커밋하는 기능도 고려 중이다.
- 이는 "문제 풀이 히스토리 관리"를 자동화하여, 사용자가 별도로 정리하지 않아도 개인 코딩 히스토리를 남길 수 있도록 돕는다.
- GitHub Personal Access Token 기반 인증 방식으로 구현하며, 사용자가 원할 경우에만 활성화되도록 옵션을 제공할 예정이다.
7.8. AI 입력 이슈 및 분석기 도입 실험 (AI 가드)
- 조사 중 확인한 내용에 따르면, AI가 사용하는 공백 문자(스페이스)는 키보드 입력과 유니코드 레벨에서 다를 수 있다는 정보가 있다.
- 단순한 복사 붙여넣기는 사용자의 학습에 방해가 되기 때문에, 이를 탐지하고 방지하는 간단한 AI 입력 분석기도 실험해볼 계획이다.
이 외에도 향후 확장 가능성은 매우 크고, 일부 기능은 사이트를 지속적으로 운영하며 발전시킬 계획이다.
일단은 핵심 기능을 MVP 수준으로 구현한 데에 의의를 두고, 나머지는 개선 여지를 충분히 남겨두었다.
