해커톤과 병행한다고 바빠져서 제대로 쓰지못해서 지금이나마 짧게 써본다.
나는 고잉디퍼 단계에서 자연어를 선택했다.
자연어랑 컴퓨터 비전의 사이에서 고민이 많았다.
그래도 자연어를 선택했고 중도 후기이다.
자연어 처리
일단 직관적으로 보이는 CV에 비해서 잘 보이지않는다.
단어들을 토큰화하고 분산화해서 임베딩 벡터로 만들어서
컴퓨터가 이해하기 쉽게 만들어버리니깐
반대로 인간인 나는 오히려 직관적인 이해가 어렵게 되는거같다 ㅋㅋㅋㅋ
그렇기때문에
뭔가 토큰화할때, 임베딩할때 더 직관적으로 살펴볼수있게 여러 text를 가지고 해보는게 도움이 많이 되는듯... 그래도 숫자들이라 잘 이해가 안될 가능성이 높지만
그리고 뭔가 한국어는 자모단위, 한자를 같이 학습시키는게 도움이 될거같은데 아직 잘 미숙해서 모르겠다. 그래도 중간에 noise를 추가시켜 학습하는 모델들은 흥미로워서 추후에 더 정리해보겠다.
해커톤에서 사용.
중고거래 게시판 제목을 대상으로 text generator 모델을 만들어 보았었는데
확실히 하나의 주제에 관련되서는 text generator가 나쁘지않겠다는 생각이 들었다.
다시 말해 각각 주제에 대해서 text generator 모델을 fine tuning하는게 좋다는 생각이 들었음.

제한된 단어들만 나오는 text를 학습시켰음
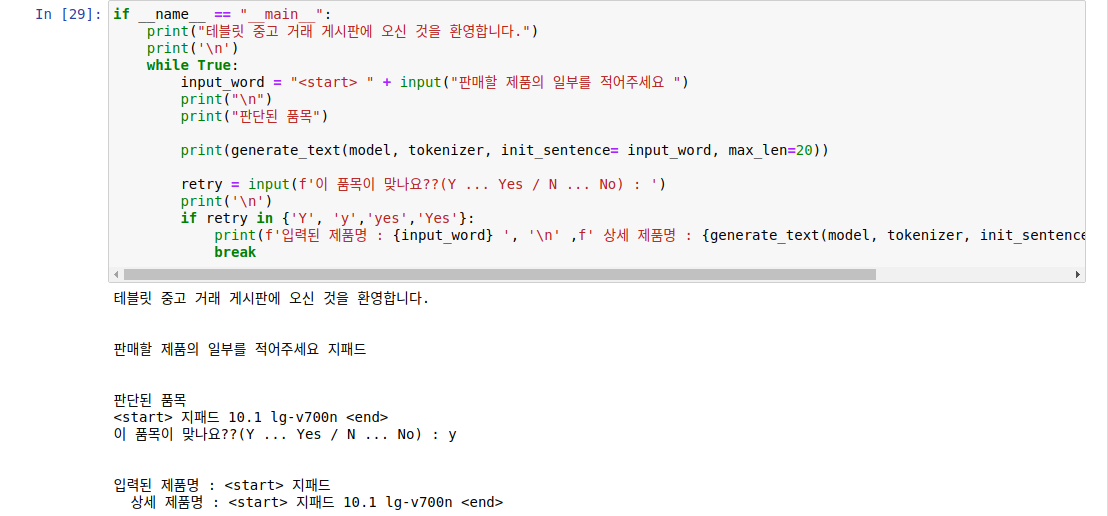
지패드만 쳐도 지패드 일렬번호와 인치까지 잘 나타냄
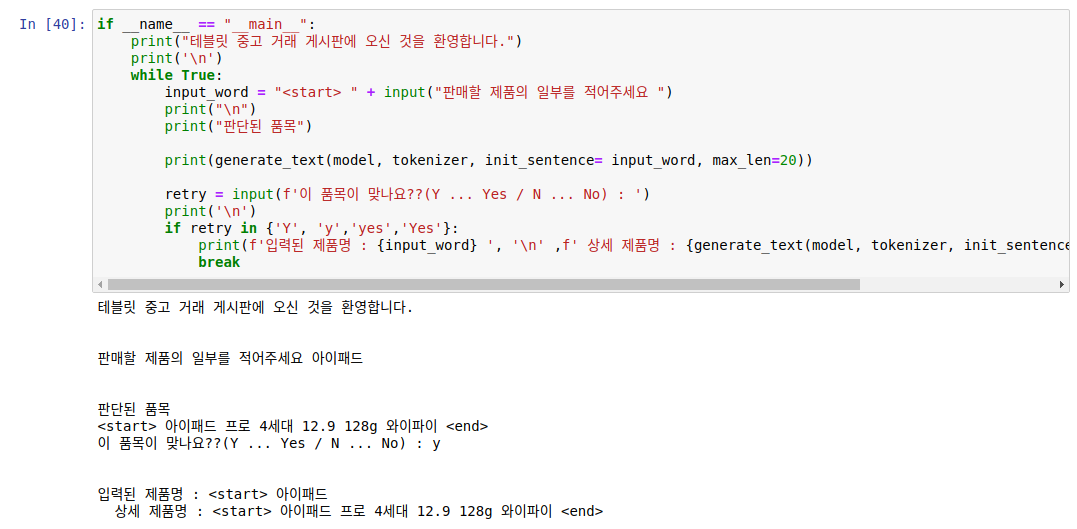
아이패드 역시 프로 12.9인치와 128g옵션 와이파이까지 잘 보여주는 모습
상당히 간단하게 만들어보았는데 데이터를 더 전처리하면 더 잘만들수도 있을꺼같다.

공부중