🤖 헌법적 AI 핵심 요약
“도움이 되면서도 해롭지 않은 AI”를 향한 Anthropic의 접근
🧭 개요
Anthropic의 Constitutional AI(2022)는
AI가 사람의 피드백 없이도 스스로 “도움이 되면서도 해롭지 않게” 학습할 수 있음을 보여줍니다.
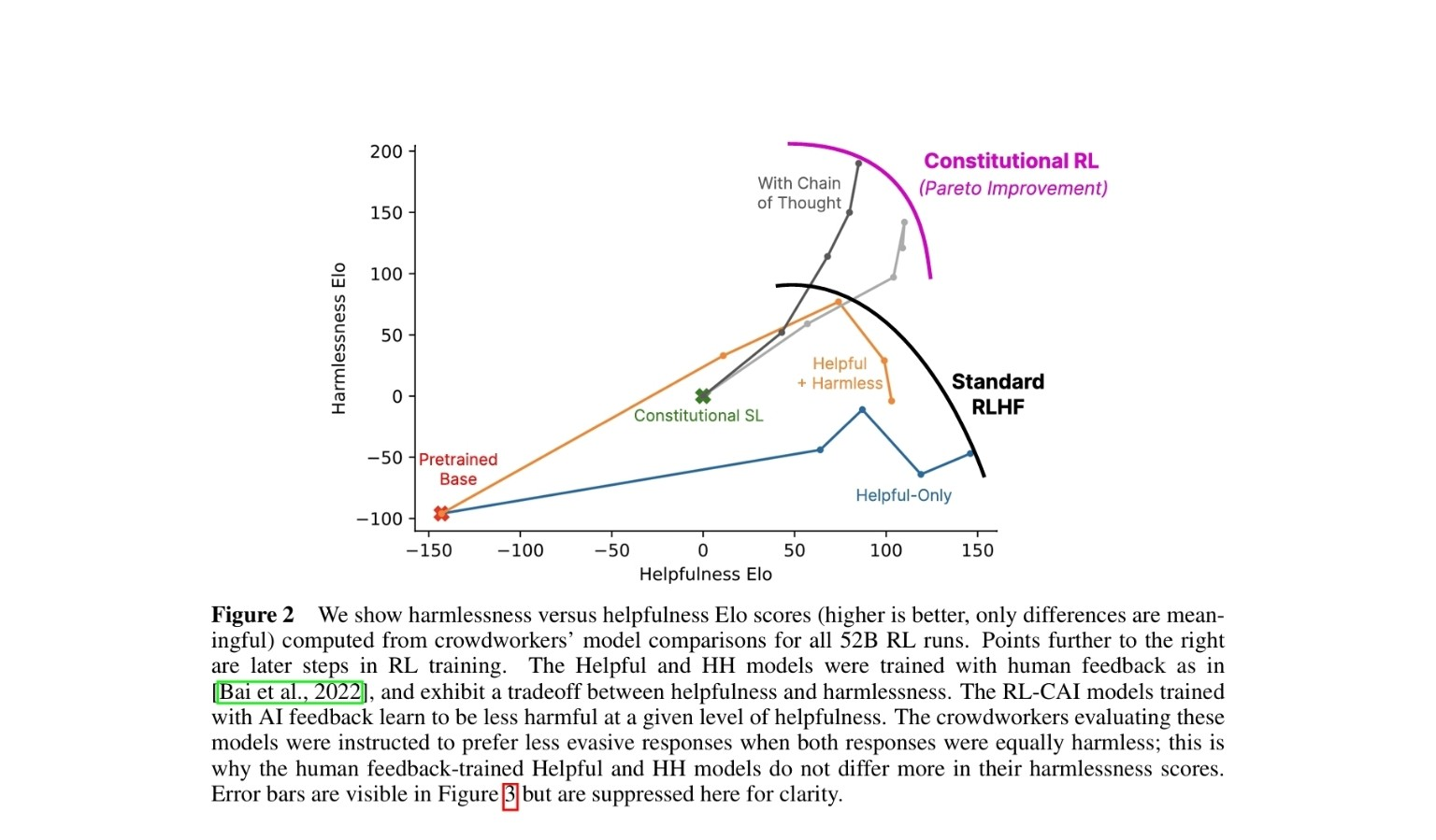
논문 속 Figure 2는
‘도움됨(Helpfulness)’과 ‘무해함(Harmlessness)’의 관계를 시각적으로 표현한 핵심 그래프입니다.
📊 그래프 핵심 해석
| 축 | 의미 |
|---|---|
| X축 | Helpfulness (얼마나 도움이 되는가) |
| Y축 | Harmlessness (얼마나 안전한가) |
오른쪽 위로 갈수록 — 더 유용하고, 더 안전한 모델
⚖️ 주요 메시지
-
기존 RLHF(사람 피드백)
→ 도움과 무해함 사이에 트레이드오프(상충 관계) 존재
(도움을 늘리면 종종 위험도 커짐) -
Constitutional AI(AI 피드백)
→ AI가 스스로 규칙(헌법)에 따라 피드백을 제공
→ 두 지표 모두 개선되는 Pareto 개선(Pareto Improvement) 달성
즉,
사람이 일일이 평가하지 않아도,
AI가 “도움을 주면서도 안전한 방향”으로 스스로 성장할 수 있다는 실증적 결과입니다.
💬 핵심 개념
- Crowdworker: AI 답변을 비교·평가하는 사람 (Human Feedback 제공자)
- Less Evasive Response: 단순 회피가 아닌, 이유를 설명하며 정중히 대응하는 답변
→ AI가 “도망치지 않고 책임감 있게 대화”하도록 학습
🧩 결론
Constitutional AI는
“AI가 AI를 가르치는 방식”으로
사람보다 효율적이고 안전한 자기학습 체계를 구축한 모델입니다.

AI developer