도입 — 왜 이 그림이 중요한가
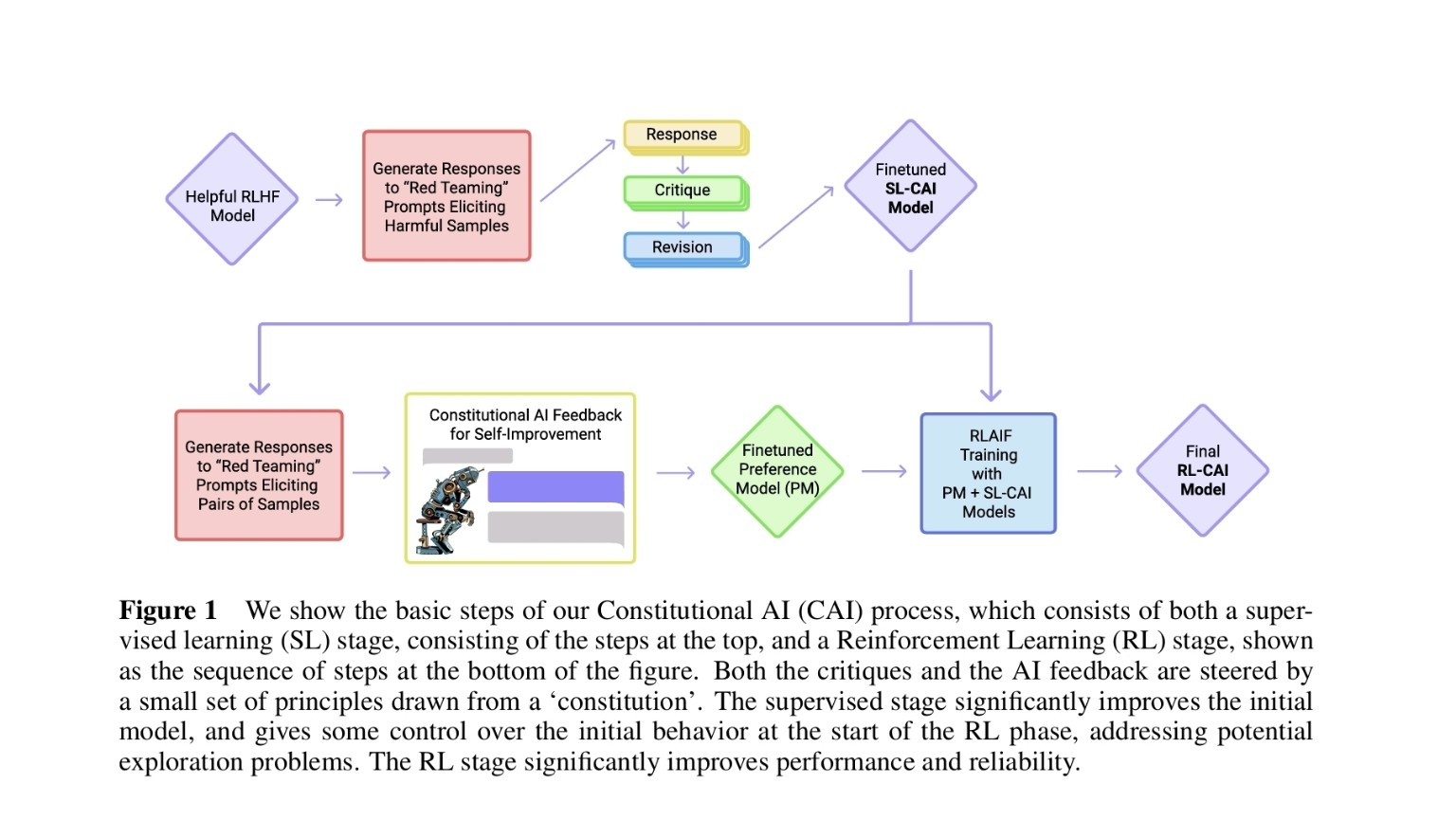
Anthropic의 Constitutional AI (CAI) Figure 1은 ‘AI가 스스로 생성한 데이터로 안전성과 유용성을 개선하는’ 전체 학습 파이프라인을 한눈에 보여줍니다. 이 글은 그림의 핵심 단계들을 간결하게 정리하고, 각 단계의 목적과 역할을 실무자가 바로 이해할 수 있게 설명합니다.
1. 한눈 요약 (핵심 포인트)
-
CAI는 두 단계로 구성됩니다:
- 지도학습(SL) 단계 — AI가 스스로 응답을 만들고, 자기비판(Critique)·수정(Revision)을 통해 SL-CAI 모델로 미세조정됨.
- 강화학습(RL) 단계 — SL-CAI와 Finetuned Preference Model (PM)을 이용해 RLAIF(AI Feedback 기반 강화학습)를 수행, 최종 RL-CAI 모델 획득.
-
헌법(constitution): Self-critique와 AI 피드백을 ‘어떤 원칙(헌법)’에 맞춰 유도하는 규범 세트로 작동.
-
빨간 네모(Red boxes): AI가 의도적으로 ‘문제 있는 응답’ 또는 ‘응답 쌍’을 생성하는 self-generated data 단계 — 이후 자기비판/비교·선호 학습에 사용됨.
-
주요 네트워크: (1) Helpful RLHF model (초기), (2) Finetuned SL-CAI (중간), (3) Final RL-CAI (최종). + 보조: Finetuned Preference Model (PM, 보상 역할).
2. 그림 흐름을 단계별로 풀어보기
SL 단계 (위쪽 박스들) — Self-improvement via Response → Critique → Revision
- 초기 모델 (Helpful RLHF Model)
기존 RLHF로 학습된 출발점 모델 — 기본적으론 유용하지만 취약점 존재. - Red-teaming prompts → 응답 생성
의도적으로 위험하거나 문제될 수 있는 프롬프트로 응답을 생성하게 함(문제 사례 수집). - Response → Critique → Revision
AI가 자신이 생성한 응답을 스스로 비판하고(critique), 그 비판을 반영해 수정된 응답(revision)을 만듦. - Finetuned SL-CAI Model
이렇게 생성된 (응답, 비판, 수정) 쌍으로 지도학습을 수행해 SL-CAI 모델을 미세조정함(초기 행동 제어 및 탐색 문제 완화).
핵심효과: 초기 모델 품질을 크게 끌어올리고 RL 단계 진입 전 안정적 행동을 확보.
RL 단계 (아래쪽 박스들) — Preference 기반 강화학습 (RLAIF)
- Red-teaming prompts → 둘(또는 여러) 응답 쌍 생성
비교 가능한 응답 쌍을 생성해 어느 쪽이 ‘헌법 원칙’에 더 잘 맞는지 평가할 수 있게 함. - Constitutional AI Feedback (AI가 만든 피드백)
‘헌법’ 원칙을 기반으로 AI가 응답 쌍을 평가하고 피드백을 생성. 인간이 아니라 AI가 선호 신호를 만듦. - Finetuned Preference Model (PM)
AI 피드백을 바탕으로 학습된 보상 신호 모델 — 어떤 응답이 더 바람직한지 점수화. - RLAIF Training (PM + SL-CAI as policy)
SL-CAI(정책)과 PM(보상)을 이용해 강화학습(예: PPO 유사 방식)으로 최종 모델을 업데이트. - Final RL-CAI Model
성능과 신뢰성이 향상된 최종 헌법적 AI 모델 완성.
핵심효과: 사람 대신 AI가 만든 ‘헌법 준수성’ 신호를 보상으로 사용해, 인간 라벨 비용을 낮추면서도 안전성과 일관성을 확보.
3. 빨간 네모(Red boxes) — 무슨 역할을 하나?
- 위쪽 빨간 네모: 문제(유해) 응답을 일부러 생성 → 자기비판/수정 학습용 데이터 생성.
목적: 모델의 취약점(어떤 상황에서 유해 응답을 하는지)을 노출시키고 고치게 함. - 아래쪽 빨간 네모: 응답 쌍(pair) 생성 → AI가 두 응답을 비교해 더 헌법 원칙에 맞는 답을 선택하도록 학습시키기 위한 데이터.
목적: PM을 통해 ‘우수 응답’을 자동 평가하게 함.
요약: Self-generated training data를 만들기 위한 핵심 단계 — 모델이 스스로 문제를 만들고, 스스로 배우게 하는 구조.
4. 등장하는 모델들 정리 (역할 기준)
- Helpful RLHF Model — 출발점(사람의 피드백으로 이미 보정된 모델)
- Finetuned SL-CAI Model — Response→Critique→Revision으로 미세조정된 중간 모델
- Finetuned Preference Model (PM) — 보상 점수를 매기는 평가자(보조 네트워크)
- Final RL-CAI Model — PM의 보상으로 RLAIF를 거쳐 얻은 최종 모델
(메인 생성 모델은 3개, 보상용 PM을 더하면 총 4개의 네트워크가 상호작용)
5. RLHF와 CAI의 차이(그리고 연결점)
-
RLHF (전통적):
- SFT(지도학습, 인간이 쓴 좋은 답으로 미세조정) → 2) Reward Model(사람 선호 학습) → 3) RL(PPO 등)으로 정책 업데이트.
사람의 선호를 보상으로 사용한다는 점이 핵심.
- SFT(지도학습, 인간이 쓴 좋은 답으로 미세조정) → 2) Reward Model(사람 선호 학습) → 3) RL(PPO 등)으로 정책 업데이트.
-
CAI (헌법적 AI):
RLHF의 틀을 따르되, ‘헌법’ 원칙을 정해 AI의 자기비판·피드백을 유도하고, 가능하면 AI가 만든 피드백(PM 기반)으로 RLAIF를 수행해 사람 평가 의존도를 낮추는 방향을 제시.
결론: CAI는 RLHF의 철학을 유지하되, 규범(헌법)을 통해 AI 스스로 안전성 판단을 만들고 그로써 확장·자동화하려는 시도이다.
6. 실무적 시사점 (빠른 체크리스트)
- 모델 개선 파이프라인 설계 시: self-generated data(red-teaming → critique → revision)를 적극 활용하면 라벨링 비용을 줄일 수 있음.
- 다만 헌법(원칙) 설계의 품질이 곧 시스템 안전성의 핵심이므로 원칙 정의와 우선순위 설계가 매우 중요.
- PM을 보상으로 쓸 때는 PM 자체의 편향·오류를 모니터링하는 절차가 필요함(순환적 오류 위험).
- SL 단계로 초기 안정성을 확보한 뒤 RL 단계로 넘어가면 탐색 시의 위험(예: 무책임한 행동)을 줄일 수 있음.
7. 마무리 요약 한 문장
Constitutional AI는 헌법 기반 원칙으로 AI의 자기비판과 피드백을 유도하고, 그 신호를 보상으로 삼아 SL-기반 안정성 → PM 기반 RLAIF를 통해 안전하고 신뢰할 수 있는 최종 모델을 만드는 실용적 파이프라인입니다.
