Cascaded Diffusion Models: 고해상도 이미지 생성을 가능하게 만든 결정적 설계
인공지능
1. 왜 고해상도 이미지 생성이 어려웠을까?
디퓨전 모델(Diffusion Models)은 GAN, VAE를 뛰어넘는 안정성과 샘플 품질로 이미지 생성 분야의 중심으로 떠올랐습니다.
그러나 한 가지 명확한 한계가 있었습니다.
“대규모 고해상도 이미지를, 강한 조건 없이도 잘 만들 수 있는가?”
기존 연구들은
- 작은 해상도
- 작은 데이터셋
- 혹은 강력한 조건(예: classifier guidance)
에 의존하는 경우가 많았습니다.
이 논문은 ImageNet 같은 대규모·고해상도 환경에서도, 순수 디퓨전 모델만으로 최고 품질을 달성할 수 있는가라는 질문에서 출발합니다.
2. 핵심 아이디어: 한 번에 만들지 말고, 나눠서 만들자
🔁 Cascaded Diffusion Models (CDM)
CDM의 핵심은 단순하지만 강력합니다.
“고해상도 이미지를 한 번에 생성하려 하지 말고, 저해상도에서 시작해 단계적으로 키운다.”
이를 위해 여러 개의 디퓨전 모델을 파이프라인 형태로 연결합니다.
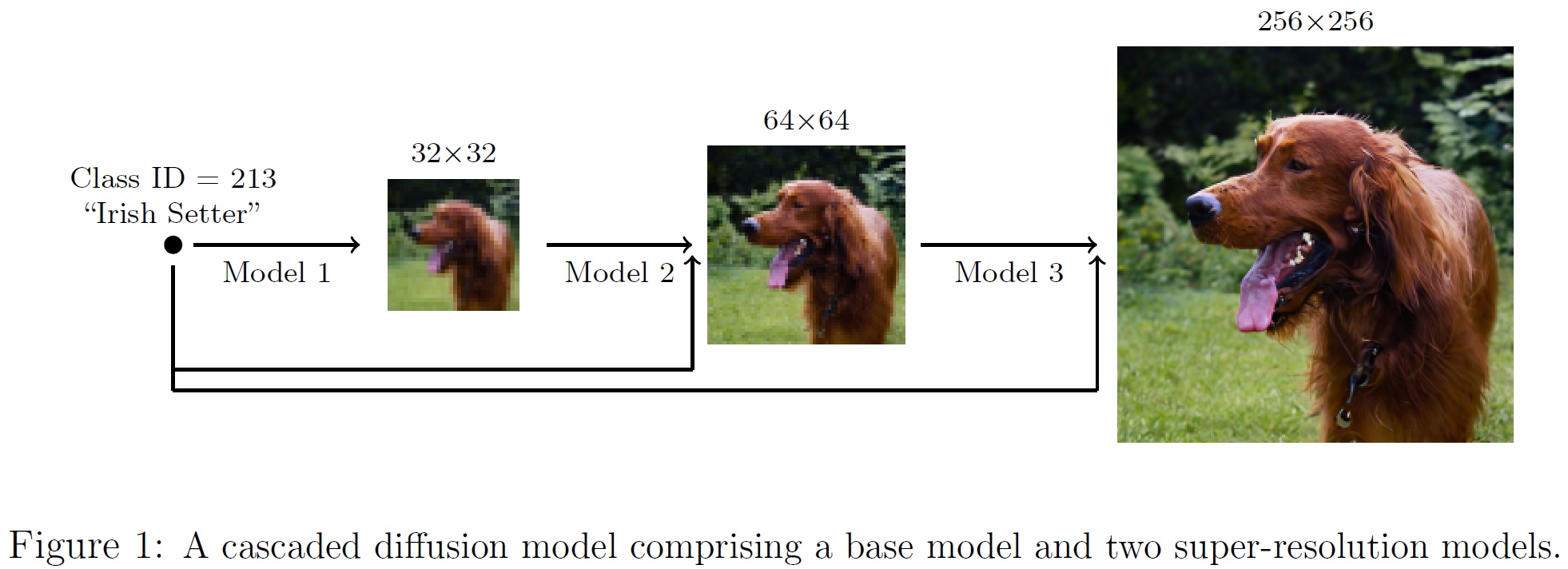
- Base Model (Model 1): 저해상도 이미지 생성 (전체 구조 담당)
- Super-resolution (Model 2): 해상도 증가 + 중간 디테일
- Super-resolution (Model 3): 최종 고해상도 + 고주파 디테일
이 구조 덕분에
- 계산은 안정적이고
- 학습은 쉬워지며
- 결과 품질은 오히려 더 좋아집니다.
3. 진짜 성능 향상의 비밀: Conditioning Augmentation
단계적 생성에는 치명적인 문제가 하나 있습니다.
❗ 문제: 오류 누적 (Compounding Error)
학습 시 (Training phase):
- 깨끗한 원본 이미지를 다운샘플해서 업스케일러에 입력
실제 생성 시 (Test phase):
- 이전 단계 모델이 만든 불완전한 이미지가 입력
이 차이 때문에 Train–Test Mismatch가 발생하고,
앞 단계의 작은 실수가 뒤 단계에서 크게 증폭됩니다.
✅ 해결책: Conditioning Augmentation
논문이 제안한 핵심 기술은 Conditioning Augmentation입니다.
-
초해상도 모델을 학습할 때
-
입력되는 저해상도 이미지에
- 노이즈
- 블러
- 변형을 의도적으로 추가
즉,
“망가진 입력에도 잘 작동하도록 일부러 단련시키는 것”
그 결과,
- 앞 단계가 실수해도
- 뒤 단계가 이를 자연스럽게 보정할 수 있습니다.
4. Figure 1로 보는 CDM 구조 한눈에 이해하기
Figure 1은 CDM의 전체 파이프라인을 직관적으로 보여줍니다.
🔹 단계별 구조
-
32×32 Base Model
- 클래스 조건(Class ID)을 받아 전체 구도 생성
-
64×64 Super-resolution
- 형태를 유지하며 디테일 보강
-
256×256 Super-resolution
- 질감, 고주파 정보 완성
모든 단계는 동일한 클래스 조건을 공유하며,
각 업스케일러는 Conditioning Augmentation으로 학습됩니다.
5. 실험 결과와 주요 기여
이 논문은 단순한 구조 제안에 그치지 않습니다.
📈 성능 측면
- Classifier 없이 BigGAN-Deep (FID), VQ-VAE-2 (Accuracy) 능가
- 순수 생성 모델 기준 당시 최고 수준
🧪 실험적 발견
- 저해상도 업스케일링 → Gaussian Noise
- 고해상도 업스케일링 → Gaussian Blur
가 가장 효과적이라는 점을 규명
6. 이 논문이 여전히 중요한 이유 (2024–2025)
Cascaded Diffusion은 과거의 아이디어가 아닙니다.
- Google Imagen 시리즈: 지금도 동일한 캐스케이드 구조 사용
- Stability AI – DeepFloyd IF: 픽셀 기반 Cascaded Diffusion 채택
- Apple Matryoshka Diffusion (2024): 다중 해상도 통합 확장
- Virtual Try-On, 고화질 생성 서비스의 표준 구조
즉,
“최고 화질이 필요한 곳에서는 여전히 Cascaded Diffusion이 정답”
이라는 것이 업계의 합의에 가깝습니다.
✨ 마무리 한 줄 요약
Cascaded Diffusion Models는 ‘단계적 생성’과 ‘Conditioning Augmentation’을 결합해 디퓨전 모델로 고해상도 이미지 생성의 한계를 돌파한 지금도 유효한 핵심 아키텍처다.
