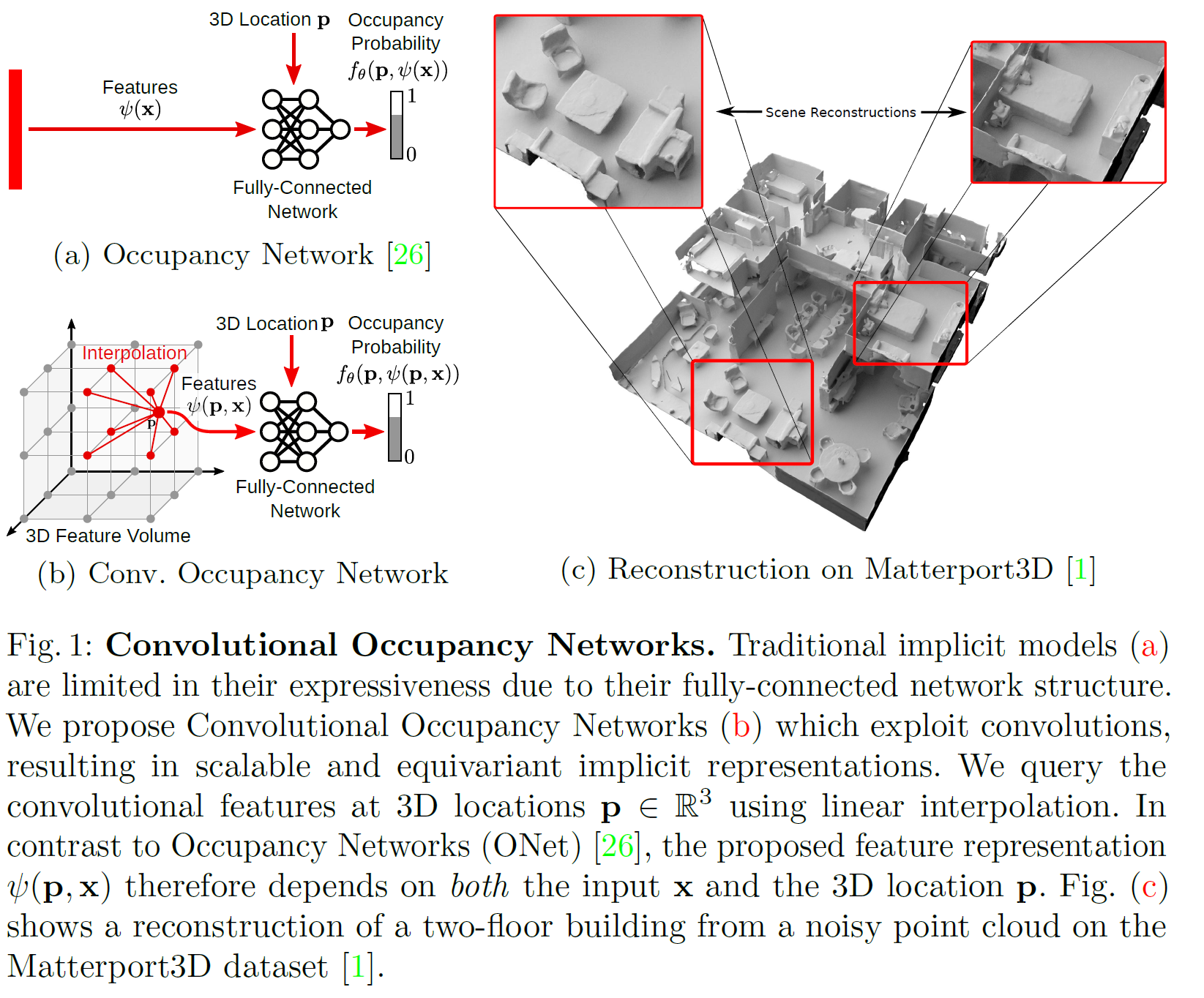
Convolutional Occupancy Networks: 3D 복원의 새로운 패러다임
논문 리뷰
Convolutional Occupancy Networks는 2020년 3월 10일 arXiv에 처음 제출되었으며, 이후 2020년 8월 1일에 수정된 버전이 업로드되었습니다 . 이 논문은 유럽 컴퓨터 비전 학회인 ECCV 2020에서 Spotlight 발표로 선정되었습니다 .(arXiv)
- 제목: Convolutional Occupancy Networks
- 저자: Songyou Peng, Michael Niemeyer, Lars Mescheder, Marc Pollefeys, Andreas Geiger
- 제출일: 2020년 3월 10일
- 수정일: 2020년 8월 1일
- 학회: ECCV 2020 (Spotlight 발표)
- arXiv 링크: https://arxiv.org/abs/2003.04618(arXiv)
간단한 설명
Convolutional Occupancy Networks (CONs)는 3D 형상 복원 및 표현을 위한 딥러닝 기반의 방법으로, 연속적인 3D 공간 상의 점들이 물체 내부(occupancy)인지 아닌지를 예측하는 데 초점을 둡니다. 기존의 Occupancy Networks가 MLP 기반의 구조로 global 정보를 처리하는 데 중점을 두었다면, CONs는 convolutional encoder와 implicit occupancy decoder를 결합하여 지역적인 디테일(local detail)을 효과적으로 캡처할 수 있도록 설계되었습니다.
주요 특징:
-
입력: 노이즈가 있는 포인트 클라우드 또는 저해상도 복셀 표현
-
출력: 연속적인 3D 공간에서의 occupancy field
-
구조: convolutional encoder와 implicit decoder의 결합
-
장점:
- 복잡한 형상의 정밀한 3D 복원 가능
- 대규모 실내 장면에도 확장 가능
- 합성 데이터에서 실제 데이터로의 일반화 능력 우수(ACM Digital Library, ResearchGate)
이 모델은 특히 노이즈가 있는 포인트 클라우드나 저해상도 복셀로부터 복잡한 형상을 정밀하게 복원하는 데 효과적이며, 대규모 실내 장면에도 확장 가능하고, 합성 데이터에서 실제 데이터로의 일반화 능력이 우수하다는 점에서 기존의 Occupancy Networks보다 향상된 성능을 보여줍니다 .(arXiv)
1. Introduction (소개): Convolutional Occupancy Networks: 대규모 3D 복원의 새로운 접근
1.1. 3D 복원이란?
3D 복원은 이미지나 센서 데이터에서 물체나 장면의 3차원 구조를 추정하는 기술로, 자율주행, AR/VR, 로봇 비전 등 다양한 분야에서 핵심 역할을 합니다.
이런 3D 데이터를 효과적으로 표현하려면 다음과 같은 조건을 만족해야 합니다:
- 복잡한 형상과 다양한 위상(topology)을 표현할 수 있어야 하며
- 대규모 장면까지 확장 가능해야 하고
- 지역(local)과 전역(global) 정보를 모두 담을 수 있어야 하며
- 메모리와 계산 효율성도 갖춰야 합니다.
1.2. 기존 3D 표현 방식의 한계
- Volumetric (부피 기반): 해상도가 낮고 메모리 소모가 큼
- Point Cloud (점군): 위상 정보가 없어서 구조 파악이 어려움
- Mesh (메시): 딥러닝으로 직접 예측하기 어렵고 복잡함
최근엔 암시적 표현(implicit representation) 방식이 등장했는데, 이는 3D 공간을 점유 함수(Occupancy Function)나 Signed Distance Function(SDF)으로 연속적으로 표현합니다. 하지만 대부분 단일 객체(single object)에만 적용되고, Fully-connected 네트워크만을 사용해 지역 정보 활용이 어렵고 결과도 부드럽기만 한 경우가 많습니다.
1.3. Convolutional Occupancy Networks의 등장
저자들은 위의 한계를 해결하기 위해 Convolutional Occupancy Networks를 제안합니다. 이 모델은 CNN의 지역성(Locality)과 계층적 정보 표현 능력을 암시적 표현과 결합하여 다음을 실현합니다:
- 복잡한 구조를 정밀하게 표현
- 대규모 실내 장면까지 확장 가능
- 지역 및 전역 정보 통합
- 유사한 구조의 반복 패턴도 잘 처리 (ex. 같은 방 안의 의자 여러 개)
1.4. 주요 기여
- 기존 암시적 3D 복원 방식의 한계를 명확히 분석
- 위치 이동 불변성(Translation Equivariance)을 갖는 유연한 아키텍처 제안
- 객체 수준부터 장면 수준까지 정밀한 3D 복원 가능
- 합성 데이터에서 실제 장면까지, 그리고 새로운 카테고리에도 일반화 가능
코드 및 데이터
이 방식은 특히 정밀한 3D 재구성이 필요한 분야에서 높은 가능성을 보여주며, 실세계 적용성도 뛰어난 것으로 평가받고 있습니다.
2. Related Work (관련 연구): 3D 복원의 다양한 접근 방식
3D 복원 방식은 어떻게 나뉘나요?
학습 기반 3D 복원 기법들은 어떤 방식으로 3D를 표현하느냐(출력 표현 방식)에 따라 나눌 수 있습니다. 아래는 주요 방식들과 그 한계입니다.
2.1. Voxel 기반 (부피 표현)
-
3D 공간을 정육면체 격자(voxel)로 나눠서 표현하는 방식입니다.
-
초기 딥러닝 기반 3D 복원 연구들에서 널리 사용됨
-
문제점:
- 메모리 요구량이 큽니다. (해상도 증가 시 계산량 급증)
- 이를 해결하기 위해 멀티스케일 구조나 옥트리(Octree) 기반 방법이 등장했지만, 여전히 효율성이 제한적입니다.
2.2. Point Cloud 기반 (점군 표현)
-
3D 객체를 많은 점들의 집합으로 표현합니다.
-
장점: 메모리 효율이 좋음
-
단점:
- 점의 수에 제한이 있고
- 위상 정보(예: 연결 관계)를 표현하기 어렵습니다.
2.3. Mesh 기반
-
3D 형태를 정점(vertices)과 면(faces)으로 구성된 메시 형태로 직접 예측합니다.
-
일부 방법은 고정된 템플릿 메시를 변형하는 방식, 일부는 메시를 직접 생성합니다.
-
문제점:
- 셀프 인터섹션(자체 교차) 등으로 watertight하지 않은 결과가 자주 발생합니다.
2.4. 암시적 표현(Implicit Representation)
-
Occupancy Networks나 Signed Distance Fields(SDF) 방식으로, 입력 3D 좌표에 대해 점유 확률 또는 거리값을 예측하는 뉴럴 네트워크입니다.
-
장점:
- 연속적인 3D 표현이 가능
- 복잡한 위상 구조도 자연스럽게 처리 가능
- 고해상도 표현에 유리
-
다양한 응용 분야:
- 이미지 기반 복원
- 텍스처 인코딩
- 4D(시간 포함) 복원
- Primitive 기반 모델링 -> 복잡한 3D 형상을 여러 개의 간단한 도형으로 나눠서 표현하는 방법
-
단점:
- 대부분 단일 객체(single object)에 한정됨
- Fully-connected 네트워크만 사용해 지역 정보 활용이 불가능
- Translation equivariance 같은 귀납적 편향(Inductive bias)도 반영하기 어렵습니다
2.5. 이번 연구 차별점
-
기존의 몇몇 예외적 시도들은 CNN을 활용하긴 했지만, 이미지 도메인(2D)에만 국한되어 카메라 시점에 종속되고, 복원 범위도 단일 객체에 제한됩니다.
-
이번 연구는 물리적 3D 공간 상에서 특징을 모읍니다.
즉, 2D와 3D 컨볼루션을 함께 사용하여, 카메라 시점이나 입력 형식에 독립적인 장면 중심(world-centric) 복원이 가능해집니다.- 결과적으로 실내 전체 장면 단위의 복원까지 확장됩니다 (Fig. 1c 참고).
이와 같은 분석을 바탕으로, Convolutional Occupancy Networks는 기존 한계들을 넘어서며 장면 수준의 정밀한 3D 복원까지 가능하게 하는 새로운 접근이라고 할 수 있습니다.
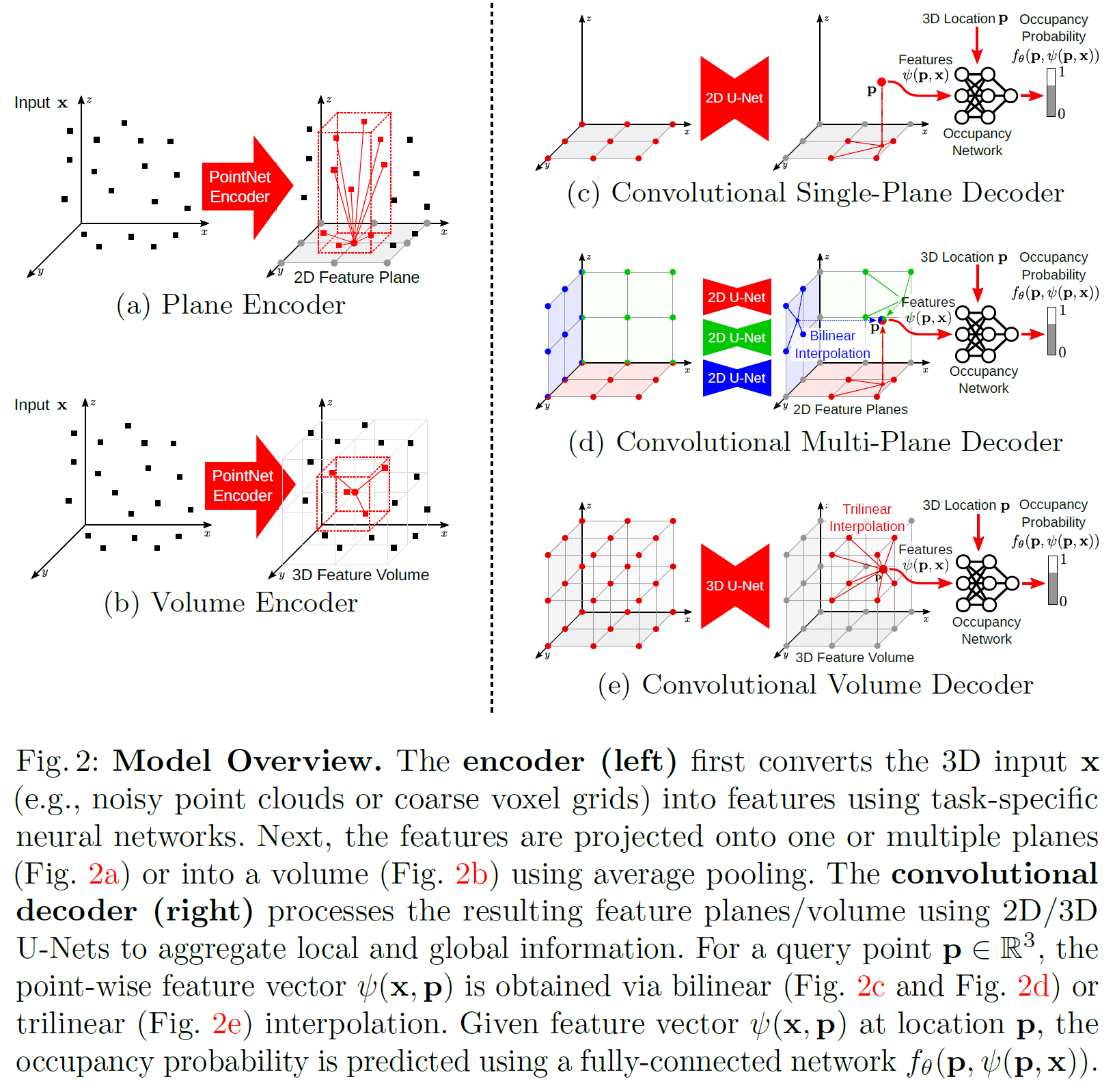
3. Methods (방법): Convolutional Occupancy Networks
이 논문의 목표는 implicit 3D 표현을 더 풍부하고 표현력 있게 만드는 것입니다. 전체 모델 구조는 크게 네 부분으로 구성되어 있으며, Fig. 2에서 그 개요를 확인할 수 있습니다.
전체 흐름
- 입력 데이터(예: 포인트 클라우드)를 받아
- 2D 또는 3D 피처 그리드(feature grid)로 인코딩한 뒤
- CNN으로 이 피처를 처리하고
- 완전연결층(Fully-Connected Network)을 통해 Occupancy 확률을 예측합니다.
이 논문에서는 다음 세 가지 표현 방식을 실험합니다:
- Planar representation (a+c+d)
- Volumetric representation (b+e)
- 이 둘의 조합
구성 요소 소개
- 3.1 Encoder: 입력 데이터를 2D/3D feature grid로 인코딩
- 3.2 Decoder: 이 feature grid를 occupancy 값을 예측할 수 있도록 해석
- 3.3 Occupancy Prediction: 각 3D 포인트가 내부인지 외부인지 확률로 예측
- 3.4 Training: 전체 모델 학습 과정 설명
이 모델은 convolutional 구조의 장점인 지역 정보 통합 및 이동 등가성(translation equivariance)을 잘 활용하여, 기존 implicit 방식보다 더 정교하고 확장성 높은 3D 복원이 가능합니다.
3.1. 인코더 (Encoder): 입력을 3D 피처로 바꾸는 방법
Convolutional Occupancy Networks에서는 다양한 형태의 입력을 받아 처리할 수 있지만, 이 논문에서는 3D 입력(포인트 클라우드나 거친 점유 격자)을 중심으로 세밀한 디테일 복원 능력과 대규모 장면에의 확장성을 보여줍니다.
3.1. 입력 전처리
-
입력 : 노이즈 있는 sparse point cloud 혹은 coarse occupancy grid
-
처리 방법:
- Voxel input: 1-layer 3D CNN
- Point cloud input: 얕은 PointNet + 로컬 풀링
이렇게 얻은 각 포인트/복셀의 feature encoding을 사용하여 두 가지 방식으로 feature를 구성합니다.
3.2. Plane Encoder (평면 인코더)
-
각 입력 포인트를 정사영(orthographic projection)하여 정해진 평면에 투영합니다.
예: XY, YZ, ZX 평면 (좌표축에 정렬된 기준 평면) -
평면은 픽셀 해상도로 구성되며,
동일 픽셀에 투영된 feature는 average pooling으로 집계합니다. -
출력: 크기의 planar feature map
(는 feature 차원) -
모델 구성:
- 단일 ground plane만 사용하는 방식 → 연산 효율 ↑
- 세 개의 평면(XY, YZ, ZX)을 모두 사용하는 방식 → 구조 정보 풍부 ↑
3.3. Volume Encoder (볼륨 인코더)
-
2D 평면은 고해상도 표현은 가능하지만, 3D 구조 정보를 직접 담기엔 부족합니다.
→ 이를 보완하기 위해 3D voxel grid를 사용하는 volumetric 방식도 적용합니다. -
방식은 Plane Encoder와 유사하게, 동일한 voxel cell로 들어간 feature들을 average pooling하여 집계합니다.
-
출력: 크기의 volumetric feature map
→ 해상도는 일반적으로 등 상대적으로 낮음
요약 포인트
- Plane Encoder: 고해상도 표현 가능, 계산 효율적
- Volume Encoder: 더 풍부한 3D 정보 표현 가능
- 두 인코더는 지역 정보 캡처에 초점 → 추후 디코딩에 효과적
3.2 디코더 (Decoder): 로컬+글로벌 정보로 풍부한 표현 만들기
Convolutional Occupancy Networks에서는 인코더로 만든 feature map을 U-Net 기반 디코더로 처리해 더 풍부하고 위치에 강건한 표현으로 바꿉니다.
3.2.1. 사용 네트워크:
2D 및 3D Hourglass(U-Net) 구조
- 다운샘플링 → 업샘플링 + skip connection
- 로컬 정보와 글로벌 정보를 함께 처리 가능
특징:
- Translation equivariance (이동 등변성) 확보
→ 입력이 공간적으로 이동해도 출력 패턴은 동일하게 이동 - Sparse input 보완(Inpainting) 가능
→ 결측치가 있어도 전체적인 구조를 추론 가능
3.2.2. 디코더 종류별 구성
| 디코더 | 설명 | 사용 U-Net |
|---|---|---|
| 🟩 Single-plane decoder (Fig. 2c) | 단일 ground plane feature 사용 | 2D U-Net |
| 🟦 Multi-plane decoder (Fig. 2d) | 3개 평면(XY, YZ, ZX) feature 각각 처리 | 2D U-Net (weight 공유) |
| 🟥 Volume decoder (Fig. 2e) | 3D volume feature 사용 | 3D U-Net |
각 U-Net의 깊이는 해당 평면/볼륨의 전체 크기만큼 수용영역(receptive field)이 되도록 설계됨
핵심 요약
- U-Net 구조를 통해 입력의 부분 정보로부터 전체 구조 추론 가능
- 이동에 강한 표현(translation equivariant)을 만들어 구조적인 reasoning 가능
- 2D와 3D feature를 각각 적절하게 처리하여 다양한 입력 구조에 유연하게 대응 가능
3.3 Occupancy Prediction: 3D 공간에서 점이 물체 안인지 예측하기
목표:
어떤 3차원 점 p가 물체 안에 포함되어 있는지 여부(occupancy)를 확률(0~1)로 예측
과정 요약:
-
특징값 추출 (Feature Querying)
점 p의 위치에서 feature 값을 얻기 위해 다음 방식 사용:디코더 타입 방법 설명 🟩 Single-plane p를 평면에 직교 투사 → bilinear interpolation 평면상의 위치로 매끄럽게 feature 추출 🟦 Multi-plane 3개 평면 모두 투사 → 각 feature를 합산 방향별 정보 결합 🟥 Volume p를 3D grid 상에 매핑 → trilinear interpolation 볼륨 기반 feature 추출 -
Occupancy Network 통과
-
추출된 feature 와 위치 를 함께 작은 **MLP(다층 퍼셉트론)**에 입력
-
이 네트워크는 점 p의 occupancy 확률을 출력:
-
핵심 포인트:
- CNN + interpolation을 통해 임의의 3D 점에서도 연속적인 feature 값을 얻을 수 있음
- 이를 기반으로 Implicit surface (연속적인 표면) 예측이 가능해짐
- 다양한 디코딩 구조에 맞게 feature를 유연하게 쿼리하는 방식이 성능과 확장성에 핵심 역할
3.4 Training and Inference
3.4.1. 훈련 (Training)
-
입력: 3D 공간 안에서 query point 를 균일하게 샘플링
-
출력: 각 의 occupancy 확률 예측
-
손실 함수: Binary Cross Entropy (BCE) Loss 사용
- : ground truth occupancy (0 또는 1)
- : 모델이 예측한 확률
-
최적화:
- Optimizer: Adam
- Learning rate:
- Framework: PyTorch
3.4.2. 추론 (Inference)
-
출력 형식: 3D mesh
-
방법: Multiresolution IsoSurface Extraction (MISE) 사용
- 여러 해상도에서 occupancy를 평가하며 최종 mesh 생성
-
확장성:
- 모델은 fully convolutional 구조이므로
- 큰 장면(예: 아파트 전체)도 슬라이딩 윈도우 방식으로 처리 가능
핵심요약:
모델은 3D 공간에서 포인트들을 샘플링해 occupancy를 예측하며, BCE loss로 학습하고 MISE 기법을 통해 mesh를 생성한다. fully-convolutional 구조 덕분에 넓은 공간도 슬라이딩 윈도우 방식으로 추론 가능하다.
4 Experiments (실험)
4.1 Object-Level Reconstruction 요약
연구에서는 ShapeNet 데이터셋을 기반으로 단일 객체 재구성(single object reconstruction) 실험을 수행하였으며, 두 가지 3D 입력 유형을 사용했습니다:
- 노이즈가 있는 포인트 클라우드: 메쉬에서 3000개의 포인트를 샘플링하고, 평균 0, 표준편차 0.05의 가우시안 노이즈를 추가.
- 저해상도 복셀: 32³ 해상도의 복셀 데이터를 사용.
학습 시 감독(supervision)을 위한 쿼리 포인트 수는 포인트 클라우드의 경우 2048개, 복셀의 경우 1024개를 사용했습니다. 각 입력에 따라 다른 인코더 구조를 사용하며, 배치 사이즈는 각각 32와 64로 설정했습니다.
4.1.1. 포인트 클라우드 재구성 결과
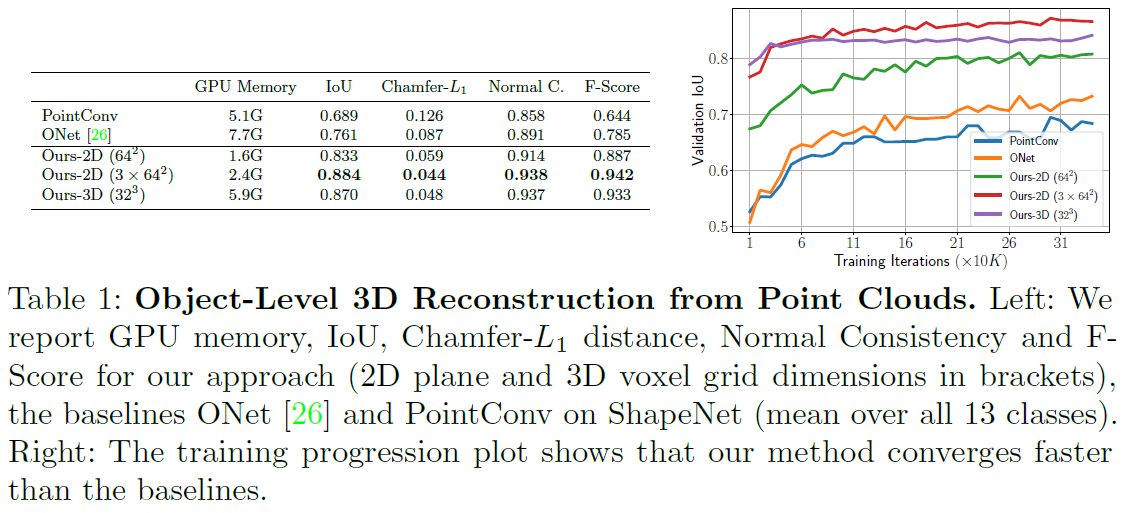
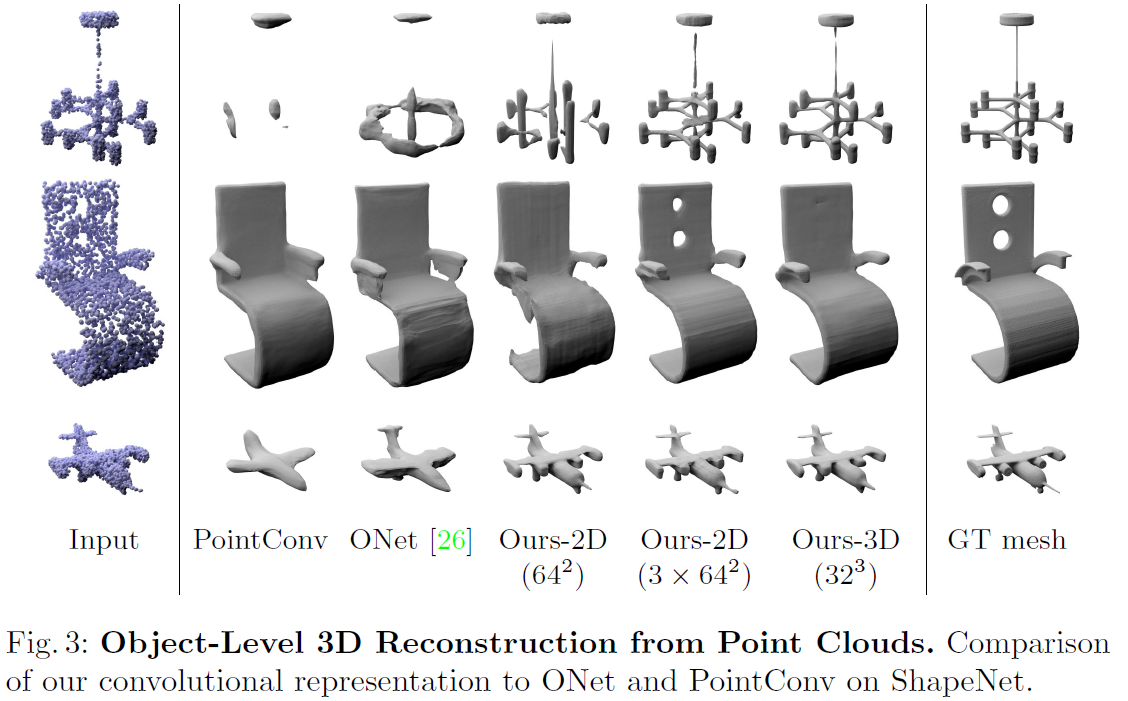
- Table 1과 Fig. 3에서 정량적, 정성적 결과를 확인할 수 있음.
- 기존 방법(PointConv 등) 대비 모든 지표에서 유사하거나 더 나은 성능을 보임.
- 학습 초기부터 높은 IoU를 달성하며, 이는 컨볼루션과 로컬 피처 활용이 재구성 정확도 및 효율성 측면에서 효과적임을 입증.
- 3D 데이터를 평면이나 볼륨에 투사한 후 CNN을 사용하는 방식이, 포인트 클라우드에서 직접 피처를 추출하는 방식보다 더 효과적임.
- 3D 볼륨을 고해상도(64²) 3개의 평면으로 분해하는 방식은 성능 향상과 함께 GPU 메모리 사용량을 줄임.
4.1.2. 복셀 슈퍼 해상도 결과
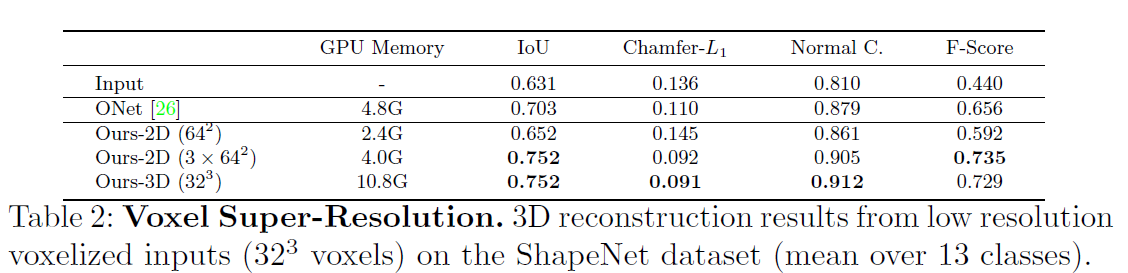
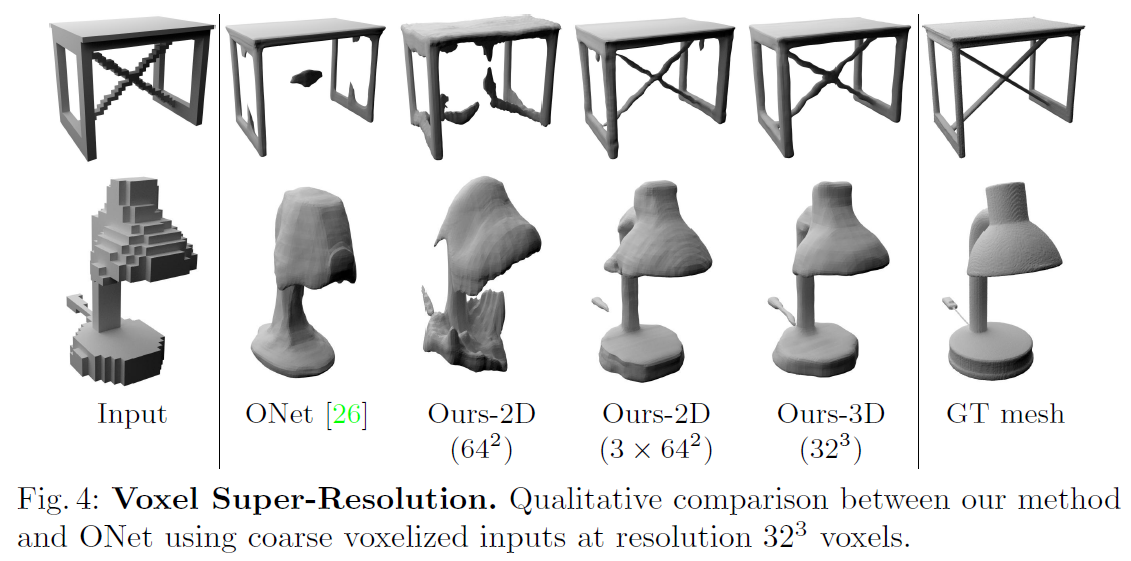
- Table 2와 Fig. 4에서 결과 제시.
- 3평면 방식은 볼륨 기반 방식과 유사한 성능을 내면서 GPU 메모리 사용량은 37% 수준.
- 단일 평면 방식은 이 작업에서 실패함. 이는 복셀 입력의 모호성을 해소하기에는 단일 평면이 부족하기 때문으로 추정.
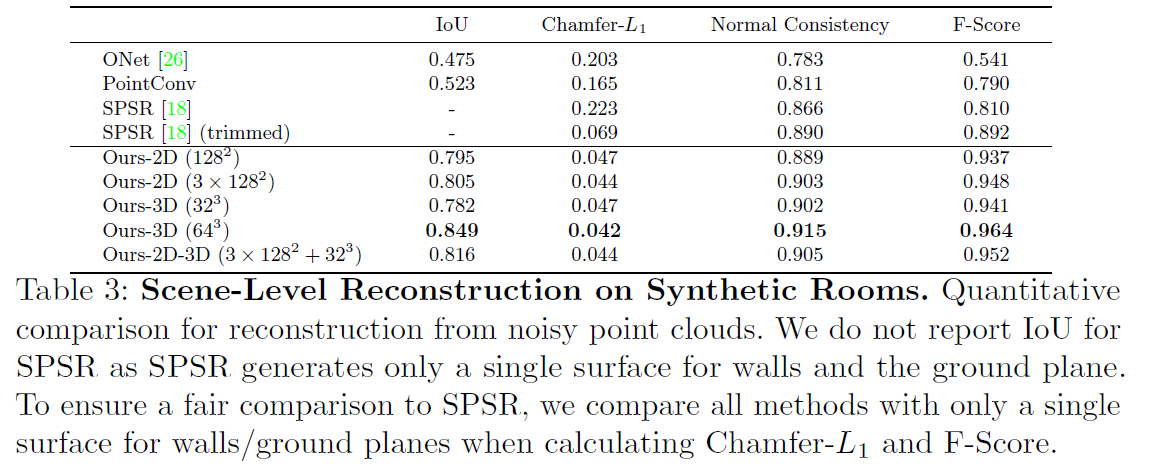
4.2 Scene-Level Reconstruction 요약

연구팀은 제안한 방법이 **더 큰 장면(scene)**에도 확장 가능함을 평가하기 위해, 합성된 실내 장면 데이터셋을 사용해 포인트 클라우드 기반 3D 재구성을 수행했습니다.
-
입력 데이터:
- 10,000개의 포인트를 균일 샘플링하고 표준편차 0.05의 가우시안 노이즈를 추가.
- 학습 시 쿼리 포인트는 2048개 샘플링 (객체 수준 실험과 동일).
-
사용된 방식 및 해상도:
- 평면 기반 방법: 해상도 128²
- 볼륨 기반 방법: 32³ 및 64³ 해상도 실험
- 또한, 평면+볼륨 통합 방식도 실험 (두 방식이 상호 보완적이라는 가설 검증)
결과 요약 (Table 3 및 Fig. 5 참고):
-
제안한 모든 방법이 장면의 기하학적 디테일을 잘 복원하고 부드러운 표면을 생성함.
-
비교 방법 성능:
- ONet, PointConv: 낮은 정확도
- SPSR: 표면이 노이즈가 많음
-
각 방식의 특성:
- 고해상도 평면 기반 특징: 정밀 디테일을 잘 포착하지만 노이즈에 민감함
- 저해상도 볼륨 기반 특징: 노이즈에 강하지만 디테일이 덜함
-
평면 + 볼륨 결합 방식: 개별적으로 사용하는 것보다 더 나은 성능을 보임 → 두 방식이 상호 보완적임을 입증.
-
최고 성능: 64³ 고해상도 볼륨 특징을 사용할 때 달성됨.
4.3 Ablation Study
본 절에서는 합성 실내 장면 데이터셋을 이용해 다음 두 가지 요소의 영향을 분석했습니다:
- 피처 집계 전략(feature aggregation strategy)
- 피처 보간 방식(feature interpolation strategy)
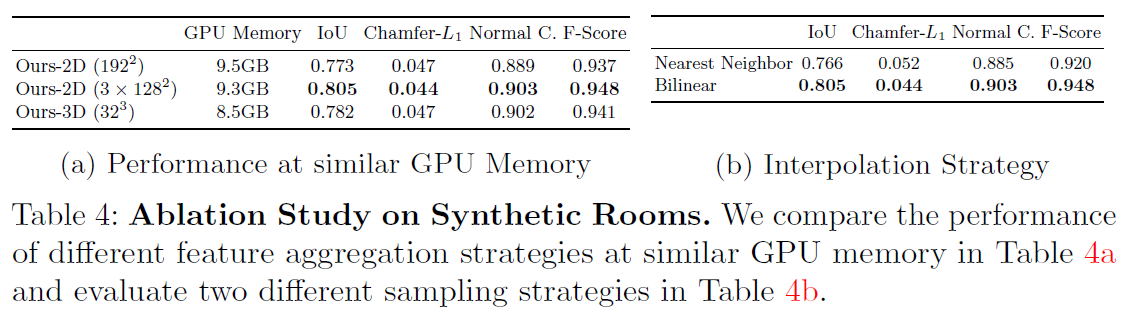
4.3.1. 유사한 GPU 메모리 사용 시의 성능 비교
-
(Table 4a 참조)
-
여러 피처 집계 방식 비교 결과:
- 멀티-플레인(multi-plane) 방식이 싱글-플레인(single-plane) 및 볼륨 기반(volume) 방식보다 약간 더 우수한 성능을 보임.
- 싱글-플레인 방식의 해상도를 높여도 성능이 뚜렷하게 향상되지는 않음 → 단순히 해상도를 높인다고 해서 항상 더 좋은 성능을 보장하지 않음을 의미.
4.3.2. 피처 보간 방식 비교
-
(Table 4b 참조)
-
멀티-플레인 방식에서 두 가지 보간 기법을 비교:
- Nearest Neighbor vs. Bilinear Interpolation
-
결과:
- Bilinear Interpolation이 성능 면에서 확실한 이점을 보여줌.
4.4 실제 데이터셋에서의 포인트 클라우드 재구성 요약
이번 실험에서는 제안한 방법의 일반화 성능과 대규모 장면에 대한 확장성을 평가하기 위해, 합성 데이터로 학습한 모델을 실제 세계 데이터셋에 적용했습니다.
실험 설정:
-
학습 데이터: 합성 실내 장면 데이터셋
-
평가 데이터:
- ScanNet v2
- Matterport3D
-
입력: 메쉬에서 추출한 10,000개의 포인트 클라우드
4.4.1. ScanNet v2 결과
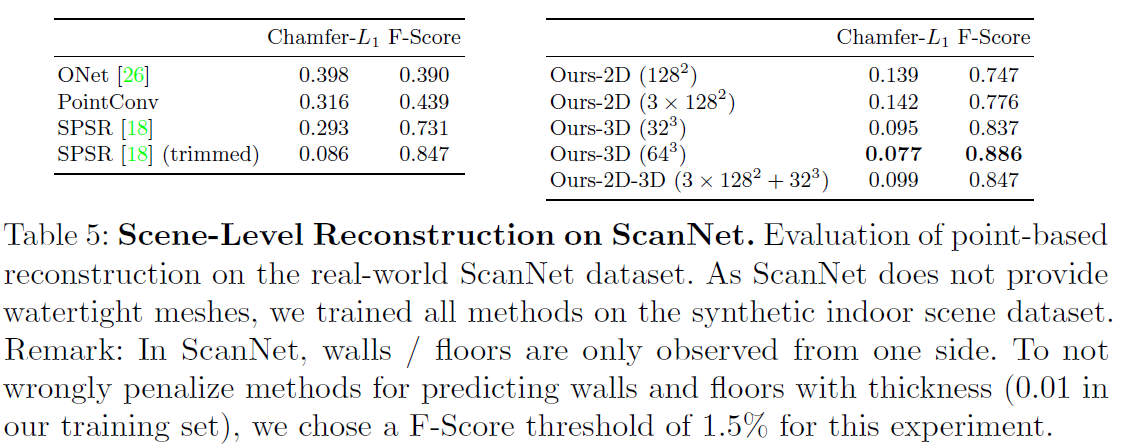

- (Table 5, Fig. 6 참조)
- 볼륨 기반 모델이 가장 좋은 성능을 보임 → 평면 기반 모델은 도메인 차이(domain shift)에 취약
- 3D CNN 기반 구조는 인접 이웃의 피처를 통합하여 노이즈에 강하고 결과가 부드러움
- 모든 변형이 기존 학습 기반 기법들보다 의미 있게 높은 성능을 달성
- 정성적 비교: 다양한 스케일에서 기하학적 디테일을 매끄럽게 재구성
- Screened PSR는 결과는 괜찮지만, 메쉬를 과도하게 닫는 경향이 있고 트리밍 파라미터 조정이 필요
- 제안한 방법은 추가 하이퍼파라미터 없이 안정적인 결과를 생성
4.4.2 Matterport3D 결과
-
대규모 장면(여러 방과 층 포함)에 대한 확장성(scalability) 평가
-
입력 포인트 클라우드의 오버랩된 슬라이딩 윈도우 방식으로 처리 가능한 완전한 3D 합성곱 모델(full convolutional 3D model) 사용
- 오버랩 크기는 수용 영역(receptive field) 기반으로 설정하여 정확한 결과 보장
-
(Fig. 1 참조) 방 내부의 디테일을 잘 복원하면서 전체 공간 구조(room layout)도 잘 유지
-
Matterport3D의 지오메트리 및 포인트 분포가 학습 데이터와 매우 다름에도 불구하고,
제안한 모델은 새로운 클래스, 방 구조, 센서 특성까지도 성공적으로 일반화함
요약하자면, 제안된 방식은 합성 데이터로 학습한 후 실제 장면에 일반화 가능하며, 복잡하고 큰 환경에도 확장 가능함을 입증했습니다.
5. Conclusion (결론)
이 논문에서는 Convolutional Occupancy Networks라는 새로운 형태의 3D 표현 방식을 제안했습니다.
이는 합성곱 신경망(CNN)의 표현력과 암시적(implicit) 표현의 유연성을 결합한 방식입니다.
5.1. 주요 기여 및 발견
-
2D vs. 3D 피처 표현의 장단점을 분석하고,
CNN 기반의 피처 처리가 새로운 클래스, 방 구조, 대규모 장면에 잘 일반화됨을 확인 -
3-플레인(3-plane) 모델:
- 메모리 효율적
- 합성 장면에서 우수한 성능
- 더 큰 해상도의 피처 표현이 가능
-
볼륨 기반 모델:
- 실제 환경(real-world)에서 가장 높은 성능
- 다만 더 많은 메모리 소비가 필요
5.2. 한계점
- 모델은 회전 등변성(rotation equivariance)을 가지지 않으며,
정해진 복셀 크기의 배수로 된 평행 이동에 대해서만 등변성(translation equivariance)을 가짐 - 합성 데이터와 실제 데이터 간에는 여전히 성능 차이(gap)가 존재함
5.3. 향후 연구 방향
- 본 연구는 학습 기반 3D 재구성에 중점을 두었지만,
향후에는 본 표현 방식을 암시적 외형 표현(implicit appearance modeling),
4D 재구성(시간에 따른 3D) 등 다른 도메인에도 확장할 계획임
