U-Net: Convolutional Networks for Biomedical Image Segmentation 리뷰
논문 리뷰
1. 소개 (Introduction)
이 논문의 Introduction 부분은 "U-Net"이라는 아키텍처가 등장하게 된 배경과 기존 접근 방식의 한계, 그리고 U-Net의 주요 특징과 장점을 소개하고 있습니다.
1. 배경
- 최근 몇 년간, 딥 컨볼루션 신경망(DCNN)이 이미지 인식 분야에서 큰 성공을 거둠.
- 특히 Krizhevsky et al. (2012)가 ImageNet 대회에서 큰 성과를 낸 이후로, 더 깊고 큰 네트워크들이 개발됨.
2. 기존 접근 방식의 한계
-
일반적으로 CNN은 분류(classification)에 사용되며, 한 이미지에 대해 하나의 라벨만 예측함.
-
하지만, 의학 영상 분석에서는 픽셀 단위의 분할(segmentation)이 필요함.
-
이를 위해 Ciresan et al. (2012)는 슬라이딩 윈도우 방식으로 픽셀 주변의 작은 영역(patch)을 입력으로 주고, 픽셀마다 라벨을 예측함.
-
장점: 지역 정보(localization)를 잘 반영할 수 있음.
-
단점:
- 느림 (패치마다 개별 예측)
- 패치 중첩으로 인한 중복 계산
- 작은 패치는 문맥(context)을 적게 보고, 큰 패치는 위치 정확도가 떨어짐
-
3. U-Net의 핵심 아이디어
-
Fully Convolutional Network (FCN) 구조를 기반으로 발전시킴.
-
FCN의 장점을 유지하면서, 더 정밀한 segmentation을 가능하게 하기 위해 구조를 변경함.
-
주요 아이디어:
- 다운샘플링(Contracting path) + 업샘플링(Expansive path)으로 이루어진 U자형 구조
- 업샘플링 과정에서는 풀링 대신 업샘플링 사용해 해상도를 복구
- 고해상도 특징과 업샘플된 출력을 결합(concatenate)하여 더욱 정밀한 출력 생성 가능
- 업샘플링 경로에서도 많은 채널을 사용해 문맥 정보 유지
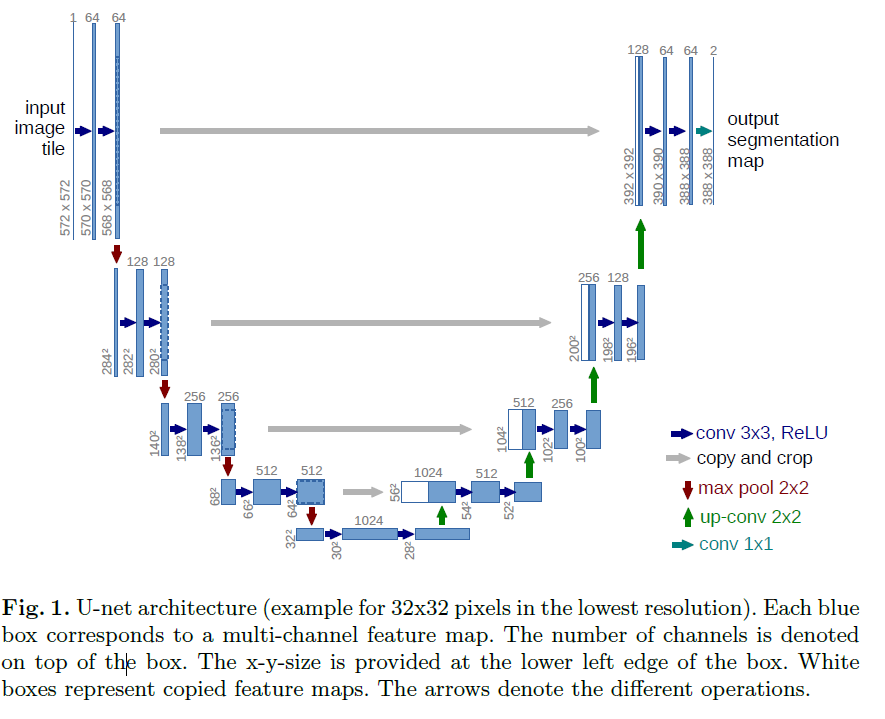
4. 추가적인 기술 요소
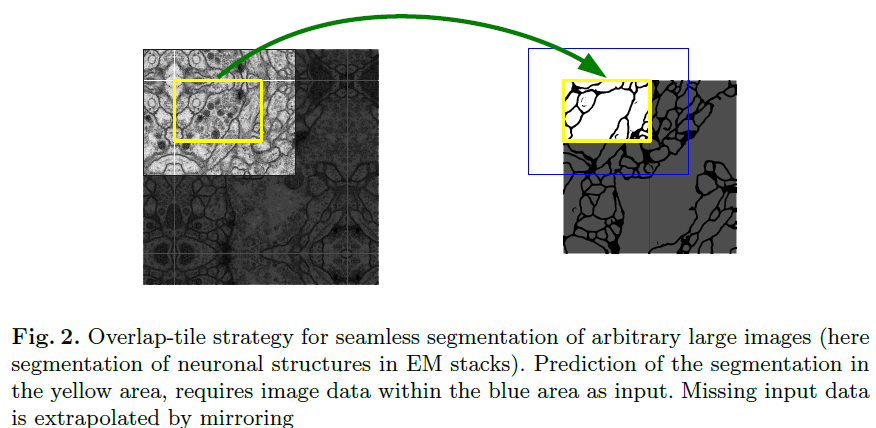
- 패딩 없이(valid convolution) 연산하여, 입력 이미지의 모든 문맥이 확보된 위치만 예측함.
- 타일 방식(overlap-tile strategy)으로 큰 이미지를 잘라 처리하여 GPU 메모리 제약 해결 (Fig. 2 참고)
- 거울 반사(mirroring)로 경계 부분의 부족한 문맥 보완
5. 데이터 부족 문제 해결
- 의료 영상에서 학습 데이터가 부족하므로, elastic deformation 등 강력한 데이터 증강(data augmentation) 사용
- 이렇게 하면 네트워크가 변형에 대해 불변성(invariance)을 학습할 수 있음
6. 접촉된 객체 분리
-
동일한 클래스의 객체들이 서로 붙어 있을 경우 분리가 어려움
-
이를 해결하기 위해 가중치 손실 함수(weighted loss function) 사용:
- 서로 닿아있는 객체 사이의 배경 라벨에 더 큰 가중치를 부여
7. 성능
- 제안한 네트워크는 다양한 생의학 영상 분할 문제에 적용 가능
- EM 이미지의 신경 구조 분할(EM stacks) 및
- 광학 현미경 이미지의 세포 분할에서 기존 방법보다 월등히 뛰어난 성능을 기록함
- 특히, ISBI 2015 cell tracking challenge에서 가장 어려운 두 개의 2D 데이터셋에서 큰 차이로 1등을 함
2. 네트워크 아키텍처 (Network Architecture)
U-Net은 크게 두 부분으로 구성된 구조를 가지고 있습니다:
1. 수축 경로 (Contracting Path) – 왼쪽
-
일반적인 CNN 구조를 따름.
-
구성 요소:
- 3×3 컨볼루션 × 2회 (패딩 없음 → 가장자리 픽셀 손실 발생)
- 각각의 컨볼루션 뒤에 ReLU 활성화 함수
- 2×2 맥스 풀링 (stride=2) 을 통해 다운샘플링
-
다운샘플링 단계마다 채널 수를 두 배로 증가시킴.
이 경로는 이미지의 특징 추출과 압축을 담당합니다.
2. 확장 경로 (Expansive Path) – 오른쪽
-
추출된 특성을 이용하여 해상도를 점점 복원하는 구조.
-
구성 요소:
-
업샘플링 (크기 복원)
-
2×2 업컨볼루션 (transposed convolution) → 채널 수를 절반으로 감소
-
같은 수준의 수축 경로에서 가져온 피처맵과 결합(concatenation)
단, 크롭(cropping) 필요 (컨볼루션 시 생긴 테두리 손실 때문)
-
이어서 3×3 컨볼루션 × 2회 + 각각 ReLU
-
이 경로는 위치 정보 복원 및 정밀한 세분화를 담당합니다.
3. 최종 출력층 (Final Layer)
- 1×1 컨볼루션을 사용하여, 각 위치의 피처 벡터(64채널)를 원하는 클래스 수로 매핑
4. 전체 구조
- 총 23개의 컨볼루션 레이어로 구성
5. 타일 분할(Tiling) 처리 관련
-
입력 타일의 크기를 잘 선택해야 함:
- 이유: 모든 2×2 맥스 풀링 연산이 짝수 크기의 feature map에 적용되어야
- 그래야 출력 segmentation map을 매끄럽게 이어 붙일 수 있음 (seamless tiling)
6. 핵심 요약
| 구간 | 구성 요소 | 기능 |
|---|---|---|
| Contracting path | 3×3 conv ×2, ReLU, 2×2 max pooling | 특징 추출과 압축 |
| Expansive path | 업샘플링, 2×2 up-conv, concat, 3×3 conv ×2, ReLU | 위치 복원과 세분화 |
| 출력층 | 1×1 conv | 클래스별 분류 결과 출력 |
3. 학습 (Training)
3.1. 입력 방식 및 SGD 세팅
- 입력 이미지와 대응되는 세그멘테이션 맵을 사용해 Stochastic Gradient Descent (SGD) 방식으로 학습합니다.
- 논문은 Caffe 프레임워크의 SGD 구현을 사용했습니다.
Unpadded Convolution의 영향
- Unpadded (valid) convolution은 입력보다 출력 크기를 줄이므로, 경계 픽셀이 손실됩니다.
- 따라서 출력 이미지는 항상 입력보다 작습니다.
3.2. 메모리 효율을 위한 설정
- GPU 메모리를 최대한 활용하기 위해, 한 번에 큰 이미지를 처리하는 큰 타일을 사용하고, 대신 배치 크기는 1로 설정합니다.
- 이렇게 배치가 작을 때 학습이 불안정해지지 않도록 모멘텀(momentum)을 0.99로 높게 설정합니다.
→ 과거 gradient를 많이 반영하여 안정적으로 학습되도록 조정합니다.
3.3. 손실 함수: 픽셀 단위 softmax + cross-entropy
-
마지막 출력(feature map)에 대해 픽셀별로 softmax를 적용하여 각 픽셀이 어떤 클래스일 확률인지 계산합니다:
- : 위치 에서의 k번째 클래스 채널의 activation
- : 그 픽셀이 k 클래스일 확률
-
이 확률과 정답 클래스 간의 차이를 cross-entropy loss로 계산:
- : 위치 에서의 정답 클래스
- : 각 픽셀의 중요도를 조절하는 가중치 맵 (weight map)
3.4. Weight map의 두 가지 목적
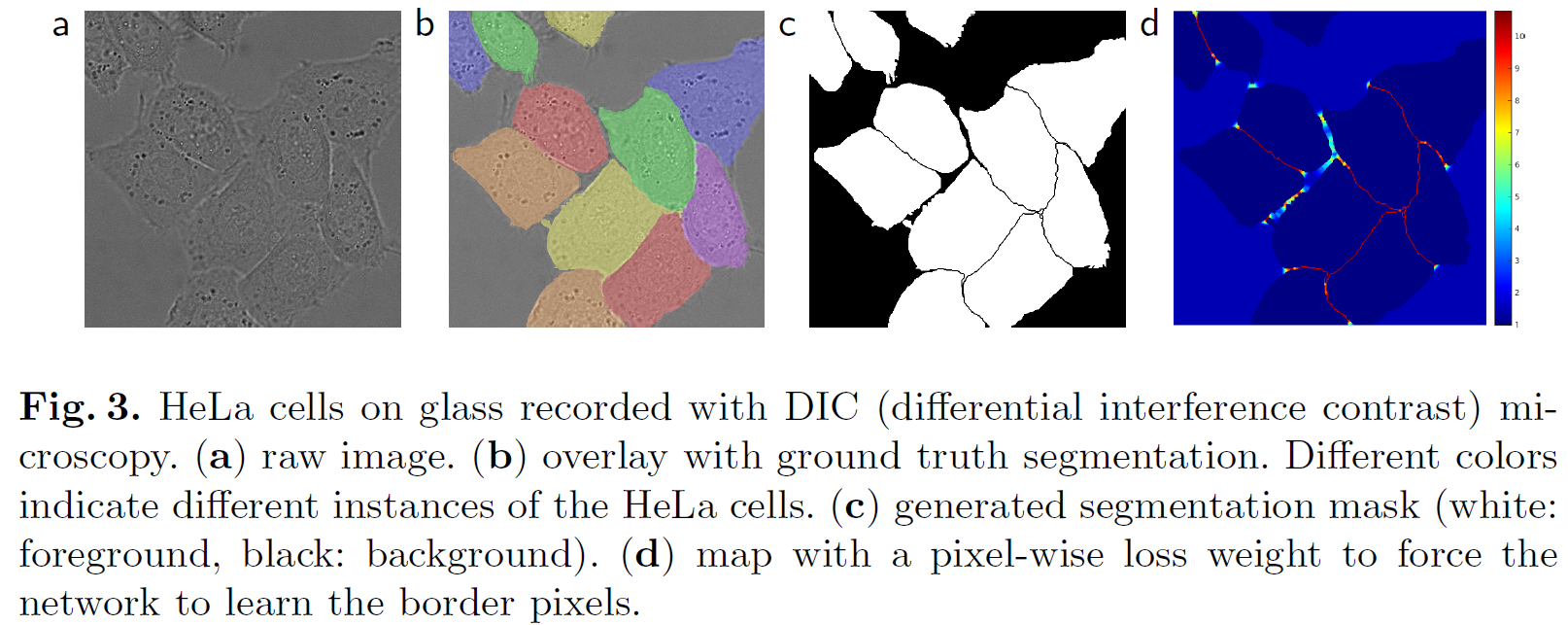
-
클래스 불균형 보정
- 특정 클래스(예: 배경)가 지나치게 많을 수 있으므로, 드물게 나타나는 클래스 픽셀에 더 큰 가중치를 부여.
-
붙어 있는 물체(셀 등) 분리
- touching cells를 구분하기 위해 경계선 쪽 픽셀에 큰 가중치를 부여합니다. (Fig. 3c and d 참고)
- 이는 morphological operations로 계산된 경계를 기준으로 생성됩니다.
Weight map 공식
- : 클래스 불균형을 보정하기 위한 기본 가중치
- : 가장 가까운 셀의 경계까지 거리
- : 두 번째로 가까운 셀의 경계까지 거리
- : 실험적으로 설정된 하이퍼파라미터
이 함수는 두 셀 사이의 픽셀(x)에 대해 거리 기반으로 가중치를 높여서 분리 경계 학습을 강조합니다.
3.5. 파라미터 초기화
-
깊은 네트워크는 파라미터 초기화가 매우 중요합니다.
-
적절하지 않으면 어떤 노드는 너무 크게 활성화되고, 어떤 노드는 아예 죽어버릴 수 있습니다.
-
He 초기화 방식을 사용:
- : 한 뉴런으로 들어오는 입력 수
(예: 3×3 커널, 64채널이면 )
- : 한 뉴런으로 들어오는 입력 수
→ 이 초기화 방식은 각 layer의 출력 분산을 일정하게 유지해 학습 안정성을 높여줍니다.
3.6. 요약
| 항목 | 설명 |
|---|---|
| 학습 방식 | SGD + high momentum (0.99) |
| 입력 방식 | 큰 타일, 작은 배치 (batch=1) |
| 손실 함수 | 픽셀 단위 softmax + cross-entropy |
| weight map | 클래스 불균형 보정 + touching cell 분리 강조 |
| 초기화 | He 초기화 () |
4. Experiments (실험)
U-Net 모델의 성능을 실제로 검증하기 위해, 논문에서는 세 가지 **이미지 분할 과제(Segmentation Tasks)**에 적용해 실험을 진행했습니다.
4.1. 실험 1: 전자현미경 이미지에서 신경세포 구조 분할 (Neuronal Segmentation in EM Images)
-
데이터: ISBI 2012 EM segmentation challenge의 데이터셋 사용
- Drosophila (초파리) 유충의 척수(Ventral Nerve Cord) 전자현미경 이미지
- 크기: 512×512 픽셀
- 총 30장의 학습 이미지 제공
- 각 이미지에 세포/세포막의 정답 분할 레이블이 주어짐
-
테스트 세트: 공개되어 있지만, 정답 라벨은 비공개
-
예측 결과(세포막 확률 맵)를 제출해야 성능을 평가받을 수 있음
-
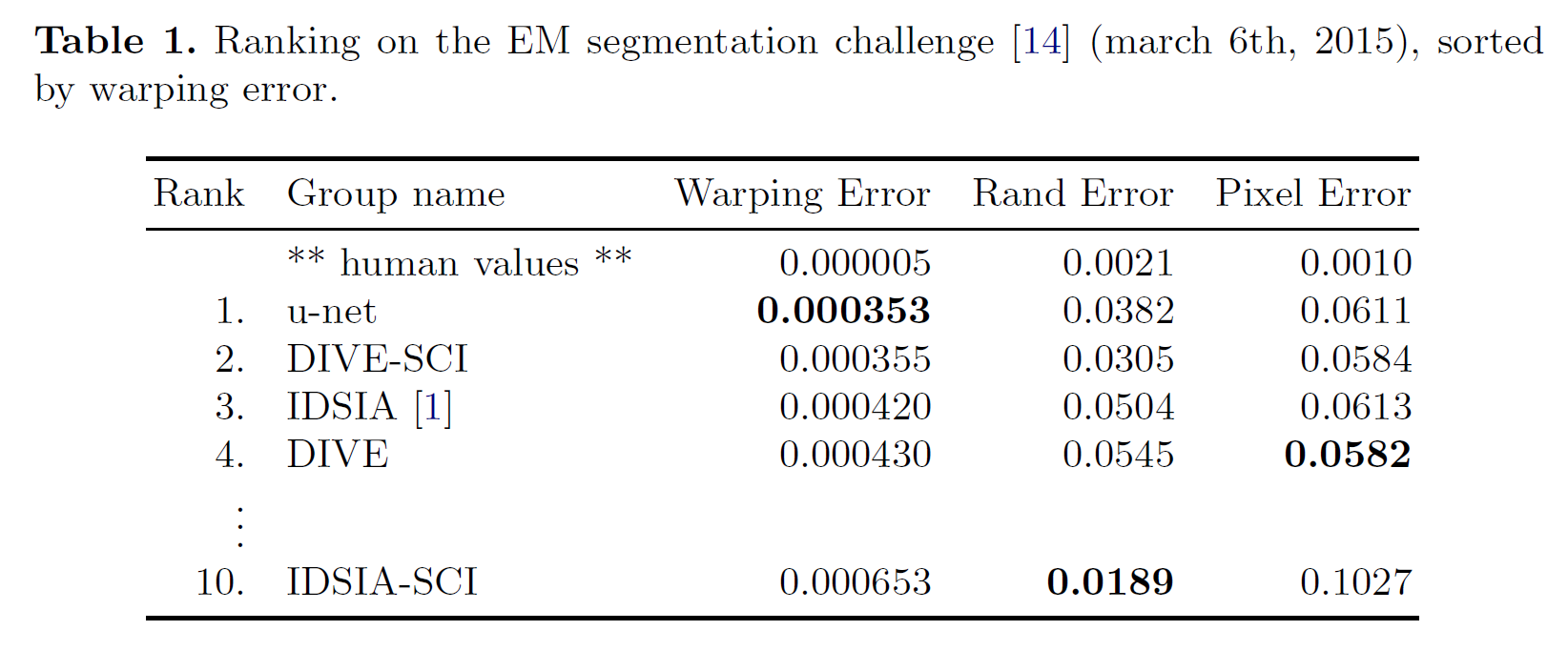
평가 지표:
- Warping error: 경계 왜곡 정도
- Rand error: 군집 간 분할 정확도
- Pixel error: 픽셀 단위 정확도
-
-
결과:
-
입력 이미지를 7방향으로 회전시킨 후 평균을 낸 결과를 사용
-
전처리나 후처리 없이도 매우 좋은 성능 달성:
- Warping error: 0.0003529 (당시 최고 성능)
- Rand error: 0.0382
-
-
비교:
-
이전 최고 모델 (Sliding-window CNN by Ciresan et al.):
- Warping error: 0.000420
- Rand error: 0.0504
-
일부 다른 모델들이 Rand error에서는 더 낮은 값 기록했지만, 후처리를 많이 한 경우임
-
4.2. 실험 2: 위상차 현미경(PhC)에서 U373 암세포 분할
-
데이터: ISBI 2014/2015 Cell Tracking Challenge – “PhC-U373”
- U373 암세포를 위상차 현미경으로 촬영
- 총 35장의 학습 이미지
-
결과:
-
평균 IOU (Intersection over Union): 92%
- 두 번째로 좋은 알고리즘은 83%
→ U-Net이 매우 뛰어난 정확도를 보임
- 두 번째로 좋은 알고리즘은 83%
-

4.3. 실험 3: 간섭 대비 현미경(DIC)에서 HeLa 세포 분할
-
데이터: ISBI Challenge – “DIC-HeLa”
- DIC (차등간섭대비현미경) 이미지
- HeLa 세포 20장의 학습 이미지
-
결과:
-
평균 IOU: 77.5%
- 두 번째로 좋은 알고리즘은 46%
→ U-Net이 압도적인 성능 차이를 보여줌
- 두 번째로 좋은 알고리즘은 46%
-
4.4. 요약 정리
| 실험 과제 | 데이터 | 성능 | 비교 결과 |
|---|---|---|---|
| 신경세포 분할 (EM) | Drosophila EM 이미지 | Warping error 0.00035, Rand error 0.0382 | 기존 모델보다 정확도 우수 |
| 암세포 분할 (PhC-U373) | 위상차 현미경 | IOU 92% | 2등 모델: 83% |
| HeLa 세포 분할 (DIC-HeLa) | DIC 현미경 | IOU 77.5% | 2등 모델: 46% |
핵심 포인트
- U-Net은 다양한 생물학 이미지에서 매우 우수한 분할 성능을 보였고,
- 복잡한 후처리 없이도 순수 모델 성능만으로 좋은 결과를 냈습니다.
- 특히 작은 학습 데이터셋에도 강한 성능을 보여 생물학적 이미지 분석에서 매우 유용한 모델로 인정받았습니다.
5. Conclusion (결론)
-
U-Net 아키텍처는 다양한 종류의 생물 의학적 이미지 분할(Biomedical Image Segmentation) 과제에서 매우 뛰어난 성능을 보여주었다.
-
특히, 탄성 변형(elastic deformation) 기반의 데이터 증강(data augmentation) 기법 덕분에, 소수의 주석(annotated) 이미지만으로도 충분히 학습이 가능하다.
-
학습 시간도 비교적 짧음:
- 약 10시간 (GPU: Nvidia Titan, 6GB 메모리 기준)
-
논문에서는 Caffe 기반 구현 코드와 학습된 네트워크도 공개함.
-
연구자들은 U-Net 아키텍처가 앞으로 다양한 이미지 분할 과제에 손쉽게 활용될 수 있을 것이라고 확신함.
핵심 내용
- U-Net은 적은 데이터만으로도 효과적으로 학습할 수 있는 이미지 분할 모델입니다.
- 탄성 변형을 활용한 데이터 증강 덕분에 데이터가 적어도 문제 없음.
- 학습 속도도 빠르고, GPU 메모리도 크게 부담되지 않음.
- 간단히 사용할 수 있는 구조 + 강력한 성능 → 다양한 분야에 널리 응용 가능.
- 코드도 공개되어 있어 누구나 쉽게 사용해볼 수 있도록 했음.
핵심 포인트 요약
| 항목 | 내용 |
|---|---|
| 성능 | 다양한 생물의학 분할 문제에서 우수 |
| 데이터 효율성 | 적은 양의 주석 데이터로도 학습 가능 |
| 학습 시간 | 10시간 (NVIDIA Titan 6GB 기준) |
| 도구 제공 | Caffe 구현 및 학습된 모델 제공 |
| 응용 가능성 | 다양한 분야로 확장 가능 |
