
딥러닝 모델, 특히 트랜스포머(Transformer) 구조를 깊이 파고들다 보면 반드시 마주치는 산이 하나 있습니다. 바로 Cross-attention(교차 어텐션)입니다.
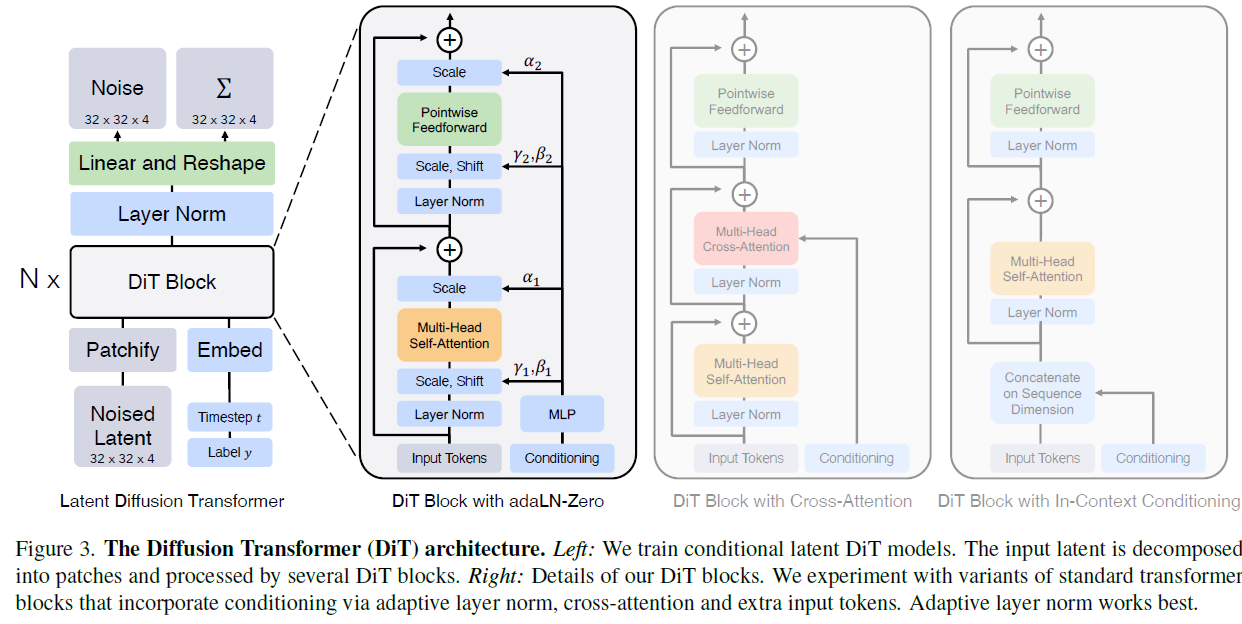
많은 분들이 Self-attention(셀프 어텐션)은 직관적으로 이해하시지만, 두 개의 서로 다른 정보가 만나는 Cross-attention 부분에서는 헷갈려하시는 경우가 많습니다. 특히 최근 이미지 생성에 쓰이는 DiT(Diffusion Transformers)나 Stable Diffusion에서 클래스(Class)와 타임스텝(Timestep) 정보가 어떻게 이미지에 스며드는지 이해하려면 이 구조를 완벽히 짚고 넘어가야 합니다.
오늘은 이 퍼즐 조각을 제자리에 맞추고, 최신 모델들이 왜 이 훌륭한 교차 어텐션을 포기하고 adaLN이라는 새로운 방식을 택했는지까지 알아보겠습니다.
1. 오리지널 트랜스포머의 Cross-attention: 역할 분담의 미학
오리지널 트랜스포머 구조에서 인코더와 디코더는 명확하게 역할을 분담하여 Cross-attention을 수행합니다. 이를 제대로 이해하려면 먼저 의 진짜 의미를 알아야 합니다.
- Query () - 질문: "내가 지금 번역을 이어가려면 원본 문장에서 어떤 정보가 필요하지?"
- Key () - 이름표/목차: "내가 분석한 원본 문장의 단어들은 이런 특징을 가지고 있어."
- Value () - 실제 내용물: "그 특징(이름표)에 해당하는 진짜 정보(문맥)는 이거야."
작동 방식 정리:
1. 디코더(Decoder): 자신이 지금까지 생성한 단어들을 바탕으로 를 만들어냅니다.
2. 인코더(Encoder): 원본 문장을 모두 분석하여 와 를 디코더에게 넘겨줍니다.
3. Cross-attention 연산: 디코더의 가 인코더가 준 들을 쭉 훑어보고 연관성(Attention Score)을 계산한 뒤, 가장 필요한 값을 쏙쏙 뽑아옵니다.
즉, 인코더가 와 를 차려놓으면, 디코더가 를 들고 가서 필요한 정보를 캐가는 구조입니다.
2. DiT(확산 모델)의 Cross-attention: 이미지와 힌트의 대화
이제 이 완벽한 원리를 DiT(Diffusion Transformers)나 조건부 입력이 있는 ViT의 Cross-attention Block에 그대로 대입해 봅시다.
이미지 생성 모델에는 명시적인 '인코더/디코더'라는 명칭은 없지만, 이미지 패치와 조건부 힌트(타임스텝 , 클래스 )가 그 역할을 나누어 맡습니다.
이때 조건부 힌트가 트랜스포머 블록에 들어간다고 해서 를 모두 생성하는 것이 아닙니다. 조건부 힌트는 와 만 만들고, 는 이미지가 만듭니다.
- 이미지 토큰 ( 생성자): 수많은 이미지 패치 토큰들이 각각 자신의 를 만듭니다.
"나 지금 우측 상단 픽셀인데, 여기 노이즈 지우려면 강아지 귀 모양 정보가 필요한가?"
- 조건부 토큰 ( 생성자): 타임스텝 와 클래스 정보가 신경망(MLP)을 거쳐 와 벡터로 변신합니다.
"우리는 '강아지()' 조건이고, 지금 '50단계()' 진행 중이야. 자, 우리 정보 여기 있어."
수천 개의 이미지 패치()들은 이 2개의 힌트 토큰()을 바라보고 필요한 힌트 정보()를 쏙쏙 골라 자신의 픽셀 값에 스며들게 합니다. 이것이 바로 "개별 맞춤형 지도" 방식입니다. 강아지의 '귀'를 그리는 토큰과 '배경'을 그리는 토큰이 각기 다르게(유연하게) 정보를 훔쳐 오는 것이죠.
3. 훌륭하지만 무겁다: 연산량(Gflops)의 압박
원리는 훌륭하지만, 이 Cross-attention 방식은 치명적인 단점이 있습니다. 바로 어마어마한 연산량입니다.
만약 이미지를 잘게 쪼갠 패치 토큰이 4,000개라면, 이 4,000개의 토큰 각각이 조건부 토큰들과 행렬 곱셈을 개별적으로 수행해야 합니다. 고해상도 이미지일수록 토큰 개수가 기하급수적으로 늘어나 교차 어텐션 층을 통과하는 비용이 폭증하게 됩니다.
4. 천재적인 타협안: adaLN (학교 전체 방송 일괄 적용)
이러한 연산량 문제를 해결하기 위해 DiT 저자들이 고안해 낸 방법이 바로 adaLN(Adaptive Layer Normalization, 적응형 층 정규화)입니다.
DiT 논문에서는 adaLN을 다음과 같이 설명합니다.
"It is also the only conditioning mechanism that is restricted to apply the same function to all tokens."
(모든 토큰에 동일한 함수를 적용하도록 제한된 유일한 메커니즘이다.)
Cross-attention이 '개별 맞춤형 지도'였다면, adaLN은 '학교 전체 방송 일괄 적용'입니다. 1. 힌트()를 받아 (증폭)와 (이동)라는 거대한 전체 수도꼭지 밸브 딱 한 세트를 만들어냅니다.
2. 그리고 이 밸브 값을 4,000개의 모든 이미지 토큰에 단 하나의 예외도 없이 똑같이 곱하고 더해버립니다.
3. 즉, 귀를 그리는 토큰이든 배경을 그리는 토큰이든 무조건
라는 완벽하게 동일한 함수(same function)를 뒤집어쓰게 됩니다.
💡 저자들의 진짜 의도
솔직히 말해, adaLN 방식은 Cross-attention처럼 토큰마다 섬세하게 조건을 다르게 줄 수 없습니다. 무식하게 모든 토큰에 똑같은 변화를 강제해야 한다는 제약(restriction)이 있죠.
하지만 스피커로 전체 방송하듯 일괄 적용해 버리니까, 일일이 를 곱하던 복잡한 계산이 싹 사라집니다. 약간의 융통성(토큰별 개별 적용)을 포기한 대신, 압도적인 가성비(연산 효율)를 얻어낸 것입니다. 이것이 DiT가 가볍고 빠르게 고품질 이미지를 생성할 수 있는 핵심 비결입니다.
