오늘은 파이토치(PyTorch)를 사용해 모델을 학습시키고 저장된 모델을 다시 불러올 때 많은 분들이 헷갈려하시는 주제를 다뤄보려고 합니다.
바로 "가중치(Weight)만 불러올 것인가, 아니면 옵티마이저(Optimizer)의 상태까지 함께 불러올 것인가?" 하는 문제입니다.
이 두 가지 방식은 단순히 코드가 한 줄 더 들어가고 덜 들어가는 차이가 아니라, 학습의 '연속성'과 '목적' 측면에서 아주 큰 차이를 만듭니다. 결론부터 말씀드리자면, 새로운 목적에 맞게 전이학습(Transfer Learning)을 하실 때는 'Weight만' 불러오는 것이 올바른 방법입니다.
그 이유가 무엇인지, 두 가지 경우의 구체적인 차이점을 정리해 보겠습니다.
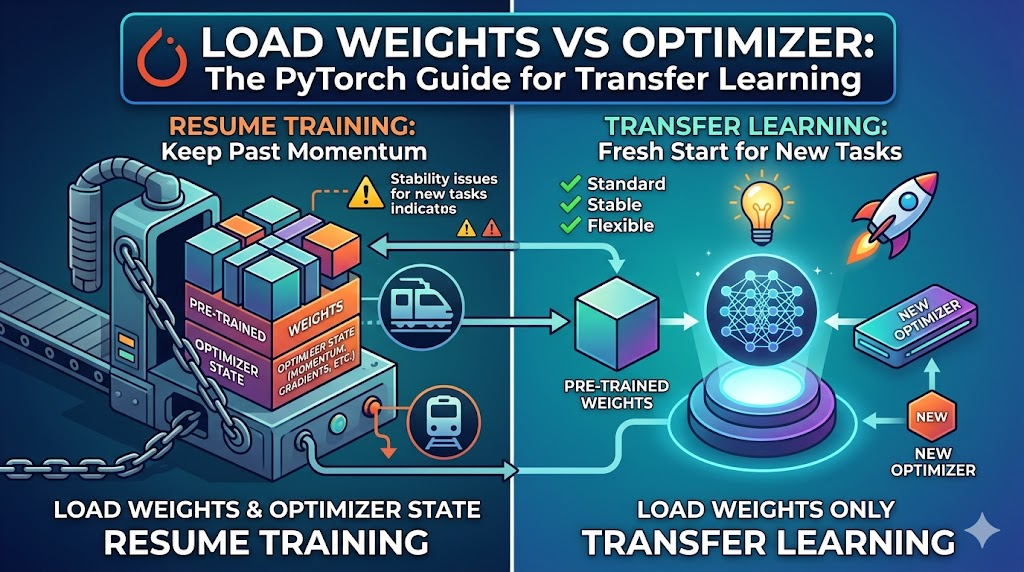
1. Weight와 Optimizer를 모두 불러오는 경우: 학습 재개 (Resume Training)
Adam, RMSprop, 또는 모멘텀(Momentum)을 사용하는 SGD와 같은 옵티마이저들은 단순히 현재의 학습률(Learning rate)만 기억하고 있는 것이 아닙니다. 과거의 기울기(Gradient) 누적값, 모멘텀 버퍼, 스텝 수 등 '과거의 학습 관성과 이력(State)'을 내부에 고스란히 저장하고 있죠.
- 동작 방식: 모델의 가중치(
model.state_dict())는 물론, 옵티마이저가 기억하는 과거의 관성(optimizer.state_dict())까지 정확히 복원합니다. - 학습에 미치는 영향: 이전에 모델이 학습해 나가던 방향과 가속도를 그대로 유지합니다.
- 적합한 상황: 정전이나 메모리 부족(OOM) 등으로 학습이 중간에 뚝 끊겼을 때 사용합니다. 이전과 완전히 동일한 데이터와 목적(Loss)으로 학습을 이어나가야 할 때 필수적입니다.
- 🚨 주의점: 만약 이 방식을 전이학습에 사용하면 문제가 생깁니다. 새로운 태스크로 넘어가야 하는데 모델이 '과거의 목적지'를 향해 가던 관성을 유지하려 하기 때문에 학습이 불안정해집니다. 또한, 분류 클래스 수가 달라져 출력층(Head)을 변경했다면 기존 옵티마이저의 상태 크기와 맞지 않아 바로 에러가 발생하게 됩니다.
2. Weight만 불러와서 학습하는 경우: 전이학습 (Transfer Learning / Fine-tuning)
이 방식은 기존 모델이 고생해서 학습한 '지식(Feature Extraction 능력)'만 쏙 가져오고, 학습을 이끌어갈 엔진인 옵티마이저는 백지상태로 새롭게 장착하는 방식입니다.
- 동작 방식: 모델의 가중치(
model.state_dict())만 복원하고, 옵티마이저는 완전히 초기화된 상태로 새로 선언하여 연결합니다. - 학습에 미치는 영향: 모델이 가진 훌륭한 특징 추출 능력은 그대로 유지하지만, 과거의 학습 관성(모멘텀)은 0으로 초기화됩니다. 새로운 손실 함수(Loss Landscape) 환경에서 새로운 방향을 안정적으로 찾아갈 수 있습니다.
- 적합한 상황: 사전 학습된 모델(Pre-trained model)을 가져와 내 데이터셋에 맞게 파인튜닝(Fine-tuning)을 할 때 사용하는 표준적인 방법입니다. 내 목적에 맞게 출력층 구조를 변경하더라도 옵티마이저가 새로 선언되었기 때문에 충돌 없이 매끄럽게 학습이 진행됩니다.
💡 한눈에 보는 요약 비교표
| 구분 | Weight + Optimizer 모두 로드 | Weight만 로드 |
|---|---|---|
| 옵티마이저 상태 | 이전 학습의 모멘텀, 기울기 이력 등 유지 | 완전히 새롭게 초기화 (관성 없음) |
| 주요 목적 | 학습 재개 (Resume Training) | 전이학습 (Transfer Learning/Fine-tuning) |
| 데이터 및 태스크 | 이전과 동일한 데이터 / 동일한 태스크 | 새로운 데이터 / 새로운 태스크 |
| 네트워크 구조 변경 | 구조가 바뀌면 에러 발생 가능성 매우 높음 | 출력층(Head) 등을 변경해도 문제없음 |
| 전이학습 시 결과 | 과거의 관성 때문에 학습 방해 또는 에러 발생 | 새로운 목표에 맞게 안정적으로 최적화 진행 |
📌 결론
파이토치로 '전이학습(Transfer Learning)'을 진행하실 계획이라면, 과거의 옵티마이저 상태에 미련을 두지 마세요! 과감히 버리고 Weight만 불러온 뒤 새로운 Optimizer를 선언하여 학습을 시작하는 것이 정답입니다.
이 포스팅이 여러분의 모델 학습 과정에서 겪는 혼란을 줄이는 데 도움이 되었길 바랍니다.
