딥러닝 모델의 성적을 올리는 '쪽지 시험' 전략: 심층 지도(Deep Supervision) 완벽 이해
딥러닝을 공부하다 보면 '심층 지도(Deep Supervision)'라는 용어를 마주치게 됩니다. 이름만 들으면 흔히 아는 '지도 학습(Supervised Learning)'의 한 종류 같지만, 사실 심층 지도는 모델의 종류가 아니라 딥러닝 모델의 구조를 설계하고 효과적으로 학습시키는 일종의 '기법'에 가깝습니다.
그렇다면 우리가 아는 일반적인 지도 학습과 심층 지도는 어떤 차이가 있을까요? 왜 복잡한 딥러닝 모델에서는 이 방식이 필수적일까요? 아주 쉬운 비유와 함께 차근차근 알아보겠습니다.
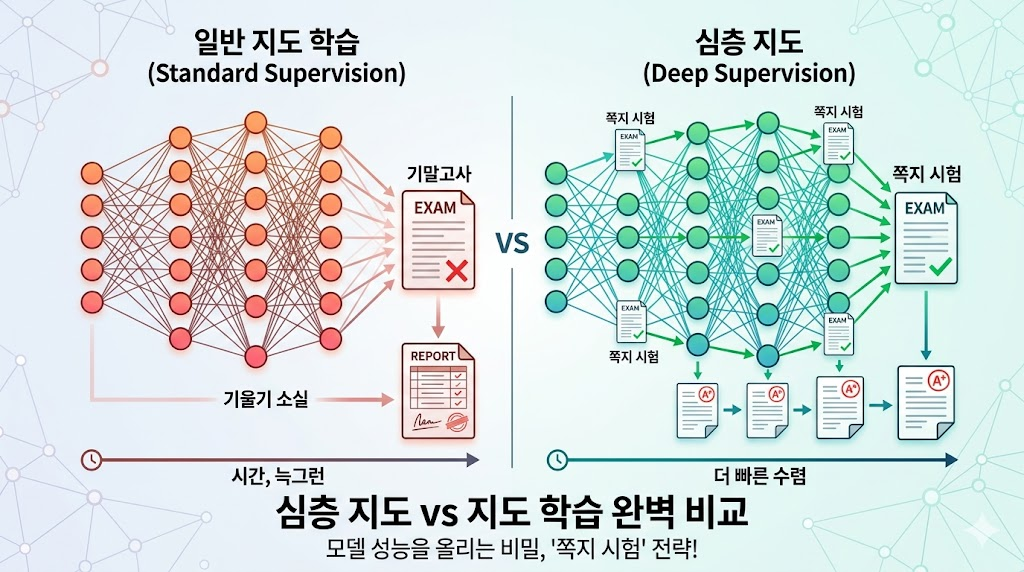
1. 기말고사 한 방 vs 꼼꼼한 쪽지 시험
가장 직관적인 비유는 바로 '학교 시험'입니다.
- 일반 지도 학습 (기말고사 올인형): 학기 내내 혼자 공부하다가 학기 말에 기말고사(마지막 층)를 딱 한 번 봅니다. 결과가 나쁘게 나오더라도, 내가 학기 초반에 어떤 개념을 잘못 이해했는지 역추적하기가 매우 어렵습니다.
- 심층 지도 (쪽지 시험형): 단원이 끝날 때마다 쪽지 시험(중간 층)을 봅니다. 채점 결과를 바로바로 확인하기 때문에, 내가 초반에 무엇을 놓쳤는지 즉각적으로 파악하고 수정하며 공부를 이어갈 수 있습니다.
2. 기술적으로는 어떤 차이가 있을까?
이를 딥러닝 네트워크 구조 관점에서 살펴보면 확연한 차이가 드러납니다.
- 일반 지도 학습 (Standard Supervision): 네트워크의 맨 마지막 층(Output Layer)에서만 최종 결과물과 정답(Label)을 비교해 오차를 계산합니다. 이 오차 신호는 역전파(Backpropagation)를 통해 거꾸로 앞쪽 층까지 전달되어야 합니다. 문제는 네트워크가 너무 깊어지면, 앞쪽 층까지 신호가 도달하다가 희미해져 버리는 '기울기 소실(Gradient Vanishing)' 현상이 발생할 수 있습니다.
- 심층 지도 (Deep Supervision): 네트워크의 마지막 층뿐만 아니라, 중간 층(Hidden Layers)들에서도 '미니 정답지'를 두고 채점을 진행합니다. 각 층에서 나온 결과물을 바로 정답과 비교하기 때문에, 오차 신호가 멀리서부터 돌아올 필요 없이 해당 층에 즉각적으로 전달됩니다.
3. 심층 지도, 도대체 왜 쓰는 걸까요?
3D 의료 영상 분할(Segmentation)처럼 데이터가 크고 아주 미세한 경계를 다뤄야 하는 복잡한 작업에서 심층 지도는 다음과 같은 강력한 이점을 제공합니다.
- 기울기 소실 완벽 방지: 중간 층에서 직접 정답과 비교하므로, 아주 깊은 모델이라도 앞쪽 층까지 학습 신호가 생생하게 전달됩니다.
- 다수준 특징 학습 (Multi-scale Feature Learning): 딥러닝 모델의 초반 층은 세밀한 경계선이나 질감(Detail)을 배우고, 깊은 층은 전체적인 형태와 맥락(Context)을 배웁니다. 각 층마다 분할 결과를 뽑아보게 강제함으로써, 각 층이 자기 역할에 맞는 수준의 특징을 더 명확하고 확실하게 학습하게 됩니다.
- 수렴 속도 향상: 중간중간 가이드라인이 명확하게 주어지기 때문에, 모델이 정답을 찾아가는 길을 헤매지 않고 훨씬 빠르게 수렴(Better Convergence)합니다.
4. 어떻게 구현할까? (임시 분류기의 마법)
"중간 층에서 어떻게 정답과 비교하나요?"라는 의문이 드실 수 있습니다. 단순히 중간에서 뽑아낸 특징(Feature Map) 덩어리 자체는 정답지(Label)와 형태가 다르기 때문입니다.
이를 위해 중간 층의 출력물 뒤에 '임시 미니 분류기(Side-output Layer)'를 붙여줍니다.
- 1x1 Convolution: 피처 맵의 채널 수를 우리가 찾으려는 클래스 개수(예: 배경 vs 종양)에 맞게 압축합니다.
- Upsampling: 중간 층은 보통 해상도가 원본보다 작게 축소되어 있으므로, 정답지와 크기를 맞춰 비교하기 위해 이미지를 다시 키워줍니다.
- Softmax (또는 Sigmoid): 각 픽셀이 특정 클래스에 속할 확률값()으로 변환합니다.
이렇게 변환된 중간 결과물들은 각각 정답과 비교되어 손실()을 계산합니다. 최종 오차는 아래와 같이 각 층의 손실을 더해서 구하게 됩니다. (보통 마지막 층의 비중을 가장 크게 둡니다.)
최종 손실
5. 실전 압축 꿀팁: 학습할 때만 쓰고 버린다?
심층 지도의 가장 재미있는 점은 이 '미니 분류기'들이 쓰이는 시점입니다.
- 학습 단계 (Training): 임시 분류기에서 나온 결과와 정답을 비교해 오차 역전파를 수행합니다. 앞쪽 층들을 혹독하게 단련시키는 스파르타식 교관 역할을 하죠.
- 테스트 단계 (Testing/Inference): 모델 학습이 완료되어 실제 데이터에 적용할 때는, 중간에 붙여둔 미니 분류기들을 미련 없이 떼어버립니다. 이미 학습 과정에서 앞쪽 층들이 충분히 강하게 단련되었기 때문에, 최종 층의 결과물 하나만 사용해도 뛰어난 성능을 발휘합니다.
마치며
결과적으로 심층 지도는 딥러닝 모델이 깊어지면서 겪는 한계를 극복하고, 중간 단계의 유실될 수 있는 정보들을 끝까지 잘 이끌고 가도록 만들어주는 매우 영리한 아키텍처 설계 기법입니다. V-Net이나 3D U-Net 등 복잡한 비전 모델을 다루고 계신다면, 이 '쪽지 시험' 전략을 구조에 꼭 도입해 보시기 바랍니다!
