딥러닝의 어설픈 실수를 바로잡는 '마무리 투수': CRF(조건부 랜덤 필드) 완벽 이해
인공지능 모델의 구조를 들여다보다 보면 CRF(Conditional Random Field, 조건부 랜덤 필드)라는 용어를 자주 마주치게 됩니다. 통계학과 확률론에서 온 수학적 모델이다 보니 이름부터 꽤 직관적이지 않고 어렵게 느껴지죠.
하지만 너무 걱정하지 마세요. 아주 쉽게 비유하자면 CRF는 "주변 눈치를 보며 가장 상식적인 정답을 고르는 깐깐한 감수자"라고 할 수 있습니다.
딥러닝 모델이 큰 그림을 아주 잘 그리는 화가라면, CRF는 그 그림의 삐져나온 선을 정리하고 디테일을 살려주는 보정 전문가입니다. 오늘은 이 CRF가 컴퓨터 비전(영상 처리)과 자연어 처리(NLP)라는 전혀 다른 두 분야에서 어떻게 똑같은 원리로 마법을 부리는지 알아보겠습니다.
1. CRF의 핵심 원리: "독립적 판단 vs 전체적 문맥"
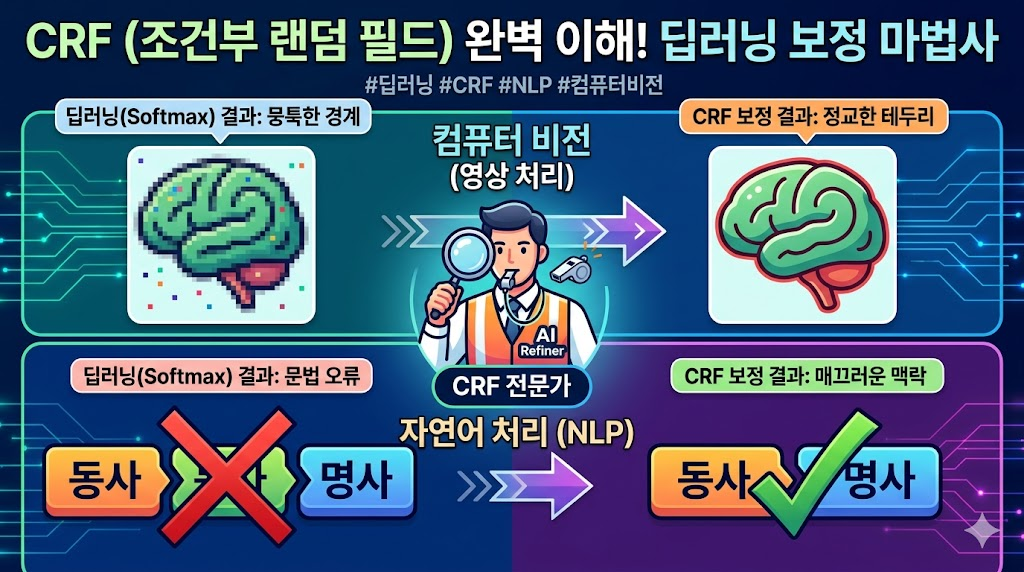
CRF를 가장 쉽게 이해하는 방법은 딥러닝의 기본 출력 방식인 Softmax와 비교해 보는 것입니다.
- Softmax (개인주의): 각 픽셀이나 단어 하나만 보고 독립적으로 판단합니다. "이 픽셀은 암세포일 확률이 90%야!", "이 단어는 명사일 확률이 80%야!"라고 외치지만, 주변에 누가 있는지는 전혀 신경 쓰지 않습니다.
- CRF (전체주의/문맥 파악): Softmax가 내놓은 결과에 더해, "근데 상식적으로 이 위치에 이게 오는 게 말이 돼?"라는 규칙을 따집니다. 전체적인 흐름과 주변과의 관계를 살펴 가장 모순이 적고 자연스러운 상태를 찾아냅니다.
2. 영상 처리(비전)에서의 CRF: 뭉툭한 선을 날카롭게!
의료 영상에서 종양을 찾아내는 U-Net 같은 딥러닝 모델들은 이미지를 줄였다 키우는 과정에서 치명적인 단점이 생깁니다. 바로 물체의 테두리가 둥글둥글하고 흐릿해지거나(뭉툭한 경계), 장기 한복판에 뜬금없이 다른 장기 픽셀이 찍히는(파편화) 현상입니다.
여기서 CRF가 후처리(Post-processing) 투수로 등판합니다. CRF는 다음과 같은 '이웃 사촌' 규칙을 적용합니다.
- 색상이 비슷하면: 두 픽셀의 색깔(강도)이 비슷하면 같은 클래스일 확률이 높다.
- 거리가 가까우면: 물리적으로 가까이 붙어 있다면 같은 덩어리일 확률이 높다.
이 기준을 바탕으로 픽셀들을 다시 깎고 다듬어 아주 정교한 테두리를 완성합니다. 특히 이미지 내의 모든 픽셀 쌍을 서로 연결해서 비교하는 Fully Connected CRF(전결합 CRF)를 사용하면, 멀리 떨어진 픽셀 간의 연관성까지 고려해 아주 가늘고 복잡한 미세 구조까지 완벽하게 복원해 냅니다.
3. 자연어 처리(NLP)에서의 CRF: 눈치 없는 AI에게 문법을 가르치다
사실 CRF는 영상 처리보다 자연어 처리(NLP)에서 먼저 대성공을 거둔 기술입니다. 문장의 품사를 맞추거나(POS Tagging), 고유명사를 찾아내는 개체명 인식(NER)에서 빛을 발하죠.
"나는 애플에서 일한다."라는 문장을 볼까요?
Softmax만 쓴다면 '애플'이라는 단어만 보고 "과거 데이터에 과일 사과가 더 많았으니 이건 과일이야!"라는 오답을 낼 수 있습니다. 하지만 CRF는 문장 전체의 눈치를 봅니다.
"조사 '~에서' 앞에는 주로 장소나 조직명이 오고, 동사 '일한다' 앞에는 과일이 올 수 없어. 그러니까 여기서 '애플'은 무조건 IT 기업(조직명)이야!"
요즘 모델 구조에 BiLSTM-CRF나 BERT-CRF처럼 딥러닝 뒤에 CRF가 꼭 붙어있는 이유가 바로 이 때문입니다.
딥러닝이 순간적으로 착각해서 절대 올 수 없는 문법적 순서(예: 개체명 태그에서 I-tag가 B-tag보다 먼저 오는 불가능한 상황)를 예측하더라도, 마지막 층에 있는 CRF가 "이건 전이 확률상 0%야. 말이 안 되니까 정상적인 순서로 고쳐!"라고 논리적으로 바로잡아 줍니다.
💡 요약: 분야는 달라도 본질은 하나!
결국 의료 영상에서의 CRF나 자연어 처리에서의 CRF나 그 본질은 완전히 똑같습니다.
- 의료 영상: "종양 픽셀 바로 옆에 뜬금없이 정상 뼈 픽셀이 있는 건 해부학적으로 말이 안 돼. 테두리 자연스럽게 다시 그려!"
- 자연어 처리: "동사 바로 뒤에 또 동사가 오는 건 문법적으로 말이 안 돼. 품사 태그 논리적으로 다시 붙여!"
딥러닝이 강력한 성능을 자랑하지만 여전히 놓치기 쉬운 '구조적인 규칙'이나 '주변과의 관계'. 이것을 통계적으로 꽉 잡아주어 최종 결과물의 퀄리티를 한 차원 높여주는 든든한 조력자가 바로 CRF입니다.
다음에 딥러닝 모델 아키텍처에서 CRF 층(Layer)을 발견하신다면, "아, 여기서 모델의 디테일을 끌어올리고 있구나!"하고 반갑게 이해하실 수 있을 겁니다.
