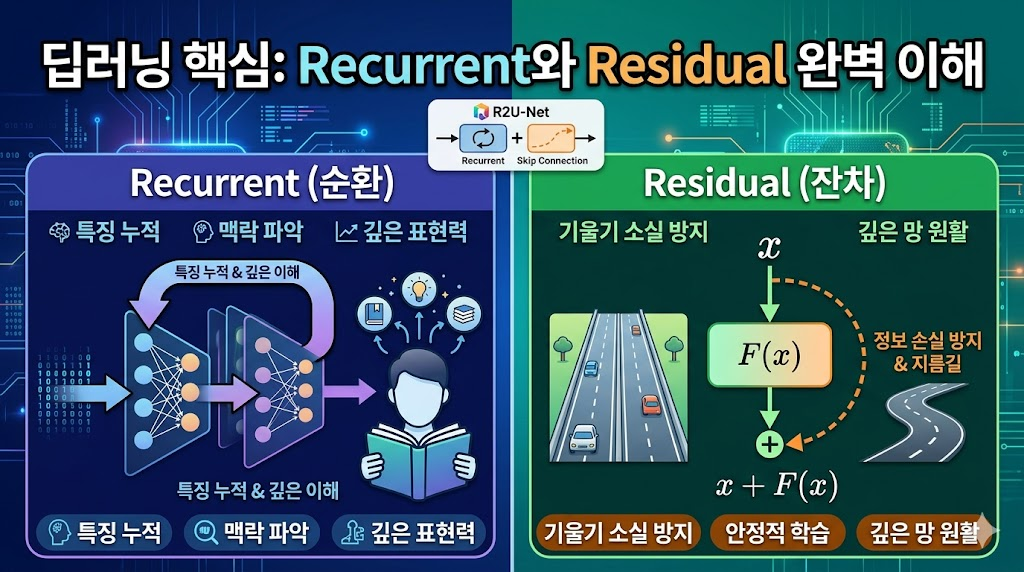
딥러닝 아키텍처를 공부하다 보면 모델의 성능을 높이기 위해 고안된 다양한 기법들을 마주하게 됩니다. 그중에서도 Recurrent(순환)와 Residual(잔차)은 현대 딥러닝 모델, 특히 이미지 분할(Segmentation) 등의 작업에서 빠질 수 없는 핵심 개념입니다.
두 개념은 네트워크 내에서 데이터가 흐르는 방식과 근본적인 목적에서 명확한 차이를 보입니다. 오늘은 이 두 가지 개념의 직관적인 의미부터, 조금은 복잡해 보이는 수학적 원리까지 알기 쉽게 풀어서 설명해 드리겠습니다.
1. Recurrent (순환): "반복과 누적을 통한 깊은 이해"
일반적인 신경망은 데이터가 한 방향으로만 흐릅니다. 하지만 Recurrent 구조는 특정 층(Layer)의 출력이 다시 자기 자신의 입력으로 되돌아가는 루프(Loop) 구조를 가집니다.
마치 한 페이지의 글을 한 번 쓱 읽고 넘어가는 것이 아니라, 여러 번 반복해서 읽으며 숨겨진 행간의 의미와 세부 묘사를 깊게 이해하는 과정과 같습니다. 시간적 흐름이나 공간적 연관성을 파악해 아주 미세한 디테일(Low-level feature)을 추출하는 데 탁월합니다.
수식으로 보는 Recurrent의 원리
수식의 뼈대를 살펴보면 순환 구조가 어떻게 특징을 누적하는지 알 수 있습니다.
이 수식은 크게 세 부분으로 나뉩니다.
- : 이전 층에서 넘어온 '외부의 처음 입력 데이터'를 처리하는 일반적인 합성곱 연산입니다.
- : 바로 순환 연산의 핵심입니다. 동일한 층 내부에서 바로 이전 단계()에 계산했던 자기 자신의 결과를 현재 연산에 더해줍니다.
- : 편향(Bias) 값입니다.
🚨 여기서 잠깐! 구조의 안정성을 지키는 숨은 디테일
많은 분들이 이 수식을 보고 "처음 한 번만 외부 입력()을 받고, 그 다음부터는 자기 자신의 결과물()만 반복해서 뭉치는 것 아닐까?"라고 오해하곤 합니다. 하지만 실제로는 반복되는 모든 시간 단계()마다 처음 입력값이 계속해서 더해집니다. 단계별로 풀어보면 다음과 같습니다.
- (첫 계산): 아직 과거가 없으므로 순환 부분은 0입니다.
- (두 번째 계산):
- (세 번째 계산):
왜 매번 처음 입력을 더해줄까요? 만약 과거의 자기 자신()에게만 의존해 반복 연산을 거듭한다면, 원본 데이터가 가지고 있던 원래의 형태를 망각하거나 정보가 왜곡될 위험이 큽니다. 매 반복마다 연산을 더해줌으로써 처음 입력 데이터가 뼈대이자 기준점 역할을 하게 만들고, 덕분에 모델은 길을 잃지 않고 디테일만 정교하게 깎아나갈 수 있게 됩니다.
또한, 반복 횟수()를 늘리더라도 똑같은 순환 가중치 를 재사용하는 가중치 공유(Weight Sharing) 덕분에 네트워크의 파라미터(무게)를 전혀 늘리지 않고도 피처를 깊게 누적할 수 있습니다.
2. Residual (잔차): "지름길을 통한 정보 손실 방지"
신경망의 층을 깊게 쌓을수록 모델의 성능이 좋아질 것 같지만, 실제로는 학습 신호가 점점 옅어지는 기울기 소실(Vanishing Gradient) 문제가 발생합니다. 이를 해결하기 위해 등장한 것이 바로 Residual 구조입니다.
Residual은 입력값을 여러 층에 거치게 하는 동시에, 층을 거치지 않은 원래의 입력값을 출력에 그대로 더해주는 건너뛰기(Skip Connection) 구조를 가집니다. 복잡한 국도로만 차를 보내는 것이 아니라, 목적지까지 안전하게 도착할 수 있는 '고속도로'를 뚫어주는 셈입니다.
수식으로 보는 Residual의 원리
- : 블록에 들어온 초기 입력값입니다.
- : 연산을 거쳐 학습된 입력과 출력 사이의 차이(잔차)입니다.
- : 이 수식의 핵심인 지름길 연결입니다.
신경망이 이상적인 결과를 통째로 학습하는 대신, 기존 정보에 추가해야 할 '차이'만 학습하도록 난이도를 확 낮춰줍니다. 또한, 역전파(Backpropagation) 과정에서 덕분에 미분값이 1이 되어, 아주 깊은 망에서도 기울기가 손실 없이 이전 층으로 잘 전달되게 합니다.
💡 한눈에 보는 Recurrent vs Residual
| 구분 | Recurrent (순환) | Residual (잔차) |
|---|---|---|
| 핵심 형태 | 자기 자신으로 되돌아오는 루프 (Loop) | 층을 건너뛰어 연결하는 지름길 (Skip Connection) |
| 수학적 특징 | 시간축을 따라 이전 정보()와 기준점() 결합 | 층과 층 사이에서 기존 입력값()을 곧바로 덧셈 |
| 주요 목적 | 원본의 뼈대를 유지하며 특징 누적 및 표현력 확보 | 깊은 네트워크의 안정적 최적화 (기울기 소실 방지) |
| 작동 원리 | 동일한 파라미터()를 사용해 반복 연산 | 정보에 추가적으로 학습해야 할 차이()만 연산 |
| 주요 장점 | 파라미터 수 증가 없이 모델 표현력 극대화 | 층을 아주 깊게 쌓아도 원활한 학습 진행 |
마치며: 두 개념의 완벽한 시너지
뛰어난 성능을 자랑하는 R2U-Net과 같은 논문에서는 이 두 가지 강력한 무기를 하나로 합쳤습니다.
네트워크 안에 Recurrent Residual 구조를 구축함으로써, 파라미터 수를 억제해 연산 효율을 챙기면서도(Recurrent의 장점), 깊은 구조에서 안정적으로 학습을 진행하여(Residual의 장점) 기존 모델보다 훨씬 더 정밀하고 우수한 성능을 끌어낸 것입니다.
복잡해 보이는 수식도 결국은 "어떻게 하면 기준점을 잃지 않고 데이터를 더 깊이 이해하며(Recurrent), 그 정보를 손실 없이 끝까지 전달할 것인가(Residual)"에 대한 고민의 결과물입니다. 딥러닝 아키텍처를 이해하는 데 이 글이 도움이 되셨기를 바랍니다!
