k8s triton
1.ec2 쿠버네티스 클러스터 구축

위와같이 마스터노드 1개와 워커노드 2개로 클러스터를 구축하려고한다. 본 포스팅에서는 다루지 않지만, 최종목적은 gpu를 할당해 ml 모델을 서빙하는것을 목표로한다. 쿠버네티스 설치 위와같이 설정하고 클러스터를 생성한다. > ubuntu@ip-172-31-0-17
2023년 8월 8일
2.k8s triton inference server 클러스터 구축
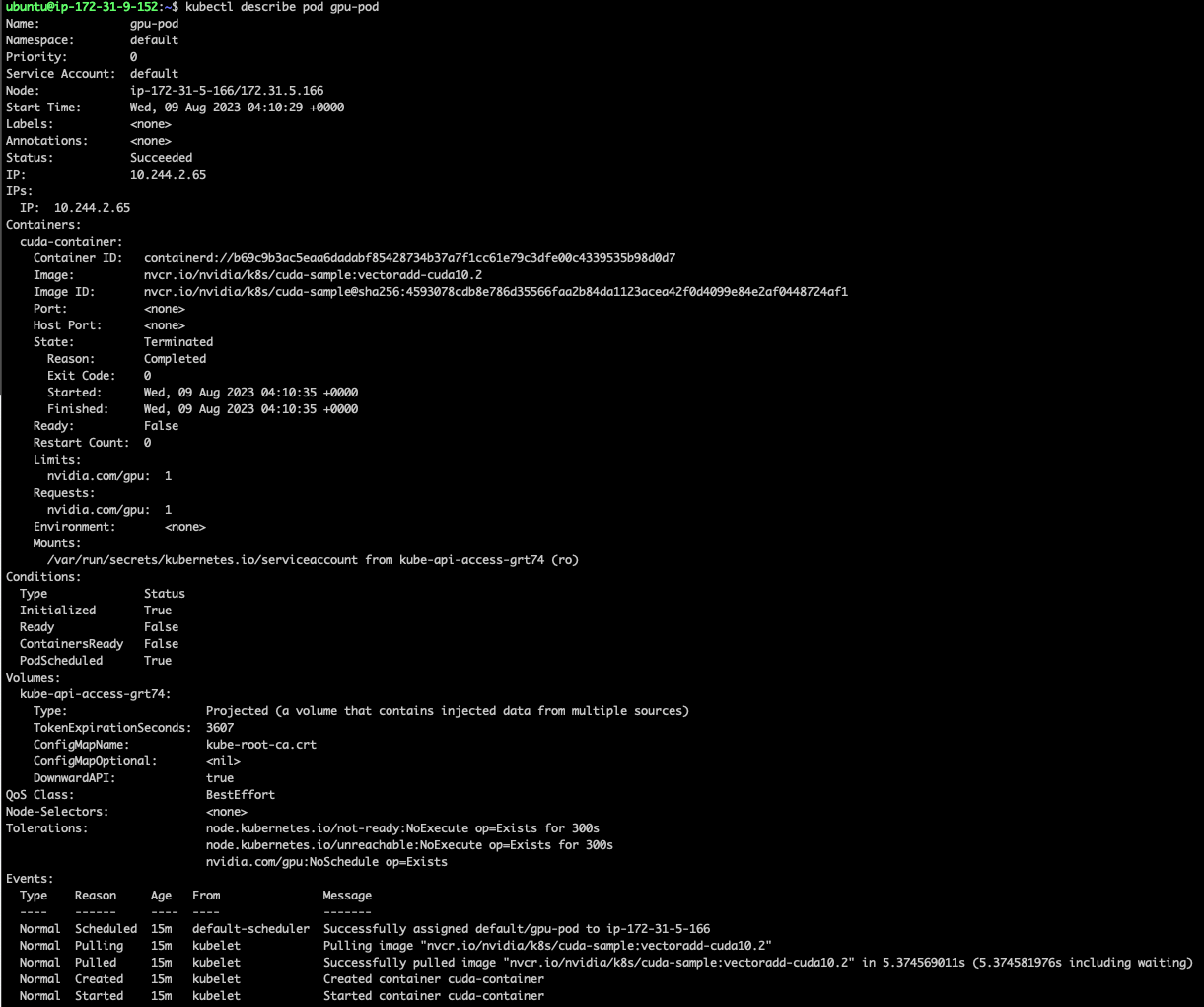
ec2 쿠버네티스 클러스터 구축 포스팅에 이어 클러스터의 worker 노드에 nvidia gpu를 할당하는 내용을 다뤄보려고한다.NVIDIA Container Toolkit과 k8s용 nvidia 장치 플러그인을 설치해야한다.컨테이너에서 gpu를 사용하는 경우 호스트에
2023년 8월 10일
3.triton inference server 성능 최적화
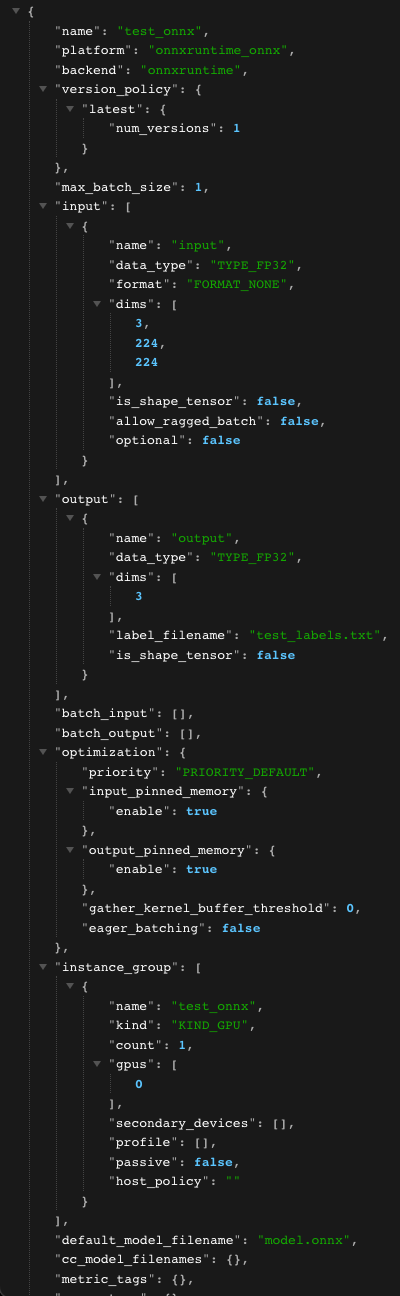
k8s triton inference server 클러스터 구축 포스팅에 이어 배포된 추론서버의 서빙성능 최적화에 관한 내용을 다뤄보려고한다.triton에서는 모델 서빙 성능을 개선하기 위해 Dynamic Batch, Concurrent Model Execution 등
2023년 8월 11일
4.triton inference server 모델관리

이전 포스팅에서 성능 최적화하는 방법까지 알아봤다.이번 포스팅에는 서비스를 운영하며 어떻게 모델을 관리해야할까? 하는 문제에서 시작된다.triton 모델관리 문서를 보면 3가지 모델제어 방식을 제공한다.NONE(기본 제어모드)POLLEXPLICITNone 제어모드로 t
2023년 9월 15일