k8s triton inference server 클러스터 구축 포스팅에 이어 배포된 추론서버의 서빙성능 최적화에 관한 내용을 다뤄보려고한다.
triton에서는 모델 서빙 성능을 개선하기 위해 Dynamic Batch, Concurrent Model Execution 등의 다양한 기능을 제공한다.
위 기능들과 Performance Analyzer, Model Analyzer를 사용해 성능 최적화를 시도해보려고한다.
Dynamic batching
Dynamic batching란 클라이언트에서 정해진 크기의 배치로 요청하는것이 아니라, 서버에서 받는 요청을 queue에 관리해 배치를 만들어 추론한다. 입력하는 값에따라 동적으로 배치크기가 달라질 수 있기때문에 Dynamic batching 이라고 부르는 것 같다.
관련 파라미터는 pbtxt 파일에 정의하며 대표적으로 아래 값들이있다.
...
max_batch_size : 1
dynamic_batching {
max_queue_delay_microseconds: 100000
}
...max_batch_size 는 배치 하나의 최대크기를 의미하고, max_queue_delay_microseconds 는 배치하나를 구성하는데 대기하는 최대 시간을 의미한다. (max_queue_delay_microseconds 필드는 microseconds)
즉, max_queue_delay_microseconds 시간만큼 대기하며 요청을 queue에 쌓고 배치하나를 만드는것이다. 만약 microseconds max_queue_delay_microseconds 시간내에 max_batch_size 이상의 요청이 들어오면 거기서 배치하나의 구성이 끝나고 다음 배치를 구성한다.
max_batch_size 필드는 배치처리를 지원하지 않는 모델의 경우 0, 적용하려면 1 이상의 값으로 설정되어야한다.
자세한 설명은 공식문서에서 확인할 수 있다.
그리고, 여기서 정의된 max_batch_size는 각 모델 인스턴스 하나당 최대 배치크기이다.
즉, 클라이언트에서 요청할 때 최대 배치크기가 정의되어있다면 그 크기 이상의 max_batch_size를 정의하는것보다 모델 인스턴스의 수를 늘리는게 성능개선에 더 도움이 될 수 있다.
물론, 그 이상의 max_batch_size와 적절한 max_queue_delay_microseconds 값 설정을 통해 성능개선도 가능하다.
적용
name: "test_onnx"
platform: "onnxruntime_onnx"
max_batch_size : 1
input [
{
name: "input"
data_type: TYPE_FP32
dims: [3, 224, 224]
}
]
output [
{
name: "output"
data_type: TYPE_FP32
dims: [3]
label_filename: "test_labels.txt"
}
]위 pbtxt 파일은 동적배치가 적용되지 않은 경우다. 배포 후
GET /v2/models/<model_name>/config
으로 모델 설정에 대해 확인할 수 있다.
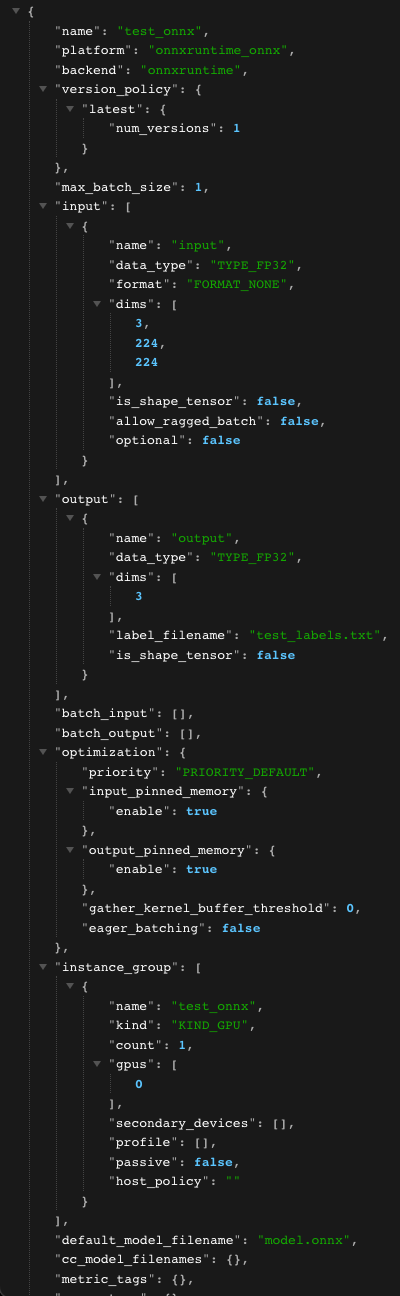
이제 동적 배치를 적용한 모델을 배포한다.
name: "test_onnx"
platform: "onnxruntime_onnx"
max_batch_size : 1
dynamic_batching {
max_queue_delay_microseconds: 100000
}
input [
{
name: "input"
data_type: TYPE_FP32
dims: [3, 224, 224]
}
]
output [
{
name: "output"
data_type: TYPE_FP32
dims: [3]
label_filename: "test_labels.txt"
}
]
dynamic_batching 필드가 추가되었다.
max_batch_size 를 조절하면 반영되는것도 확인할 수 있다.
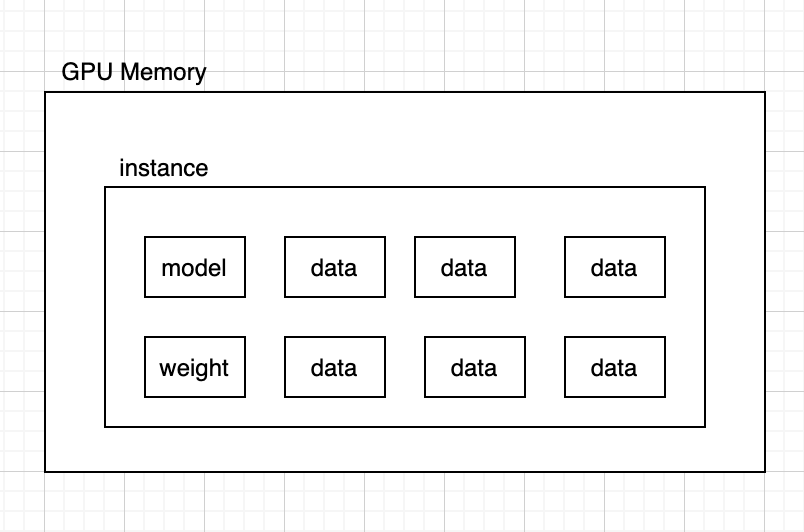
Concurrent Model Execution
Concurrent Model Execution란 여러 모델 혹은 동일한 모델의 인스턴스 여러개가 같은 노드에서 병렬실행시킬 수 있는 기능이다.
인스턴스 그룹에 구체적인 정의를 할 수 있다. 하나의 gpu에 몇개의 모델 인스턴스를 할당한다거나, 다수의 gpu가 있는경우 0번 gpu에는 인스턴스를 1개 할당하고 1번 gpu에는 인스턴스를 2개 할당하는 등의 구체적인 정의가 가능하다.
처음에는 Concurrent Model Execution 기능이 어떻게 사용되는건지 와닿지 않았는데, 배포하며 겪었던 의문점을 해결하며 이해할 수 있었다.
이전포스팅 내용중
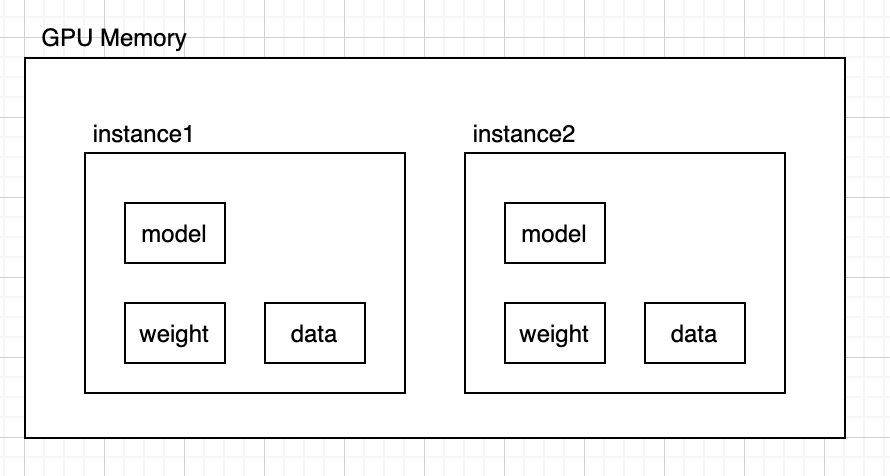
위와같은 의문이 들었는데 Concurrent Model Execution 기능으로 해결할 수 있었다.
모델의 크기가 작아 gpu에 프로세스가 실행되었음에도 메모리가 많이 남는상황이었다.
k8s에서 자원할당은 pod에 독립적이기 때문에 남는 gpu자원을 다른 pod에서 사용할수도 없는 상황이다.
pod 하나에 여러컨테이너를 실행시킬 수 있지만 특별한 경우가 아니면 지양하는걸로 알고있다.
pod 내부의 모든 컨테이너는 같은 라이프사이클을 공유하기 때문에 한 서비스 컨테이너가 죽으면 pod 전체를 재시작 해야한다.
물론 pod 내부 컨테이너간에 강한결합이 필요한경우(사이드카패턴을 사용하는 istio 등)에는 필요할 수 있으나 자원을 나눠 처리량을 높이는 용도로는 적합하지 않은 방식이라고 생각한다.
컨테이너를 여러개 사용하지않고 gpu 메모리를 잘 활용하는 방법이 배치처리를 하거나 Concurrent Model Execution를 사용하는 것이다.
배치처리를 할 경우 한번에 많은 데이터를 입력받고 추론하는 경우 배치크기를 늘리는만큼 메모리에 많은 데이터를 적재해 사용량을 높일 수 있다.
반면 Concurrent Model Execution 방식은 여러 모델을 메모리에 로드하고 병렬처리하는것이다.
Concurrent Model Execution의 메모리 적재방식이 위와같다면 nvidia-smi로 모니터링되는 gpu 메모리 사용량이 인스턴스의 수에 비례해 늘어나야한다. 이를 검증하려고한다.
적용
pbtxt 파일에 instance_group 필드를 추가해야한다.
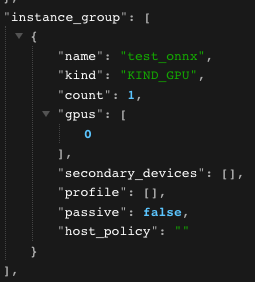
인스턴스 그룹을 정의하지 않고 모델을 배포하면 아래사진과 같은 설정이 적용된다.
instance_group [
{
kind: KIND_AUTO
count: 1
}
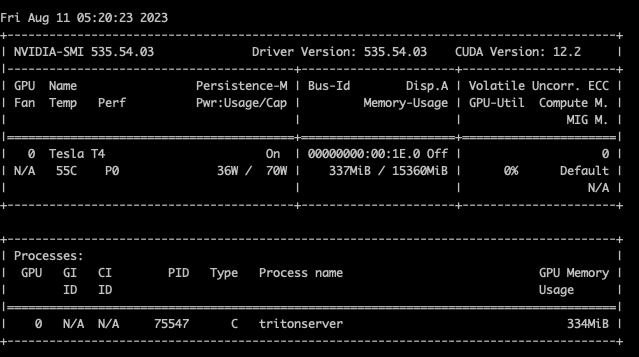
]0번 gpu에 인스턴스 1개가 실행된다.
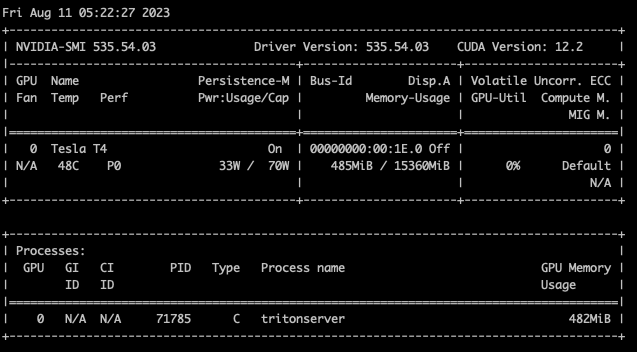
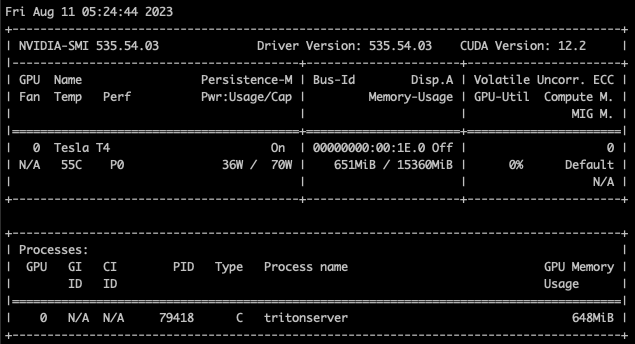
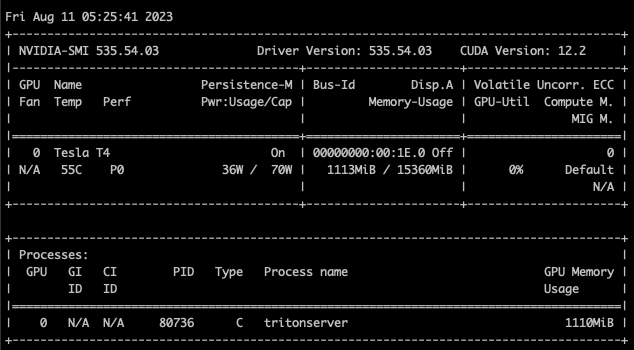
인스턴스가 1개일때 메모리 사용량을 캡처하고, 인스턴스 갯수를 늘려가며 메모리 사용량이 늘어나는지 확인한다.
instance count 1
instance count 2
instance count 4
instance count 8

위와같이 인스턴스 갯수에 따라 메모리 사용량이 늘어가는것을 확인할 수 있다.
Performance Analyzer
Performance Analyzer는 triton에서 제공하는 성능 측정 클라이언트로, 어떤 모델에 얼마나 추론 요청을 할지 등 세세한 옵션을 지정할 수 있다.
추론 요청에대한 결과로 Throughput, Latency 등의 정보를 제공하며 부하테스트 역시 가능하다.
공식문서에 따라 Performance Analyzer 컨테이너를 실행시키고 테스트가 가능하다.

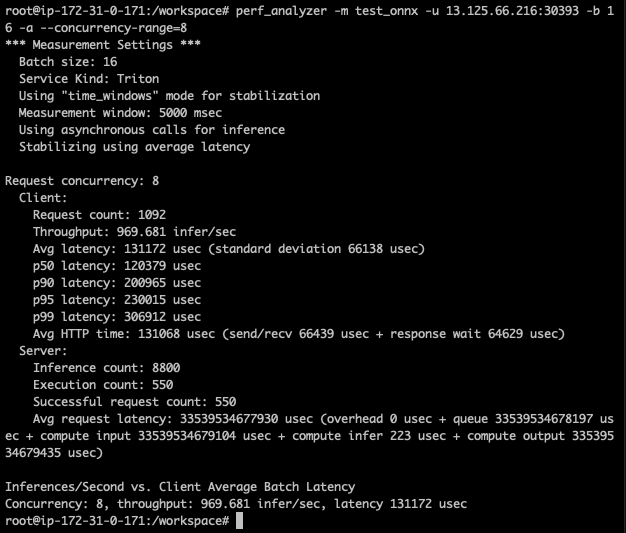
위와같이 성능측정 결과를 확인할 수 있다.
perf_analyzer -m test_onnx -u 13.125.66.216:30393 -b 16 -a --concurrency-range 1:8 -f perf.csv
서버, 클라이언트의 배치사이즈는 동일하다.
위와같이 동시요청 범위를 설정하고, 결과지표를 export 할 수 있다.
위 결과를 그래프로 그려서 분석한다.
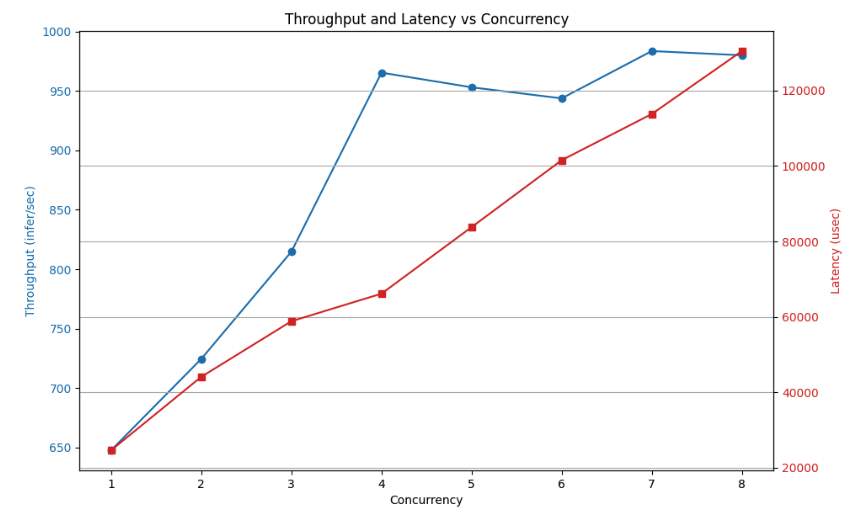
동시요청 수가 증가함에따라 rps와 latency가 증가하는것을 확인할 수 있다.
하지만 latency 증가량에 비해 rps 증가량이 그렇게 크지 않은것을 확인 할 수 있다.
즉, 동시요청 증가량을 커버하지 못하고있다.
concurreny=4 에서 최적의 성능을 보이고있다.
배치사이즈와 인스턴스 개수를 조절해가며 다양한 테스트를 진행하면 최적의 성능을 내는 설정을 찾을 수 있다.
Model Analyzer
Performance Analyzer에서 직접 값을 수정해가며 테스트를 할 수 있지만 많은 테스트가 필요하다. triton에서 이러한 과정을 자동화시켜주는 툴(Model Analyzer)을 제공한다.
설치안내에 따라 설치할 수 있고, 쿠버네티스 배포도 지원한다고 나와있다.
하지만 쿠버네티스 배포에 실패했다.
우선 문서에 나와있는 analyzer 이미지가 없다. 프로젝트의 root 위치로 이동하면 Dockerfile이 있는데 이 Dockerfile로 이미지를 빌드하고 dockerhub에 푸시했다.
이 이미지를 사용해 helm으로 배포했다.
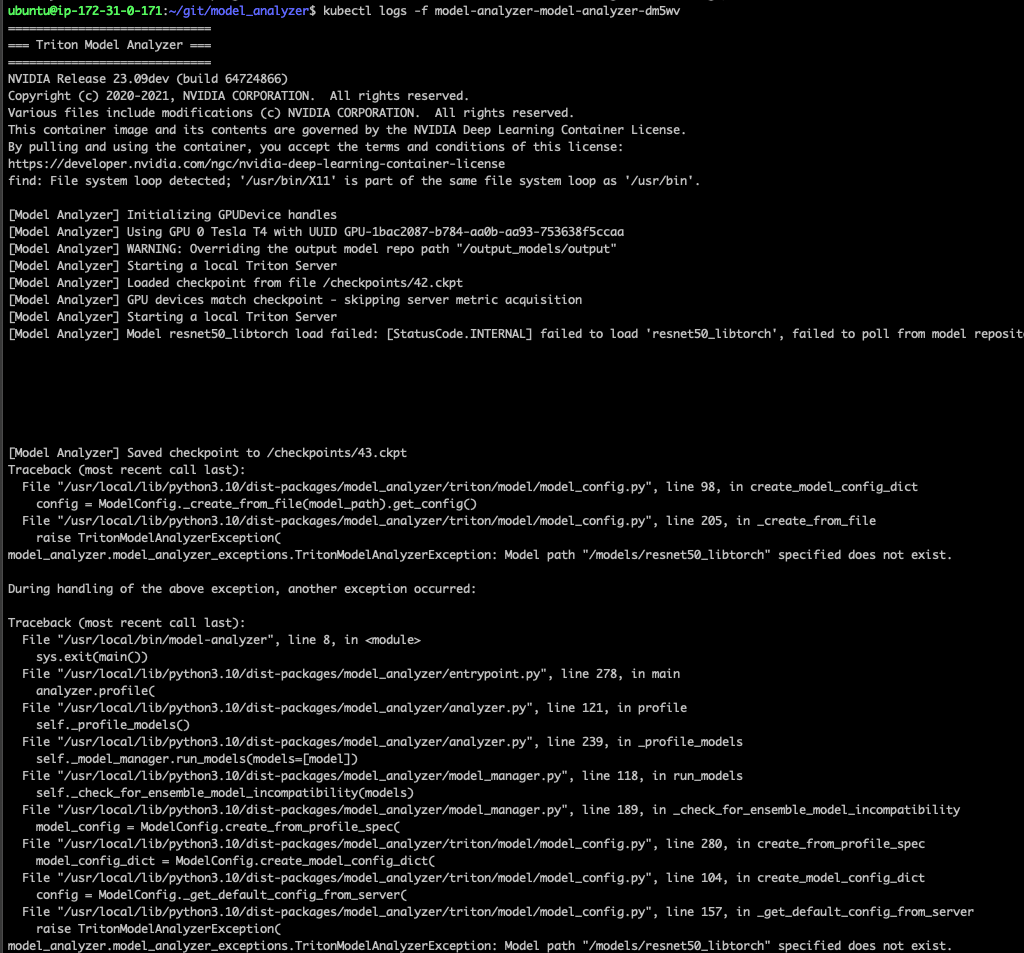
하지만 pod이 정상적으로 실행되지 않았다.
테스트로 사용할 모델들을 볼륨에 마운트했는데, 이 모델을 찾지 못하는것으로 보인다.
pod 내부 /models 디렉토리를 ls 로 조회해봤는데 제대로 마운트되지 않은것으로 보인다. 호스트에서 가지고있던 파일과 디렉토리 없이 /models 디렉토리만 생성되어있었다.
hostPath로 볼륨을 마운트해서 문제가 발생한거라 생각했다. 마스터노드의 디스크에 마운트할 모델들이 있는데 실제로 워커노드에 pod이 배포된다.
즉 워커노드에는 모델이 없는것이다. 그렇다고 모든 노드들에서 파일을 똑같이 관리하는것은 너무 비효율적인 방법이라고 생각해 pv, pvc를 사용한 클러스터 내부 파일공유를 생각했다.
하지만 pv, pvc를 설정했음에도 모델들이 정상적으로 마운트되지 않았다. k8s에 대한 경험과 공부가 너무 부족했다.
우선은 클러스터에 배포하지 않고 model analyzer 컨테이너를 실행시켜 테스트해보려고한다.
문서를 보면 도커로 분석하는 방법을 안내하고있다.
docker run -it --gpus all \
-v /var/run/docker.sock:/var/run/docker.sock \
-v /home/ubuntu/git/model_analyzer/examples/quick-start:/home/ubuntu/git/model_analyzer/examples/quick-start \
-v /home:/home \
--net=host nvcr.io/nvidia/tritonserver:23.07-py3-sdk
컨테이너를 실행시키고 모델 분석을 시작한다.
model-analyzer profile --model-repository /home/ubuntu/git/model_analyzer/examples/quick-start --profile-models add_sub --triton-launch-mode=docker --output-model-repository-path /home/output_models/result --export-path profile_results --override-output-model-repository
위와같이 여러 설정을 만들며 모델의 성능을 측정한다.
하지만 설정 최대값을 제한하지 않고 분석하면 완료하는 데 최대 60분이 소요될 수 있다(공식문서에서 확인가능).
문서에서 안내하는대로, 짧게 실행하여 테스트하고싶은 경우 옵션을 추가해 설정 최대값을 제한한다.
model-analyzer profile --model-repository /home/ubuntu/git/model_analyzer/examples/quick-start --profile-models add_sub --triton-launch-mode=docker --output-model-repository-path /home/output_models/result --export-path profile_results --override-output-model-repository --run-config-search-max-concurrency 2 --run-config-search-max-model-batch-size 2 --run-config-search-max-instance-count 2
분석이 끝나면 요약한 내용이 저장된다.

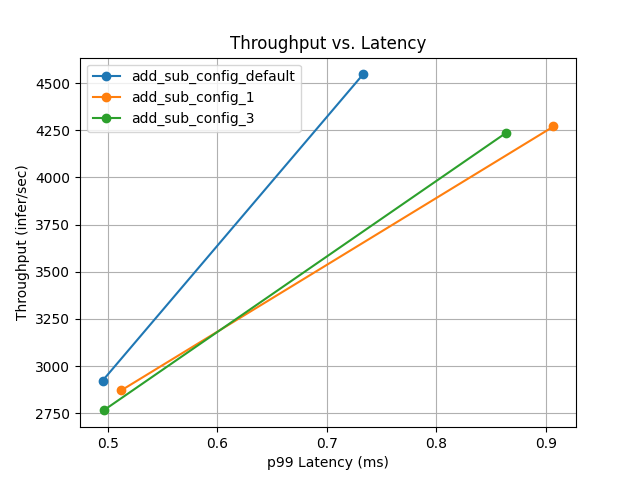
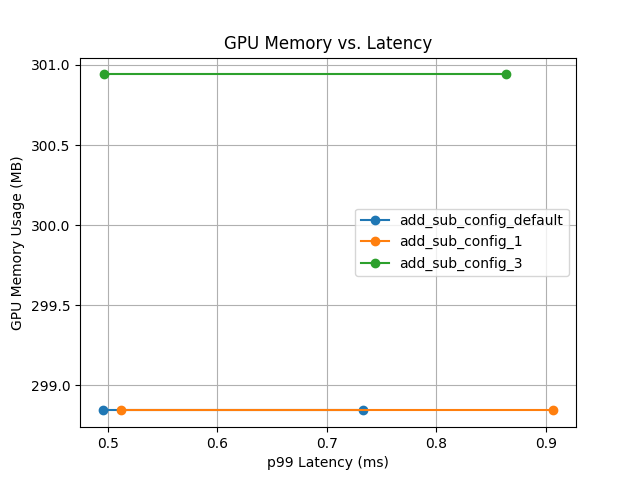
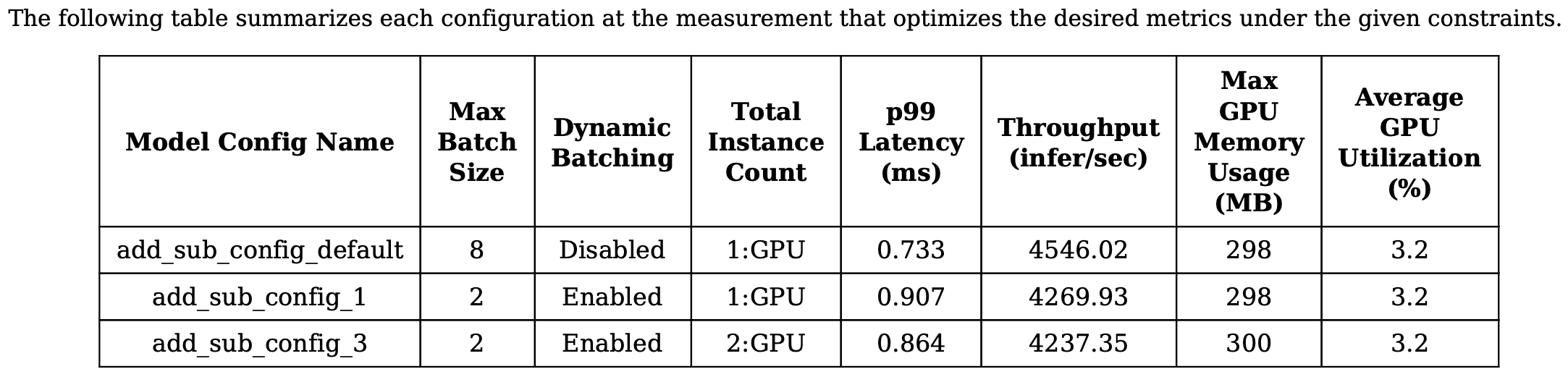
위 내용은 요약본이며, 각 설정별 분석내용이 모두 있다.
output_models에 각 config이 어떤 값으로 추론테스트를 진행했는지 확인할 수 있는 pbtxt 파일이 저장되어있다.

좋은 글 감사합니다. 자주 방문할게요 :)