ec2 쿠버네티스 클러스터 구축 포스팅에 이어 클러스터의 worker 노드에 nvidia gpu를 할당하는 내용을 다뤄보려고한다.
gpu 할당
NVIDIA Container Toolkit과 k8s용 nvidia 장치 플러그인을 설치해야한다.
컨테이너에서 gpu를 사용하는 경우 호스트에서 자원을 마운트해야하는데, NVIDIA Container Toolkit은 이를 자동으로 해준다.
기본적으로 호스트에 nvidia 드라이버가 설치되어 있어야 하는데, 본 포스팅에서 사용하는 ec2 인스턴스의 AMI에는 위 드라이버가 모두 설치되어있다. 직접 호스트의 nvidia 드라이버를 설치할 필요는 없고, 바로 환경을 구성하면 된다.
nvidia k8s 플러그인에 자세한 방법들이 나와있다.
런타임 환경으로 docker가 아닌 containerd를 선택했다.
우선 nvidia-container-toolkit를 설치한다.
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/libnvidia-container/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | sudo tee /etc/apt/sources.list.d/libnvidia-container.listsudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
그리고, containerd 런타임의 구성파일을 설정한다.
/etc/containerd/config.toml
version = 2
[plugins]
[plugins."io.containerd.grpc.v1.cri"]
[plugins."io.containerd.grpc.v1.cri".containerd]
default_runtime_name = "nvidia"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes]
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia]
privileged_without_host_devices = false
runtime_engine = ""
runtime_root = ""
runtime_type = "io.containerd.runc.v2"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia.options]
BinaryName = "/usr/bin/nvidia-container-runtime"sudo systemctl restart containerd
설정을 마치고 containerd를 재시작한다.
이제 쿠버네티스에서 gpu 할당이 가능하게 daemonset을 배포한다.
$ kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.14.1/nvidia-device-plugin.yml
README에도 나와있지만, 위 명령은 테스트를 위한 정적인 데몬셋이고 production에서 helm을 사용한 플러그인 배포를 권장한다.
$ cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
restartPolicy: Never
containers:
- name: cuda-container
image: nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda10.2
resources:
limits:
nvidia.com/gpu: 1 # requesting 1 GPU
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
EOFgpu를 할당해 pod을 실행시키고 정상적으로 실행되는지 확인한다.
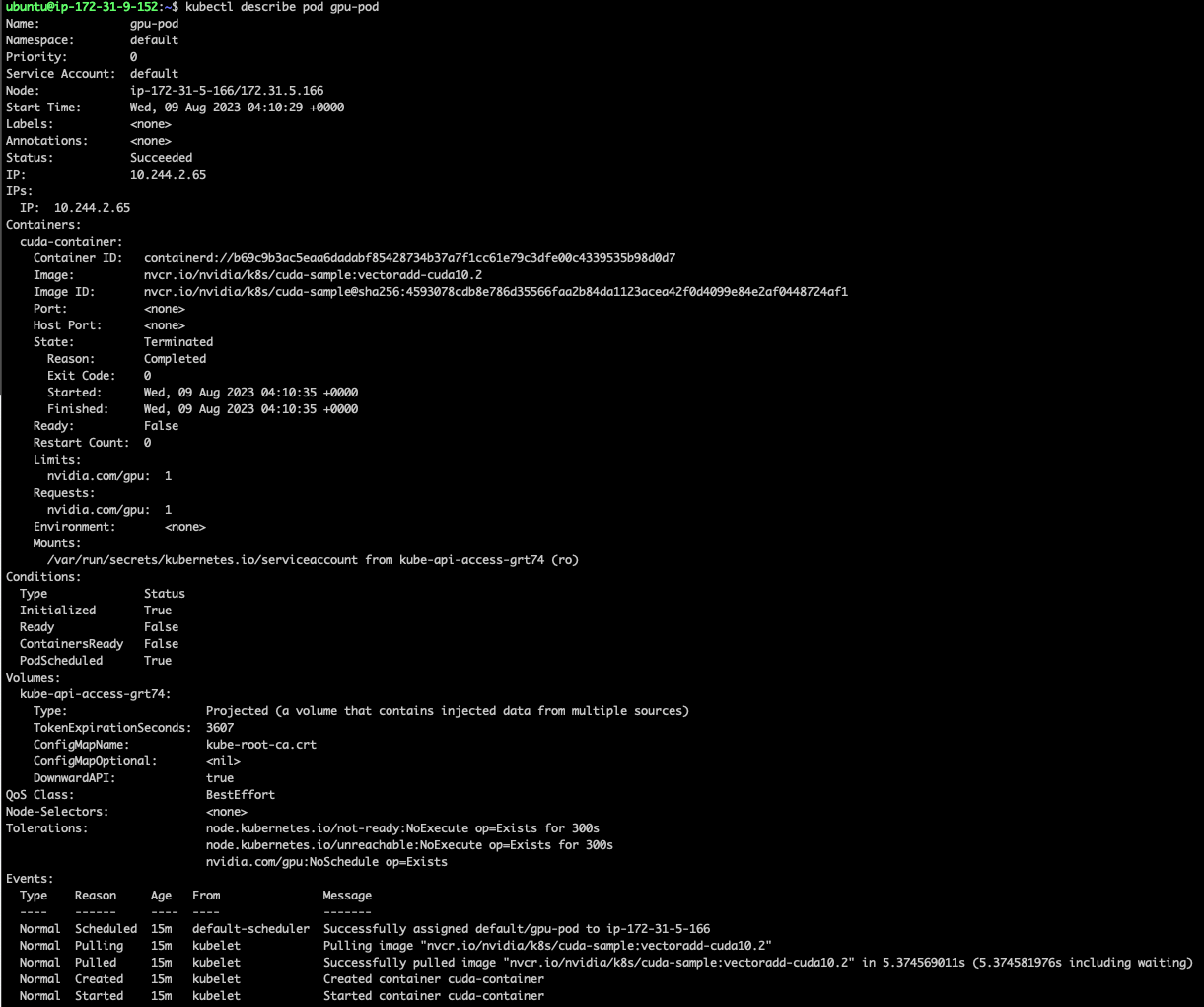
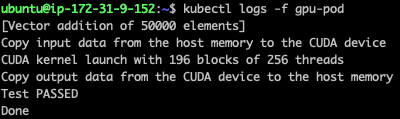
정상적으로 처리되었다.
triton 서버 배포
문서를 보면 k8s에서 triton 서버를 배포하는 방법이 나와있다.
배포 예시중에 aws가 있지만, 실제 운영환경은 온프레미스가 될것같아 온프레미스 배포예시를 기준으로 환경을 구축했다.
모든 노드에 helm 이 설치되어있다고 가정한다.
metric 서버 배포
추론 서버 메트릭은 Prometheus에서 수집하고 Grafana로 볼 수 있다.
kube-prometheus-stack Helm 차트를 사용해 환경을 구성한다.
ServiceMonitorSelectorNilUsesHelmValues플래그는 Prometheus가 배포후 추론 서버 메트릭을 찾는데 필요하다고 한다.
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
helm install example-metrics --set prometheus.prometheusSpec.serviceMonitorSelectorNilUsesHelmValues=false prometheus-community/kube-prometheus-stack
클러스터에 배포되었을 뿐이고, 로컬에서 접속할 수 없다.
ngrok과 포트포워딩으로 로컬에서 접속 가능하게 설정했다.
Triton Inference Server Dashboard 템플릿을 사용해 대시보드를 생성했다.
inference 서버 배포 설정
value.yaml 파일을 보면
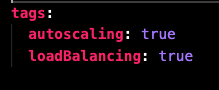
오토스케일링과 로드밸런싱 설정이 가능한데, 오토스케일링 기능은 필요없어서 false 로 수정한다.
처음에는
true로 놓고 배포를 시도했으나
Error: INSTALLATION FAILED: unable to build kubernetes objects from release manifest: resource mapping not found for name: "triton-hpa" namespace: "default" from "": no matches for kind "HorizontalPodAutoscaler" in version "autoscaling/v2beta2"
ensure CRDs are installed first
위 에러가 발생했다. 추가적인 의존성 설정? 이 필요한 것 처럼 보이는데 당장 필요하지 않아 해당 옵션을 비활성화했다.
docs/example/fetch_models.sh 스크립트를 실행하면 로컬에 테스트용 모델 저장소를 다운로드 할 수 있다. 모델저장소를 디스크가 아니라, s3 저장소를 사용하고싶어 s3에 버킷(triton-inference-bucket)을 생성하고 업로드했다.
추론서버를 배포하면 모델을 저장소에서 읽어와야한다. k8s 온프레미스 예시에는 s3 사용을 고려한 설정이 아니라 직접 바꿔줘야한다.
values.yaml 파일에
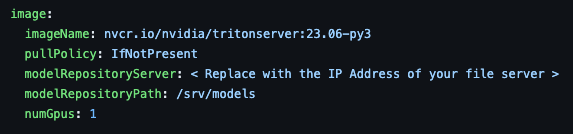
위와같이 초기값이 정의되어있는데,
image:
imageName: nvcr.io/nvidia/tritonserver:23.06-py3
pullPolicy: IfNotPresent
modelRepositoryPath: s3://triton-inference-bucket/model_repository
numGpus: 1modelRepositoryPath를 s3 저장소로 수정한다.
이 저장소에 접근가능한 권한을 얻기위해 region, acess key, secret key가 필요하다.
secret:
region: AWS_REGION
id: AWS_SECRET_KEY_ID
key: AWS_SECRET_ACCESS_KEY위 정보를 추가한다.
base64로 인코딩해서 추가해야한다.
template 디렉토리에 배포를 위한 yaml 파일들이 정의되어있다.
values.yaml 에 추가한 aws credentials 값을 secrets.yaml 파일에 정의해 컨테이너 실행 시 제공해준다.
apiVersion: v1
kind: Secret
metadata:
name: aws-credentials
type: Opaque
data:
AWS_DEFAULT_REGION: {{ .Values.secret.region }}
AWS_ACCESS_KEY_ID: {{ .Values.secret.id }}
AWS_SECRET_ACCESS_KEY: {{ .Values.secret.key }}deployment.yaml 파일도 수정해줘야한다.
spec.template.spec.containers 필드에 모델을 볼륨에 마운트하는 코드가 있다.
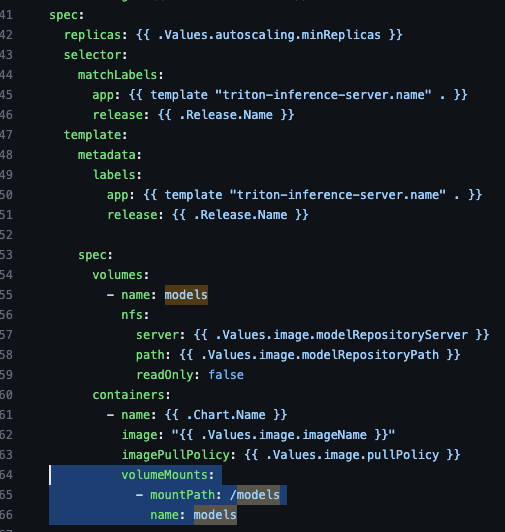
볼륨 마운트부분을 지우고, aws credentials 값을 환경변수로 주입해준다. 그리고 args를 추가해 모델 저장소를 values.yaml에 정의한 s3 저장소로 명시한다.
...
spec:
containers:
- name: {{ .Chart.Name }}
image: "{{ .Values.image.imageName }}"
imagePullPolicy: {{ .Values.image.pullPolicy }}
resources:
limits:
nvidia.com/gpu: {{ .Values.image.numGpus }}
args: ["tritonserver", "--model-store={{ .Values.image.modelRepositoryPath }}",
"--model-control-mode=poll",
"--repository-poll-secs=5"]
env:
- name: AWS_DEFAULT_REGION
valueFrom:
secretKeyRef:
name: aws-credentials
key: AWS_DEFAULT_REGION
- name: AWS_ACCESS_KEY_ID
valueFrom:
secretKeyRef:
name: aws-credentials
key: AWS_ACCESS_KEY_ID
- name: AWS_SECRET_ACCESS_KEY
valueFrom:
secretKeyRef:
name: aws-credentials
key: AWS_SECRET_ACCESS_KEY
...다음으로 로드밸런싱을 활성화한다.
docs에 따르면, traefik-helm-chart를 통해 리버스 프록시를 배포해야한다.
helm install traefik traefik/traefik
로드밸런싱을 활성화 한 후 Chart.yaml이 있는 디렉토리에서 helm으로 배포한다.
helm dependency build
helm install example .
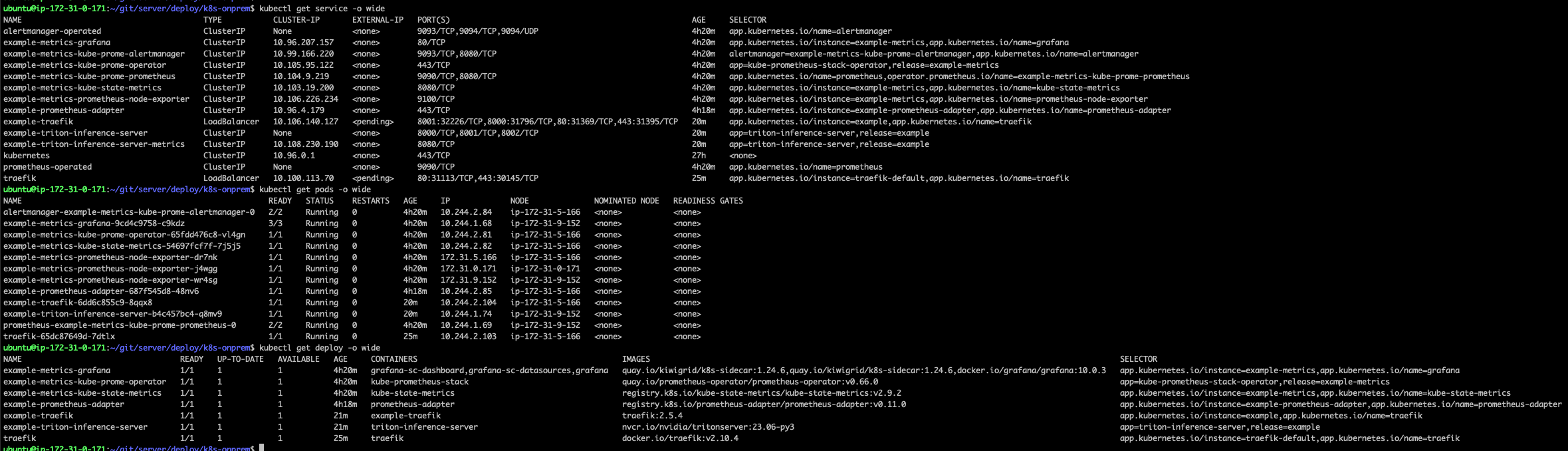
정상적으로 배포되었다.
클러스터에 요청하기 위해 ip를 확인한다.
kubectl get svc -l app.kubernetes.io/name=traefik -o=jsonpath='{.items[0].spec.clusterIP}'
10.106.140.127
example-traefik service의 로드밸런서 ip가 조회된다.
curl 10.106.140.127:8000/v2
http 요청을 하면 정상적으로 응답이 돌아온다.
클러스터에 참여한 노드 호스트에서 정상적으로 동작하는것을 확인했으니, 클러스터 외부(로컬)에서 public ip로 요청해본다.
8000 포트는 31796 포트로 포워딩되어있다.
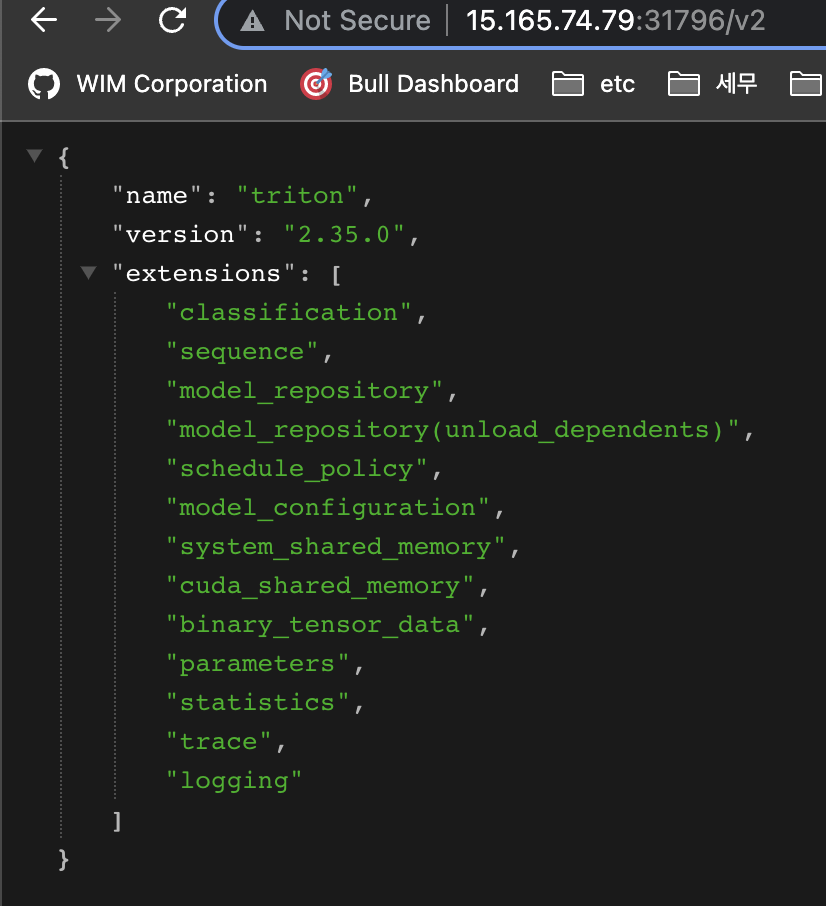
정상적으로 조회된다.
여기서 한가지 의문이 들었는데, 조회된 서비스 목록에 아까 helm으로 설치했던 리버스 프록시용 로드밸런서가 있다. 그런데, 이 로드밸런서로 요청할 일이 없다.
helm uninstall traefik
삭제해도 정상적으로 동작한다.
Chart.yaml을 보면 traefik 의존성이 있다. 직접 install 하지 않아도 Chart.yaml 로 배포하는 과정에 의존성이 알아서 관리된게 아닐까 하는 생각이들어, 직접 의존성을 제거하고 다시 테스트해봤다.
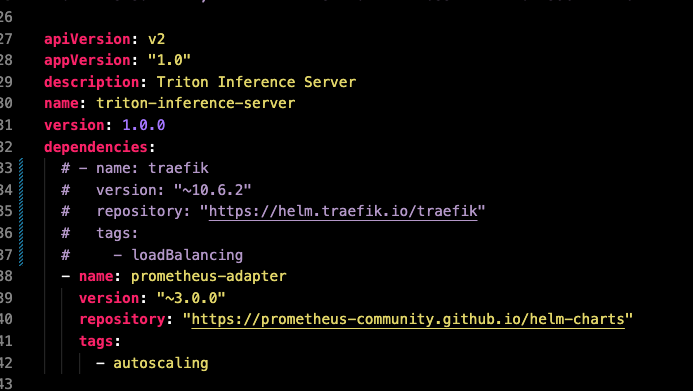
traefik 의존성을 주석처리한다.
helm uninstall example
rm Chart.lock
helm dependency build
helm install example .
그리고 다시 배포했다.
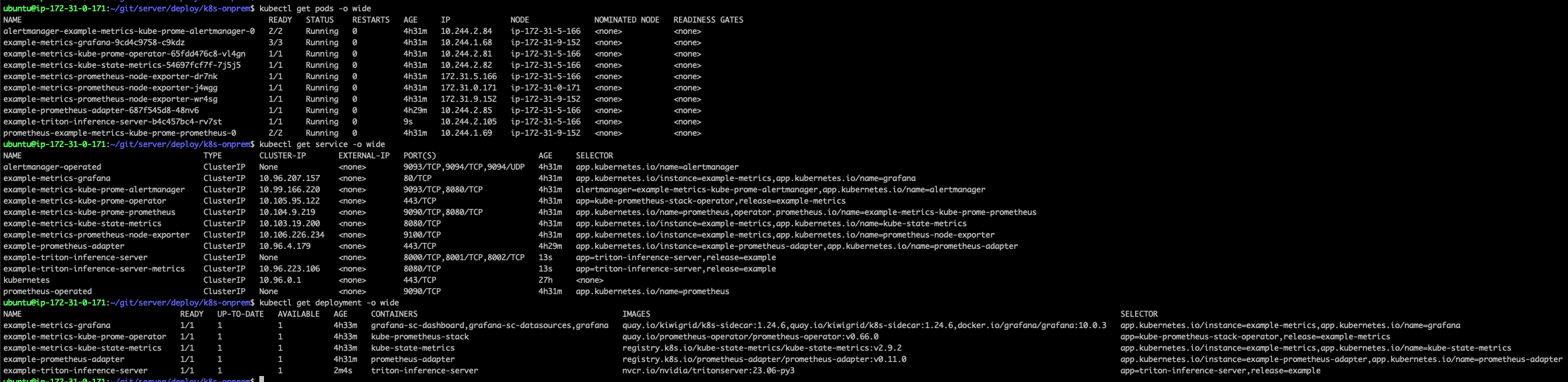
로드밸런서가 배포되지 않았다. Chart.yaml에서 의존성을 알아서 관리해주는것을 확인했다.
쿠버네티스에대한 이해도가 얕아 의존성 관리하는 부분도 직접 겪어보고서야 알게되었다.
다시 의존성을 추가하고 배포한다.
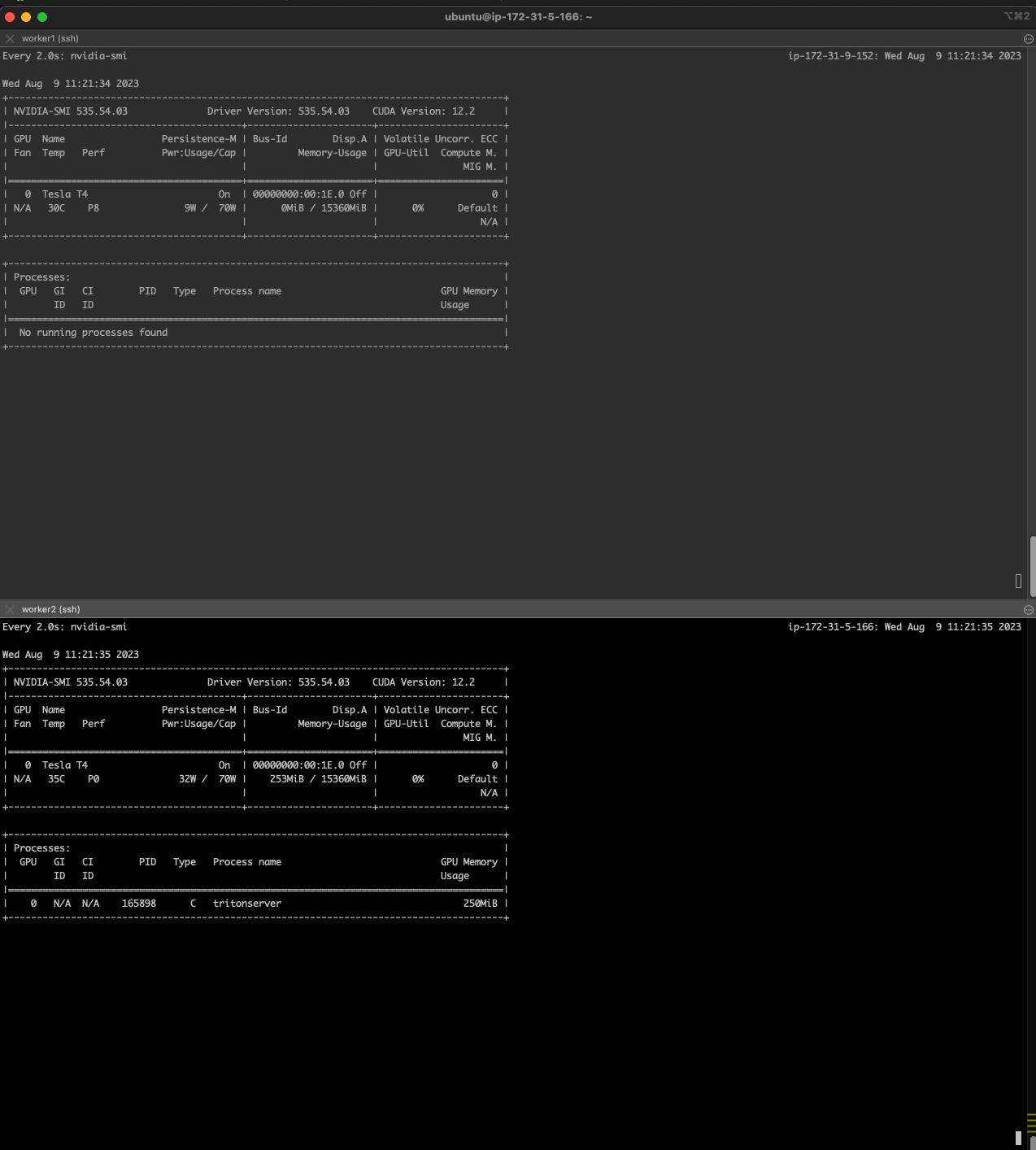
deployment의 pod를 1개로 배포했기 때문에 워커노드 하나의 그래픽카드에 프로세스가 올라갔다.
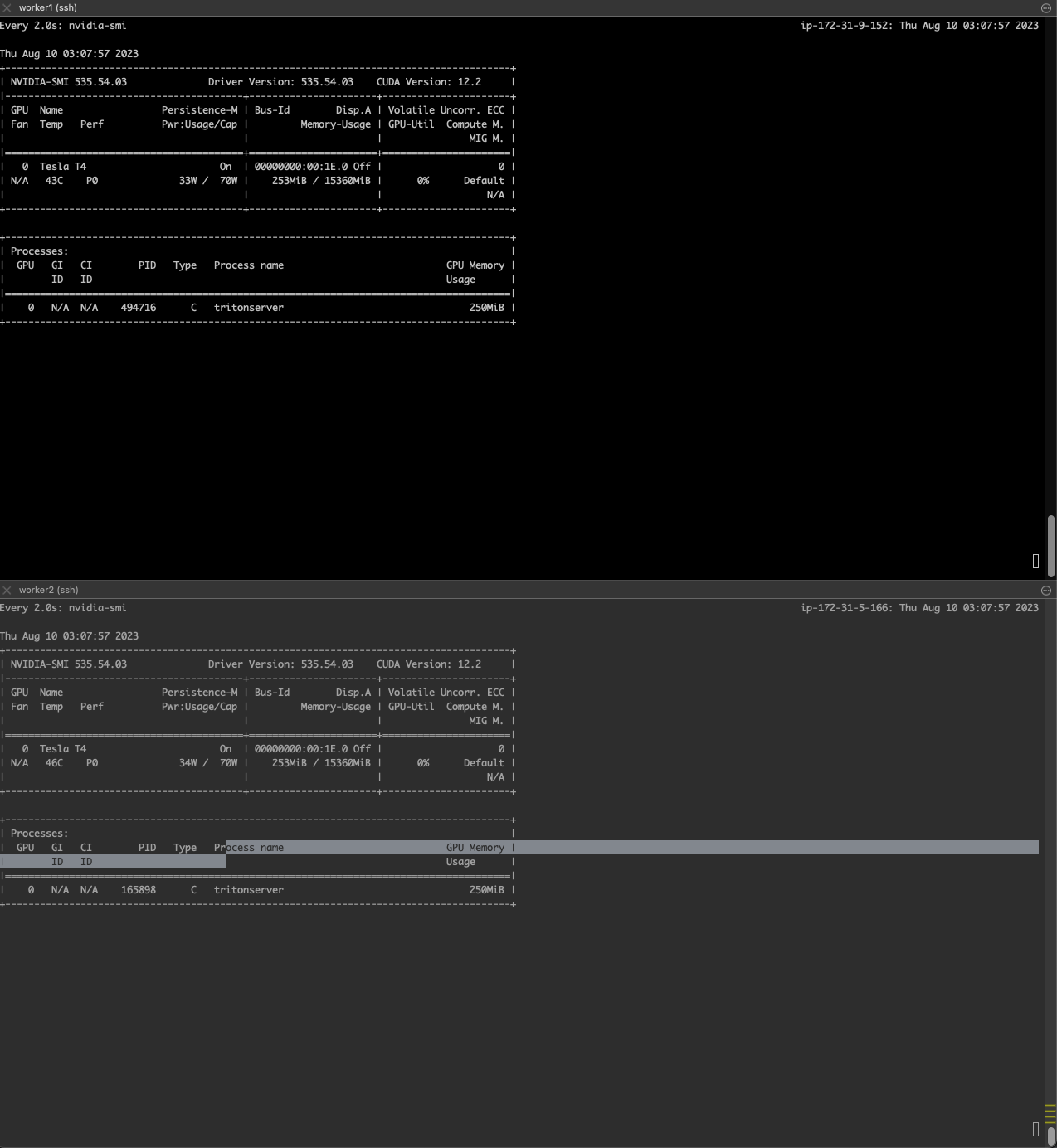
pod을 2개로 스케일아웃하면 각각의 워커노드에서 gpu를 사용하는 triton process가 실행중인것을 확인할 수 있다.
추론 요청
추론서버가 배포되었다.
triton에서 제공하는 client sdk로 요청해보려고한다.
docs/getting_started/quickstart.md 파일을 보면 추론서버에 요청을 보내는 방법이 나와있다.
클라이언트 도커 컨테이너를 실행시킨다.
docker pull nvcr.io/nvidia/tritonserver:23.06-py3-sdk
docker run -it --rm --net=host nvcr.io/nvidia/tritonserver:23.06-py3-sdk
/workspace/install/bin/image_client 파일이 클라이언트 파일이다.
-u 옵션에 클러스터 ip와 http 요청을 받는 포트를 추가한다.

정상적으로 처리되었다.
2개의 추론서버 pod에 부하분산이 잘 이루어지는지 확인하기위해 100회 반복요청했고, 그라파나에서 확인했다.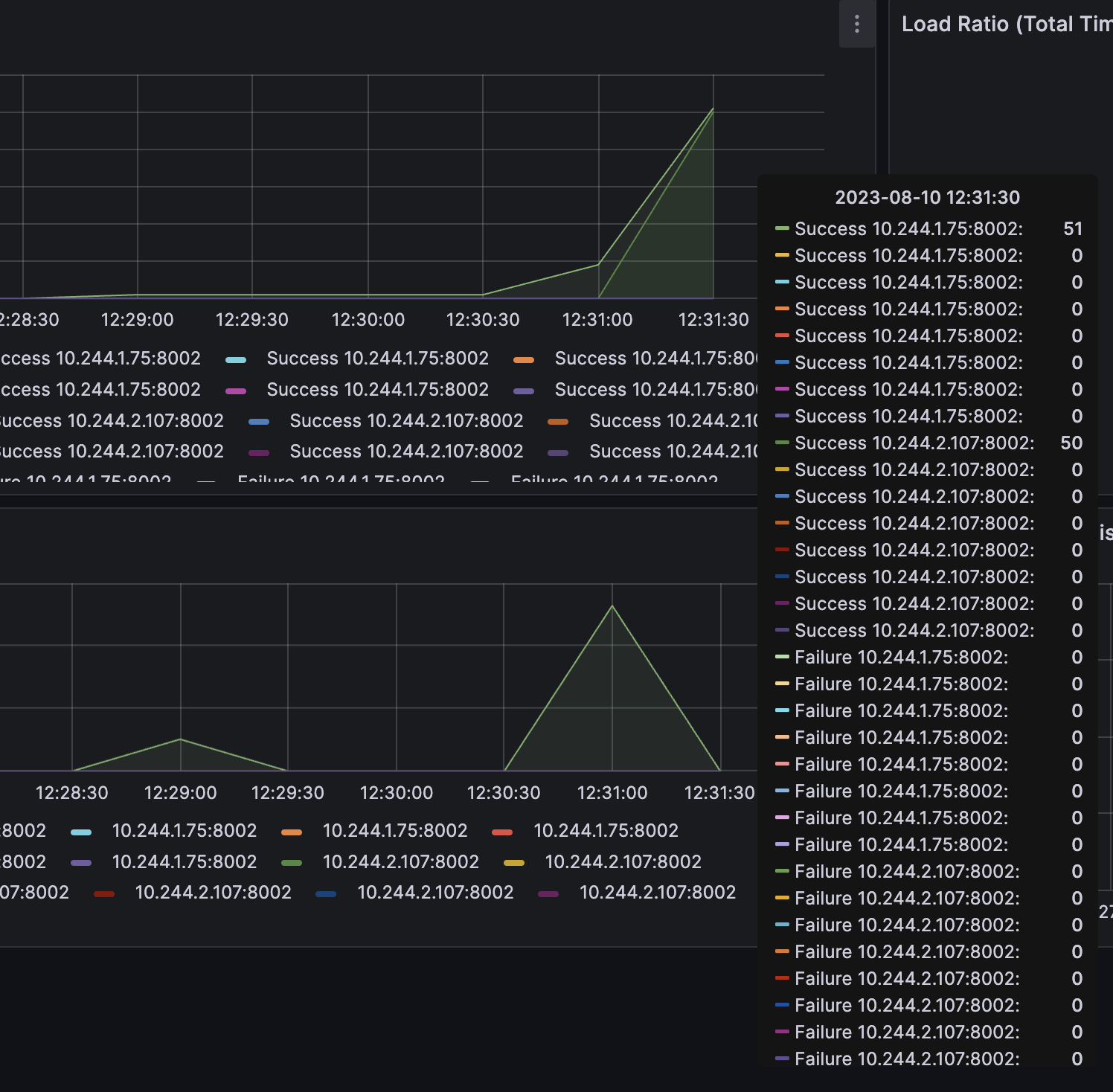
for i in {1..100}; do /workspace/install/bin/image_client -m densenet_onnx -c 3 -s INCEPTION -u 10.107.148.47:8000 /workspace/images/mug.jpg; done
부하분산이 잘 되고있는것을 확인할 수 있다.
각 워커노드에 pod이 하나씩 위치하고있는데, 만약 워커노드 갯수 이상의 pod이 배포되면 어떻게될지 의문이생겼다.
kubectl scale deployment example-triton-inference-server --replicas=3
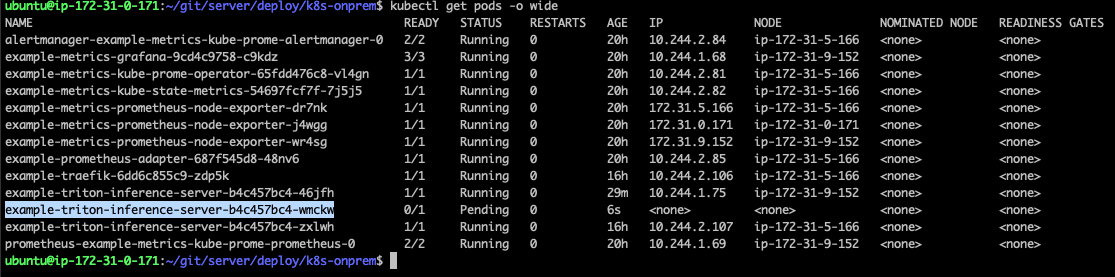
pending 상태에서 바뀌지않아 describe로 이벤트를 확인했다.
0/3 nodes are available: 1 node(s) had untolerated taint {node-role.kubernetes.io/control-plane: }, 2 Insufficient nvidia.com/gpu. preemption: 0/3 nodes are available: 1 Preemption is not helpful for scheduling, 2 No preemption victims found for incoming pod..
위와같은 메시지가 있었다.
위 내용을 정리하면 다음과같다.
- 0/3 nodes are available: 총 3개의 노드 중에서 사용 가능한 노드가 없습니다.
- 1 node(s) had untolerated taint {node-role.kubernetes.io/control-plane: }: 1개의 노드는 node-role.kubernetes.io/control-plane라는 taint가 있어서 해당 taint를 용인할 수 없는(untolerated) pod는 해당 노드에 스케줄링되지 않습니다.
- 2 Insufficient nvidia.com/gpu: 나머지 2개의 노드는 GPU 리소스가 부족합니다.
- preemption: 0/3 nodes are available: preemption(더 낮은 우선순위의 Pod를 종료하고 더 높은 우선순위의 Pod를 스케줄링하는 메커니즘)을 통해서도 사용 가능한 노드를 찾을 수 없습니다.
- 1 Preemption is not helpful for scheduling: preemption을 사용하여도 스케줄링 문제를 해결할 수 없습니다.
- 2 No preemption victims found for incoming pod: 스케줄링을 위해 중단시킬(사용 중지) 가능한 낮은 우선순위의 Pod(victims)가 없습니다.
master node 에는 배포되지 않는것이 맞기때문에 gpu 리소스가 부족하다는 메시지가 원인으로 보인다.
다시 생각해보니, 각 워커노드는 하나의 그래픽카드가 꽂혀잇는 인스턴스였다. 각 노드가 gpu를 1개씩 가지고있고 서비스를 배포할 때 gpu를 하나씩 할당했으니 gpu가 모자란게맞다.
pod이 2개면 gpu를 2개 사용해서 딱 맞는데 pod이 1개 추가되었으니 pod 개수 > gpu 개수 가 된다.
테스트용 모델이라 그런지 메모리 사용량이 너무 낮은데(381MiB / 15360MiB) 다른프로세스를 할당할 수 없으니 자원을 제대로 활용하지 못한다는 느낌이 들었다.
추론 테스트 문제점
triton 예시에서 제공하는 모델이 아니라, 커스텀 모델을 저장소에 업로드하고 테스트하려고한다.
예시에서 제공된 모델을 확인했는데 일관적이지 않은? 구조였다.
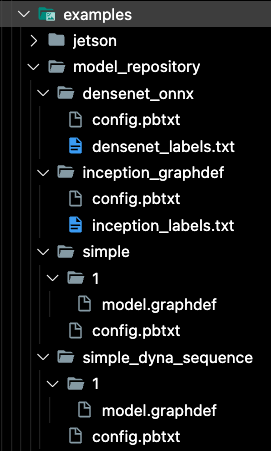
인공지능 개발자가 아니라 모델관련 파일들의 확장자에 대해서 잘 모른다. 하지만, 추론과정에 weight 파일이 필요하다는것은 알고있다.
아까 테스트했던 densenet_onnx 모델의 weight 파일이 보이지않는다.
triton 깃헙에서 모델 저장소에대한 문서를 발견했다.
<model-repository-path>/
<model-name>/
[config.pbtxt]
[<output-labels-file> ...]
<version>/
<model-definition-file>
<version>/
<model-definition-file>
...
<model-name>/
[config.pbtxt]
[<output-labels-file> ...]
<version>/
<model-definition-file>
<version>/
<model-definition-file>
...
...기본적으로 위 구조이며, onnx 모델 저장소의 예시는 아래와같다.
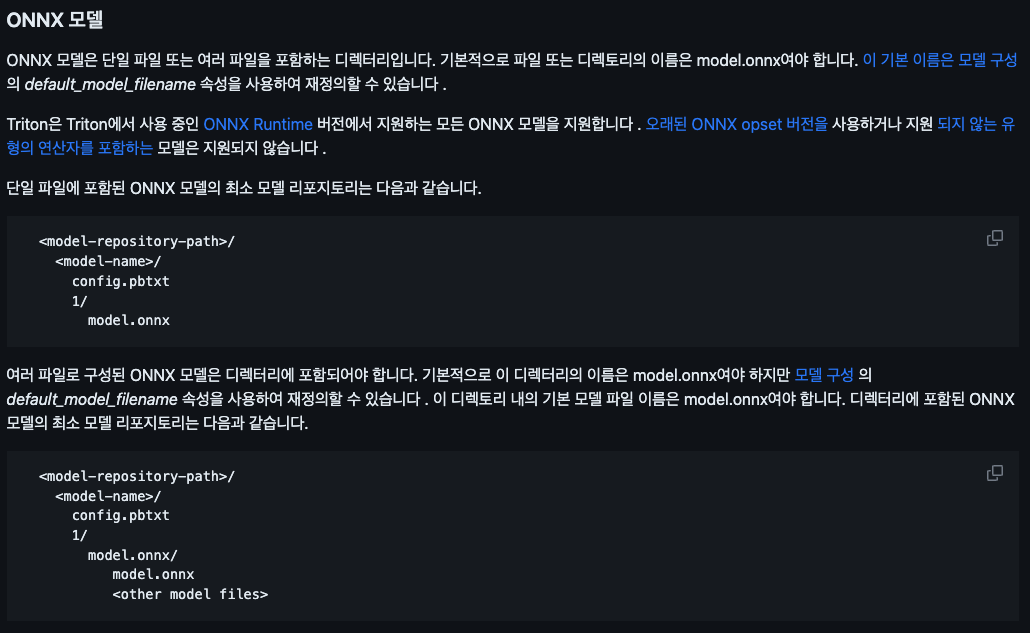
이 문서에는 model.onnx 라는 weight 파일이 있는데, 스크립트로 다운받았던 model_repositroy에는 weight 파일이 없는것이다.
즉, 본 포스팅에서 테스트했던 추론결과는 weight 파일 없이 추론한 결과물이며 통신이 정상적으로 되는지 정도의 의미만 있었던것이다.
모델 변경
새로운 모델과 weight 파일을 업로드하고 테스트를 하려고한다.
3dim-input-layers 모델을 찾았고, pbtxt도 함께 첨부되어있었다.
모델 저장소에 모두 업로드하고 추론서버를 배포하는데 성공했다.
배포 후 어떻게 추론서버에 요청해야할지 몰라서 많이 당황스러웠다.
위에서 진행했던 예제는 client 파일이 첨부되어 있어서 따라서 실행시키면 되었다. 하지만 커스텀 모델의경우 제각각 요청방식이 있을텐데, 어떻게 알 수 있을까?
우선 triton-inference-server 레파지토리에서 http server 코드를 찾았다.
c 언어에 익숙하지않아 한눈에 들어오지 않았지만,
void
HTTPAPIServer::HandleInfer추론 엔드포인트로 추측되는 함수를 찾았다.
위 함수의 코드를 gpt에 물어보고 확신을 얻었다.
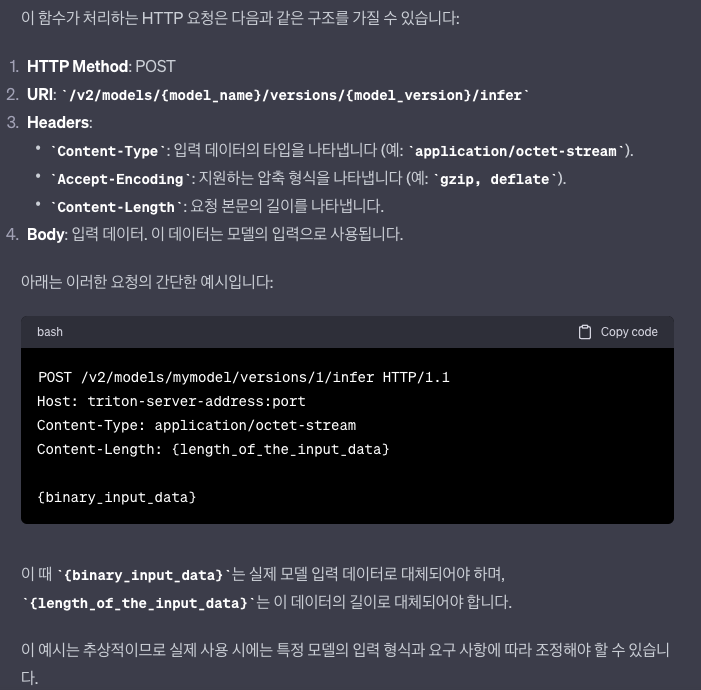
하지만, {binary_input_data}에 어떤값을 넣어야하는지 알 수 없었다.
이쯤되니 모델에도 요청/응답 스키마가 있지않을까? 하는 생각이 들었고, .pbtxt 파일이 이와 유사해보였다.
모델의 메타데이터 정도로 생각하고있었는데 잘 보면 input, output 이라는 필드가있다.
...
input [
{
name: "input"
data_type: TYPE_FP32
dims: [3, 224, 224]
}
]
output [
{
name: "output"
data_type: TYPE_FP32
dims: [3]
label_filename: "test_labels.txt"
}
]
...하지만 이 필드의 내용이 뭘 의미하는지 알 수 없었다.
pbtxt 구성 문서를 다시 확인하고, gpt를 사용했다.
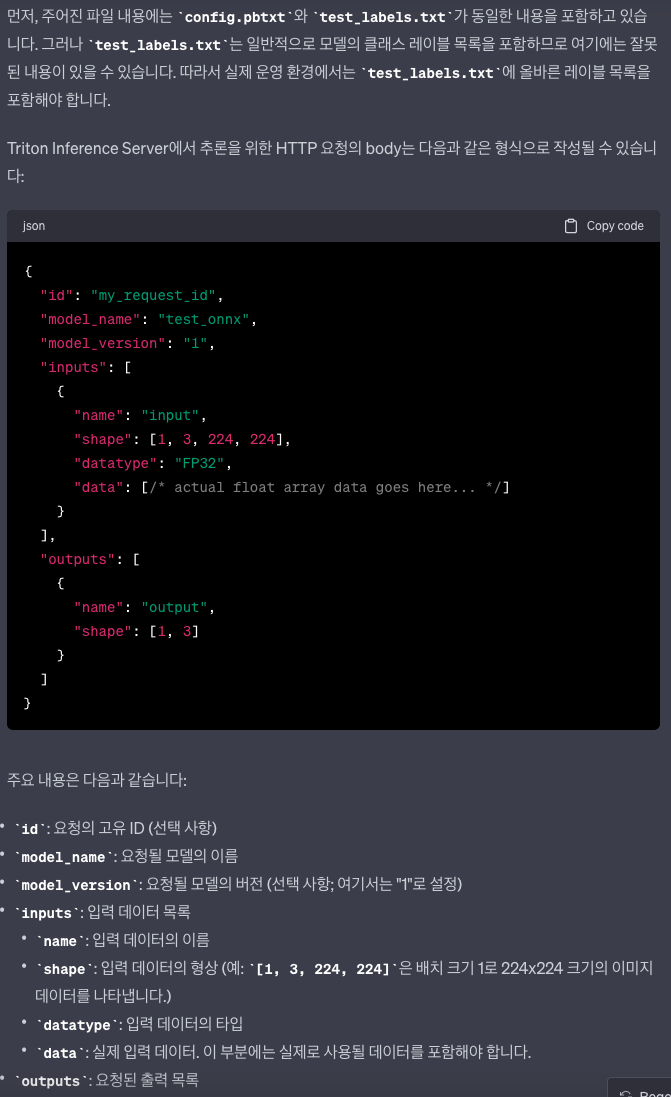
모델명이나 버전은 http 요청의 uri에 포함되어있으니 실제로 바이너리 데이터에 해당되는 부분은 inputs, outputs 필드로 예상된다.
위 형태에맞는 요청을 만들어야한다.
python - <<END > input_data.json
import json
dummy_data = {
"inputs": [
{
"name": "input",
"shape": [1, 3, 224, 224],
"datatype": "FP32",
"data": [0] * (1 * 3 * 224 * 224)
}
],
"outputs": [
{
"name": "output",
"shape": [1, 3]
}
]
}
print(json.dumps(dummy_data))
END
curl -X POST "http://10.107.8.92:8000/v2/models/test_onnx/versions/1/infer" \
-H "Content-Type: application/json" \
--data @input_data.json./request_script.sh
{"model_name":"test_onnx","model_version":"1","outputs":[{"name":"output","datatype":"FP32","shape":[1,3],"data":[0.3704143762588501,0.32775938510894778,0.3018261790275574]}]}
요청이 처리되었다.

위 내용에 따르면 pbtxt는 모델에 따라 필요할수도 있고, 아닐수도있다. 입력값이 있는 모델에는 필요할 것 같다.
