PROJECT 1-2 GIT is here
MY NOTION is here
PROJECT 1: THREADS_ (2023 4/26 수요일 밤까지) - 1주
PROJECT 2: USER PROGRAMS (2023 5/8 월요일 밤까지) - 1.5주
#케로베로스_코딩법
 동일 프로그램들의 전 기수 선배들이 당시 적었던 회고록들을 열심히 열람했다. 눈에 띄었던 내용 중 하난 멀티 허브를 통해 한 모니터를 두고 여러 개의 키보드를 연결해 함께 고민하며 코딩하는 장면이었다.
동일 프로그램들의 전 기수 선배들이 당시 적었던 회고록들을 열심히 열람했다. 눈에 띄었던 내용 중 하난 멀티 허브를 통해 한 모니터를 두고 여러 개의 키보드를 연결해 함께 고민하며 코딩하는 장면이었다.  운 좋게 난 연수과정 초기에 목돈 들여 고급 허브를 장만했었고, 우리 팀은 함께 한 줄 한 줄 적어보는 식의 코딩을 진행하기로 했다. 자꾸 서로의 모니터를 향해 몸을 기울여 작업하는 것보다 이 편이 합리적이라 판단했다.
운 좋게 난 연수과정 초기에 목돈 들여 고급 허브를 장만했었고, 우리 팀은 함께 한 줄 한 줄 적어보는 식의 코딩을 진행하기로 했다. 자꾸 서로의 모니터를 향해 몸을 기울여 작업하는 것보다 이 편이 합리적이라 판단했다. 좋은 결정이었다. 나중에는 기계를 추가로 더 연결해 장관이었다. (벨킨 만세~)
좋은 결정이었다. 나중에는 기계를 추가로 더 연결해 장관이었다. (벨킨 만세~)
Browsing about the theme...
나는 내가 이해한 것을 정리정돈하는 맥락으로, 순차적으로 정리할 것이다. 그래서 어쩌면 Pintos과제의 수행과 직계되지 않는 원초부터 시작한다...
📌 너무 길어져서 글을 나누기로 했다.
기나긴 복습의 출발에서는, 용어의 뜻을 알아보며 다이브하는 형식으로서 해당 프로젝트에서 필요한 개념들을 정리해봤다.
Project 1 개념 (1-1) | 프로세서, 프로세스, CPU와 기억장치들
Project 1 도입 (1-2) | 인터럽트, 예외
(위의 게시물들은 지금 이 글과 함께 쓴 하나의 글이다. 소개하는 인덱스 순서대로 읽었을 때 모두 자연스레 이어지므로 내가 열심히 쓴 내용들에 대한 총체적인 확인을 권장한다. (제발))
인터럽트가 발생하는 과정과 목적
자, 우선... 다시 정리한다.
CPU는 명령어 한 줄에 대한 작업이 끝날 때마다 매번 Interrupt line을 체크하여 현재 들어온 Interrupt가 있는지 없는지 확인한다고 하였다.
Interrupt란,
1️⃣ i/o device controller 들에 의해서 "나 작업 도와줘, 파일 읽어줘~"라며 던져지게 되거나
2️⃣ exception, system call과 같은 trap이 걸려 "저기 CPU야! 나 OS인데~ 이것 좀 처리해줘~" 라며 주어지게 되는 상황이다.
인터럽트의 과정에 대해 어셈블리 단으로 다시 짚어보자.
인터럽트가 발생하면 → 프로세서는 스택으로 향하는 PC와 다른 레지스터를 포함하는 현재 프로그램 상태를 저장한다.
→ 그리고 프로세서는 메모리 내 인터럽트 핸들러(== ISR, interrupt service routine)가 위치한 곳으로 jump
→ 인터럽트 핸들링이 수행되고 → 미리 저장된 인터럽트 발생 프로그램으로 복귀(return)한다.
→ 이후 인터럽트 발생 위치에서부터 다시 프로세스가 실행된다. (마치 인터럽트가 발생한 적이 없던 것처럼!)
이런 과정을 통해 인터럽트 핸들러는 단일 프로세서에서 여러 프로그램을 동시에 실행시키는(동시성 적용) 멀티태스크(멀티 프로세스) 운영을 가능하게 하는 것이다.
그런데 이 멀티 프로세스 운영을 하는 스케줄링 방법론에 대해서, 매우 길게 얘기하진 않겠다. 결론은, Pintos는 "Timer"를 사용한다는 거다.
이 Timer는 Timer Interrupt를 발생시키며, 이는 미리 세팅된 시간이 끝나면 제어권이 자동으로 운영체제에게 가게 되는 방식이다.
타이머 인터럽트는 미리 정의된 시간 간격의 만료에 따라 발생하는 인터럽트 유형이다. 시스템 설계에 따라 하드웨어에 의해 생성되거나 소프트웨어에 의해 트리거될 수 있는데, 우리의 Pinots에선 이것이 당연하게도... 소프트웨어 단에서 트리거 될 예정이다.
타이머 인터럽트를 통해서 프로그래머들은 너무 오랜 런타임을 필요로 하는 높은 우선순위의 프로세스, 무한 루프 등 특정 프로세스가 CPU를 독점하는 상황을 방지하고 멀티태스크 운영을 가능하게 하는 작업 스케줄링을 도모한다.
Timer - Interrupt를 통해 sleep 상태의 thread를 깨우기
Busy-waiting과 Sleep-Awake
- Busy-waiting
임계 영역(critical area)에서 작업 중인 스레드 B를 기다리는 스레드 A가 있을 때, A는 B가 끝날 때까지 즉, 임계 영역에 들어갈 수 있을 때까지 아무 작업도 하지 않고 임계 영역에 접근이 가능한지 무한으로 검사만 하고 있는 "바쁜 대기" 현상이다.
다시 말해, 하나의 프로세스나 스레드가 원하는 자원을 얻고자 하는데, 특정 공유자원에 대하여 다른 한 개 이상의 프로세스나 스레드가 그 이용 권한을 획득하고자 하는 동기화 상황이 일어난다.
그 권한 획득을 위한 과정에서 일어나는, 권한을 얻을 수 있을 때까지 수 천 수 억번 주기적인 확인을 수행하는 현상을 "Busy-waiting"이라 말한다.
Busy-waiting은 자원의 권한을 얻는데 많은 시간이 소요되지 않는 상황인 경우에 사용하는 것이 효율적이다. 또한, Context Switching 비용보다 성능적으로 더 우수한 상황인 경우에는 Busy-waiting을 사용하는 것이 어쩌면 효율적인 멀티테스킹을 가능케 할 수도 있다.
(함께 언급되는 스핀락(Spinlock)은 아래에서 말할 락(Lock)의 한 종류인데, 임계 구역에 진입이 불가능할 때 진입이 가능할 때까지 루프를 돌면서 재시도 하는 방식으로 구현된 락이다. 임계 구역 진입 전까진 루프를 계속 돌고 있기 때문에 이 현상도 바쁜 대기의 한 종류가 된다.)
현실적으로 보면 적어도 OS에서는 후자의 방식이 거의 언제나 옳은 성 싶다... Busy-waiting 방식은 CPU 자원을 낭비하고, 다른 스레드가 실행되는 기회를 줄여 성능 저하를 야기할 수 있기 때문이다.
(스핀락도 마찬가지. 스핀락은 운영체제의 스케줄링에 의해 스케줄되는 개념이 아니기 때문에, 짧은 시간 안에 진입할 수 있는 경우 문맥 교환 비용이 들지 않으므로 효율을 높일 수 있다.
하지만 이외의 경우에는 해당 스레드가 임계 구역에 진입할 때까지 다른 스레드에게 CPU를 양보하지 않기 때문에, 오히려 CPU의 효율을 떨어뜨리게 된다.)
- Sleep-Awake Alarm Clock
자원의 권한을 얻기 위해 기다리는 시간을 Wait Queue에 실행 중인 Thread에 담은 뒤, 다른 Thread에게 CPU를 양보하는 것을 말한다. 그러면 커널은 권한 이벤트가 발생하면 Wait Queue에 담긴 Thread 정보를 깨워 CPU에 부여한다.
이 경우, 프로세스 혹은 스레드가 대기 상태에 들어가 있는 동안 CPU 사이클을 사용하지 않기 때문에, Busy-waiting 방식에 비하여 CPU 자원을 매우 절약할 수 있다.
Pintos를 처음 설치하게 되면, 현재 스레드가 devices/timer.c의 timer_sleep() 함수를 호출하면 지정 Tick동안 While문이 계속해서 thread_yield()를 호출하면서 CPU를 점유하지 않는 모습을 보여준다. 
✨ 드...디어... Project 1의 첫 과제다.
주어진 기존의 Pintos 코드는 기본적으로 Busy-waiting 기법으로 동작하게 되어있다. 이를 Sleep-Awake 방식으로 동작하게끔 Alarm Clock 체계를 도입하자.
기본적으로 Pintos의 코드 안에 타이머 함수들이 구현되어 있다. devices/timer.c 중 timer_ticks()를 주목하자.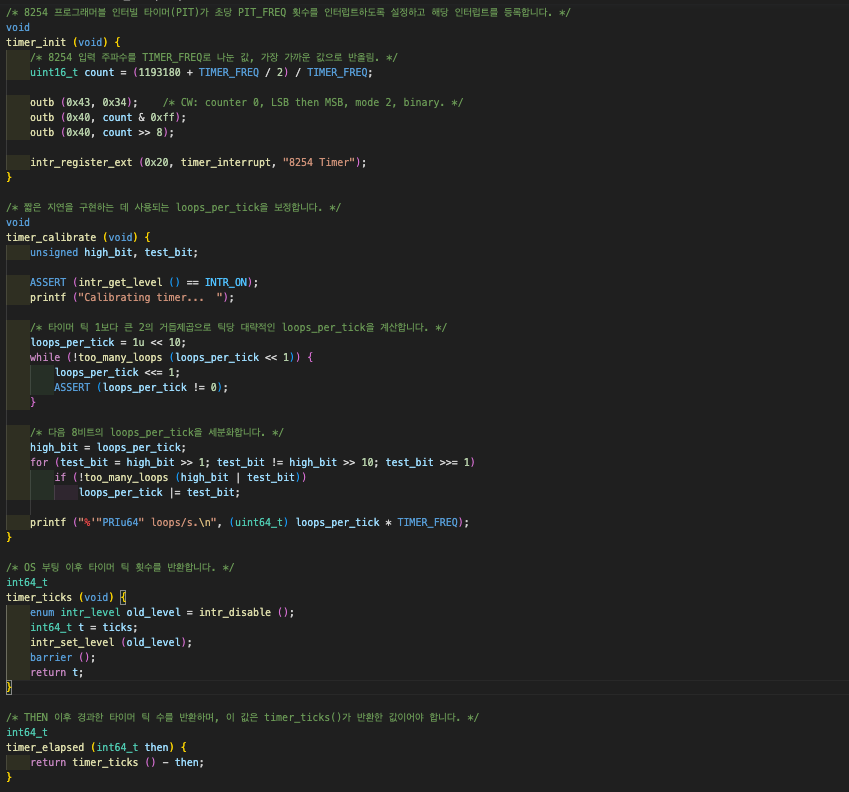 이 함수는 Pintos의 부팅 이후부터 카운트하여 타이머 틱 횟수를 반환한다. 여기서부터
이 함수는 Pintos의 부팅 이후부터 카운트하여 타이머 틱 횟수를 반환한다. 여기서부터 time slice에 대한 개념이 필요한데, 실행의 최소 단위시간을 타임퀀텀(Time Quantum) 또는 타임슬라이스(Time Slice)라 말한다. 이를 기준으로 하여서 OS는 프로세스들에게 정해진 시간마다 CPU를 할당하고 해당 단위의 시간이 지나면 다음 프로세스를 타임퀀텀만큼 CPU를 할당한다.
타임슬라이스, 타임퀀텀의 길이에 대한 기준이 중요한데,
- 너무 길면 바로 반응이 오는 시스템에 문제가 생기고,
- 너무 짧은 경우에는 문맥전환(Context Switching)이 자주 발생하여 그만큼 성능의 저하가 올 수 있다.
생각해보면 지극히 당연한 얘기이다. 목적에 따라 구현이 다르겠지만, 어쨌든 Pintos에서는 기존에 tick이 주어져 있다.
timer의 time slice 단위로 스레드가 실행되는 이 방법론은 기본적으로 Round-Robin 스케줄링 기법에 해당한다. Pintos는 여기서 priority 까지 메긴다. 아까 말했듯 OS의 스케줄링은 등장의 시간순으로 더 많은 종류를 나열할 수 있으나, 이 글에서는 아래의 두 개만 매우 짧게 다룬다.
Scheduling
Round-Robin 스케쥴러
: 기본적으로는 FIFO(선입선출) 스케쥴러와 동작 방식이 비슷하며, 차이점은 Non-preemptive인 FIFO와 달리 시분할 시스템을 가정하고 있다(Preemptive).
특정 시간이 지날 때마다 아직 프로세스가 완료되지 않았더라도 중단하고 다음 프로세스를 실행한다. 중단된 프로세스는 다시 준비 큐의 맨 뒤에 추가된다. 마치 작은 새(Round-Robin)들을 일렬로 기다리게 해놓고 한 마리씩 공평하게 모이를 주는 방식과 그 모습이 같다.
먹이를 먹은, 즉 일정 시간(tick)동안 자신의 수행을 실행된 스레드는 대기열로 들어가는데 이때 이 대기열로 들어가는 현상을 sleep이라고 한다. sleep에서 깨어나게끔 하는 것이 곧 alarm clock인 개념이라고 생각하자.
Priority-Based 스케쥴러
: 프로세스에 우선순위를 매겨 놓고, 우선 순위가 높은 순서대로 프로세스를 실행하는 방식이다. Priority는 최초에 부여된 Priority value에서 달라질 수 있으며, OS마다 프로세스에게 Priority를 부여하는 지점이나 항목, donation의 여부를 어떻게 설정하는 가에 따라 그 규칙이 상이할 수 있다. (우리의 Pintos에서는 노화 등 최초로 부여받은 Priority가 수정되는 항목은 없되, Priority Donation는 이뤄질 수 있다.)
- 정적 우선순위: 프로세스마다 우선순위를 미리 지정!
하지만 모든 프로세스에 직접 우선 순위를 준다는 것이 현실적으로 번잡스럽다.- 동적 우선순위: 상황에 따라 스케쥴러가 우선순위를 동적으로 변경!
목적에 따라 스케쥴러가 우선순위를 할당하는 알고리즘이 다를 것이다.
우선순위 순으로 프로세스를 CPU할당을 하면서, 우선순위가 동일한 프로세스의 경우에는 타임퀀텀 만큼 실행하고 다른 동일한 우선순위의 프로세스에게 CPU 할당을 넘긴다.
우리의 Pintos 과제는 궁국적으로 Priority-Based-Round-Robin 방식의 스케줄러를 구현하도록 하고 있다. 실로 많은 OS에서 우선순위 스케줄링와 라운드로빈 스케줄링을 섞어서 사용하고 있다고 한다.
스케줄링이 진행되는 시점
- 매 타임슬라이스, 타임퀀텀 마다 스케줄러 동작.
- 새로운 프로세스가 등장할때마다 현재 실행중인 프로세스와 비교해야 하므로 스케줄러 동작.
- 현재 실행중인 프로세스가 종료될 때 마다 다른 프로세스를 실행시켜야 하므로 스케줄러 동작.
- 현재 실행중인 프로세스가 I/O 요청에 의해 Blocked 상태에 놓일 때 마다 스케줄러 동작.
Thread's status & Priority
아래는 Pintos 안에서 예상되는 한 스레드의 생명주기이다. 생성되어서는 가장 먼저 대기 상태에 진입하게 된다. 조건이 갖춰져 실행된 이후에도 timer나 event에 의해 ready, blocked 상태를 몇 번 오갈 것이다. 그러다 자신의 수행이 다 끝나면 dying 상태가 되어 종료됨에 이른다.
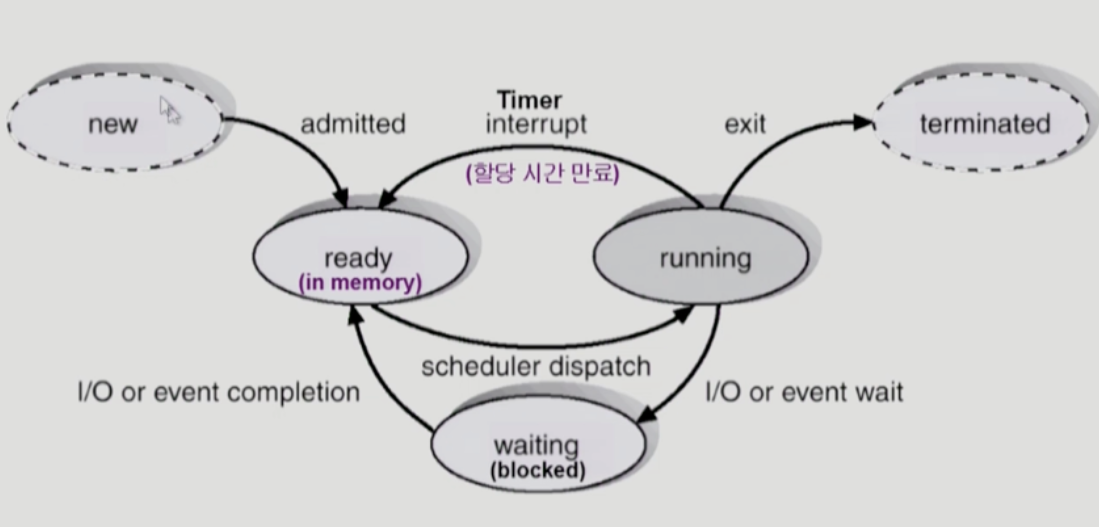 이 status에 대한 분류는 고스란히 아래의 코드 상에서 확인할 수 있다.
이 status에 대한 분류는 고스란히 아래의 코드 상에서 확인할 수 있다.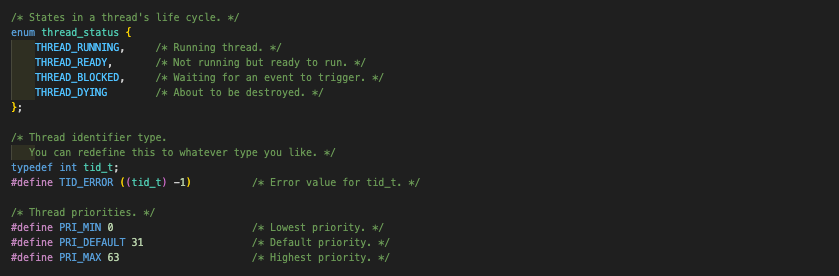
Priority Donation
Synchronization
Lock & Semaphore
alarm clock & priority donation 구현
1. donor list와 sema waiters에 대한 오해와 구현에서의 어려움
 가장 처음 마주한 test case : priority-donate-one는 스레드 자신이 본래 가지고 있던 우선순위 점수인
가장 처음 마주한 test case : priority-donate-one는 스레드 자신이 본래 가지고 있던 우선순위 점수인 origin_priority 라는 비교적 단순한 int형 변수로 해결했었다. 그러나 test case : priority-donate-multiple부터는 2개 이상의 lock이 등장하며 priority donation 작용이 유동적이어지면서, 여러 시도 끝에 donation을 주고 대기가 걸린 스레드들에 대한 관리가 연결리스트의 형태로 이뤄져야 한다는 결론을 내릴 수 있었다. 그렇게 처음 donor_list를 선언한다.
처음 접근 시 "직전에 donation을 한 스레드" 에 대한 정보만이 필요할 것이라고 생각했다.
그래서 donation을 주고 대기가 걸린 스레드들이 donor_list에 list_push_front() 되도록 구현하었고 이 donor_list에 삽입된 "순서"를 로직 상 중요한 단서로 여겼다.
이때까지만 해도 경민이와 성범이 그리고 나는 각 스레드가 donate한 priority와 각자 원하는 lock의 이름에 대한 정보가 따로 기록되어야 한다고 생각하지 않았다. running thread는 lock을 release하는 시점에, 직전에 대기가 걸린 스레드 즉 donor_list의 맨 앞에 위치해있는 스레드에게 priority를 반환하면 된다고 생각했다. 고로 donor_list의 스레드들에 각개로 접근해야 하는 경우도 없을 것이라는 오판을 했다.
그러나 계속해서 이 로직으로 접근하는 시도가 실패하였고, 대략 test case : priority-donate-one을 해결한 이후 12시간 정도를 소요했을 때에서야 우리가 단단히 개념에 대한 오해를 했음을 알았다.
우선 우린 priority 점수로 계속해서 donor_list가 정렬되어야 하는 점을 놓쳤단 걸 알았다. 최종 코드에서 lock이 2개 이상인 경우, lock A가 lock_acquire()될 때 donor_list 중 lock A를 원하던 스레드들은 priority_donate(lock A)를 통해 priority 점수가 갱신된다.
running thread에게 2개 이상의 lock이 있고 donor_list에 여러 개의 스레드가 기다리고 있을 때, running thread는 lock A을 기다리는 스레드와 lock B를 기다리는 스레드 중 더 높은 우선순위의 스레드가 들고 있는 lock을 release해야 할 것이다.
해당 경우에 대한 예시가 아래에 있다.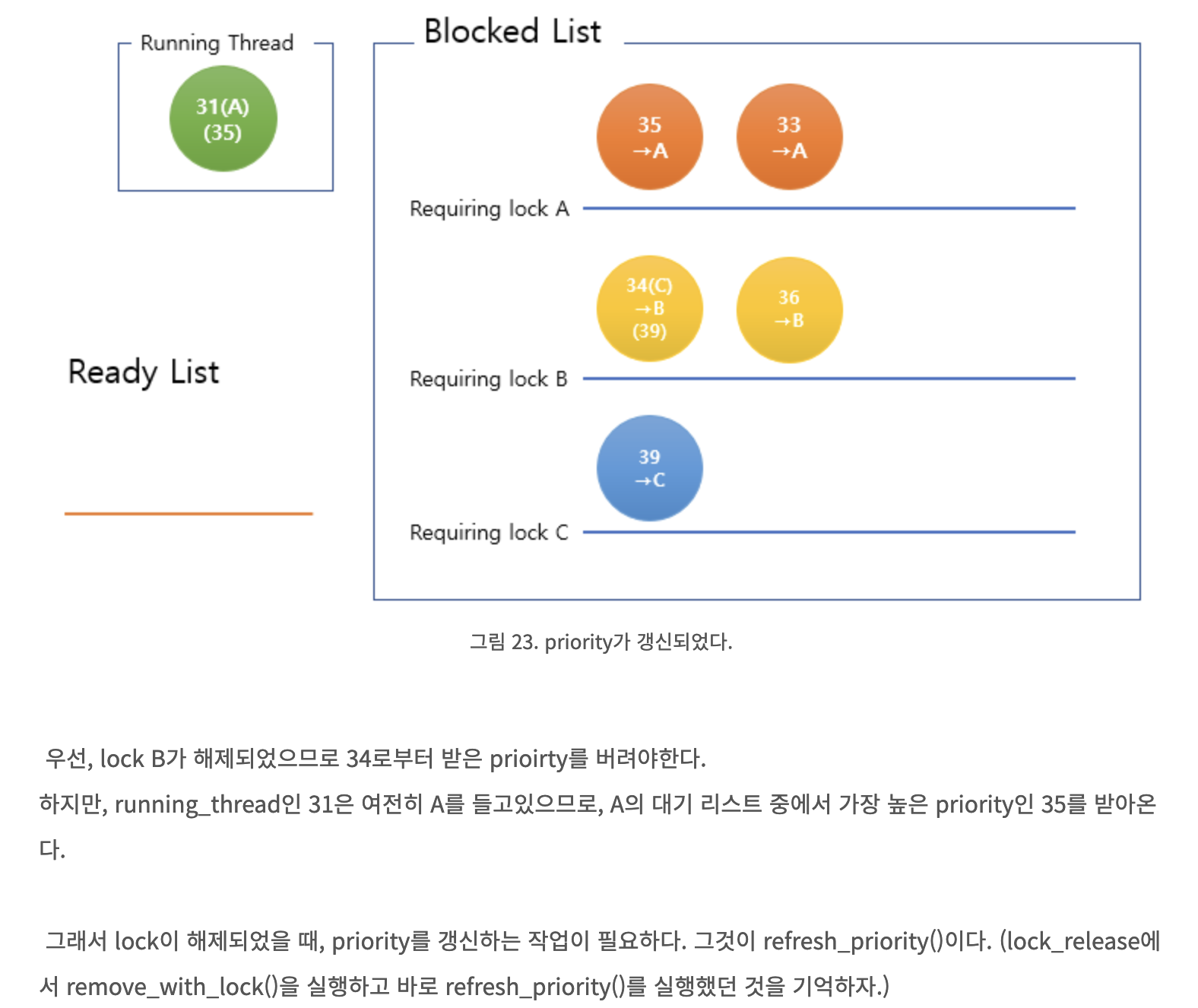 그림에 대한 출처는 여기(https://firecatlibrary.tistory.com/60)이다.
그림에 대한 출처는 여기(https://firecatlibrary.tistory.com/60)이다.
고로, 이로 인해 우린 donor_list 내 스레드의 priority가 전위되는 경우에 대비하여 lock_release()시 donor_list는 늘 priority 기준으로 재정렬되어야 함을 깨달았다!
이 내용은 즉 스레드마다 각자 원하는 lock의 이름에 대한 정보를 따로 저장해야 한다는 것이었다. 우린 여태까지 donor_list가 재정렬되어야하는 경우를 생각하지 못해 이 정보를 삽입 순서에 기인해 찾으려 했고, 오류를 해결하지 못하고 있었다. 우리는 wait_on_lock 변수로 스레드 구조체 안에 추가해, 같은 donor_list 안의 스레드들끼리도 각각 기다리는 lock이 다른 녀석들을 식별할 수 있는 방법을 모색했다.
재정렬 이슈는 sema_priority_more()를 통해 list_sort()로 구현해 해결했다. 이를 구현하며 donor_list의 스레드 중 가장 높은 priority 점수가 running thread의 priority 점수보다 높다면 running thread의 priority 점수 역시 그만큼으로 갱신해줘야 한다는 것을 알았다.
그리고 이 과정에서 donor_list의 스레드들에 각개로 접근해야 하는 경우가 발생하므로, 우리는 donor_list의 list_elem 구조체인 donor_elem을 선언했다.
void
priority_donate (struct lock *lock) {
struct thread *curr_th = thread_current();
int curr_priority = curr_th->priority;
for (int dep=0; dep<8; dep++) {
if (!curr_th->wait_on_lock) {
break;
}
curr_th = curr_th->wait_on_lock->holder;
curr_th->priority = curr_priority;
}
}
void
remove_with_lock (struct lock *lock)
{
struct list_elem *e;
struct thread *cur = thread_current ();
for (e = list_begin (&cur->donor_list); e != list_end (&cur->donor_list); e = list_next (e)){
struct thread *t = list_entry (e, struct thread, donor_elem);
if (t->wait_on_lock == lock)
list_remove (&t->donor_elem);
}
}
void
refresh_priority(void) {
struct thread *curr_th = thread_current();
curr_th->priority = curr_th->origin_priority;
if (!list_empty(&curr_th->donor_list)) {
list_sort(&curr_th->donor_list, sema_priority_more, NULL);
struct thread *highest_donor = list_entry(list_front(&curr_th->donor_list), struct thread, donor_elem);
if (highest_donor->priority > curr_th->priority) {
curr_th->priority = highest_donor->priority;
}
}
}
void
lock_acquire (struct lock *lock) {
ASSERT (lock != NULL);
ASSERT (!intr_context ());
ASSERT (!lock_held_by_current_thread (lock));
if (lock->holder != NULL) {
thread_current()->wait_on_lock = lock;
list_push_front(&lock->holder->donor_list, &thread_current()->donor_elem);
priority_donate(lock);
}
sema_down (&lock->semaphore);
thread_current()->wait_on_lock = NULL;
lock->holder = thread_current();
}
void
lock_release (struct lock *lock) {
ASSERT (lock != NULL);
ASSERT (lock_held_by_current_thread (lock));
remove_with_lock(lock);
refresh_priority();
lock->holder = NULL;
sema_up (&lock->semaphore);
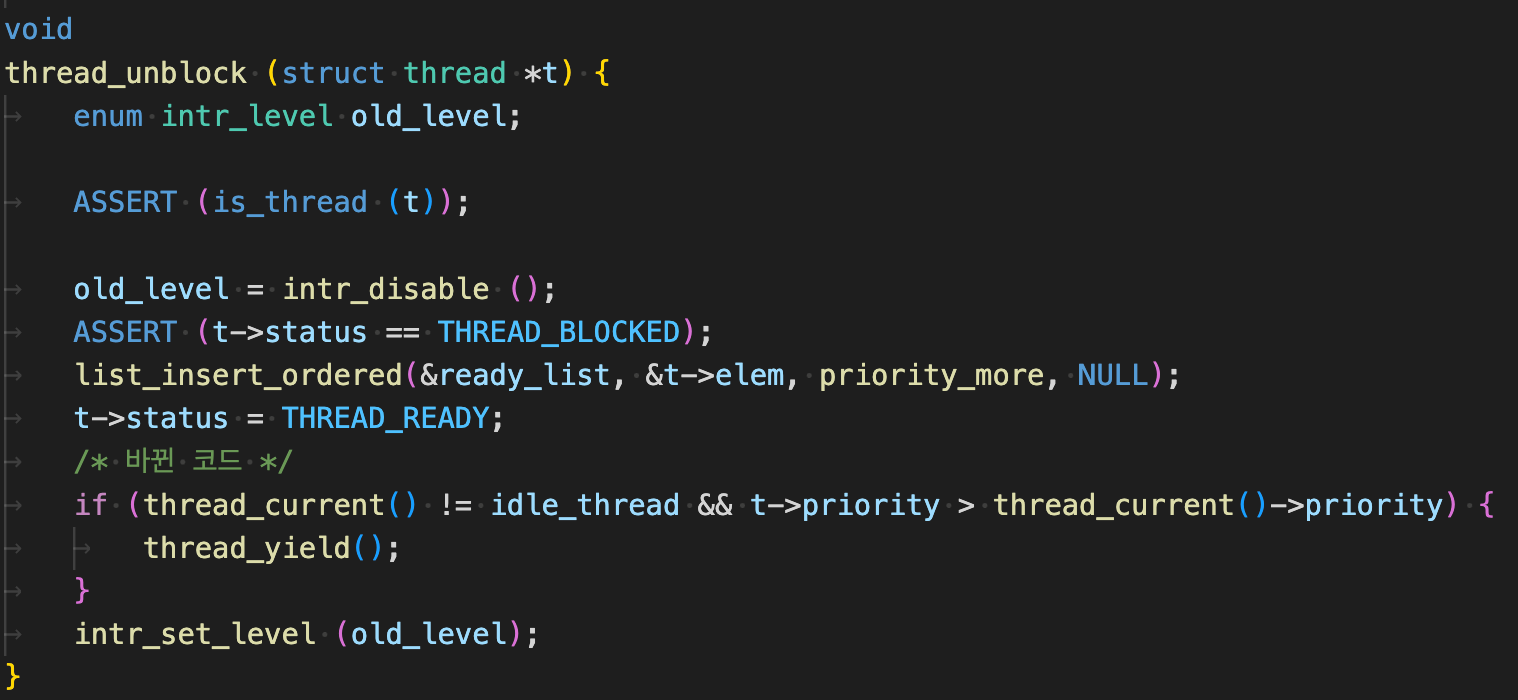
}2. thread_unblock()과 thread_yield()의 혼재
alarm clock()을 모두 문제없이 구현하고 나서, thread_donation_one 테스트 케이스를 통과했는데, 앞서 통과했던 alarm_clock에 대한 테스트 케이스가 모두 실패하는 문제가 발생했다.
처음에는 문제의 원인을 발견하지 못했는데, 결국 thread_unblock() 내부에서 thread_yield() 함수를 호출하는 과정에서 문제가 발생한다는 것을 알게 되었다.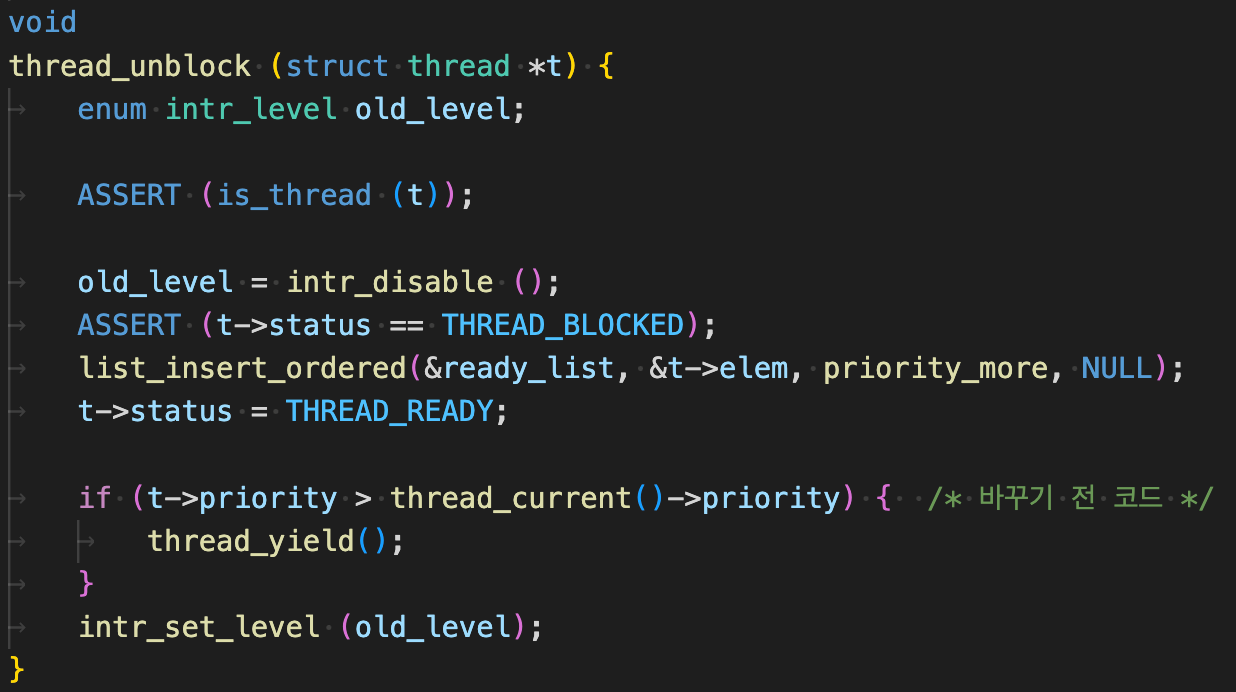
thread_create(), thread_awake(), sema_up() 세 군데에서 thread_unblock() 함수를 호출하는데, thread_awake() 함수에서 thread_yield()를 할 때 문제가 발생하였다.
문제를 발견하고 나서 thread_yield() 안에 넣어 놓은 조건문을 밖에 꺼내서, thread_create()와 sema_up()에서만 thread_yield()를 하는 방식으로 문제 해결을 시도했다.
계속 구현을 해 나가며 테스트 케이스를 뜯어보다 보니, 알게 된 거대한 실수....
바로, 위 코드 상 thread_awake() 과정에서
idle_thread가 yield되면 안 되는 상황에서 yield를 하기 때문에 문제가 발생한다는 것을 알게 되었다.
그래서 다음과 같이 조건문을 수정한 결과, 구현했던 부분의 테스트 케이스가 모두 통과하는 것을 확인하였다.