디지털 병리학을 위한 딥 러닝은 전체 슬라이드 이미지(WSI)의 매우 높은 공간 해상도로 인해 방해를 받습니다. 대부분의 연구는 이미지 패치의 상세한 주석이 필요한 패치 기반 방법을 사용했습니다. 이것은 일반적으로 WSI에 대한 힘든 프리핸드 컨투어링을 포함합니다. 이러한 컨투어링의 부담을 줄이고 수많은 WSI로 교육을 확장하여 이점을 얻기 위해 슬라이드 수준 진단만 사용하여 전체 WSI에서 신경망을 교육하는 방법을 개발합니다. 우리의 방법은 컴퓨팅 가속기의 메모리 제약을 극복하기 위해 통합 메모리 메커니즘을 활용합니다. 9662 폐암 WSI의 데이터 세트에 대해 수행된 실험은 제안된 방법이 테스트 세트에서 선암종 및 편평 세포 암종 분류에 대해 각각 0.9594 및 0.9414의 수신자 작동 특성 곡선 아래 영역을 달성한다는 것을 보여줍니다. 또한 이 방법은 클래스 활성화 매핑을 통해 작은 병변에 대한 강력한 현지화 결과뿐만 아니라 다중 인스턴스 학습보다 높은 분류 성능을 보여줍니다.
Introduction
최근 수십 년 동안 폐암은 가장 자주 진단되는 암 중 하나였으며 대만을 포함하여 전 세계적으로 암 관련 사망의 주요 원인이었습니다[1]. 비소세포폐암(NSCLC)은 새로 진단된 폐암 사례의 ~85%를 차지하며, 두 가지 주요 조직학적 유형인 선암종과 편평세포암종이 각각 NSCLC의 거의 50%와 30%를 차지합니다2. 폐의 침윤성 선암종은 5가지 주요 패턴을 갖는 악성 상피 종양이다: lepidic, acinar, papillary, micropapillary 및 solid.
편평 세포 암종은 편평 분화 및/또는 각질화를 동반한 악성 상피 종양입니다. 폐암 유형 간의 형태학적 차이가 미묘하기 때문에 적절한 병리학적 진단은 많은 경우에 어려울 수 있습니다.
선암종과 편평 세포 암종의 병리학적 특징의 예는 그림 1에 제시되어 있습니다.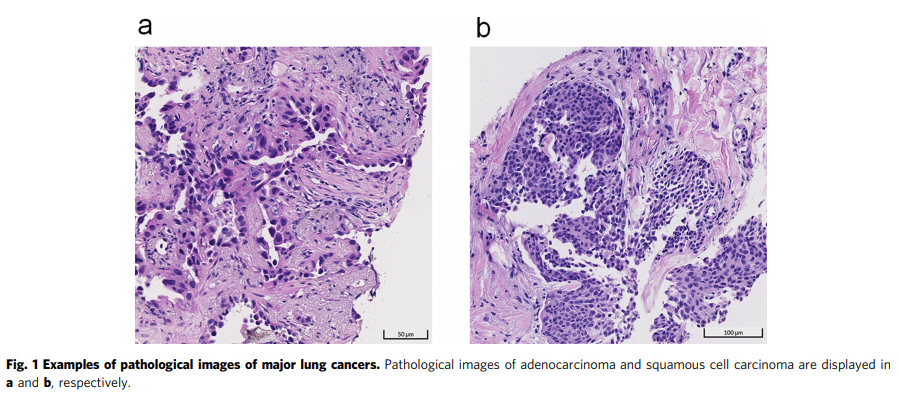
심층 신경망(DNN), 특히 CNN(컨볼루션 신경망)은 이미지 인식을 위한 지배적인 방법이 되었습니다. 2012년에 그들의 성능은 ImageNet 대규모 시각적 인식 챌린지에서 대부분의 기존 이미지 분석 알고리즘을 능가했습니다. 의료 분야에서 컴퓨터 단층 촬영이나 자기 공명 영상의 종양 식별 및 세분화, 안저 색상 이미지를 사용한 심혈관 위험 평가, 흉부 Xray의 폐렴 감지 등 여러 작업에서 딥 러닝 알고리즘이 인간 수준의 성능을 달성하는 것으로 입증되었습니다. 그러나 디지털 전체 슬라이드 이미지(WSI)의 분석은 다른 의료 영상 방식에 비해 공간 해상도가 매우 높기 때문에 여전히 까다롭습니다.
컴퓨팅 한계에 의해 제한되는 대부분의 조직병리학 연구는 2단계 패치 기반 워크플로우를 사용했습니다 : 패치 수준 CNN은 WSI에서 잘라낸 패치를 사용하여 훈련되고, 최종 진단을 나타내기 위해 패치 수준 모델에서 추출한 기능에 대해 슬라이드 수준 알고리즘이 훈련됩니다.
이러한 패치 기반 방법은 암 식별, 암 유형 분류, 암 전이 감지 및 예후 분석에서 성공적인 결과를 낳았습니다. 그러나 이러한 방법은 숙련된 병리학자가 상당한 주석을 수행해야 합니다.
슬라이드 레벨 레이블을 직접 활용하기 위해 다중 인스턴스 학습(MIL)은 기존 방법과 동일한 2단계 워크플로우를 따르지만 훈련 절차를 다르게 구성합니다. 슬라이드 수준 암 분류를 위한 MIL에서 슬라이드에서 가장 높은 점수를 가진 패치(암일 가능성이 가장 높은 k 패치)가 암종으로 식별되면 슬라이드는 암으로 분류되어야 합니다. 그렇지 않으면 최고 점수의 패치가 정상이면 슬라이드가 양성으로 분류됩니다. MIL은 슬라이드 수준의 ground truth를 약한 감독으로 사용하여 성공적으로 주석 부담을 줄입니다. 그러나 최근 연구에 따르면 객체 감지(object detection), 의미론적 분할(semantic segmentation) 및 인스턴스 분할(instance segmentation)과 같은 대부분의 이미지 인식 작업에서 최첨단 약한 감독 방법도 강력한 감독 방법의 평균 성능을 달성할 수 없습니다. 반복적으로 모델을 훈련시키기 위해 슬라이드 대표로 상위 k개의 패치를 선택하는 MIL 방법과 달리 Pinckaers et al.의 패치를 역전파 알고리즘에 통합하여 큰 이미지의 종단 간 교육을 달성합니다. 특히 스트리밍 CNN은 특별히 설계된 업데이트 일정으로 훈련하는 동안 WSI 패치의 손실 기울기를 수집하고 업데이트하므로 제한된 컴퓨팅 리소스로 모든 이미지 정보를 유지할 수 있습니다. 그러나 훈련 중에 기능 맵을 패칭하면 가장 일반적으로 사용되는 배치 정규화 레이어와 같이 모든 feature 맵 정보가 필요한 일부 작업이 중단됩니다. 따라서 신중한 모델 설계 및 튜닝이 필요합니다.
이 연구에서는 교육 파이프라인이나 모델 아키텍처를 수정하지 않고 매우 큰 이미지 입력으로 표준 CNN을 교육하기 위해 통합 메모리(UM) 메커니즘과 여러 GPU 메모리 최적화 기술을 통합하는 전체 슬라이드 교육 방법을 개발했습니다. 실험 결과 제안하는 방법은 WSI 분류에 바로 적용할 수 있으며 MIL 방법보다 성능이 우수함을 보였다. 연구의 기여는 다음과 같이 요약됩니다. (1) 입력 이미지 또는 기능 맵을 패치로 나누지 않고 슬라이드 수준 레이블을 사용하여 WSI에서 CNN을 교육하는 교육 접근 방식을 제안합니다. (2) 우리의 방법은 선암종 및 편평 세포 암종 분류에 대해 각각 0.9594 및 0.9414의 수신자 작동 특성 곡선(AUC) 점수 아래 영역을 달성하는 우수한 성능을 가지고 있습니다. (3) 클래스 활성화 맵(CAM) 기술로 강조 표시된 모델의 중요한 영역은 병리학자가 식별한 암 영역과 높은 일치성을 나타냅니다.
Results
달리 명시되지 않는 한, 실험은 전체 슬라이드 및 MIL 모델을 훈련시키기 위해 ×20 배율로 스캔한 슬라이드를 ×4 배율로 축소(즉, 원래 크기의 0.2배로 크기 조정)하여 수행했습니다. ×4 배율로 축소한 후 슬라이드의 대부분의 조직은 21,500픽셀의 높이와 너비로 포함될 수 있습니다. 다운샘플링된 이미지는 동일한 크기를 보장하기 위해 21,500 × 21,500으로 패딩되었습니다. 우리는 모든 실험에 대해 수정 초기화와 함께 ResNet-50을 사용했습니다. 이 모델은 선암종, 편평 세포 암종 또는 비암종에 대한 삼항 분류기로 훈련되었습니다. 모델은 5606개의 슬라이드에서 학습되었으며 타이페이 의과 대학 병원(TMUH), 타이페이 시 완팡 병원(WFH) 및 타이페이 의과 대학 솽호 병원(SHH)에서 수집한 1397개의 슬라이드에서 평가되었습니다. 마지막으로, AUC를 사용하여 폐 표본에서 폐암 유형 분류에 대한 모델 성능을 측정했습니다.
MIL model performance
우리는 MIL의 표준 및 최신 변형을 모두 사용하여 실험을 수행했습니다. 먼저 슬라이드 이미지를 다음 교육 절차의 인스턴스로 겹치지 않는 224 × 224 패치로 슬라이스했습니다. 표준 MIL 접근법에서 우리는 k가 1, 3 또는 5로 설정되었을 때 성능을 평가했습니다. 여기서 k는 교육 단계 동안 슬라이드당 선택된 패치의 수입니다. MIL의 변형에는 각각 EM-CNN-LR 및 EM-CNN-SVM으로 표시되는 로지스틱 회귀 및 지원 벡터 머신 슬라이드 레벨 집계가 있는 기대 최대화 기반 방법(expectation maximization-based methods)이 포함되었습니다. 또한 CNN-MaxFeat 기반 RF로 표시되는 최대 기능 집계 및 랜덤 포레스트 슬라이드 레벨 집계가 있는 MIL과 MIL-RNN으로 표시되는 순환 신경망 슬라이드 레벨 집계가 있는 MIL이 평가되었습니다.
모델 성능 결과는 표 1에 나열되어 있습니다. k 값이 다른 표준 MIL 모델 중에서 k = 3인 MIL 모델은 선암종 및 편평세포에 대해 0.9188(0.9052–0.9324) 및 0.9032(0.8825–0.9240)의 최적 테스트 AUC 점수를 달성했습니다. 각각 세포 암종 분류. 이 결과는 k = 3이 양성인 경우 진양성 패치를 샘플링하고 작은 암 병변의 경우 정상 조직일 수 있는 패치를 샘플링하지 않도록 할 수 있는 적절한 백 크기임을 나타냅니다.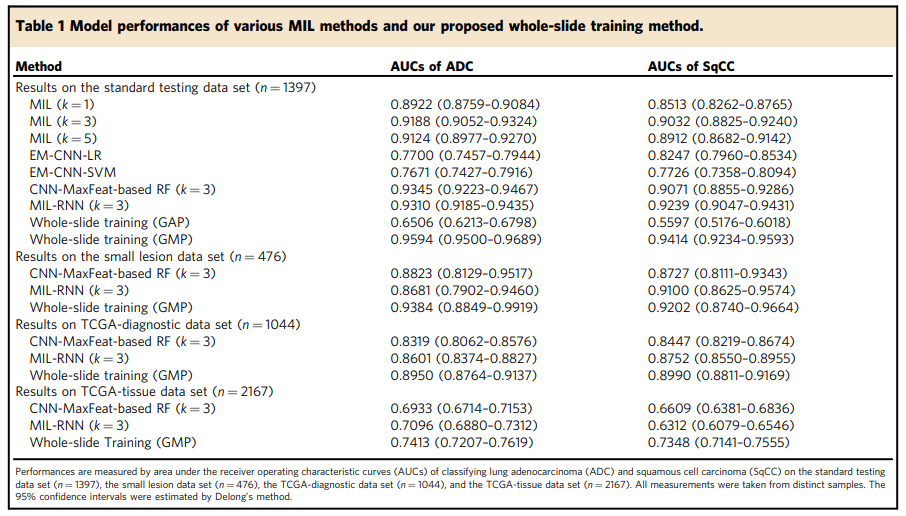
대조적으로 EM-CNN-LR 및 EM-CNN-SVM은 0.76–0.83의 AUC 점수를 달성했으며 이는 표준 MIL보다 성능이 떨어졌음을 의미합니다. 이는 패치의 클래스 확률을 합산하는 패치 간 집계 방법이 이기종 데이터 세트, 즉 절제와 생검으로 구성된 데이터 세트에 적합하지 않을 수 있음을 시사합니다. 패치 결과를 합산하면 양성 패치가 많은 슬라이드는 양성으로 분류되고 양성 패치가 거의 없는 슬라이드는 음성으로 분류되는 경향이 있습니다. 그러나 우리의 데이터 세트는 생검 및 절제 슬라이드로 구성되었으며 생검 슬라이드의 병변 크기는 훨씬 작아서 무시할 가능성이 높습니다.
마지막으로, CNN-MaxFeat 기반 RF(선암종의 경우 AUC = 0.9345, P = 2.938e−4, 편평 세포 암종의 경우 AUC = 0.9071, P = 0.6459) 및 MIL-RNN(AUC = 0.9310, P = 1.003e−3 선암종의 경우 AUC = 0.9239, 편평 세포 암종의 경우 P = 1.472e−3) 표준 MIL(k = 3)을 능가하여 이러한 패치 집계 방법의 효과를 입증했습니다.
Model performance of the whole-slide training method
UM 메커니즘을 활용하여 제안된 전체 슬라이드 교육 방법은 슬라이드 예측을 도출하기 위해 패칭 절차 및 추가 집계 모델 없이 전체 21,500 × 21,500 이미지 엔드 투 엔드를 교육하고 평가했습니다. 또한 최종 풀링 작업의 두 가지 변형, 즉 글로벌 평균 풀링(GAP) 및 글로벌 최대 풀링(GMP)이 포함된 ResNet-50이 평가되었습니다.
표 1에 제시된 바와 같이, GAP 레이어를 사용한 전체 슬라이드 교육 방법은 선암종의 경우 0.6506(0.6213–0.6798), 편평 세포 암종 분류의 경우 0.5597(0.5176–0.6018)의 AUC 점수를 달성했으며, 이는 모델이 입력에서 제한된 정보만 캡처함을 나타냅니다. GAP 레이어는 대부분의 자연스러운 이미지 분류 방법에서 최첨단 CNN 모델에 널리 채택되지만 초고해상도 이미지에 적용하면 작은 특징이 나타내는 미묘한 정보가 손실되는 경향이 있습니다. 이러한 비효율성은 GMP 레이어를 사용한 전체 슬라이드 학습 방법에 비해 모델 성능이 크게 저하됩니다.
대조적으로, GMP 레이어를 사용한 전체 슬라이드 교육 방법은 선암의 경우 0.9594(0.9500–0.9689), 편평 세포 암의 경우 0.9414(0.9234–0.9593)의 AUC 점수를 달성했으며, 이는 CNN을 포함한 다른 접근 방식에 의해 달성된 것보다 훨씬 우수했습니다. -MaxFeat 기반 RF(선암종 및 편평세포암종 분류에 대해 각각 P = 3.565e-7 및 3.189e-4) 및 MIL-RNN(각각 선암종 및 편평세포암종 분류에 대해 P = 2.279e-9 및 0.02498). 앞서 언급한 모델에 대한 수신자 작동 특성(ROC) 곡선은 그림 2a, b에 나와 있습니다.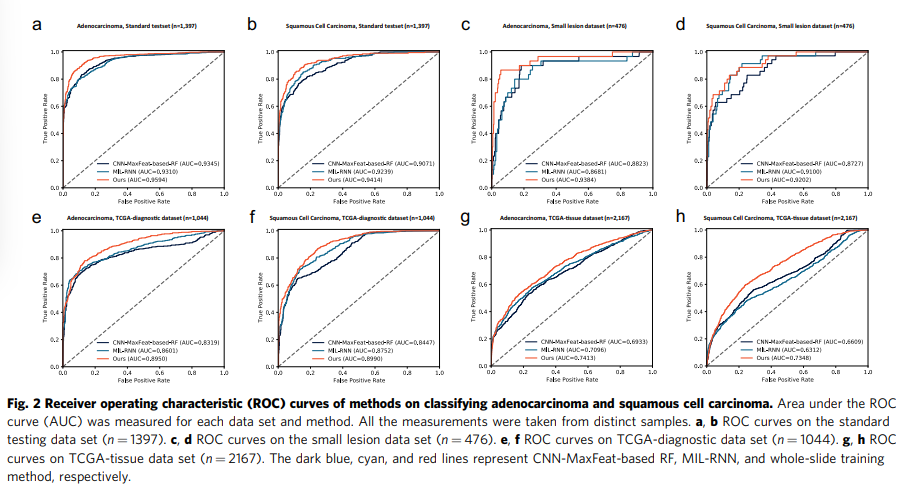
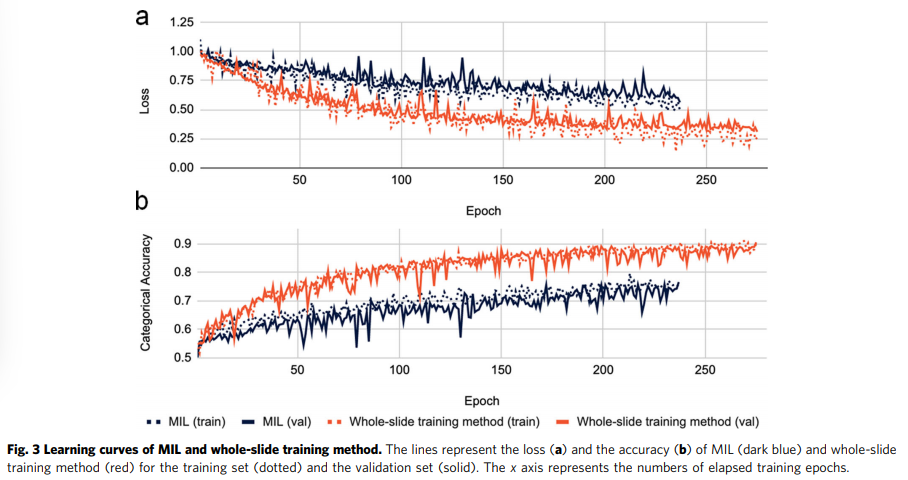
그림 3에서 보는 바와 같이 MIL 방법과 제안한 방법의 학습 곡선은 초기 훈련 단계에서 상당히 다른 패턴을 보였다. 우리가 제안한 방법의 성능은 처음 몇 epoch 동안 급격히 증가했고 남은 훈련 시간에는 점차 수렴했습니다. 이는 모델이 고차원 표현 공간으로 쉽게 나눌 수 있는 특징을 먼저 찾아 학습하는 경향이 있어 정확도의 급격한 향상에 기여하기 때문에 DNN을 훈련할 때 전형적인 학습 패턴입니다. 학습 절차와 함께 대부분의 명백한 기능이 사용되었고 모델 성능은 점차 포화되었습니다. 모델이 고차원 평면을 찾아 손실을 최소화하려고 시도했기 때문에 이후 학습 단계에서 미묘한 특징이 추출되었으며, 이로 인해 모델이 더욱 정교해졌습니다. 대조적으로, MIL의 학습 곡선은 처음 몇 에포크 동안 상대적으로 매끄러웠습니다. MIL 교육 절차는 분류자를 교육하기 전에 WSI에서 대표 타일을 선택하기 위해 진행 중인 작업 모델에 의존합니다. 그러나 초기 학습 단계의 모델은 아직 정보를 학습하지 않았기 때문에 무작위 추측 동작을 보였습니다. 타일을 잘못 선택하면 필연적으로 모델이 잘못 안내되어 수렴 속도가 느려집니다.
Visualization
CNN은 분류 작업에서 인상적인 성능을 달성했지만 더 흥미로운 것은 모델이 결정을 내리는 방식입니다. 시각화는 모델이 주어진 작업을 해결하는 방법을 학습하는 방법을 조사하기 위한 가장 간단한 접근 방식입니다. MIL 모델과 전체 슬라이드 모델 간에 내부 속성이 동일하지 않기 때문에 다른 모델에 다른 시각화 접근 방식이 적용되었습니다.
MIL 모델의 경우 슬라이드의 예측 맵은 패치 수준 분류기에 의해 전달된 타일의 확률을 조합하여 간단하게 파생될 수 있습니다. 전체 슬라이드 교육 방법의 경우 특정 암 범주와 관련된 식별 영역을 시각화하기 위해 CAM 기술을 채택했습니다.
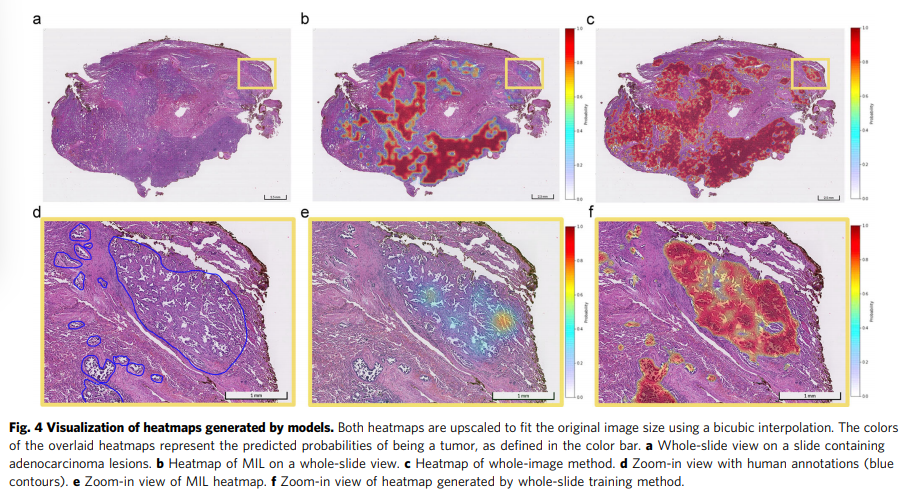
그림 4에서 볼 수 있듯이 MIL 모델과 전체 슬라이드 모델 모두 대표 정보를 발견할 수 있으며, 이는 슬라이드 수준 진단에서 반복적으로 학습한 후 히트맵으로 강조 표시됩니다. 또한 CAM과 결합된 우리의 방법은 슬라이드의 모든 의심스러운 영역, 특히 작은 병변을 강조 표시하는 보다 포괄적인 기능을 보여주었습니다.
Model performance on the small lesion testing data set
하드 케이스에 대한 다양한 모델의 성능을 조사하기 위해 표준 테스트 데이터 세트에서 407개의 비암 슬라이드와 함께 작은 병변(즉, 종양 면적 < 조직 면적의 10%)이 있는 69개의 슬라이드를 선택했습니다. 이 하위 데이터 세트의 슬라이드는 특히 암 조직 영역의 비율이 적기 때문에 병리학자가 잘못 분류하는 경향이 있었습니다. 이 하위 집합에서 전체 슬라이드 교육 방법, CNN-MaxFeat 기반 RF 및 MIL-RNN을 비교했습니다.
그림 2c, d 및 표 1의 세 가지 모델의 ROC 곡선과 AUC 점수는 작은 병변 테스트 데이터 세트에 대한 성능을 나타냅니다. 결과는 작은 병변이 있는 슬라이드가 구별하기 더 어렵다는 것을 보여주었습니다. 또한 모든 모델의 AUC 점수는 표준 테스트 데이터 세트에서 테스트한 것과 비교할 때 0.01에서 0.07로 어느 정도 떨어졌습니다. 그럼에도 불구하고 우리의 방법은 CNN-MaxFeat 기반 RF(선암종의 경우 P = 0.1171, 편평 세포 암종의 경우 P = 0.08036) 및 MIL-RNN(선암종의 경우 P = 0.02924 및 편평 세포 암종의 경우 P = 0.5760과 비교할 때 작은 병변이 있는 슬라이드에서 우수한 성능을 나타냈습니다.)
Model performance on Cancer Genome Atlas data sets
Cancer Genome Atlas 데이터 세트의 모델 성능
모델의 일반화 능력을 조사하기 위해 The Cancer Genome Atlas(TCGA) 공개 데이터 세트의 LUAD(폐 선암종) 및 LUSC(폐 편평 세포 암종)라는 두 개의 폐암 데이터 세트가 연구에 포함되었습니다. TCGA-LUAD 및 TCGA-LUSC 진단 슬라이드 데이터는 각각 선암 532개 슬라이드와 편평 세포 암종 512개 슬라이드로 구성됩니다. TCGA 진단 데이터 세트의 슬라이드와 데이터 세트 간에 색상 특성이 크게 다르기 때문에 교육 슬라이드의 색상 스펙트럼 분포를 TCGA 슬라이드의 색상 스펙트럼 분포와 일치시키기 위해 이미지 전처리의 일부로 Vahadane 얼룩 정규화 알고리즘을 적용했습니다. 우리는 우리의 방법(GMP 레이어 포함), CNN-MaxFeat 기반 RF 및 MIL-RNN을 이 하위 데이터 세트에서 비교했으며, 모두 전체 훈련 데이터 세트에서 훈련되었습니다.
그림 2e, f 및 표 1에서 볼 수 있듯이 모든 방법에 대해 TCGA 진단 데이터 세트를 테스트할 때 AUC 점수가 감소했습니다. 구체적으로, 우리의 방법은 TCGA 진단 슬라이드에서 선암종을 분류하기 위해 0.8950(0.8764–0.9137)의 AUC 점수를 달성했는데, 이는 표준 테스트 데이터 세트의 점수보다 더 나쁩니다(AUC = 0.9594 [0.9500–0.9689], P = 1.987e− 9). 그러나 전체 슬라이드 학습 방법은 CNN-MaxFeat 기반 RF(선암의 경우 P = 2.138e-9, 편평세포암의 경우 P = 2.849e-8) 및 MIL-RNN(P 선암종의 경우 = 1.033e-4, 편평 세포 암종의 경우 P = 5.221e-3).
우리는 선암종과 편평 세포 암종의 각각 1067개 및 1100개의 신선 냉동 절편 슬라이드로 구성된 TCGA 조직 데이터 세트에 대한 모델 성능을 추가로 조사했습니다. 그림 2g, h 및 표 1에 묘사된 바와 같이 AUC 점수는 예상한 대로 모델이 TCGA 조직 데이터 세트에서 추론했을 때 상당히 낮았습니다. 가장 중요한 요인 중 하나는 절편 동결 과정에서 발생하는 얼음 결정 아티팩트입니다. 이러한 인공물은 폐암 유형을 분류하는 데 중요한 형태학적 특징을 크게 왜곡합니다. 또한 훈련 분포(포르말린 고정 파라핀 내장[FFPE]-슬라이드 도메인)와 테스트 데이터 세트(고정 슬라이드 도메인) 사이의 큰 도메인 불일치를 감안할 때 모델 성능이 상당히 감소했습니다.
Impact of data set size and image resolution
데이터 세트 크기 및 이미지 해상도의 영향
DNN의 예측 성능과 견고성은 단순히 더 많은 데이터를 제공함으로써 향상될 수 있습니다. 그러나 이것은 또한 계산 리소스의 요구 사항을 증가시킵니다. ×40 배율로 스캔한 조직병리학적 이미지는 일반적으로 수십억에 달하는 총 픽셀 수를 가집니다. 이러한 극단적인 해상도로 조직 병리학 이미지에서 DNN을 교육하려면 모든 데이터를 반복하기 위해 엄청난 양의 계산 리소스가 필요합니다. 예를 들어 이 연구에서 9662 WSI의 픽셀 수는 ImageNet 이미지보다 최소 1000배 더 컸습니다. Campanella et al.23은 더 나아가 MIL 모델을 교육하기 위해 44,732개의 WSI를 수집했습니다. WSI에서 모델을 교육할 때 모델 정확도와 리소스 보존 간의 균형을 맞추는 것이 중요합니다. 우리는 전체 데이터 세트의 훈련 세트 크기 또는 이미지 해상도를 축소하여 모델 성능과 데이터 세트 규모 간의 균형을 평가했습니다. 교란 요인을 제어하기 위해 모델 아키텍처 설정(수정 초기화가 포함된 ResNet-50 GMP) 및 하이퍼파라미터는 모든 실험에서 동일했습니다. 마지막으로 표준 테스트 데이터 세트의 AUC 점수를 사용하여 모델 성능을 평가했습니다.
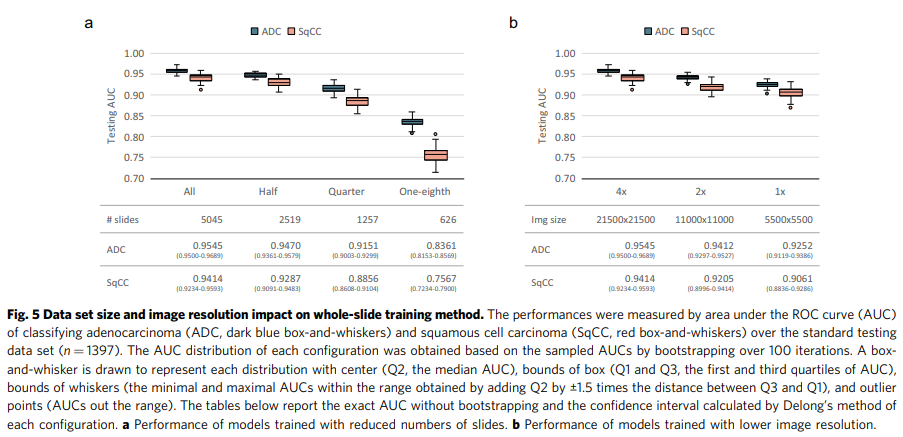
그림 5에서 볼 수 있듯이 훈련 데이터 세트 크기와 이미지 배율 수준의 감소는 테스트 세트에서 모델의 성능을 감소시켰습니다. 예를 들어, 전체 데이터 세트(슬라이드 5045개)에 대한 교육 모델의 테스트 AUC는 절반의 데이터 세트보다 훨씬 더 높았습니다(선암의 경우 P = 7.251e-6, 편평세포암의 경우 P = 1.222e-2). (2519 슬라이드). 유사하게 이미지 해상도를 ×2로 줄이면 AUC가 낮아졌습니다(선암의 경우 P = 1.779e−6, 편평세포암의 경우 P = 3.249e−3). 이러한 실험 결과는 모델이 세부 정보를 캡처하여 향상된 성능을 제공할 수 있도록 방대한 양의 고해상도 슬라이드 데이터가 필요함을 시사했습니다.
특히, 해상도 감소가 모델 성능에 영향을 미쳤음에도 불구하고 다운샘플링된 슬라이드에 대한 전체 슬라이드 훈련 방법의 AUC는 여전히 높았으며 ×1 배율을 사용하는 방법은 0.9보다 높았습니다(선암종의 경우 0.9252, 편평 세포 암종의 경우 0.9061). ×4 배율을 사용하여 훈련된 MIL 방법과 비교하여 ×2 배율을 사용하여 훈련된 우리의 방법은 CNN-MaxFeat 기반 RF(AUC = 0.9412 대 0.9345, 선암의 경우 P = 0.2378 및 AUC = 0.9205 대 0.9071, P = 0.1994로 경쟁력 있는 결과를 달성했습니다. 편평 세포 암종). 결과는 또한 ×2 배율을 사용하여 훈련된 방법이 선암종(AUC = 0.9412 vs 0.9310, P = 0.06015) 및 편평 세포 암종(AUC = 0.9205 대 0.9239, P = 0.6865). 따라서 제한된 계산 리소스를 고려할 때 해상도를 줄이는 것은 교육 시간을 단축하고 폐암 유형 분류와 같은 작업에 대해 허용 가능한 모델 정확도를 얻기 위한 실행 가능한 전략입니다.
3-Class classifier versus multiple binary classifiers
3-클래스 분류기 대 다중 이진 분류기
정보 이론에 따르면 대부분의 분류 알고리즘의 출력 확률은 대상 클래스의 수에 관계없이 엔트로피를 최소화하도록 설계되어 있습니다. 현재 연구에서 선암종, 편평 세포 암종 및 비암의 패턴을 식별하는 단일 모델을 여러 개별 모델로 분할해도 더 나은 결과를 얻지 못했습니다. 우리의 실험 결과는 개별 분류기와 3등급 모델 사이에 유의미한 차이가 없음을 보여주었습니다. AUC 점수는 선암의 경우 0.9548(0.9450–0.9646), 편평세포암의 경우 0.9414(0.9239–0.9588)였습니다.
Throughput comparison and memory consumption
처리량 비교 및 메모리 소비
그 후 분당 처리되는 슬라이드 수를 측정하여 다양한 방법 간의 교육 및 추론의 컴퓨팅 처리량을 비교했습니다. 모든 실험은 21,500 × 21,500(배율 4배) 및 11,000 × 11,000(배율 2배)의 두 가지 이미지 해상도에서 수행되었습니다. 특히, MIL 방법의 변형 중 처리량이 비슷하기 때문에 k = 1인 표준 MIL을 성능 측정을 위한 대표로 채택했습니다. 제안하는 방법은 입력을 분할하지 않고 이미지를 직접 피팅합니다. 메모리 부족 문제를 방지하기 위해 UM 메커니즘을 활용하고 최적화하여 그래프 편집 및 혼합 정밀도를 통해 임시 데이터를 호스트 메모리로 효율적으로 오프로드했습니다. 일반 UM과 비교하여 전체 슬라이드 훈련 방법의 처리량은 그림 6a에 표시된 것처럼 최적화된 메모리 액세스와 혼합 정밀도 훈련을 모두 통합하여 6.26배까지 가속화할 수 있습니다. 또한 우리가 제안한 방법은 가장 일반적으로 사용되는 분산 학습 방식인 동기화된 데이터 병렬성과 직교 통합하여 더욱 가속화할 수 있습니다. 우리는 16 GPU의 하드웨어 구성으로 TAIWANIA 2에서 실험을 수행했습니다. 교육 프로세스는 그림 6c에 표시된 것처럼 최적화되지 않은 단일 GPU와 비교하여 64.60배의 처리량을 달성했습니다.
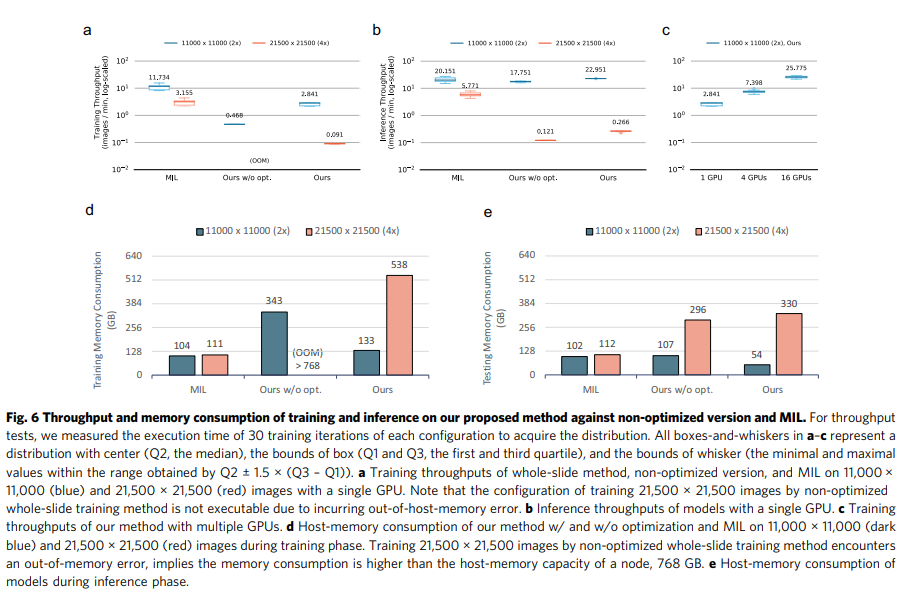
MIL 방식은 패치 기반 프로토콜을 따르며 추가 CPU-GPU 스와핑 없이 GPU에 패치를 배치할 수 있으며 교육 및 추론 단계 모두에서 높은 효율성이 유지됩니다. 그림 6에서 보는 바와 같이 입력 크기가 11,000 × 11,000, 21,500 × 21,500일 때 학습 단계에서 제안한 방법보다 MIL 방법의 처리량이 각각 3.5배, 15.7배 빨랐다. 특히 추론 단계에서 입력 크기가 11,000 × 11,000일 때 우리 방법의 처리량이 MIL 방법보다 1.3배 빠른 반면, 크기가 21,500 × 21,500일 때 16.4배 느렸다. 이는 우리 방법의 메모리 오버헤드가 선형적으로 확장되지 않아 서로 다른 입력 크기 간에 처리량 차이가 발생했음을 나타냅니다. 평균적으로 우리 방법은 x2 및 x4 배율을 실험할 때 수렴에 도달하는 데 100 GPU-day 및 1200 GPU-day가 소요된 반면 MIL 방법은 훈련 단계에서 30 GPU-day 및 120 GPU-day가 걸렸습니다. 추론 단계에서 제안한 방법은 1.5 GPU 시간과 80 GPU 시간이 소요되어 ×2 및 ×4 배율로 1397개의 WSI를 완성한 반면, MIL 방법은 동일한 실험 조건에서 1.5 GPU 시간과 5 GPU 시간이 소요되었습니다.
제안한 방법은 UM이 활성화되어 있어 GPU 메모리 크기의 제약을 받지 않지만 모델 학습 중에 생성된 중간 데이터를 저장하기 위해 적절한 호스트 메모리 공간이 필요합니다. 우리는 11,000 × 11,000 및 21,500 × 21,500 입력 모두에서 유휴 상태 동안의 호스트 메모리 사용량에서 최대 호스트 메모리 사용량을 빼서 서로 다른 방법 간의 호스트 메모리 사용량을 측정했습니다. 그림 6에서 알 수 있듯이 MIL 방법의 메모리 소비는 두 이미지 크기 모두 훈련 및 추론 단계에서 일정하게 유지되었습니다. 입력 이미지의 크기와 상관없이 MIL은 한 번에 하나의 패치를 처리하므로 패치 처리를 위한 고정 크기의 임시 메모리 공간이 필요합니다. 대조적으로, 우리 방법의 메모리 소비는 글로벌 컨텍스트 정보를 저장하기 위해 입력 해상도에 따라 확장됩니다. 메모리 최적화 및 혼합 정밀도 훈련을 통해 우리의 방법은 훈련 중에 최적화되지 않은 버전이 소비하는 메모리의 절반 미만을 소비했습니다.
Discussion
패치 기반 방법은 컴퓨팅 가속기의 메모리 제약을 쉽게 우회하기 때문에 디지털 병리학을 위한 딥 러닝에서 널리 사용되었습니다. 감독된 패치 기반 방법에는 일상적인 병리학에서 사용할 가능성이 없는 패치별 주석이 필요합니다. 또한 WSI에 대한 자세한 주석을 생성하는 것은 매우 힘든 작업입니다. 전문가는 단일 WSI의 일부에만 주석을 추가하는 데 1시간이 걸릴 수 있습니다. 또한 조직 유형 간의 경계가 종종 모호하여 병리학자 간에 불일치가 발생합니다. 조직 형태의 높은 가변성으로 인해 주석 중에 가능한 모든 예를 다루기가 어렵습니다. 이러한 단점은 딥 러닝 모델을 전문가가 정의한 주석의 강한 편향에 노출시키고 포괄적으로 학습하기 어렵게 만듭니다. 전문가의 주석 부담과 선택 편향을 피하기 위해 가장 최근의 연구는 WSI 내부의 관계를 탐색하도록 딥 러닝 모델을 훈련시켜 직접적인 임상 진단을 내릴 수 있는 취약한 감독 방법을 적용했습니다.
자세한 주석 없이 암 분류기를 교육하면 전문가의 부담이 줄어들고 DNN 모델이 즉시 사용 가능한 사인아웃 진단을 통해 수많은 WSI의 이점을 얻을 수 있습니다. 이전 연구에서 패치별 주석으로 훈련된 강력한 감독 모델을 사용하여 암을 탐지하는 방법은 약한 감독 모델을 여전히 능가했습니다. 그러나 주석이 너무 비싸고 강력한 감독을 통해 훈련된 모델이 대상에 주석이 추가되는 방식에 따라 제한되기 때문에 암 탐지를 위한 약한 감독 모델에 대한 연구가 인기를 얻고 있습니다.
슬라이드 진단과 같은 약한 레이블로 MIL을 훈련할 수 있지만 몇 가지 단점이 모델 성능에 영향을 미칠 수 있습니다.
(1) 초기 교육 반복에서 잘못 선택된 패치는 무작위 초기화로 인해 지역 최소값에 모델을 가둘 수 있습니다. 경우에 따라 모델은 처음 몇 에포크 후에 개선을 멈춥니다. (2) MIL은 k-most 대표적인 패치를 활용하려 하고 다른 패치에 포함된 다른 관련 정보는 포기한다. 그러나 k-most 대표 패치의 크기는 하이퍼파라미터이며 진정한 정보 영역은 슬라이드마다 다를 수 있습니다. k-most 대표 패치는 관련 없는 패치를 양성으로 추월하거나 진단에 중요한 비정형 패턴을 포함할 수 있는 능력이 부족할 수 있습니다.
약한 감독으로 알고리즘과 훈련 파이프라인을 수정하여 메모리 부족 문제를 피하는 대신 훈련 파이프라인을 수정하지 않고 수많은 이미지로 CNN을 직접 훈련하기 위해 UM 메커니즘을 활용하는 것이 더 간단하다고 생각합니다. UM을 사용하면 GPU가 호스트 메모리에 직접 액세스할 수 있으므로 용량이 기가바이트에서 테라바이트로 확장됩니다. UM 메커니즘은 PCIe(Peripheral Component Interconnect Express) 인터페이스를 통한 빈번한 데이터 교환으로 인해 느린 GPU와 호스트 메모리 간에 데이터를 교환하여 작동합니다. 작업 기억의 사용을 제한하면 이 연구에서 입증한 것처럼 상당한 가속이 발생할 수 있습니다. 그러나 20,000 × 20,000 픽셀보다 큰 이미지에서 CNN을 훈련하는 것은 엄청나게 느립니다. 결국 호스트 메모리의 제한이 발생합니다. 따라서 보다 메모리 효율적인 알고리즘이나 교육 방법에 대한 추가 연구가 필요합니다. 현재 연구에서는 ×4 대물 렌즈와 동등한 배율로 WSI를 처리했습니다. ×20 또는 ×40 배율의 해상도가 필요한 이미지 인식 문제를 해결하려면 2단계 접근 방식을 취하는 것이 좋습니다. 해당 영역의 이미지는 최종 이미지 인식 작업에 사용해야 합니다. 이 과정은 병리학자의 실생활과 매우 유사합니다.
Campanellaet al의 [23]논문에서 MIL이 슬라이드 레벨 레이블만 있는 WSI 데이터 세트를 사용하여 우수한 결과를 얻을 수 있음을 보여주었습니다. 이 연구에서 우리는 학습을 위해 전체 WSI를 사용하여 우수한 결과를 얻을 수 있음을 입증했습니다. 두 가지 가능한 설명이 이를 설명할 수 있습니다. 첫 번째는 샘플링 프로세스의 임의성이 주어지면 MIL은 동일한 성능 수준에 도달하기 위해 훨씬 더 많은 수의 교육 샘플이 필요하다는 것입니다. 두 번째는 패치 수준에서 실측 정보가 부족하기 때문에 MIL이 달성할 수 있는 성능에 상한선이 존재한다는 것입니다. 따라서 수만 개의 WSI가 있는 데이터셋을 사용하여 두 가지 방법을 비교하는 추가 연구가 필요할 수 있습니다.
CAM을 통한 우리 모델의 병변 국소화는 대부분의 경우 좋은 커버리지를 보여주었습니다. 그러나 우리가 제안한 방법에서 CAM의 의미는 암세포 위치와 약간 다릅니다. CAM으로 강조 표시된 영역은 예측과 매우 관련이 있습니다. DNN은 주어진 데이터 세트에서 구별 가능한 기능을 사용하여 이미지를 그룹으로 분류하므로 컨텍스트 편향과 같은 빈번한 부작용이 발생할 수 있습니다. 예를 들어, 자동차와 보트를 학습하도록 훈련된 분류기는 보트 자체뿐만 아니라 물도 강조합니다. 보트에는 항상 물이 수반되기 때문입니다. 우리의 경우 편평 세포 암종에 대한 CAM은 암 영역뿐만 아니라 괴사 영역도 강조했습니다 (보조 그림 1). 괴사는 편평 세포 암종 이외의 질병, 예를 들어 신체적 손상이나 감염으로 인해 발생할 수 있다는 사실에도 불구하고 이러한 질병은 생검을 거의 요구하지 않으므로 훈련 데이터 세트에서 과소 표현되었습니다. 따라서 모델은 괴사가 편평 세포 암종의 식별 특징임을 학습했습니다.
딥 러닝 모델은 결정을 내리기 위해 가능한 모든 단서를 수집하기 때문에 이러한 약한 관계 또는 후광 효과가 선암과 편평 세포 암종을 구별하는 데 유용하다는 것을 모델은 불가피하게 학습합니다. 주의 지도를 안내하기 위해 추가 감독을 추가한 Li et al.과 유사하게 이 문제를 해결하는 한 가지 방법은 암 세포를 지정하기 위해 자세히 주석이 달린 적은 수의 슬라이드를 추가하는 것입니다. 이러한 주석은 약한 관련 표현에서 암 표현을 분리하는 모델에 대한 힌트를 제공합니다. 향후 연구에서는 슬라이드 수준 주석과 제한된 세부 주석을 모두 활용하기 위한 통합을 개발하여 보다 포괄적이고 정확한 모델을 달성할 수 있습니다.
영상의학과의 인공지능(AI) 발전에 비해 병리학 AI의 발전은 더디다. 이는 데이터 부족 때문이 아니라 주석의 부담 때문이라고 판단합니다. 대규모 의료 센터는 연간 최대 50만 개의 슬라이드를 생성할 수 있지만 일반적인 디지털 병리학 AI 프로젝트는 수백 개의 슬라이드만 사용합니다. 병리학 AI 프로젝트의 범위는 미시적 수준에서 수행되기 때문에 본질적으로 느린 주석에 의해 제한되는 경우가 가장 많습니다. 우리의 방법은 상세한 주석의 필요성을 줄임으로써 병리학 AI 연구에서 보다 빠른 진전을 위한 길을 열어줍니다. 우리의 방법은 다양한 분류 작업에 적용될 수 있으며 잠재적으로 다중 레이블 학습(예: 폐 종양 섹션에서 여러 조직 하위 유형의 존재를 결정하기 위한 것)에도 적용될 수 있습니다. 우리는 우리의 방법이 강력하게 지도되는 방법과 결합될 수 있을 때 가장 유용할 것으로 기대합니다. 이를 통해 약하게 레이블이 지정된 많은 양의 데이터를 활용하여 조잡한 이해를 얻을 수 있습니다. 그 후 전략적으로 주석이 달린 작은 데이터 세트를 사용하여 성능을 미세 조정하여 다중 레이블 분류 또는 하위 분류 작업에서 우수한 병변 위치 파악 및 정확한 의미론을 달성할 수 있습니다.
Methods
Data set
2018년부터 2019년까지 TMUH, WFH, SHH에서 2843명의 환자로부터 수집한 총 9662개의 H&E(hematoxylin and eosin) 염색 FFPE(formalin-fixed paraffin-embedded) 표본이 검색되었습니다. 각각의 경우에 대해 생검 또는 절제된 폐 조직의 다른 부분에서 수집된 H&E 슬라이드가 적어도 하나 있을 수 있으며 지배적인 유형의 암 또는 비암 조직으로 진단될 수 있습니다. 폐 표본은 생검(32%, 3075 슬라이드) 또는 절제술(68%, 6587 슬라이드)로 샘플링되었습니다.
특정 유형의 희귀 폐암에는 샘플이 부족하기 때문에 샘플이 500개 미만인 경우를 필터링했습니다. 그 결과 소세포암종과 대세포암종으로 진단된 경우는 제외하였다. 최종 데이터 세트에는 선암 3876건, 편평 세포 암종 1088건, 비암 조직 2039건을 포함한 7003개의 슬라이드가 포함되어 있습니다. 진단은 적어도 두 명의 병리학자에 의해 확인되었습니다.
데이터 세트는 층화 샘플링 방법을 사용하여 각각 5045, 561 및 1397 슬라이드를 포함하는 훈련, 검증 및 테스트 세트로 무작위로 분할되었습니다. 각 사이트의 자세한 슬라이드 수는 표 2에 나열되어 있습니다. 달리 명시되지 않는 한 이 교차 사이트 데이터 세트 구성을 사용하여 실험을 수행했습니다.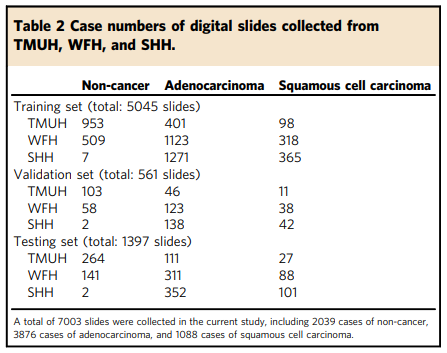
경증 사례에 대한 모델 성능을 조사하기 위해 테스트 세트의 양성 사례 외에 작은 병변(즉, 종양 면적이 조직 면적의 10% 미만)이 있는 암 사례만 사용했습니다. 이 하위 집합은 총 476개의 슬라이드로 구성되며 선암종 슬라이드 30개와 편평 세포 암종 슬라이드 39개, 양성 케이스 슬라이드 407개를 포함합니다.
데이터 액세스는 타이페이 의과대학 법무부 및 연구를 위한 국가 법률에서 승인한 정책(NO.1080506_1)을 준수했습니다. 데이터 수집은 참가자로부터 정보에 입각한 동의를 얻은 후에 진행하도록 허용되었습니다. 모든 WSI는 비식별화되었으며 슬라이드 수준 진단을 제외하고 환자 정보 또는 레이블 텍스트를 포함하지 않습니다. 수집된 데이터는 연구용으로만 제한됩니다.
모든 슬라이드는 Hamamatsu NanoZoomer XR에 의해 ×20 배율(픽셀당 0.46μm)로 스캔되었습니다. 각 슬라이드 이미지의 원래 해상도는 너비가 최대 110,592픽셀(평균: 65,683픽셀)이고 높이가 최대 55,552픽셀(평균: 40,593픽셀)입니다.
모델의 교차 사이트 일반화 능력을 평가하기 위해 TCGA 폐암 슬라이드도 현재 연구에 포함되었습니다. TCGA 진단 데이터 세트에는 TCGA-LUAD 진단 데이터(배율 정보가 제공되지 않았기 때문에 9개의 슬라이드가 폐기됨)의 선암종의 532개 H&E 염색 FFPE 조직 슬라이드와 TCGA-LUSC 진단 데이터의 편평 세포 암종 슬라이드 512개가 포함되어 있습니다. 모든 슬라이드를 Aperio 스캐너로 ×20(픽셀당 0.50μm) 또는 ×40 배율(픽셀당 0.25μm)로 스캔했습니다. 해상도 일관성을 위해 이 슬라이드는 슬라이드의 픽셀 간격(픽셀당 0.46μm)과 일치하도록 적절한 비율로 크기를 조정했습니다. 또한 Vahadane et al.32가 제안한 얼룩 정규화 방법을 사용하여 TCGA 슬라이드 이미지의 색상 스타일을 통일했습니다. 비 FFPE 슬라이드의 모델 성능에 대한 추가 연구를 위해 선암 슬라이드 1,067개와 편평 세포 암종 슬라이드 1,100개를 포함하여 TCGA-LUAD 및 TCGA-LUSC 조직 데이터 세트의 냉동 단면 슬라이드를 평가했습니다.
Multiple-instance learning
대부분의 이미지 이진 분류 작업은 다음 기준이 충족되는 경우 이미지를 여러 부분 영역으로 분할하여 MIL 문제로 공식화할 수 있습니다. 가방 또는 이미지는 대상이 적어도 하나의 인스턴스에 나타날 때 양성으로 레이블이 지정됩니다. 또는 지역; 대상이 모든 인스턴스에 없으면 음수로 레이블이 지정됩니다. 따라서 모든 긍정적인 백은 몇 가지 중요한 인스턴스만 사용하여 나타낼 수 있지만 의심스러운 인스턴스는 부정적인 백에 남아 있어서는 안 됩니다.
이 속성은 포지티브 백의 중요한 인스턴스에 포지티브 백 레벨 레이블을 적용하고 네거티브 백의 모든 인스턴스에 네거티브 백 레벨 레이블을 적용하여 백 레벨 레이블이 있는 학습 모델을 가능하게 합니다. 교육 중에 MIL은 분류기를 교육할 때 각 백에서 높은 점수의 인스턴스를 반복적으로 선택합니다.
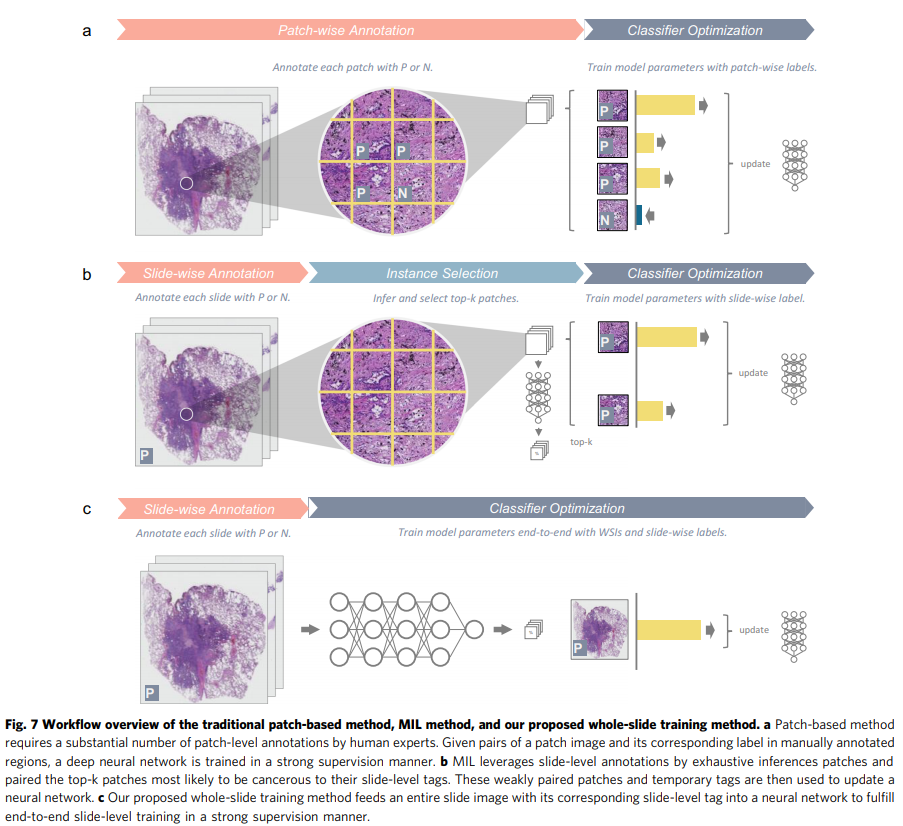
보다 구체적으로 MIL 방법은 그림 7과 같이 인스턴스 선택과 분류기 최적화의 두 가지 대체 단계로 분리될 수 있습니다. 인스턴스를 선택하는 동안 백 인스턴스에 대해 긍정적인 확률을 계산하는 인스턴스 선택기는 각 백에서 k-most 긍정적인 인스턴스를 마이닝하는 데 사용됩니다.
선택된 인스턴스를 사용하여 분류기는 양성 백에서 선택된 인스턴스의 확률을 최대화하고 음성 인스턴스에서 선택된 인스턴스의 확률을 최소화하도록 훈련됩니다.
MIL의 끝에서 분류자는 긍정적 사례의 가장 상대적인 패턴을 마이닝할 수 있으며 주어진 가방의 레이블은 최대 점수(max pooling)를 취하거나 k-most 인스턴스의 점수를 평균화하는 것과 같은 순진한 집계 방법으로 추론할 수 있습니다.
주어진 이미지를 나타내는 인스턴스 수를 결정하는 것은 합의가 없는 문제입니다. 일반적으로 최대 풀링(즉, k = 1)을 사용한 집계는 특히 교육 단계에서 관련 문헌 중에서 가장 일반적인 구현입니다. 왜냐하면 포지티브 백 레벨 레이블은 적어도 하나의 포지티브 인스턴스만 의미하기 때문입니다. k > 1로 설정하면 지정된 백에서 진정한 긍정 인스턴스가 k보다 작은 경우 인스턴스 오버샘플링이 발생하여 모델이 이러한 백에 대해 부정적인 것으로 예측하는 경향이 있습니다. k > 1을 사용하는 부작용은 특히 임계 패턴이 상대적으로 작은 일부 상황에서 발생할 수 있지만 모델이 이상값의 영향을 받을 가능성이 적기 때문에 k의 적절한 크기를 1보다 크게 설정하는 것이 더 강력한 것으로 나타납니다. 인스턴스. 균형을 맞추기 위해 다양한 MIL 변형이 제안되었습니다. EM(Expectation-Maximization) MIL19는 모델 교육 및 평가 중에 인스턴스 간의 공간 관계를 활용하여 k를 동적으로 선택하도록 제안됩니다. 여러 작업19,23,24은 모든 인스턴스의 예측 결과를 결합하기 위해 백 수준 집계 모델을 훈련합니다.
MIL methods on lung cancer type classification
폐암 유형 분류에 대한 MIL 방법
슬라이드 수준 레이블만 있는 폐암 분류 작업은 슬라이드가 선암종, 편평 세포 암종 또는 비암 조직으로 레이블이 지정되기 때문에 MIL 문제로 간주될 수 있습니다.
그림 7에서 볼 수 있듯이 각 슬라이드를 독립적인 가방으로 취급하고 각 가방 내부에 224 × 224 픽셀의 자른 패치를 인스턴스로 사용하여 분류기를 훈련하고 널리 채택된 최대 풀링 방법을 사용하여 인스턴스의 예측을 집계했습니다. 인스턴스 분류자의 경우 수정 초기화가 포함된 ResNet-50이 구현되었습니다. 우세한 폐암 유형 분류는 그림 1과 같이 세포 수준 형태가 아닌 조직 수준 형태를 검사하는 데 주로 의존하지만 분류기에 충분한 관찰 범위를 제공하기 위해 ×2 및 ×4 배율로 인스턴스를 생성합니다.
모델 교육 중에 견고성을 개선하기 위해 다음과 같은 데이터 확대를 적용했습니다.: 무작위 대비(0.5–1.5를 곱함), 밝기(0.65–1.35를 곱함), 색조(-32–32를 더함) 및 값(-32–32를 더함)을 포함한 뒤집기, 변환, 회전 및 색상 확대.
또한 배경에 속한 인스턴스(즉, 220보다 큰 RGB 값 모두)가 무시되어 전체 인스턴스 수를 80%까지 대폭 줄이고 전체 교육 프로세스 속도를 높였습니다. 배경 제거 후 훈련, 검증 및 테스트 데이터 세트에 각각 920만, 100만, 260만 타일이 포함되었습니다. 각 백의 대표 인스턴스를 선택하기 위해 선암종 또는 편평 세포 암종 인스턴스 및 마크 인스턴스일 가능성이 가장 높은 인스턴스를 선택하기 위해 다른 시험에서 k = 1, k = 3 또는 k = 5로 설정했습니다. 가방을 해당 슬라이드 수준 주석에 추가합니다.
EM-CNN-LR, EM-CNN-SVM, CNN-MaxFeat 기반 RF 및 MIL-RNN을 포함한 여러 이전 작업도 제안된 방법의 벤치마크로 구현되었습니다. EM-CNN-LR 및 EM-CNN-SVM은 둘 다 EM(기대 최대화)을 활용하여 k를 동적으로 조정합니다. 각 훈련 반복 동안 패치 예측 맵은 먼저 3 × 3 직사각형 커널을 사용하여 가우시안 블러링에 적용됩니다. 흐린 예측 맵의 예측 점수가 이미지의 패치 중 이미지 수준 임계값(0.1번째 백분위수 점수) 또는 클래스 수준 임계값(클래스의 0.05번째 백분위수 점수)보다 높은 경우 대표 타일이 선택되었습니다.
백 레벨 모델을 훈련하기 위해 모든 패치의 모든 클래스 확률을 합산하여 패치 예측 결과의 클래스 히스토그램을 계산한 다음 백 레벨 분류기, 로지스틱 회귀 분석기(LR) 또는 방사형 지원 벡터 머신(SVM)에 입력합니다. 최종 예측을 위한 기본 함수(RBF) 커널.
값을 직접 평균화하는 대신 CNN-MaxFeat 기반 RF는 패치 결과 위에 추가 임의 포리스트 집계 모델을 교육합니다. 구체적으로 k = 3인 표준 MIL에 의해 훈련된 패치 수준 모델을 통해 각 블록에서 가장 높은 확률의 패치를 선택하여 특징 벡터를 추출한 다음 이러한 특징 벡터를 평균화하여 최종 예측을 위해 랜덤 포레스트 모델에 입력합니다. 마지막으로 MIL-RNN 방법은 128개의 히든 유닛이 있는 순환 신경망(RNN)을 훈련하여 표준 패치 수준 모델에서 선택한 상위 k 인스턴스를 집계합니다. 성능을 서로 공정하게 비교하기 위해 모든 MIL 변형은 모든 실험에서 수정 초기화와 함께 ResNet-50을 채택했습니다.
Whole-slide training method.
하드웨어 메모리 제약 문제에 대한 해결 방법으로 MIL은 일반적인 CNN 교육 파이프라인을 변경하므로 몇 가지 단점이 있습니다. 첫째, 분류자의 무작위 초기화로 인해 초기 훈련 단계에서 인스턴스가 거의 무작위로 선택되었습니다. 이러한 초기 단계의 선택된 인스턴스는 다음 훈련 과정에서 분류기의 선택 전략 경향에 큰 영향을 미칩니다. 일부 상황에서, 예를 들어 암세포 자체가 아닌 과형성 조직을 동반하는 잘못 선택된 사례는 분류기가 국소 최소값으로 떨어지도록 유도하여 몇 에포크 후에 개선을 멈출 수 있습니다.
둘째, top-k 대표 인스턴스는 정보 영역을 수행하거나 관련 없는 영역을 추월할 수 있으므로 모델을 대상을 포괄적으로 학습하도록 제한합니다. 관련 없는 인스턴스를 긍정적으로 추월하는 것은 훈련 절차에 더 가혹할 수 있기 때문에 대부분의 구현은 가장 관련 있는 인스턴스만 취하도록 k = 1로 설정하며, 이는 모델이 진단에 중요한 비정형 패턴을 포함할 수 있는 능력이 부족함을 나타냅니다.
대조적으로 우리는 표준 CNN 아키텍처와 통합 메모리(UM) 메커니즘을 통합하여 수억 픽셀의 입력을 직접 지원하여 평소와 같이 모델을 훈련시키는 전체 슬라이드 훈련 방법을 제안합니다(그림 7). 컨볼루션 레이어는 입력의 높이 및 너비 차원에 대해 수많은 로컬 변환을 수행하여 출력을 생성하기 때문에 입력 크기를 늘리면 CNN 모델에 더 많은 로컬 변환 부하가 발생하므로 알고리즘적으로 전체 슬라이드 이미지를 입력으로 사용할 수 있습니다. 그러나 슬라이드의 매우 높은 이미지 해상도로 인해 메모리 소비 규모가 쉽게 GPU 메모리의 한계를 초과합니다. 메모리 풋프린트를 분석하면 모든 텐서가 동시에 필요한 것은 아니라는 것이 분명합니다. 따라서 GPU에서 텐서를 오프로딩하면 GPU에 대한 인타임 리소스 수요를 줄일 수 있습니다.
CUDA 기능인 UM(통합 메모리)을 사용하면 GPU가 호스트 메모리에 대한 직접 액세스 권한을 부여할 수 있으므로 정방향 및 역방향 전파 중에 대부분의 중간 텐서를 수용할 수 있도록 즉시 테라바이트의 메모리를 제공합니다. 기본적으로 UM은 가상 메모리와 동일한 아이디어를 공유합니다. 통합 메모리 공간은 페이지로 구성되며 각 페이지는 GPU 또는 호스트 메모리에 가상으로 지정되고 물리적으로 저장됩니다. 총 페이지 수가 최대 GPU 용량을 벗어나면 제한된 수의 페이지가 GPU 메모리에 배치되고 나머지 페이지는 호스트 메모리에 배치됩니다. GPU 메모리에 저장된 페이지는 GPU 코어에서 직접 액세스할 수 있습니다. 그렇지 않으면 시스템은 사전에 대상 페이지를 호스트에서 GPU 메모리로 이동하는 온디맨드 데이터 마이그레이션을 트리거합니다. 종종 GPU 메모리가 가득 차면 요청된 페이지를 위한 공간을 확보하기 위해 GPU 메모리의 페이지가 호스트 메모리로 동시에 제거됩니다. 데이터 스와핑이라고 하는 이러한 프로세스를 통해 GPU는 스와핑을 위한 충분한 호스트 메모리 공간이 있는 한 통합 메모리 할당의 모든 콘텐츠에 액세스할 수 있습니다. Tensorflow에서 UM을 도입하는 것은 cudaMalloc에 의해 호출되는 모든 GPU 메모리 할당 요청을 cudaMallocManaged에 의해 호출되는 통합 메모리 할당으로 대체함으로써 간단하게 이행될 수 있습니다. UM은 투명하기 때문에 지루한 스와핑 작업은 모두 백그라운드에서 수행되며 Tensorflow에 대해 다른 수정을 가할 필요가 없습니다.
Performance optimization of whole-slide training method
전체 슬라이드 학습 방법의 성능 최적화
UM은 메모리 제약 문제를 피하지만, 느린 하드웨어 링크인 PCIe를 통해 호스트 메모리와 GPU 간의 빈번한 데이터 스와핑으로 인해 교육 처리량이 엄청나게 느려집니다. 이를 해결하기 위해 런타임 동안 데이터 스와핑을 조작하여 효율성을 높이기 위해 그룹 실행 및 그룹 프리페치라는 두 가지 메모리 최적화 기술이 제안되었습니다.
Group Execution은 GPU 메모리에서 스왑된 데이터를 호스트 메모리로 스왑 아웃하기 전에 철저하게 사용하여 스왑 양을 줄입니다. 대부분의 딥 러닝 프레임워크의 교육 프로세스 중에 모든 컴퓨팅 리소스를 활용하기 위해 여러 작업이 병렬로 실행됩니다. 각 작업에는 중간 데이터를 유지하기 위해 일정량의 메모리 공간이 필요하기 때문에 과도한 병렬 처리에는 더 많은 공간이 필요하며 때로는 GPU에서 제공하는 것보다 더 큽니다. 이때 많은 양의 데이터가 GPU와 호스트 메모리 사이를 빈번하게 오가며 "스래싱(thrashing)"이라고 하는 스와핑 양이 크게 증가합니다. 스래싱을 억제하기 위해 동시에 실행되는 작업의 총 메모리 소비가 GPU 메모리에 맞도록 그룹 실행이 구현되었습니다. 그룹 실행에서는 총 중간 데이터 크기가 GPU 메모리 크기보다 작도록 인접 작업이 그룹화됩니다. 작업의 동시 실행이 그룹 범위 내에서만 존재하도록 그룹이 순차적으로 실행됩니다.
Group Prefetch는 메모리 지연을 방지하기 위해 예정된 작업에 필요한 데이터를 미리 로드합니다. UM은 GPU 프로그램이 작업을 실행할 때 호스트 메모리에 저장된 데이터에 대한 온디맨드 액세스를 허용하지만 액세스는 비효율적입니다. 첫째, 온디맨드 액세스의 전송 속도(3.6GB/s)는 명시적 복사(10.3GB/s)만큼 빠르지 않습니다. 둘째, 데이터가 주문형으로 로드될 때 GPU 코어는 유휴 상태입니다. 이 문제를 해결하기 위해 Group Prefetch는 현재 그룹이 처리될 때 명시적 복사를 통해 다음 그룹에 필요한 데이터를 미리 가져옵니다. 이를 통해 계산과 통신을 병렬로 수행할 수 있습니다.
특히 그룹화는 교육 프로세스가 시작되기 전에 수행됩니다. 작업은 먼저 토폴로지 정렬에 의해 시퀀스로 구성됩니다. 둘째, 그룹화 프로그램은 첫 번째 n 작업의 총 메모리 소비를 반복적으로 계산하고 메모리 제한 바로 아래에서 최적의 n을 찾습니다. 셋째, 처음 n개의 연산을 첫 번째 그룹으로 표시하고 나머지 그룹은 동일한 과정을 반복하여 만든다. 마지막으로 그룹 간의 순차적 실행은 연산 순서를 강제하기 위해 딥 러닝 프레임워크에서 식별할 수 있는 작업 그래프에 제어 종속성을 삽입하여 구현됩니다. 마찬가지로 프리페치 작업이 작업 그래프에 추가되며 각 작업은 제어 종속성을 사용하여 그룹 기간 내 언젠가 프리페치를 강제로 호출합니다.
우리 방법의 최적화 훈련 속도를 더 얻기 위해 우리는 또한 혼합 정밀도 훈련 및 데이터 병렬성 분산 전략을 채택했습니다. 혼합 정밀도 학습을 통해 평균 풀링 레이어 이전의 그래디언트 및 피처 맵을 포함한 정밀도에 민감한 값을 제외한 데이터는 16비트 반정밀도 부동 소수점 숫자 형식으로 저장 및 계산되므로 메모리 요구 사항이 줄어들 뿐만 아니라 계산 속도도 빨라집니다. Tensor 코어를 사용하여. 그 동안 데이터 병렬성 분산 전략을 사용하여 여러 GPU에서 서로 다른 샘플을 처리하고 반복 후 평균 그래디언트를 적용했습니다. 서로 다른 노드에서 수집된 평균 기울기의 부드러움으로 인해 발생하는 배치 간의 무작위성 손실을 보상하기 위해 초기 학습률을 기본 학습률에 GPU 수의 제곱근을 곱한 값으로 설정했습니다.
MIL assumption in the whole-slide training
전체 슬라이드 교육에서 MIL 가정
자연 이미지의 분류자와 WSI의 분류자는 이미지 크기의 스케일 차이로 인해 교육이 크게 다릅니다.
일반적으로 224 × 224 공간 해상도의 이미지는 ResNet에서 컨벌루션 및 다운샘플링 레이어의 여러 스택 후에 7 × 7 공간 해상도의 2048개 기능 맵으로 압축됩니다. 이러한 레이어는 슬라이딩 윈도우 작업을 사용하기 때문에 각 7×7 특징 맵은 입력 이미지와 동일한 공간 배열을 유지합니다. 더 정확히 말하자면, 이러한 레이어는 특징 맵의 각 픽셀이 원본 입력의 특정 크기 영역을 단일 2048차원 임베딩 벡터로 인코딩하는 기능으로 간주할 수 있습니다.
원본 입력에 해당하는 특징 맵의 픽셀의 투영 크기는 수용 필드38라고 할 수 있습니다. 수용 영역을 넘어서는 정보는 인코딩할 수단이 없습니다. ResNet50의 작업에 따르면 최종 기능 맵의 수용 필드는 483 × 483으로 일반적인 입력 크기인 224 × 224보다 큽니다.
결과적으로 최종 기능 맵에서 픽셀의 수용 필드는 이미 이미지의 모든 정보를 포함합니다.
다음 GAP(Global Average Pooling) 레이어는 일반적으로 1 × 1 × 2048 벡터로 7 × 7 × 2048의 평균 기능 맵에 적용됩니다. 그러나 입력을 높이와 너비와 함께 수만 픽셀로 확대할 때 최종 기능 맵에서 주어진 픽셀의 수용 필드는 더 이상 전체 이미지를 덮지 않습니다. 이러한 차이는 WSI의 암 분류에서 중요합니다. 양성 슬라이드의 전체 조직에 비해 악성 부위가 상대적으로 작을 수 있기 때문에 중요한 부위를 덮는 수용 필드는 거의 없습니다.
다수 투표 집계 또는 글로벌 평균 풀링(Global Averaging Pooling, GAP)을 사용하여 기능 맵의 끝에서 중요한 신호는 암 패턴과 관련이 없는 기능 맵에서 나오는 신호로 인해 더욱 희석되었습니다. 그것은 궁극적으로 작은 암 영역이 있는 슬라이드를 식별하도록 모델을 제한합니다.
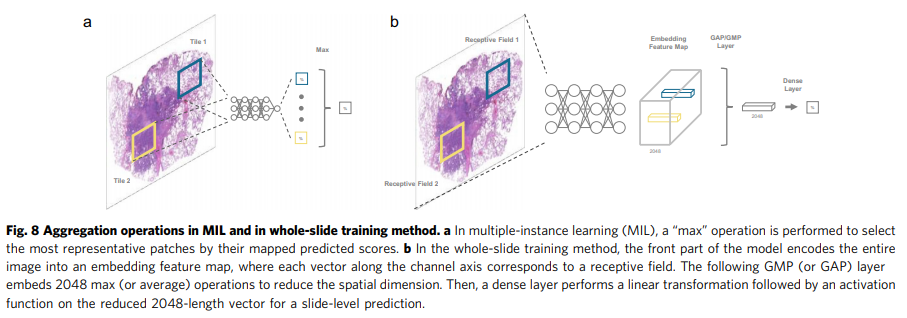
MIL에서 영감을 받아 GAP 레이어를 그림 8과 같이 2048 길이 벡터의 각 요소의 최대값만 유지하는 GMP(global max-pooling) 레이어로 대체합니다.
임베딩 벡터에 나타나는 큰 값은 의미 있는 특징이 추출되었음을 의미합니다. GMP를 채택함으로써 이러한 큰 값이 유지되므로 그 뒤에 있는 구별 가능한 신호가 보존됩니다.
또한 적절한 크기의 수용 필드를 갖는 것은 모델이 폐암 주요 유형을 식별하는 데 필요한 정보를 인코딩하는 데 중요합니다. ResNet50의 수용 필드 크기는 483 × 483 픽셀입니다. 모델의 수용 영역은 모델 구조에 따라 고정되어 있기 때문에 전체 슬라이드 이미지의 배율에 따라 수용 영역의 물리적 크기가 달라집니다. 더 정확하게 말하면 수용 필드는 ×4 및 ×2 배율에서 각각 약 1111 × 1111 µm^2 및 2222 × 2222 µm^2입니다. 현미경의 ×100 배율에서 조직 수준 형태를 분석하기 위한 병리학자의 시야(FOV)는 약 200 × 200 µm^2이지만, 우리 모델의 수용 필드는 폐암 유형을 식별하기 위한 정보를 인코딩하기에 충분합니다.
Whole-slide training method on lung cancer type classification
폐암 유형 분류에 대한 전체 슬라이드 교육 방법
그림 7에서 볼 수 있듯이 가속을 위한 엔지니어링 노력의 복잡성에도 불구하고 전체 슬라이드 교육 방법은 논리적으로 심층 신경망 엔드-투-엔드 교육과 동일합니다. MIL 분류기와 동일한 실험 조건을 유지하기 위해 모델 아키텍처로 수정 초기화31가 있는 ResNet-503을 사용했습니다. WSI는 ×2 및 ×4 배율로 크기를 조정한 다음 흰색으로 각각 11,000 × 11,000 픽셀 및 21,500 × 21,500 픽셀로 패딩되었습니다. 각 훈련 반복에 대해 각 훈련 샘플은 MIL 훈련 파이프라인에서와 동일한 증강 프로세스를 거쳤습니다.
Experiment setup
우리는 모든 실험을 다중 GPU, 다중 노드 슈퍼컴퓨팅 환경인 TAIWANIA 2에서 수행했습니다. 각 노드에는 8× Tesla V100 32GB-HBM2 GPU가 장착되어 있습니다. GPU 가속을 위한 소프트웨어 스택에는 CUDA 10.0 및 cuDNN 7.6이 포함되었습니다. 슬라이드 로딩에는 OpenSlide(버전 3.4.1), 모델 구축 및 훈련에는 TensorFlow(버전 1.15.3), Horovod39(버전 0.19.0), Open MPI(버전 4.0.1), Python용 MPI(버전 3.0.3) 다중 GPU 병렬 훈련을 가능하게 합니다. 모든 실험은 배치 크기 8, GPU당 1개 샘플로 실행되었습니다. Eq.에 의해 계산된 손실 함수로 3-클래스 범주형 교차 엔트로피를 최소화하여 모델을 최적화합니다.
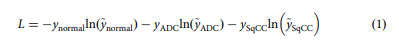
여기서 y는 실측 레이블을 나타내고 ỹ는 특정 주요 유형에 대한 모델 예측을 나타냅니다.
모든 학습 모델의 가중치는 ImageNet 사전 학습 가중치로 초기화됩니다. 훈련 진행과 함께 기울기 하강이라는 프로세스로 커널 가중치가 점차 업데이트되었습니다. 우리는 Adam 옵티마이저40(초기 학습률이 2e-5이고 유효성 검사 손실이 24 epoch에서 개선되지 않을 때 2e-6으로 감소함)을 사용하여 모델을 훈련하고 100개의 훈련 단계당 성능을 epoch로 평가했습니다. 교육 프로세스 중에 가장 낮은 유효성 검사 손실을 달성하는 가중치 집합만 평가를 위해 저장됩니다.
Statistics
다양한 방법의 슬라이드 수준 성능을 측정하기 위해 수신기 작동 특성(Area Under ROC, AUC) 아래 영역을 평가 메트릭으로 사용합니다. 95% 신뢰 구간은 Delong의 방법41을 사용하여 얻었습니다. 두 모델의 AUC를 비교할 때 양측 가설을 사용하여 Delong 테스트에 의해 P 값도 계산되었습니다. 모델의 AUC의 유의 수준을 평가하기 위해 귀무 가설로 항상 0.5를 반환하는 더미 모델을 채택했습니다.
다양한 방법의 처리량을 조사하기 위해 모델이 배치에서 훈련하는 데 경과된 시간이 기록되었습니다. 경과 시간의 분포를 추정하기 위해 동일한 절차를 30회 반복했습니다.
Reporting summary
연구 설계에 대한 추가 정보는 이 문서에 링크된 Nature Research Reporting Summary에서 확인할 수 있습니다.
Data availability
모델의 예측, 학습 곡선 및 처리량의 원시 데이터는 보충 데이터 1로 제공됩니다.
TMUH, WFH 및 SHH의 슬라이드 데이터는 환자 개인 정보 보호 제약으로 인해 공개적으로 사용할 수 없지만 교신 저자인 Chao-Yuan Yeh 또는 Cheng-Yu Chen의 합당한 요청에 따라 사용할 수 있습니다. 이 연구에서 교차 사이트 일반화 기능을 지원하는 슬라이드 데이터는 Genomic Data Commons Data Portal(https://gdc.cancer.gov)을 통해 TCGA에서 얻습니다.
Code availability
이 연구의 소스 코드는 CC BY-NC- 아래 https://github.com/aetherAI/whole-slide-cnn42 및 https://github.com/aetherAI/tensorflow-huge-model-support43에서 다운로드할 수 있습니다. SA 4.0 라이선스. 전체 슬라이드 CNN 교육 파이프라인은 모델 교육, 추론, 시각화 및 통계 계산 등을 포함하여 이 연구의 결과를 재현하기 위한 스크립트를 제공합니다. 또한 파이프라인은 다른 병리학적 사례에 원활하게 적응할 수 있습니다. Tensorflow Huge Model Support는 독립 실행형 Python 라이브러리로 Tensorflow에 대한 고효율 통합 메모리 교육을 가능하게 합니다.
