교차검증이란?
일반적으로는 train set으로 모델을 훈련 , test set으로 모델 검증을 진행합니다.
🥕 이 경우에 약점이 존재 test set에 과적합(overfitting) 하게 됨!!
고정된 test set으로만 학습을 하기 때문에 test set 통해서만 잘 작동하게 되는 경우가 발생할 수도 있다.
실제 데이터에 예측 수행하였을 시 엉망이 될 수도 있다!
이에 해결하고자 훈련용 및 시험용 데이터를 변경하는 교차 검증 이라는 방법론을 사용한다.
- 통계적인 평가방법
- 얼마나 잘 일반화 되어 있는지 평가 가능
- 데이터를 여러번 반복해서 나누고 여러 모델을 학습

전체 데이터셋을 일정한 비율 ex) 8:2 train:test로 나눌 수 있다고 한다면, 위와 같이 훈련용 데이터셋과 테스트 데이터셋을 교차 변경하는 방법론을 교차검증이라고 합니다.
교차 검증의 장단점?
장점
모든 데이터셋을 훈련에 활용가능 또한 모든 데이터셋을 평가에 활용할 수 있다고 볼 수 도 있다.
- 정확도 향상
- 특정 데이터셋에 대한 과적합 방지
- 데이터셋 규모가 적을 시 과소적합 방지
단점
- 모델 훈련 및 평가 소요시간 증가
교차 검증 기법 종류
- K-Fold Cross Validation (k-겹 교차 검증)
- Stratified K-Flod Cross Validation (계층별 k-겹 교차 검증)
- Hold-out Cross-Validation
- Leave-One-Out CV(LOOCV)
K-fold Cross Validation (k-겹 교차 검증)
테스트를 정확히 설정할 수록 모델이 더 잘 작동한다.
하지만 데이터가 그만큼 충분하지 않는 경우에는 좋은 결과를 내기가 어렵다.
이러한 단점을 보완하고자 하는 방법이 k겹 교차 검증이다.
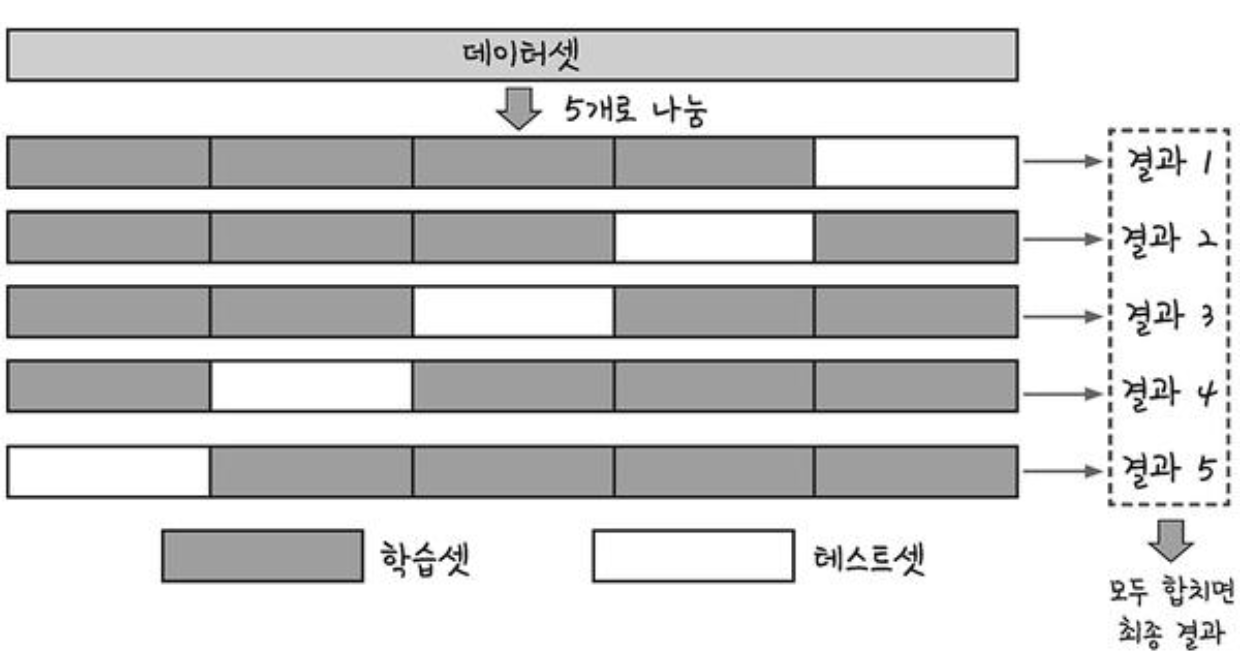
K-fold Cross Validation 이란?
- 가장 많이 사용되는 교차 검증 방법!
- 보통 회귀 모델에 사용
- 데이터가 독립적이고 동일한 분포를 가진 경우
- 중간 정도의 bias와 variance 가짐
k겹 교차 검증이란 데이터셋을 여러 개로 나누어 하나씩 테스트셋으로 사용하고 나머지를 모두 합해서 학습셋으로 사용하는 방법이다.
이렇게 하면 가지고 있는 데이터의 100%를 테스트 셋으로 사용가능하다!
총 K개의 성능 결과가 나오며, 이 k개의 평균을 해당 학습 모델의 성능이라고 한다.
Stratified K-Flod Cross Validation (계층별 k-겹 교차 검증)
데이터가 편향되어 있을 경우에는 k겹 교차검증 실행시 편향된 데이터가 고루 분할 되지 못하고 몰릴 수 있다.
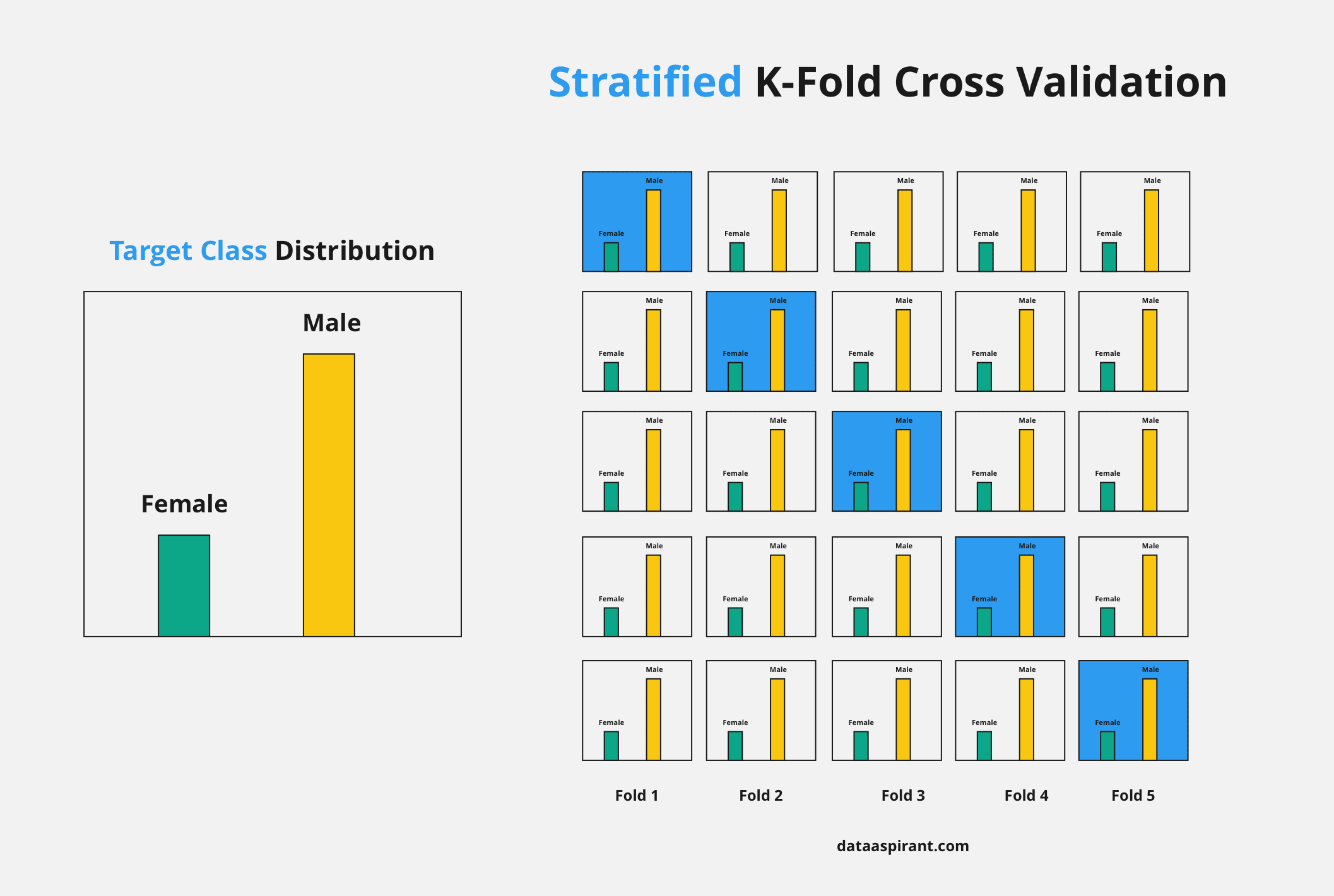
이때 데이터 클래스 별 분포를 고려하여 나눠주기 위해 계층별 k겹 교차 검증을 사용한다.
보통 분류 모델에 사용한다. <-> 회귀 모델 : k-fold
Hold-out Cross-Validation
전통적이고 널리 사용되는 머신 러닝 모델의 일반화 성능 추정 방법이다.
hold-out은 데이터셋을 훈련셋과 테스트셋으로 분리합니다. 데이터셋은 모델 훈련에 테스트셋으로 성능을 추정하는 데 사용합니다.
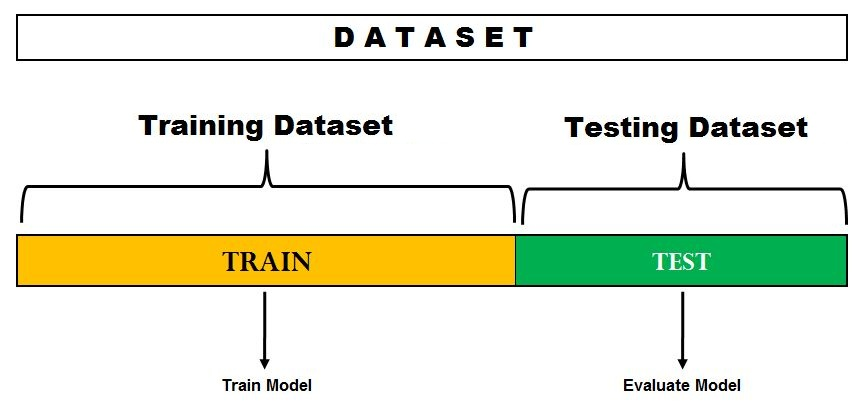
하지만 이렇게 훈련셋, 테스트셋으로 나누어서 성능을 평가하다보면 테스트셋이 모델의 파라미터 설정에 큰 영향을 미치게 되고, 결국에 과대적합의 위험이 존재한다
따라서 훈련 데이터셋, 검증 데이터셋, 테스트 데이터셋 세 개의 부분으로 나누는 것을 권장한다.
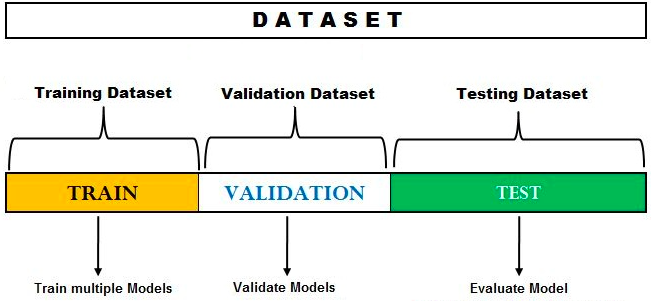
훈련 데이터셋은 여러가지 모델을 훈련하는 데 사용하고,
검증 데이터셋은 최적 파라미터들을 찾아가고, 테스트셋으로 모델의 성능을 평가하는 것이다.
LOOCV(Leave-One-Out CV)
교차 검증을 극단적으로 사용하여, 사례 개수만큼 많은 버킷으로 교차 검증을 하는 것을 말한다.
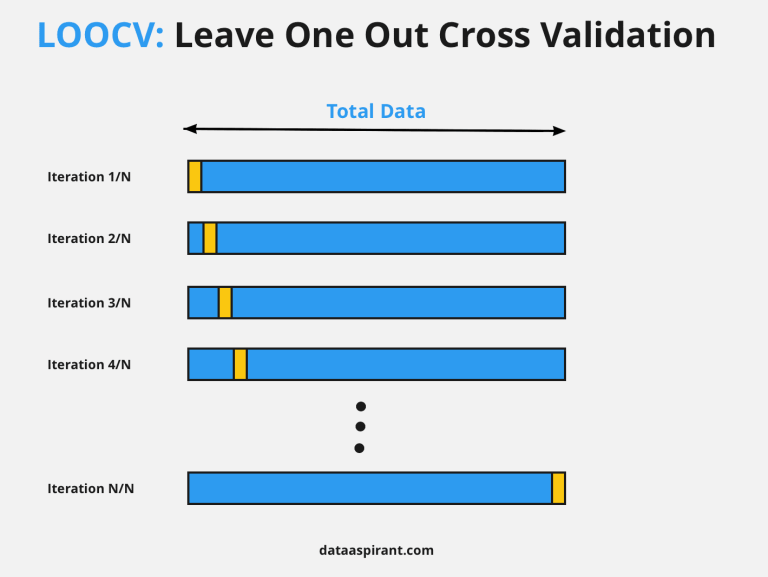
단 하나의 관측값만을 validation set으로 사용하고, 나머지 n-1개 관측값은 train set으로 사용한다. 총 n번 나누고 그것을 전부 사용하여 fit 하기 때문에 랜덤성이 없다 (무작위성이 개입 안한다)
- n-1개 관측값을 train에 사용하므로 bias가 낮음
- overfitting 되어 높은 variance를 가짐
LOOCV는 결정론적인 평가 방법입니다. 결정론적인 특성은 학습 알고리즘의 정확성을 비교하고 테스트할 때 유용하지만 비용이 많이 듭니다.
출처
더북 : https://thebook.io/080228/part04/ch13/05/
https://heytech.tistory.com/113
https://jhryu1208.github.io/data/2021/01/24/ML_cross_validation/
hoid-out
https://bskyvision.com/720
https://vitalflux.com/hold-out-method-for-training-machine-learning-model/
이미지
https://dataaspirant.com/7-loocv-leave-one-out-cross-validation/
계층별 k겹 교차 검증
https://huidea.tistory.com/30
https://jinnyjinny.github.io/deep%20learning/2020/04/02/Kfold/
