
✔️ 공부하며 배운 것
- 시간(시계열) 데이터 다루는 방법 행/열
- Area 차트
- 필터 적용법
✔️ 앞으로 To do List
- 해보고 싶은 분석의 데이터 생각하기
✔️ 오늘 활용한 자료
- 미국 실업률에 관련한 데이터
섹션 3
데이터 설명

데이터가 조금 산만한 느낌이 있다.
나이별로 중복 되는 것이 굉장히 많아 보이고,
나이별, 기간별로 적용을 하면 더 쉽게 파악할 수 있게 될 것 같다!
또한 데이터를 보니
- 나이에 관련한 실업률
- 기간에 따른 실업률
- 성별 따른 실업률
등, 실업률에 대하여 다양한 관게를 볼 수 있을 것 같다.
데이터 추출

데이터 라이브, 추출 변경이 가능하다.
🤔 왜 데이터 추출을 진행할까?
데이터의 양의 많은 경우, 몇개의 데이터만 가지고 진행을 하고 싶을 수가 있다. 그경우에 데이터 추출을 사용하여 진행해주면 된다.
이 부분이 조금 헷갈려서 고민을 해보았는데, Spotfire 의 embedded data와 기능이 흡사한 것 같다.
즉, 대시보드에 데이터를 담아 둔 것으로 이해했다.
+ 필요한 데이터만 추가로 남기기 (1600행 중 300개만 추출하여 사용하기 등등)
이부분은 틀린 부분이 있을 수 있다... 추후 수정해야 하는 부분이 생기면 사족을 붙이기로!
따라서 연결된 데이터의 값이 변경 되더라도 업데이트를 누르거나 추가작업을 하지 않는다면 대시보드에 작용이 되지 않을 것 같다!
이렇게 새로고침을 하여 추출한 데이터의 변경된 부분을 다시 적용하는 것 같은 기능도 있다.
시게열 작업하기
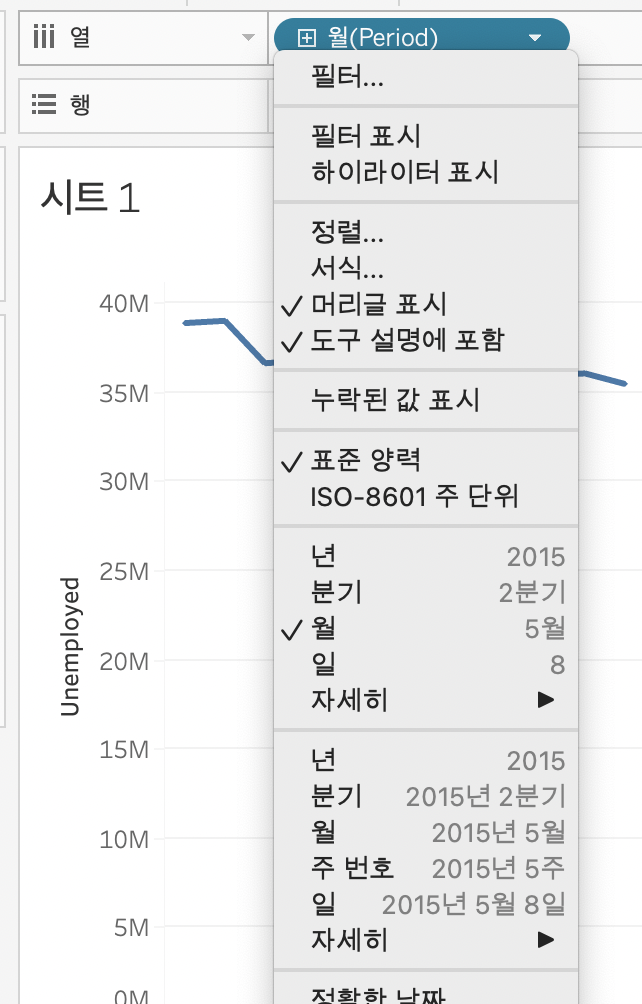
열의 필터를 보니, [년, 분기, 월, 일, 자세히], [년, 분기, 월, 일, 자세히] 가 위 아래 하나씩 있는 것을 알 수 있다.
뭐가 다른 것일까?
- 범주형 (카테고리)
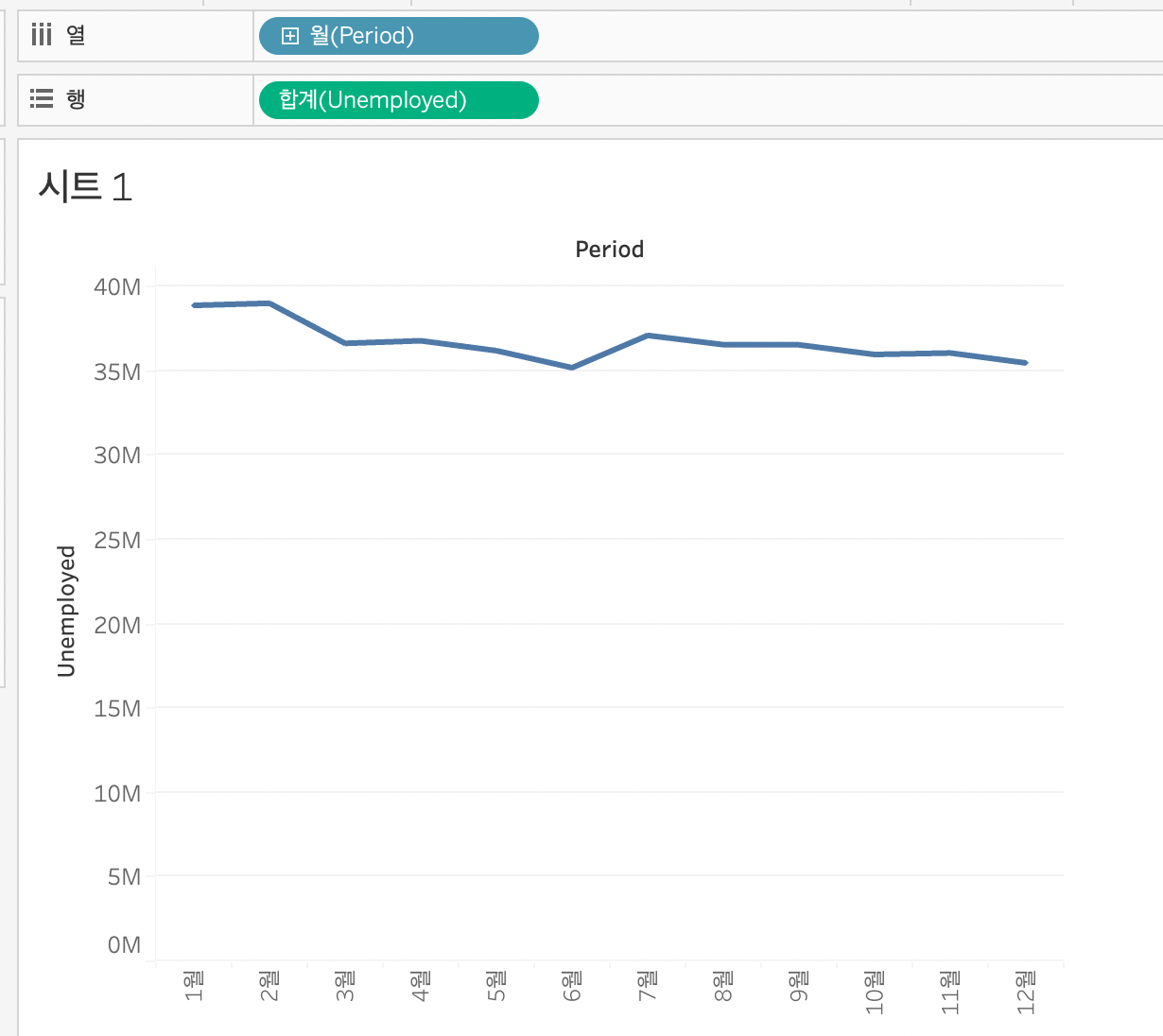
이렇게 1월~ 12월의 12개의 카테고리로 설정을 하게 된다.
열을 보면 파란색으로 나타내져 있다.

이렇게 년> 분기> 월을 선택하여 보면 카테고리로 나뉘어져 있는 것을 쉽게 확인할 수 있다.
- 연속형
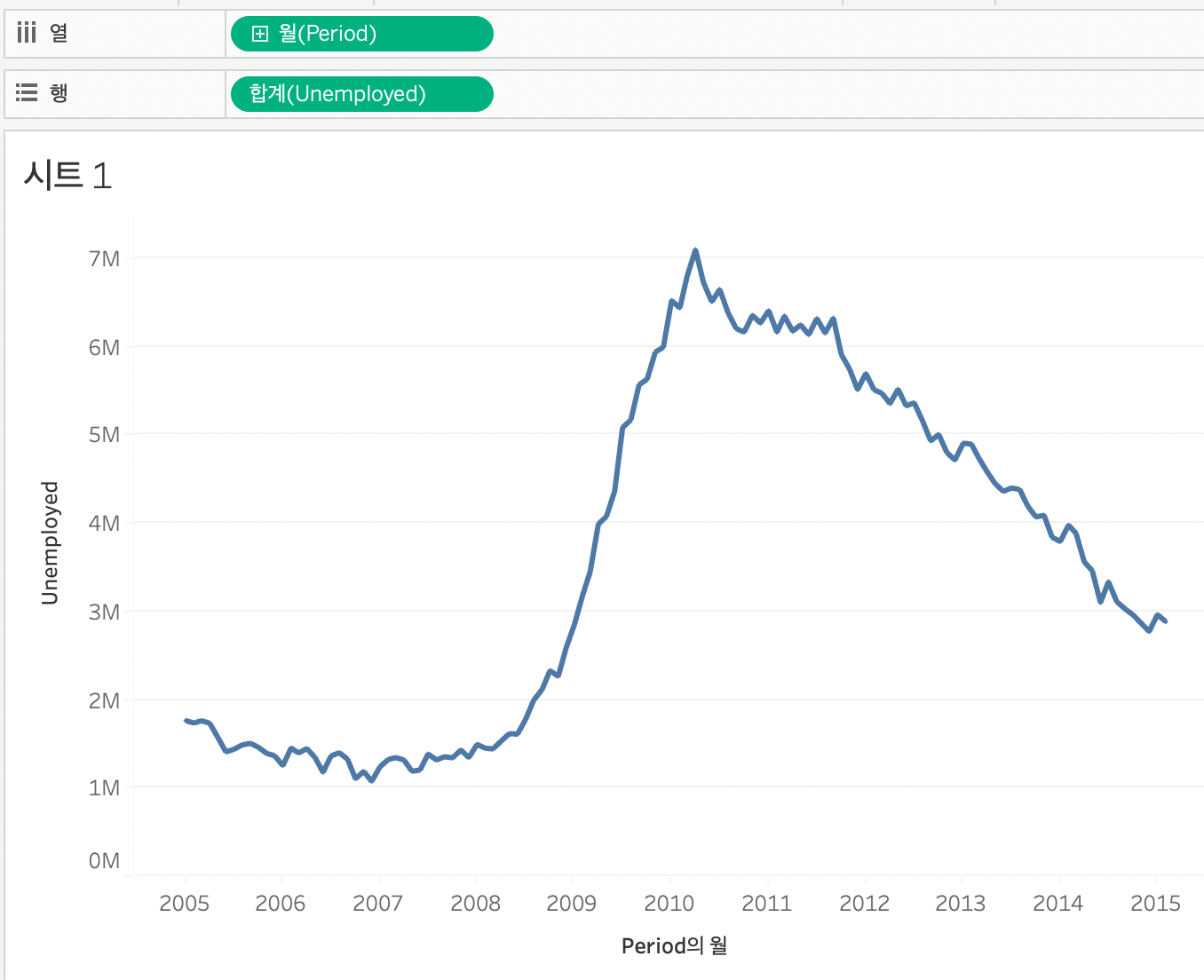
아래에 있는 월을 클릭하게 되면, 시간이 변수가 되고 측정값이 되는 것을 볼 수 있다.
열이 초록색임을 확인가능하다.
시각화 세분화
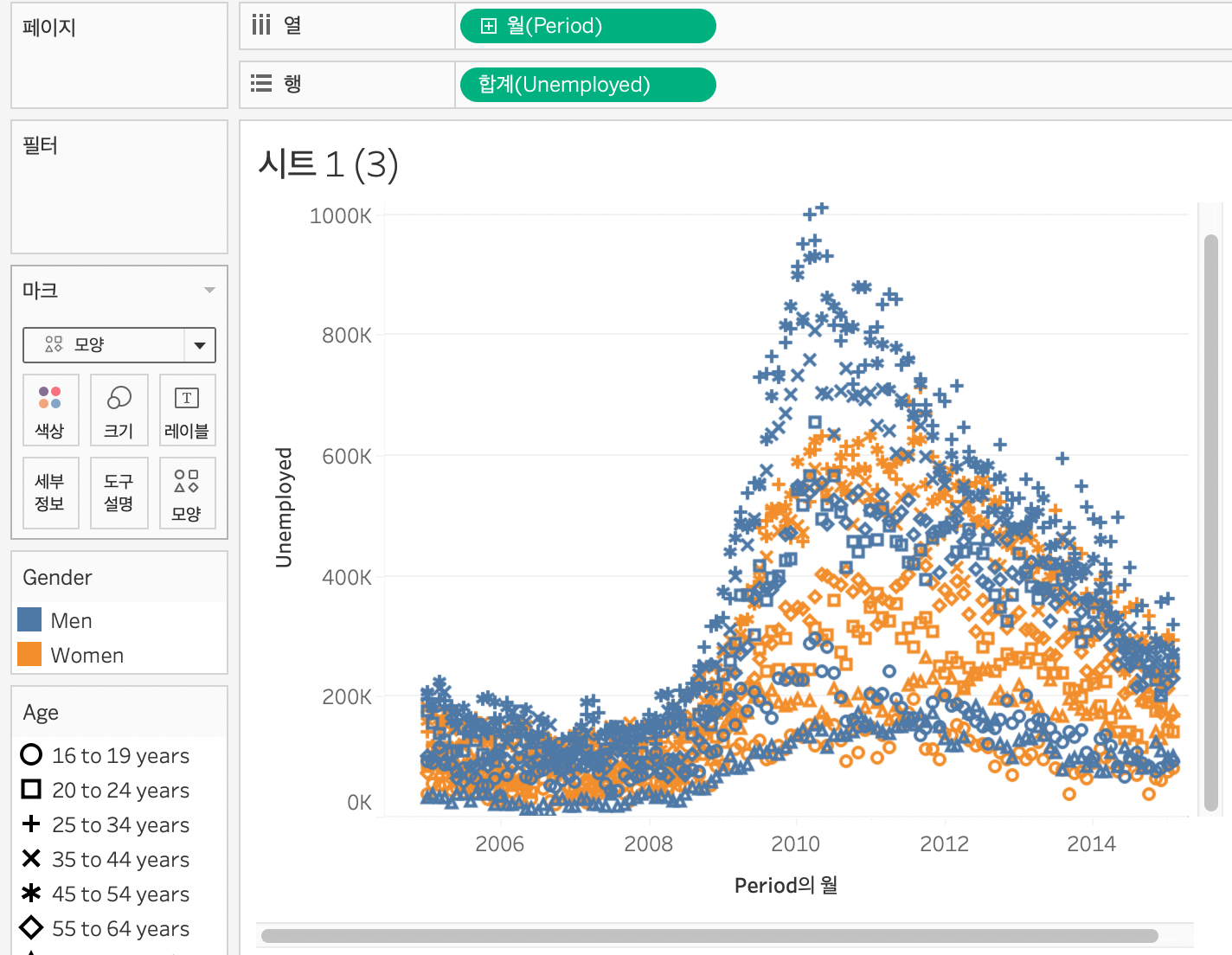
여러 가지의 변수를 세분화하여 대시보드에 시각화 할 수 있다.
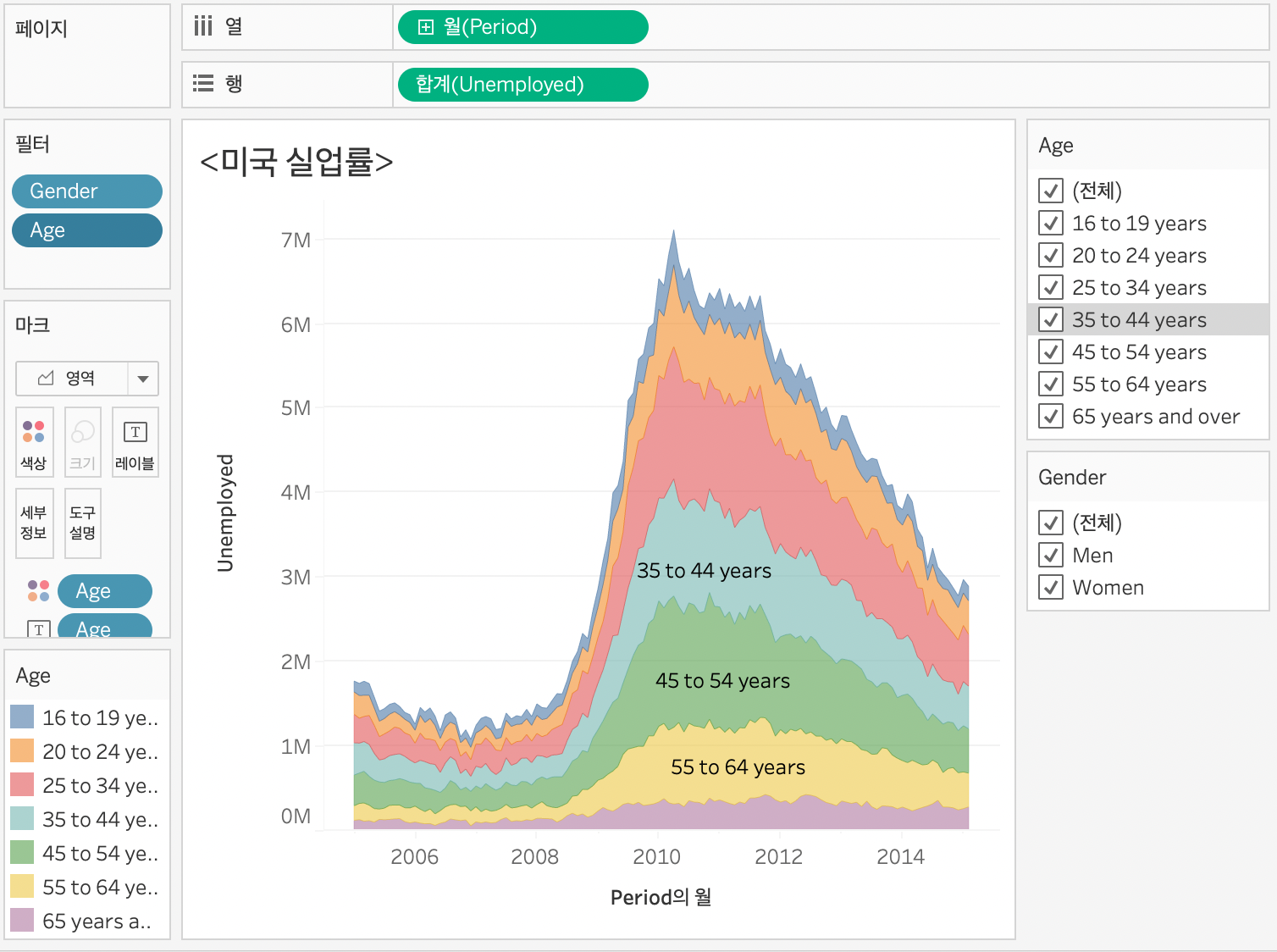
미국의 실업률을 나이별로 (모양), 성별로(색깔)로 나타낸 것을 알 수 있다.
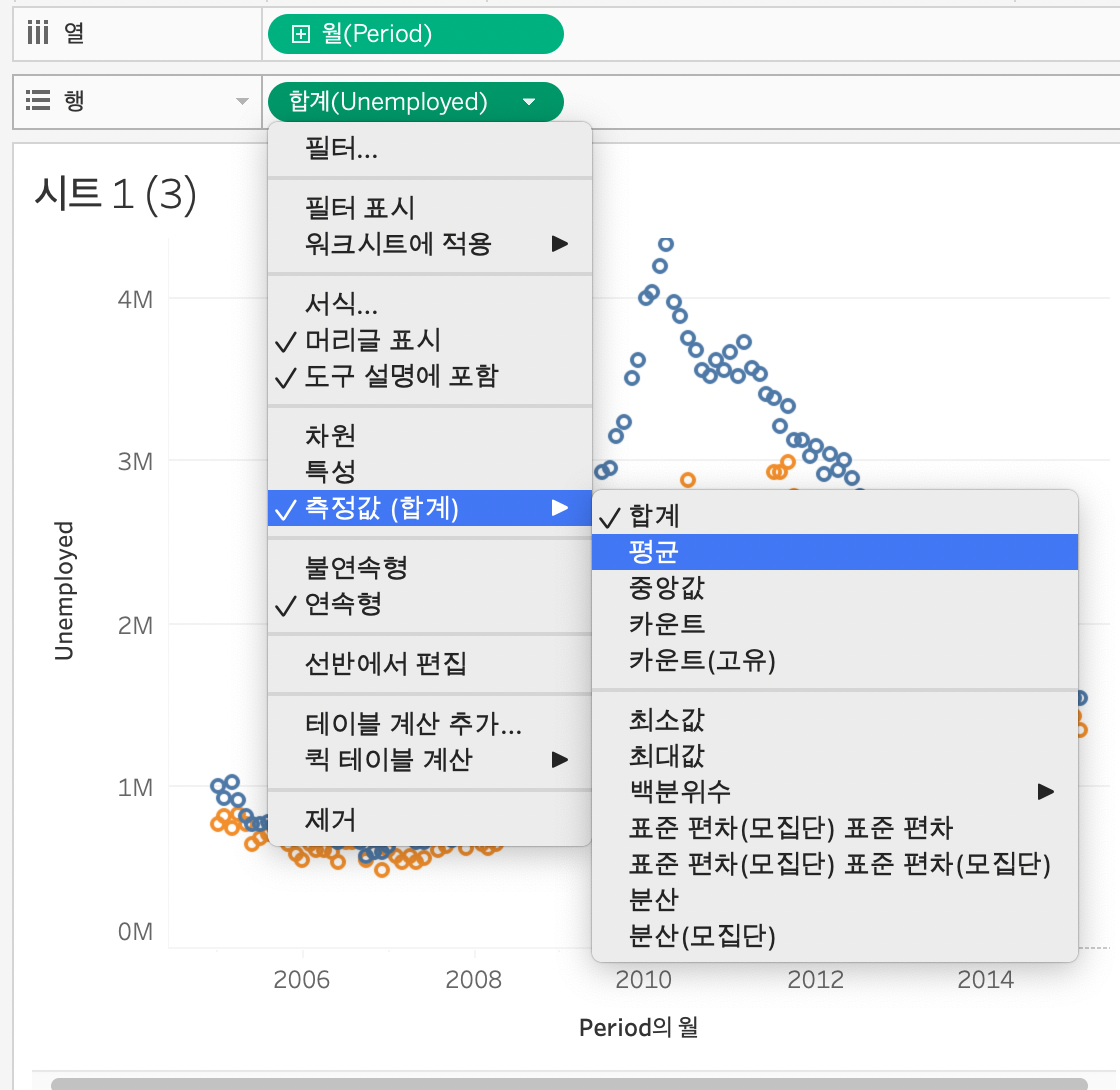
이처럼 측정값을 변경하여 적용이 가능하다.
AREA 차트 / 영역 차트
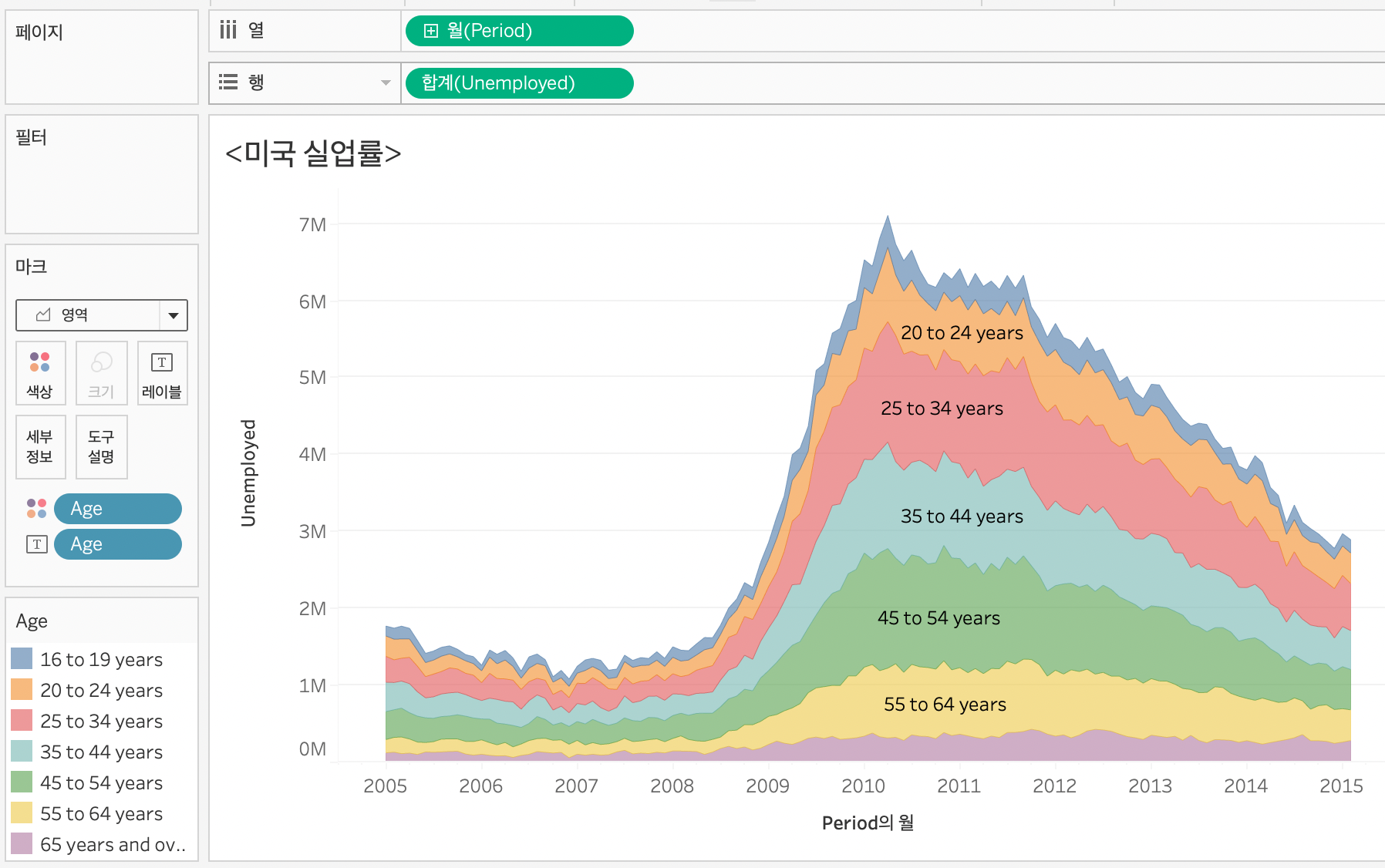
영역 차트로 설정하게 되면 우측의 범주가 바뀌는 것을 알 수 있다.0M~7M
나이에 따른 영역이 각각 독립적으로 세팅(?) 되어 있다고 생각하면 될 것 같은데,
각 나이가 가지고 있는 영역 (색깔)이 실업률 합계라고 보면 될 것 같다.
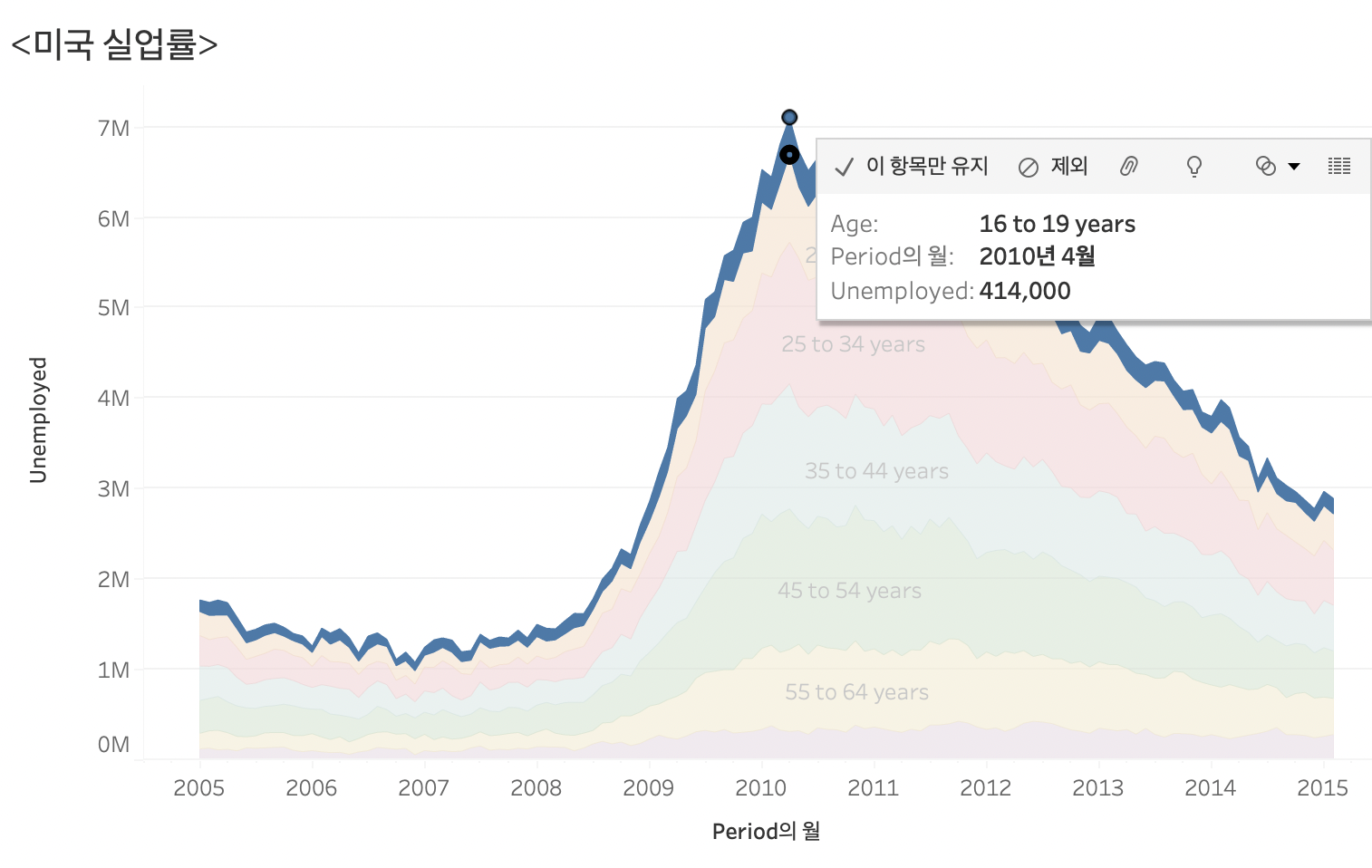
해당 영역을 클릭하면 더 자세한 정보를 보여준다. 저 작고 작은 영역이 16~ 19세에 해당하는 정보를 가지고 있다고 보면 될 것 같다.

라인차트의 y축을 보면 1600K까지이며 여기서는 16~19세의 실업률이 낮은 부근에 위치한 것을 볼 수 있다.
라인 차트는 y축의 그대로 읽어 드리면 되고, 영역 차트의 경우는 영역이 데이터를 나타내므로 유심히 살펴봐야 함을 알 수 있다.
필터
성별에 대한 정보도 보기 위해 필터를 걸어 내용을 확인이 가능하다.
이렇게 설정하게 된다면 
테이블의 변수 값들을 전부 볼 수 있는 간단한 대시보드를 만드는 데까지 완료하였다!
- 필터에 단일 보기를 클릭하여 한 개씩만 선택이 가능하도록 설정할 수 도 있다.
시각화 결과물을 보면 16-19세, 55~64, 보다는 20~~~54세까지의 실업률이 현저히 높은 것을 알 수 있는데, 다른 연령 범주보다 경제활동인구가 많기에 그에 따른 실업자도 많아 실업률이 높을 수 있겠다라는 생각이 든다.
1주차 회고
아직 어려운 부분이 들어가지는 않았으나, 기능별로 범주형, 연속형에 사용되는(?) 게 다르고 영어... 공부를 해야겠다.
또한 대시보드를 만들 때는 '나'의 편의성이 아닌 그것을 보는 '다른 사람'의 편의성에 맞추어 만들어야 함을 다시 느꼈다.

후 ^0^ 빨리 수료증 받고 싶다.
