
INTRO
올해 6월 전후로 M1에 Pytorch가 M1 GPU를 쓸 수 있는 Pytorch 1.12를 내놓았다. 그리고 최근, 2022년 12월에 Pytorch 2.0이 발표되었다. Pytorch 2.0에서 강조하는 부분은 torch.compile() 이다. torch.compile()뿐만 아니라, TorchDynamo, TorchInductor, AOTAutograd, PrimTorch 등을 통해서도 효율성과 연산속도를 올린 것 같다. 또한, HuggingFace와 timm 라이브러리와의 호환성도 대폭 높였다고 한다.
9월말부터 Google Colab의 배신(=pay-as-you-go, 즉, 종량제 요금제로 바뀌면서)으로 필자 역시도 간단한 연습이나 실습의 경우, M1에서 진행할 수 밖에 없었다. 이어드림스쿨2기 과정에서 토치의 호흡으로 하드캐리하고 있었는데, 간단한 파이토치 Basic Task로 강의를 하는 경우에는 M1으로 진행을 하게 되었다. 그러던 와중에 Pytorch 2.0 (nightly 버전)이 나왔다.
여러분도 한 번 체험해보지 않겠는가?
TMI
- 필자의 경우, 어쩌다보니 Pytorch nightly 버전으로 1.12, 1.13, 1.14 그리고 Pytorch 2.0을 사용해보게 되었는데 M1 GPU의 속도가 올라갔다. 그리고 올해가 가기 전에 M1에 Pytorch 2.0을 설치하는 것에 대해 포스트를 남기고 있다.
- 사실 12월초였나? 1.14.0.dev.20221203 버전이 설치가 되었었다. 이 버전에서는 torch.compile()이 작동이 되어서 구글링해보니, (Pytorch 혹은 Meta 관계자의 말은 아니었지만) 이 버전이 Pytorch 2.0이라고도 했었다.
INSTALL
1) M1 Part6 - '니들이 mps를 아느냐?' 포스트를 참고하여 설치해보자.
: 설치방법은 완전 동일하다. 이 포스트를 보고 있는 당신의 M1 맥에 Pytorch 라이브러리가 아예 설치가 안 되어 있다면, 위 링크 방법대로 그대로 설치하면 된다. 동일한 방법으로 그대로 Pytorch 버전이 다음과 같이 뜰 것이다.

nightly 버전은 최신베타버전의 Pytorch를 설치한다고 생각하면 된다. 6월에 설치할 때에는 1.13이 떴지만, 지금은 2.0.0 버전으로 뜰 것이다.
- 주의: 위 링크의 포스트의 가장 하단에 성능 평가를 위한 '실험해본 코드' 가 있을 것이다. 사용하지 않기를 바란다. 지금 보니까, '내가 왜 저렇게 했지?' 이 생각이 든다. 새로운 실험 코드로 업데이트를 하겠다. 이 포스트에서.
2) 이미 nightly 버전이 설치되어있다면? 1.13이하 버전이라면?
: 필자처럼 뭔가 Pytorch nightly 버전 설치로 얼리어답터 느낌을 살리고 싶어서 수단과 방법을 가리지 않고 필자와 동일하게 설치해본 사람이 있을 것이다. 그런 사람의 경우, 해당 conda 가상환경을 activate 한 후에, 다음 코드 한 줄을 입력해보자.
pip3 install numpy --pre torch torchvision torchaudio --force-reinstall --extra-index-url https://download.pytorch.org/whl/nightly/cpu 
이 코드 한 줄이면, Pytorch nightly 버전을 최신 버전(지금은 2.0.0.dev20221230)으로 설치될 것이다. 자동적으로.
- 혹시라도 무언가 모험이 불안하다면, conda 가상환경을 복제해서 새로 만들어서 진행해봐도 무관하다. (참고: M1 Part7 - "Hugging Face Transformers Installation on M1" 중 '00 Get Reday: Clone Conda env')
How About 성능?
: 여기서 성능은 CIFAR10 분류문제를 기준으로 하였다. Colab에서 돌리든, M1에서 돌리든, 성능상으로 가장 먼저 생각나는 큰 차이는 바로 '속도' 였다. Accuracy, F1 Score 등 Evaluation Metric이 있어서 뭘로 하면 좋을 지 고민하다가, 그냥 일단은 (귀찮아서) 속도만 보기로 하였다.
(Colab) 새로운 실험코드
: Colab에서 GPU(nvidia Tesla T4)으로 CIFAR10 코드를 돌렸을 때를 기준으로 비교해보려고 한다. Train, Valid를 30000, 20000으로 Split하고, 배치사이즈 128, Epoch은 100으로 지정했다. 또한, Model은 Conv2d 레이어 2개와 MaxPool2d 레이어 하나만 쌓았다. 자세한 것은 코드를 확인해보길 바란다.
1) Colab에서의 성능
: Colab GPU로 학습시켰을 때, 25 Epoch까지 학습이 진행되었다. (EarlyStopping 때문) 25 Epoch이 돌아가는 동안 67초가 걸렸다. 1 Epoch당 2.68초가 소요된다.
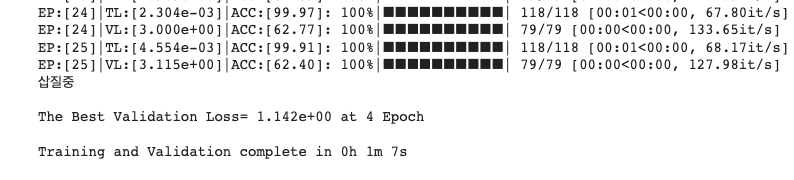
2) M1 GPU(MPS)에서의 성능
먼저 위 코들르 ipynb 파일로 다운로드 받은 후, Pytorch 2.0을 설치한 conda 가상환경으로 잔압허여 실행하면 된다. 물론, 다음과 같이 device를 설정해야한다.
# M1
device = torch.device("mps") if torch.backends.mps.is_available() else torch.device("cpu")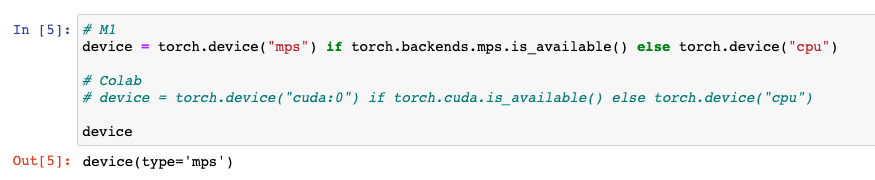
그리고 학습을 돌려보면, M1에서는 24 Epoch까지 학습이 진행되었다. (EarlyStopping 때문) 24 Epoch이 돌아가는 동안 138초가 걸렸다. 1 Epoch당 5.75초가 소요된다.
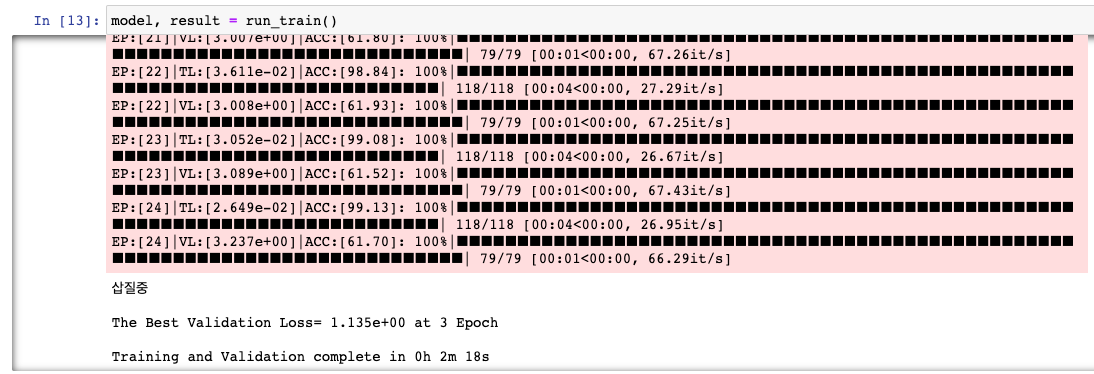
3) 그렇다면, torch.compile()로 한 성능은?
결론부터 말하자면, '아직은 잘 모르겠다.'이다. Pytorch 2.0에서 강조하는 torch.compile() 은 사용자가 정의한 함수이든, 모델이든 다 적용이 된다. 적용하면 더 빨라지는 것은 맞는 것 같다. 하지만, 실험코드가 간단한 태스크인지 혹은 아직 Pytorch 2.0이 M1에 Optimize가 안 된 것인지 모르겠지만, 실험 성능상 별 차이는 없었다.
- 공식적인 방법: 위 실험코드 기준으로, Model class 코드를 작성한 뒤, model 객체를 선언해준 다음, 다음과 같이 코드를 짜면 된다고 한다.
model = Model().to(device)
model = torch.compile(model) # Only at Pytorch 2.0하지만, 이렇게 짜고 돌리면 에러가 난다.
(아래 스샷을 보면 알겠지만, 마니 가려져서 그렇지, 매우 긴 에러가 난다.)
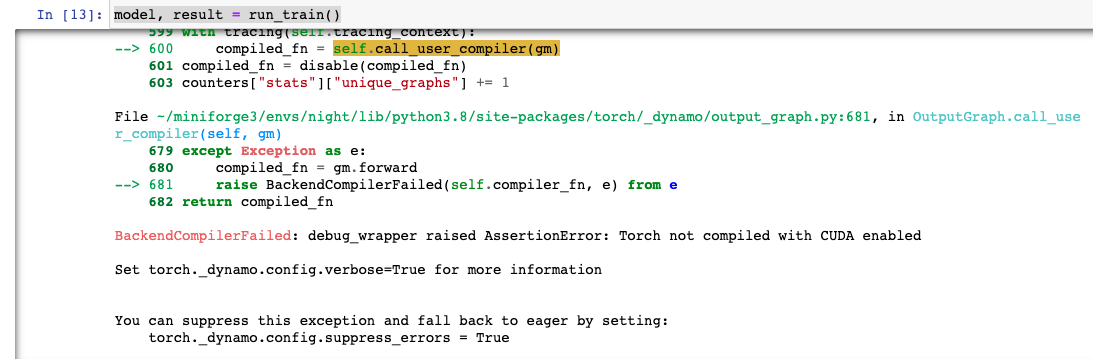
방법이 없는 것이 아니다. 위에서처럼 torch.compile()을 적용하는 것뿐만 아니라, 다음과 같이 run_train() 함수를 실행하는 부분에 다음 두 줄의 코드를 추가하면, (엄청나게 긴 warning같은 분홍 바탕의 긴 글이 한 번 뜨고나서) 돌아간다.
# model = Model().to(device)
# model = torch.comile(model) 이 진행된 상태에서
torch._dynamo.config.verbose=True
torch._dynamo.config.suppress_errors = True
model, result = run_train()그래서 torch.compile()을 먹여서 학습을 돌려보면, 2)에서와는 달리, 25 Epoch까지 학습이 진행되었다. (EarlyStopping 때문) 25 Epoch이 돌아가는 동안 141초가 걸렸다. 1 Epoch당 5.64초가 소요된다.
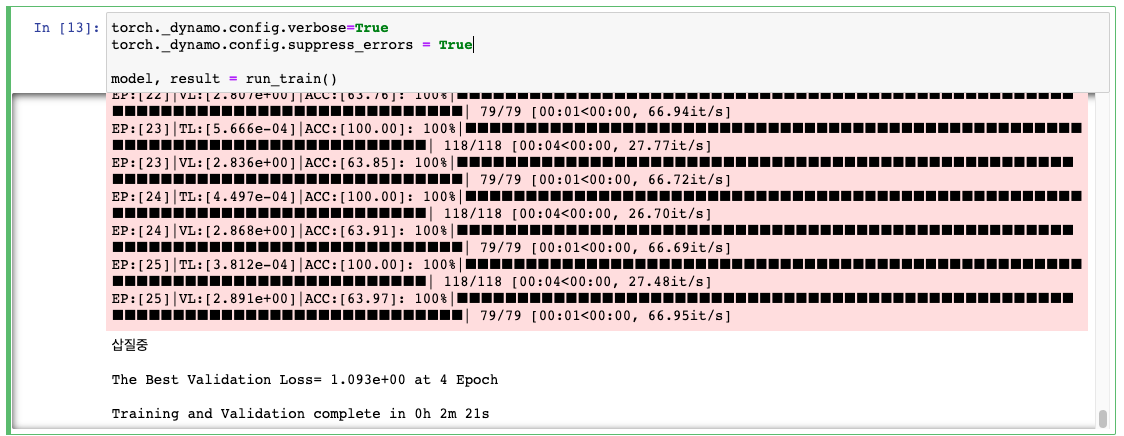
여기까지면 된다. 당장 M1이나 M2에서 Pytorch 2.0으로 의미있는 무언가를 해보기에는 무리가 있을 것이다. 하지만, 필자는 지속적인 관심을 가지고 계속 실험을 해보려고 한다. 이후 포스트는 BetterTransformer인데 쓸 수 있을지 모르겠다.
새해 복 많이 받으세요! :)
갑자기?

처음부터 글을 읽고 세팅을 했는데, 진짜 엄청나네요 감사합니다