
썸네일 이미지 출처: https://www.geeksforgeeks.org/top-kaggle-courses-for-data-science/
EDA Review
04. 3차 컬럼(column) 선별
이전 포스트에서 마지막 부분에 언급하긴 했지만, 필자가 참고한 EDA 노트에 따르면, 저자는 df 의 각 컬럼마다 'default'와의 관계를 for문을 이용해서 돌려서 살펴보아았고, 이를 기반으로 마지막으로 컬럼을 또 걸러내었다.
df= df.drop(['emp_length', 'verification_status', 'annual_inc',
'disbursement_method', 'home_ownership', 'purpose', 'addr_state'], axis=1)참고한 EDA 노트 저자가 선별한 이유를 적어놓긴 했으나, 필자가 나름 생각하고 고민을 해봤다. for문으로 시각화 결과를 보면서 생각해보았다..
EDA 노트 저자의 컬럼 선별 기준
아래 기준에 해당하는 컬럼들은 EDA 노트 저자가 제외하고 'df'라는 변수로 저장하였다.
-
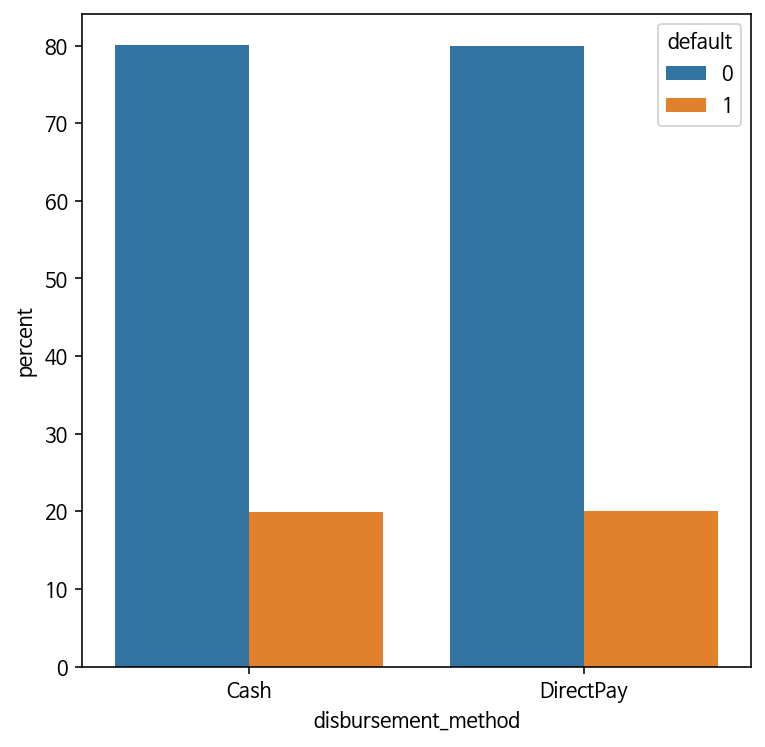
'default' 값(0, 1)에 따라 변화가 없는 FEATURE
: 'disbursement_method', 'emp_length', 'verification_status', 'annual_inc',
-
컬럼의 값의 종류가 너무 많거나 'default' 값(0, 1)에 따라 변화가 없는 컬럼들
: 'purpose', 'addr_state', 'home_ownership'
.png)
05. 4차 컬럼(column) 선별 및 정리
여기서부터는 (이전까지 과정을 바탕으로) 필자의 자력으로 컬럼을 선별하였다. 여기서부터 대략적인 프로세스를 말하자면
- 추가적인 컬럼 선별
- 상관성이 있는 컬럼 확인
- 애매한 컬럼들 확인 및 분류
- 범주형 컬럼 수치화, 결측치 제거, 범주재구성
- HeatMap 및 결론
(1) 추가적인 컬럼 선별
: EDA 노트 저자가 각 컬럼별로 'default' 타겟컬럼과의 관계를 시각화했던 것처럼, 동일하게 진행하되, 데이터 타입이 float 인 경우에는 'boxplot'대신 'violinplot' 을 사용했다. default 값이 0일 때와 1일 때 데이터의 모양이 다르면, 'default와 상관관계가 있다'고 할 수 있다. 반대로, default 값이 0일 때와 1일 때 데이터의 모양이 같다면, 그 컬럼은 'default와 상관관계가 없다'고 할 수 있다.
- violinplot?
: boxplot의 경우, 평균과 분산(?) 등 대략적인 정보를 알 수 있다. 하지만, 대략적인 분포 모양을 알 수 없다. violinplot의 경우, boxplot 와는 반대로 대략적인 분포 모양을 그려주기 때문에 분포 모양을 알 수 있다.
1) float64인 데이터
# float64인 데이터
for col in df.columns:
if df[col].dtype == 'float64':
fig, ax = plt.subplots(figsize = (5, 5))
sns.violinplot(ax = ax, y=col, x='default', data=df)
else:
pass int_rate 와 default 와의 관계 - violinplot
: default가 0일 때와 1일 때, 두 그래프의 모양이 확실하게 다르다. int_rate 컬럼은 default와 상관관계가 있는 컬럼이라고 할 수 있고, 머신러닝에서도 좋은 성능을 발휘하게 할 수 있는 컬럼이다.
.png)
installment 와 default 와의 관계 - violinplot
: default가 0일 때와 1일 때, 두 그래프의 모양이 거의 비슷하다. 이 컬럼은 default와 상관관계가 있는 컬럼이라고 할 수 없다. 이런 컬럼은 제외시키는 것이 좋다. !.png)
2) object인 데이터
: 사실 당시에 해놓고, float인 데이터를 선별하느라, 제대로 된 선별 작업을 못 했다.
# object인 경우
for col in df.columns:
if df[col].dtype == 'object':
fig, ax = plt.subplots(figsize = (5, 5))
data = df.groupby(col)['default'].value_counts(normalize=True).mul(100).rename('percentage').reset_index()
sns.barplot(data=data, x='percentage', y=col, hue='default', ax=ax)
else:
pass disbursement_method 와 default 와의 관계 - violinplot
: default가 0일 때와 1일 때, 두 그래프의 모양이 유사하다. 이 컬럼 또한 default와 상관관계가 있는 컬럼이라고 할 수 없고, 제외시키는 것이 좋다. 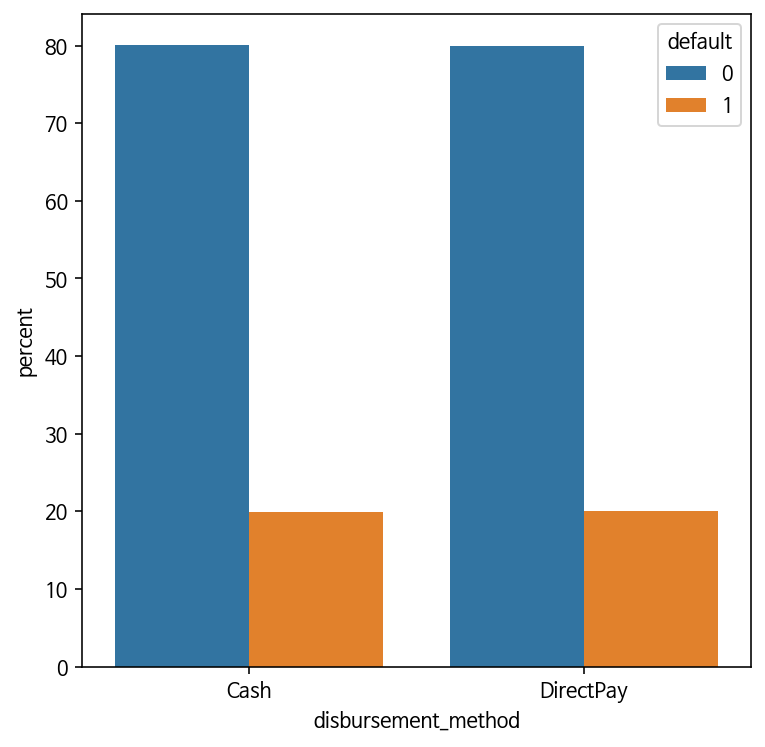
(2) 상관성이 있는 컬럼 확인
1) helpful, useless
위 과정에처럼 violinplot 으로 시각화해서 다시 살펴보고 default와 상관성이 있는 컬럼들과 상관성이 없는 컬럼들을 나눠서 다음과 같이 list에 담아두었다.
helpful = ['pub_rec_bankruptcies', 'application_type', 'open_acc', 'int_rate', 'term']
useless = ['loan_amnt', 'dti', 'total_acc', 'revol_util', 'installment', 'open_acc']Google Colab 에서는 위와 같이 helpful 리스트(default와 상관관계가 있는 컬럼들)과 useless 리스트(default와 상관관계가 없는 컬럼들)을 나누고, 각 리스트마다 위와같이 for문으로 다시 한 번 시각화를 했는데, 이전 과정과 중복된 과정이므로 여기서는 생략하겠다.
2) helpful - 다시 한 번 선별
helpful 리스트에 있는 원소 하나하나를 다음 시각화 기법으로 구체적으로 살펴보았다. 왜냐하면, 혹시 쓸모없는 컬럼인데도 착각한 것일 수도 있기 때문이다. 다시 한 번 살펴보기로 했다. seaborn의 FacetGrid를 활용하여 default 값이 0일 때와 1일 때의 분포 양상을 더 자세히 살펴보았다.
- FacetGrid
: 원래 시각화 자료를 보기 좋게 정렬하기 위해 검색하다가 우연히 발견하였고 여기서 활용하였다.
# term
grid = sns.FacetGrid(data=df, col='default', col_order=[1, 0], height= 4, aspect=1.5)
grid.map(sns.countplot, "term") term과 default와 관계
: default 값에 따라 확실히 다르다. default 와 상관관계를 가졌을 가능성이 크다.
.png)
open_acc와 default와 관계
: default 값에 따라 다른지는 확실히 알 수 없다. boxplot만 오히려 비슷해 보인다. 그래서 아래에 violinplot을 하나 더 추가해서 살펴본 결과, violinplot로 보면, default 값에 따라 분포 범위와 모양이 다르지 않고 거의 비슷하다. .png)
.png) 분포 모양의 첨도가 다르긴 하다. default가 1일 때는 뾰족하지만, 0일 대는 뾰족하지 않다. 하지만, 전반적으로 살펴봤을 때, 이것은 일부에 지나지 않기 때문에 default와 상관관계를 가진다고 할 수 없다.
분포 모양의 첨도가 다르긴 하다. default가 1일 때는 뾰족하지만, 0일 대는 뾰족하지 않다. 하지만, 전반적으로 살펴봤을 때, 이것은 일부에 지나지 않기 때문에 default와 상관관계를 가진다고 할 수 없다.
그래서 다음과 같이 제거한다.
helpful.remove('open_acc')(3) 애매한 컬럼들 확인 및 분류
df의 컬럼 중, helpful이나 useless 에 어디에도 분류되지 않는 컬럼들이 있다. 이러한 컬럼들을 애매하기 때문에 'aemae' 라는 리스트로 저장했다.
convinced = helpful + useless
# apply 함수와 lambda 함수를 사용
aemae = [x for x in list(df.columns) if x not in convinced]
# default가 자동으로 포함될텐데, 타겟이기 때문에 일단 제외한다.
aemae.remove('default')
aemae# aemae
['sub_grade', 'pub_rec', 'revol_bal', 'initial_list_status', 'mort_acc']aemae 리스트에 속하는 컬럼들 하나하나를 이전과 같은 방식으로 seaborn의 FacetGrid를 활용하여 default 값이 0일 때와 1일 때의 분포 양상을 더 자세히 살펴보았다.
mort_acc 와 default와 관계
: default 값에 따라 확실히 다르다. default 와 상관관계를 가졌을 가능성이 크다. 그래서 helpful에 추가하였다.
grid = sns.FacetGrid(data=df, col='default', col_order=[1, 0], height= 4.5, aspect=1.5)
grid.map(sns.violinplot, "mort_acc") .png)
helpful.append('initial_list_status')# 최종적인 helpful
['pub_rec_bankruptcies', 'application_type', 'int_rate', 'term', 'mort_acc', 'initial_list_status'] revol_bal과 default와 관계
: 분포범위가 상당히 좁지만, 그래도 default 값에 따라 분포 모양이 비슷하다. default 와 상관관계를 가졌을 가능성이 적다. 그래서 useless 에 추가하였다.
grid = sns.FacetGrid(data=df, col='default', col_order=[1, 0], height= 4, aspect=2)
grid.map(sns.violinplot, "revol_bal").png)
useless.append('revol_bal')# 최종적인 useless
['loan_amnt','dti','total_acc', 'revol_util', 'installment', 'open_acc', 'revol_bal'](4) 범주형 컬럼을 만져보자
지금부터는 범주형 컬럼을 수치화, 결측치 처리, 범주 재구성을 할 것이다. 이제까지 그래왔지만, 여기서도 하나씩 예시를 들어 설명하겠다.
그리고 아래 코드처럼, df pandas DataFrame 데이터를 helpful 리스트로 마스킹하여, 'df_n'이라는 변수에 저장하였다.
df_n = df[helpful]1) 범주형 컬럼 수치화
: term 컬럼의 경우, 데이터의 value 가 문자열인데, 컴퓨터가 알아듣고 연산할 수 있도록 숫자로 바꿔줄 것이다. 이런 식으로, 'term', 'application_type', 'initial_list_status', 'sub_grade' 를 수치로 바꾸어주었다.
- 'sub_grade'의 경우, 나중에 범주재구성 작업을 한 번 더 진행.
value_counts() 로 value 값 확인
: groupby로 default에 따라 살펴보았다.
df_n.term.groupby(df_n.default).value_counts()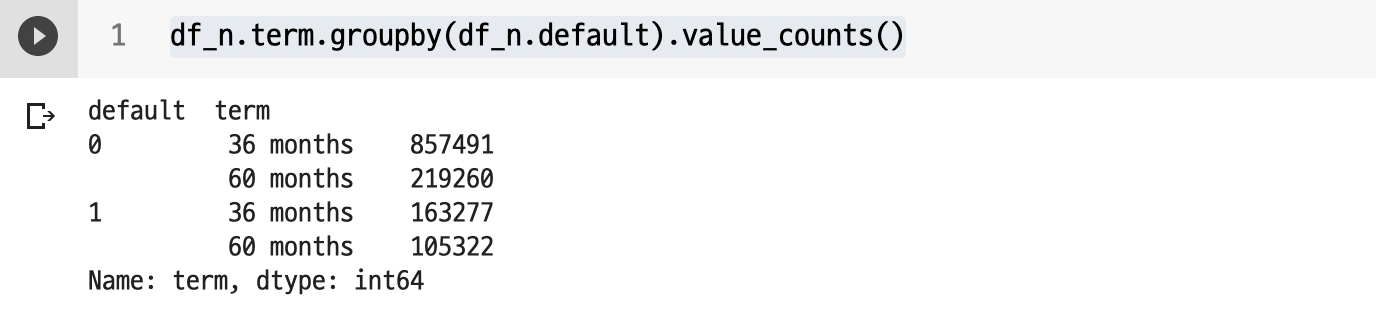
위 내용을 토대로 plot.pie 로 시각화
plt.figure(figsize= (7, 8))
plt.title('term', fontsize= 20)
df_n.term.groupby(df_n.default).value_counts().plot.pie().png)
문자인 value를 숫자로 변환
: new_term 이라는 컬럼을 새로 만들어서, term 의 value 값 중 ' 36 months'인 경우 1로 , ' 60 months'인 경우 0 으로 변환한다.
# 수치로 변환
# ' 36 months'를 1로 나머지 값은 0으로
df_n['new_term'] = df_n.apply(lambda x : 1 if x['term'] == ' 36 months' else 0, axis=1)
df_n['new_term']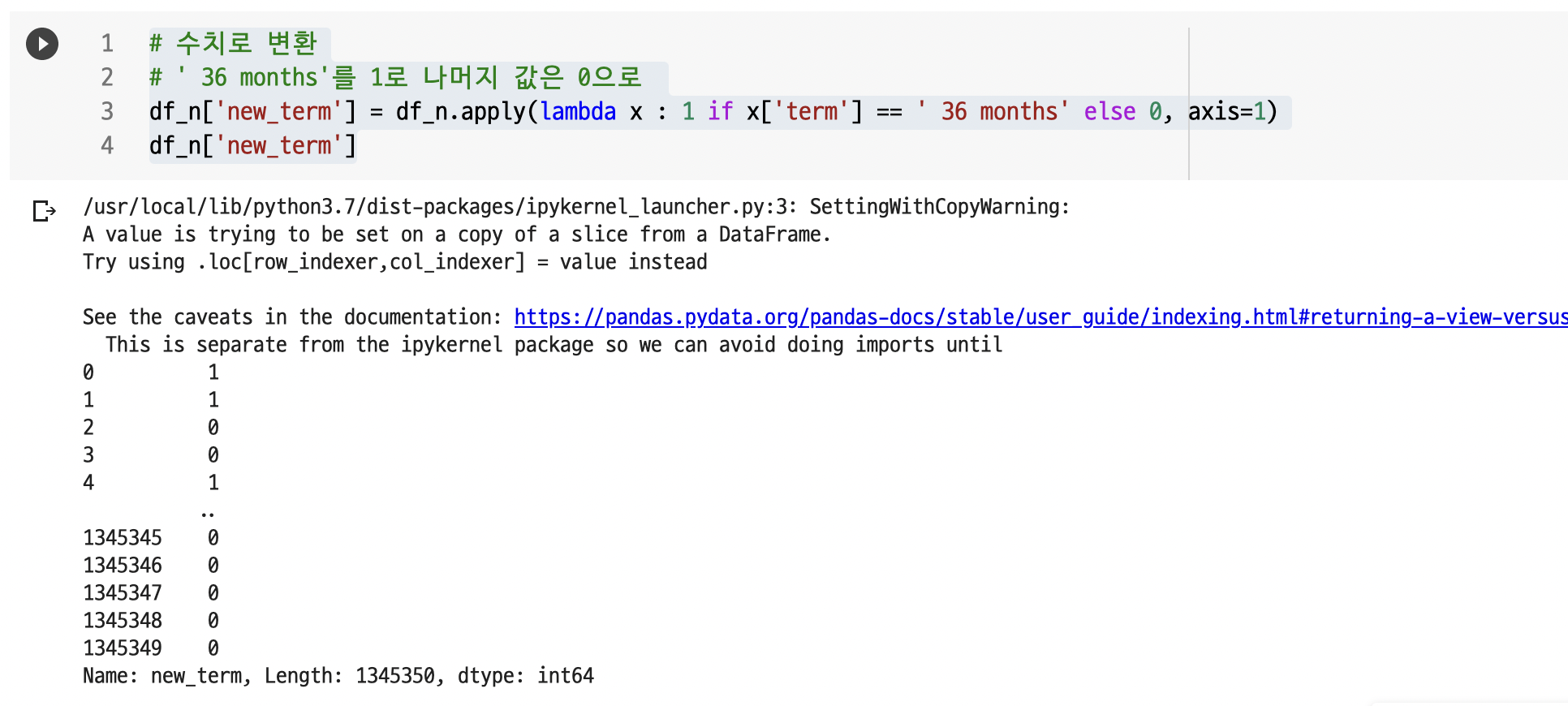
new_term으로 동일하게 plot.pie 로 시각화
: new_term으로 시각화하여 이전과 같은 모양인지 보고 숫자로 잘 바뀌었는지 확인해본다.
# 시각화
plt.figure(figsize= (7, 8))
plt.title('new_term', fontsize= 20)
df_n.new_term.groupby(df_n['default']).value_counts().plot.pie().png)
2) 결측치 처리
결측치가 있는 컬럼을 다음 코드와 같이 확인하였다.
df_n.isnull().sum()
결과가 다음과 같이 범주형 컬럼인 pub_rec_bankruptcies와 mor_acc 두 컬럼이 나오는데, 필자는 두 컬럼을 간단하게 결측치를 채웠다. 여기에서 예시로 mort_acc를 예로 들겠다.
결측치 비율확인
# 결측치 비율확인
100*(df_n.mort_acc.isnull().sum()/df_n.shape[0])# 결과
3.5144014568699595value_counts() 로 살펴보기
# 종류 확인
df_n.mort_acc.value_counts()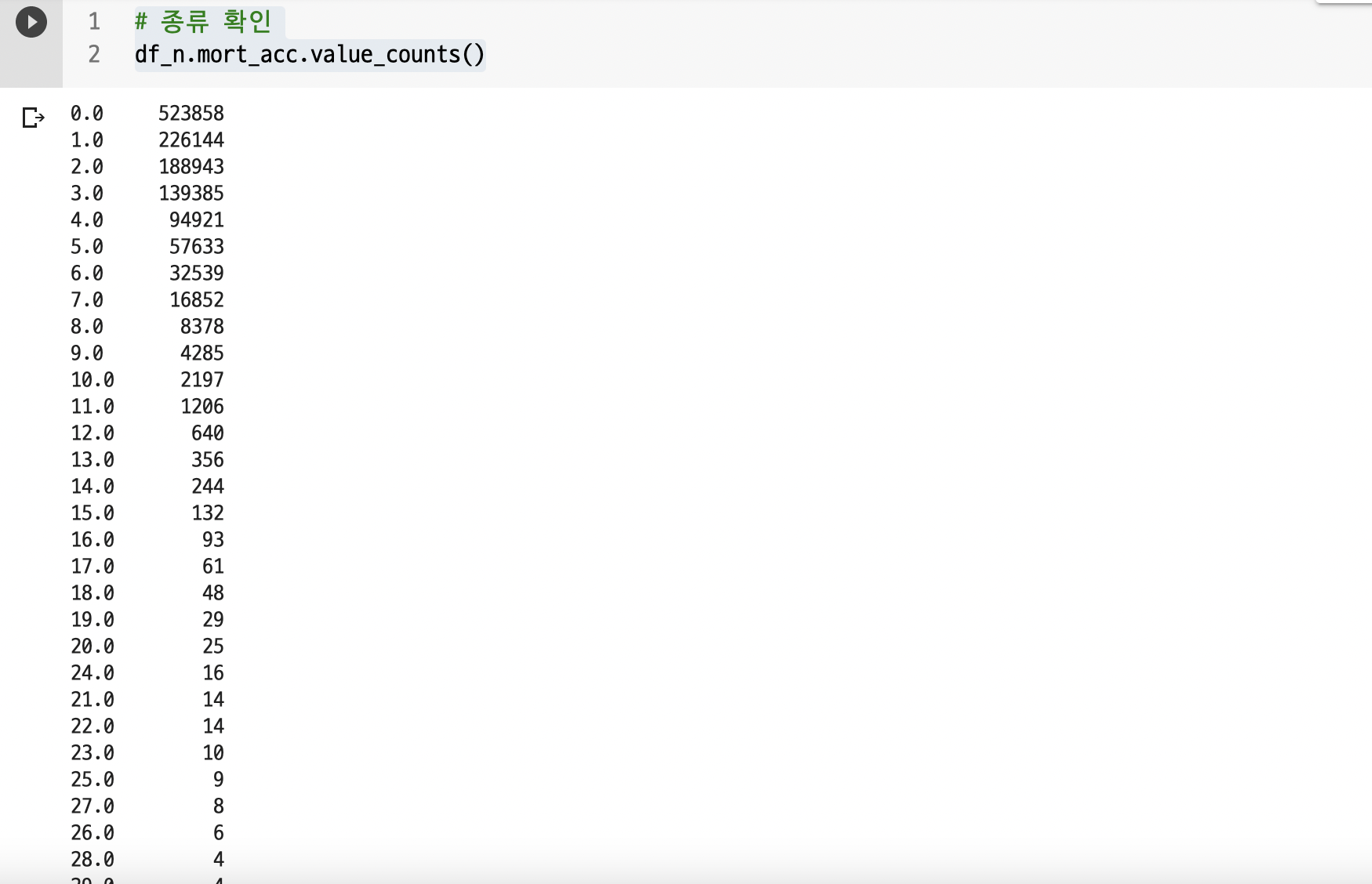 이렇게 많지만, 보면, 0.0인 value가 많다.
이렇게 많지만, 보면, 0.0인 value가 많다.
결측치를 0으로 채워보자
# 가장 많은 0.0으로 채우겠다.
df_n.mort_acc = df_n.mort_acc.fillna(0.0)다음 코드로 성공적으로 결측치가 제거된 것을 알 수 있다.
df_n.mort_acc.isnull().sum()
# 출력결과 : 03) 범주재구성
: 일부 컬럼의 경우, 범주형 컬럼인데 value 종류값이 2~4개가 아닌 35개를 넘는 경우가 있다. 이런 경우, 머신러닝을 돌릴 때 성능저하를 일으킨다. 범주가 10개만 넘어가도 성능 저하가 온다고 한다. 그 만큼 연산하고 판단해야하는 과정이 많아지기 때문이다.
sub_grade의 분포 양상을 살펴보자.
보다시피, default 의 값이 따라 양상이 다르다.
# 시각화
plt.figure(figsize= (10, 14))
plt.title('sub_grade by default', fontsize= 20)
df_n.sub_grade.groupby(df_n.default).value_counts().plot.barh()
plt.show()y 축의 값이 0 혹은 1인데, 이것은 default 값이 0일 때와 1일 때를 의미한다. default 값에 따라 다른 양상을 보이기 때문에 default와 상관관계가 상당히 있는 것으로 보인다.
.png) 하지만, sub_grade의 value 값의 종류가 35개이기 때문에, 더 3~4개의 컬럼의 범주로 다시 재구성을 해줘야한다.
하지만, sub_grade의 value 값의 종류가 35개이기 때문에, 더 3~4개의 컬럼의 범주로 다시 재구성을 해줘야한다.
- sub_grade 컬럼의 value 값이 문자열이기 때문에, 숫자로 바꾸는 작업을 중간에 한 번 했었다. 이 과정을 아래 코드로 간단하게 안내하고 생략하겠다.
new_lists = []
# sub_grade 컬럼의 변수를 숫자로 바꾸되 중복을 피하도록 코드를 구성했다.
def change_into_num(val):
if val not in new_lists:
new_lists.append(val)
val_num = int(new_lists.index(val))
return val_num
elif val in new_lists:
val_num = int(new_lists.index(val))
return val_num
# new_sg 라는 컬럼을 만들어서, 숫자로 바꾸는 함수를 apply() 로 적용해서 넣었다.
df_n['new_sg'] = df_n.sub_grade.apply(change_into_num)
df_n['new_sg']sub_grade의 분포 양상을 살펴보자.
먼저 value_counts() 로 데이터를 살펴보면
df_n.new_sg.value_counts()대략적인 분포는 이러하다.
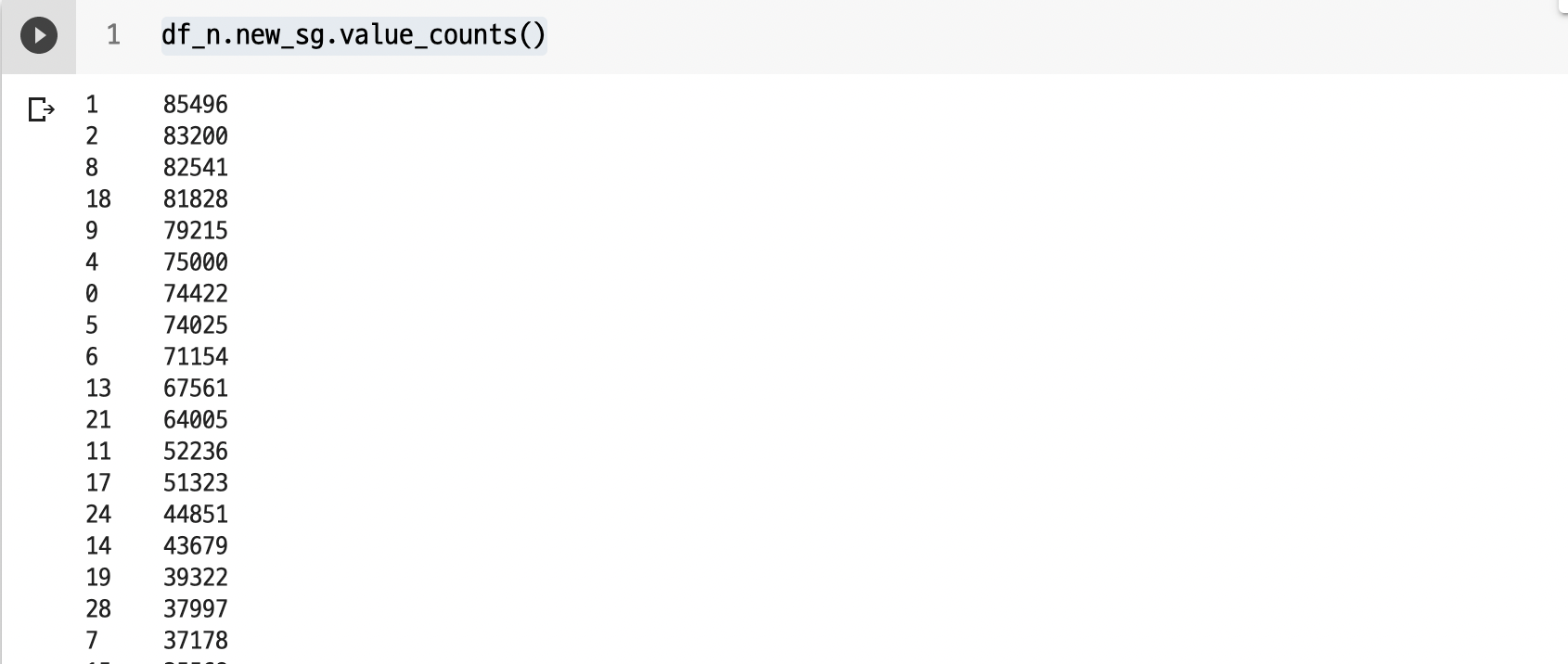
그래서 처음에는 함수를 만들어서, 특정 컬럼의 value 값이 들어오면, 그 value가 포함된 데이터의 개수를 세어서, 그 개수가 특정 숫자범위일 때, 그 범위에 따라서 숫자 0, 1, 2, 3 을 반환하도록 함수를 구성했다. 아래 코드를 확인해보자.
def reshape_into_class1(val):
if (df_n.new_sg[df_n.new_sg == val].count() >= 74420):
return 0
elif (df_n.new_sg[df_n.new_sg == val].count() < 74420) and (df_n.new_sg[df_n.new_sg == val].count() >= 43670):
return 1
elif (df_n.new_sg[df_n.new_sg == val].count() < 43670) and (df_n.new_sg[df_n.new_sg == val].count() >= 14400):
return 2
elif (df_n.new_sg[df_n.new_sg == val].count() < 14400) and (df_n.new_sg[df_n.new_sg == val].count() >= 10000):
return 3
else:
return 4df_n['new_sg_r'] = df_n.new_sg.apply(reshape_into_class1)
df_n['new_sg_r']df_n에 'new_sg_r' 컬럼을 만들어서, 위 코드를 apply() 함수에 넣어서 범주를 재구성한 뒤, 재구성한 범주의 정보(0, 1, 2, 3, 4)를 'new_sg_r' 컬럼에 넣으려고 했다. 그런데 실패했다. 일단 이렇게 실행하면, 돌아가는 것 같으나, 매우 오래 걸린다. Colab의 RAM도 빨리 차오르고...(애초에 오래걸리는 코드였는데, 필자가 무지해서 몰랐다...) 그래서 전략을 바꾸었다.
value_counts() 에서 개수를 보고 그 개수에 따라, 특정 value 값을 고르고, 그 value 값에 따라 범주를 4개로 재구성했다.
- value 값이 1, 2, 8, 18, 9, 4, 0, 5, 6, 13, 21 일 때는 0으로
: 개수가 60000개 이상인 경우 - value 값이 11, 17, 24, 14, 19, 28, 7, 15 일 때는 1로
: 개수가 35500개 이상 60000개 미만인 경우 - value 값이 20, 25, 10, 27, 12, 23, 27, 3 일 때는 2로
: 개수가 9900개 이상 35500개 미만인 경우 - 나머지의 경우 3으로 반환
: 개수가 9900개 미만인 겨우
def reshape_into_class2(val):
if val in [1, 2, 8, 18, 9, 4, 0, 5, 6, 13, 21]:
return 0
elif val in [11, 17, 24, 14, 19, 28, 7, 15] :
return 1
elif val in [20, 25, 10, 27, 12, 23, 27, 3]:
return 2
else:
return 3df_n['new_sg_r'] = df_n.new_sg.apply(reshape_into_class2)
df_n['new_sg_r']이렇게 value 값을 35개에서 4개로 재구성하였고 이를 시각화까지 해보았다. 범주의 재구성이 잘 된 것을 확인 할 수 있다.
4개 범주로 재구성한 new_sg_r 시각화
plt.figure(figsize=(6,6))
plt.title('new_subgrade_classified', fontsize=15)
df_n.new_sg_r.value_counts().plot.pie().png)
default에 따른 new_sg_r 시각화
plt.figure(figsize=(6,6))
plt.title('new_subgrade_classified by default', fontsize=15)
df_n.new_sg_r.groupby(df_n.default).value_counts().plot.pie().png)
이제 다음 포스팅에서 MiniEDA 시리즈를 마무리 지으려고 한다. : )
# 쿠키
# 1) 나중에 리뷰를 위해 df_n1 생성 및 copy()
df_n1 = df_n.copy()
# 2) df_n에서는 'mort_acc', 'pub_rec_bankruptcies', 'new_sg' 세 컬럼 삭제
df_n = df_n.drop(['mort_acc', 'pub_rec_bankruptcies', 'new_sg'], axis=1)