INTRO
: 06 NLP Basic Classification with GRU에서 진행했던 내용을 그대로 진행한다. 단, Model 부분을 Encoder와 TransformerEncoderModel로 교체할 뿐이다. 오늘은 그래서 글이 길지 않을 것이다.
- 기억을 되살려보자
- 06 NLP Basic Classification with GRU
- 이전 포스트까지의 트랜스포머 내용을 알아야할 것
- Colab Code
: 오늘의 실습코드이다.
TransformerEncoderModel
- Embed, PositionalEncodingLayer, Encoder, EncoderLayer, MultiHeadAttention, Attention, PositionwiseFeedForwardLayer 는 그대로 가져다 쓰고, Text Classification 태스크에 맞게 Model 클래스를 구성하였다.
- Model을 제외한 다른 부분은 그대로 동일하다고 보면 된다.
- 06 NLP Basic Classification with GRU 의 실습코드(Colab) 복사해서 Model 부분만 바꿔서 만들었으니 동일할 수 밖에...
- 설명은 아래 주석으로 달아두겠다.
class TransformerEncoderModel(nn.Module):
def __init__(self,
sl = sl, # 90
hid_dim = hid_dim, # 256
dropout = 0.1,
device = device):
super().__init__()
self.device = device
self.dropout = nn.Dropout(dropout)
self.enocder = Encoder()
# [bs, sl] -> [bs, sl, hid_dim]
# [bs, sl, hid_dim] -> [bs, k]
k = sl * hid_dim
# [bs, k] -> [bs, 256] -> [bs, 4]
self.seq = nn.Sequential(
nn.Linear(k, 256),
nn.ReLU(),
nn.Linear(256, 4),
nn.LogSoftmax(dim=-1)
)
def forward(self, src):
# src: [bs, sl] from DataLoader
bs = src.shape[0]
## train_loader 혹은 valid_loader에서 나오는
## 배치 단위의 데이터 Shape은 [bs, sl]
## 이를 토대로 src_mask를 만들어준다.
## self.make_mask 함수로 (아래 존재)
src_mask = self.make_mask(src)
# src_mask: [bs, 1, 1, sl]
# Encoder's output: enc_src
enc_src = self.enocder(src, src_mask)
# enc_src: [bs, sl, hid_dim]
# enc_src: 3차원 -> 2차원
enc_src = enc_src.reshape(bs, -1)
# enc_src: [bs, sl, hid_dim] -> [bs, k]
y = self.seq(enc_src)
# y: [bs, 4]
return y
def make_mask(self, src):
sl = src.shape[1]
pad_mask = (src!=0).unsqueeze(1).unsqueeze(2)
sub_mask = torch.tril( torch.ones((sl, sl), device = self.device)).bool()
# return pad_mask
# 원하면 pad_mask로 진행해도 된다.
return pad_mask & sub_mask
# x: [bs, sl] --> [bs, 1, 1, sl]Visualization
: 성능을 올리고 싶다면, 여러분의 몫으로 남겨둔다. (귀찮은 거 아니다)
: 이대로 끝내기에 뭔가 허전해서 시각화라도 넣었다.
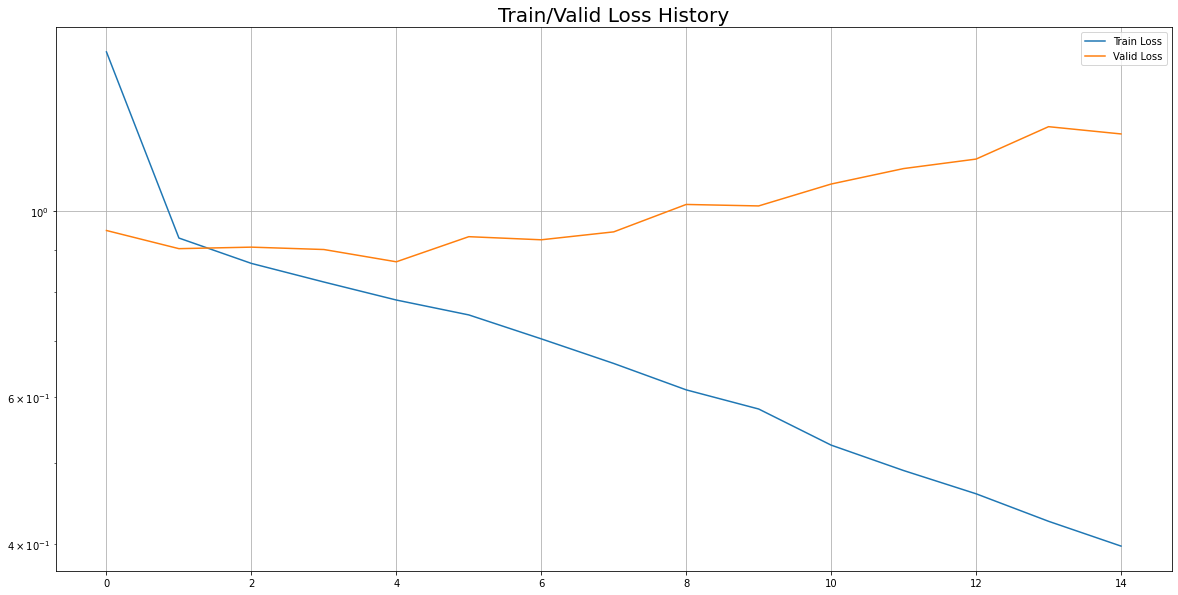
1) Loss 추이 시각화
- Early Stopping 적용되었다.
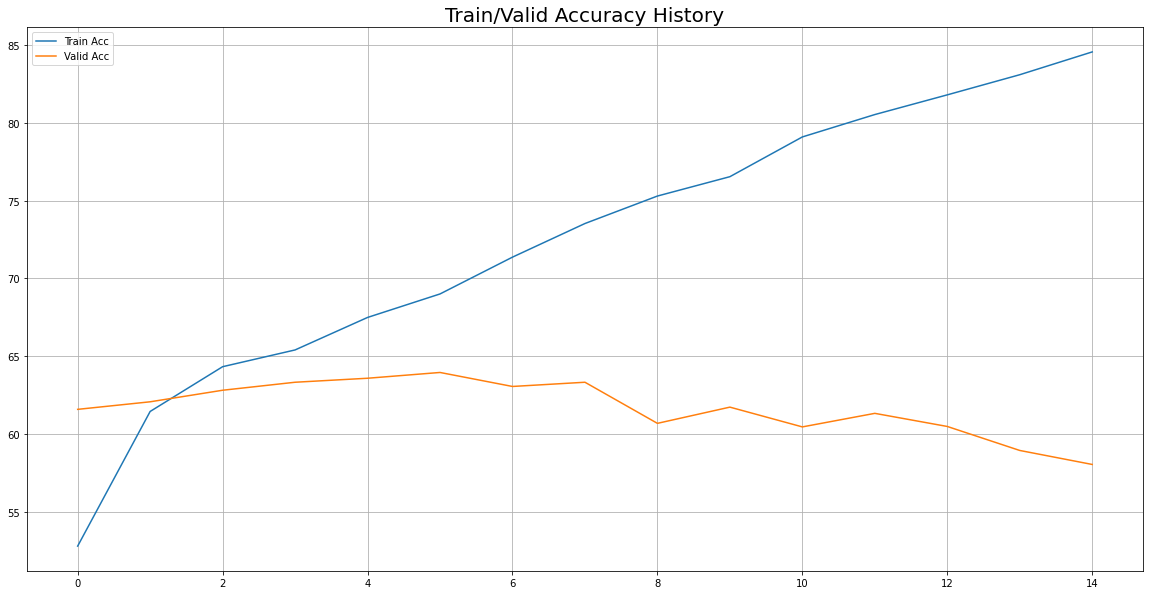
2) Accuracy 추이 시각화
- train: 85% 까지 증가
- Valid: 60%에서 64%까지 올랐다가 서서히 감소
끝인데...
짧게 끝나니까 이상하게 많이 허전하다. 어색하다.
하지만, 적응해보겠다.

weird